
基于稀疏系数和FV向量的图像质量评价
2018-03-19 05:56李博文范赐恩冯天鹏
计算机工程与设计 2018年3期
李博文,范赐恩,颜 佳,冯天鹏
(武汉大学 电子信息学院,湖北 武汉 430072)
0 引 言
图像质量评价(image quality assessment,IQA)领域是指面对海量有待评价的图像数据,主观评价手段费时耗力,不具备可行性,应该采用客观图像质量评价方法,利用计算机代替人类对图像质量进行正确评估。其中不需要任何参考信息的无参考(no-reference,NR)图像质量评价算法存在更大潜在的提升空间和实用价值。现有的NR-IQA模型大致可分为两类:特定失真型(distortion-speci-fic)方法和通用型(distortion-generic)方法。通用型模型旨在处理多个,可能存在未知失真的实际问题。通用型算法大体遵循两种趋势:①自然场景统计特性(natural scene statistics,NSS)[1,2]:其依赖于寻求测试图像与自然图像子空间的距离[3]。②基于训练的方法[4,5]:通过学习一个高维特征空间到一个标量质量值的映射关系来评估图像质量。文献[6]利用卷积神经网络(convolutional neural networks,CNN)直接对数据库图像块进行预测模型训练,特征提取和预测在同一网络中完成。CNN作为特征提取算子,在网络的层数以及特征定位的层数需要消耗巨大的运行时间。文献[7]提出了一种称之为CORNIA的无监督特征学习算法,提出Max-Pooling池化的降维方式丢掉了大部分的系数特征信息。此外,这类基于训练的算法有些还会因为字典基数大,增加计算的复杂性,不能很好地适用于实际应用场景中。
本文采用显著性图像块建立稀疏编码字典,去除原始的冗余图像块,并提出了一种基于稀疏系数和Fisher向量的无参考图像质量评价方法。该算法应用小尺度稀疏编码字典就可以取得和大尺度字典相当的效果,并且用Fisher向量对稀疏表达系数编码,能更加全面保留系数矩阵各个维度上的特征信息。实验结果表明,预测过程符合人眼视觉系统感知图像质量的过程,得到的客观评价结果与主观评价结果具有良好的一致性。
1 显著性局部特征描述子提取
对于一幅图像,人们往往只关注其场景中的部分信息,例如场景中的物体、物体的轮廓和物体环境的上下文等信息,这反映了人类视觉系统(human visual system,HVS)的视觉关注特性。为了让机器也能实现对视觉感兴趣区或显著性焦点的自动视觉关注,获取图像显著性信息是最为基础的一步,它不仅有助于剔除图像冗余信息,而且能够为其它应用领域提供图像显著性参考标准,从而提高应用领域的算法效率并降低算法复杂度。在图像显著性区域定位时,通常选择显著图作为一个表征图像像素显著性的标量去执行定位操作。显著图能够有效剔除冗余信息,在图像质量评价领域,显著性信息往往作为图像预处理过程中的辅助量被使用,目前很多结合了图像显著性信息的客观质量评价方法[8,9]均获得了很好的评价效果。本文采用文献[10]的谱残差法(spectral residua,SR)辅助完成图像预处理操作,实验发现应用了显著性检测之后,小尺寸字典能够在同等条件下取得更好的实验效果。
图1显示了同一幅图片在不同失真类型下,用SR算法提取显著性图像块的过程。其中,第一行是LIVE库[11]中的原始图像(从左到右失真情况:无失真、白噪声失真、JP2K失真、JPEG失真),第二行是经过SR算法之后的显著图,第三行框中区域是提取出来的显著性图像块,即显著性局部特征描述子。

图1 SR算法对不同类型失真图像提取显著性图像块的过程
2 基于稀疏系数和Fisher向量的无参考图像质量评价方法
2.1 稀疏字典训练
图像经过稀疏编码后得到的编码系数近似模拟了人类大脑皮层V1区简单细胞的感受特性,编码系数的稀疏性也符合HVS的稀疏表达特性,而求解图像的稀疏编码系数首先要构建合适的字典。字典如同大脑的神经元,按不同约束条件训练出来的字典会直接决定信号稀疏表达的效率。例如,在基于聚类方法或独立成分分析(independent component analysis,ICA)方法构建的字典上,对输入信号进行稀疏编码,获得的编码系数的稀疏性较低,这是因为聚类或ICA方法学习的字典不能很好地描述V1区简单细胞的三大特性(局部性、方向性、带通特性),编码系数在字典上的重建图样容易丢失细节信息和纹理结构信息。本文通过稀疏编码方法同时训练超完备字典和计算稀疏系数,最后提取图像稀疏特征。假设从字典训练集中提取了M个尺寸为B*B的显著性图像块,对图像块矩阵进行向量化、归一化和ZCA白化操作,得到局部特征描述子矩阵X={x1,x2,…,xM}∈RD×M, 对描述子进行稀疏编码的字典训练,目标函数为

(1)

2.2 稀疏表达求解
(2)
图3展示了一幅输入图像稀疏表达系数的求解过程,(B)显示了稀疏表达系数矩阵的三维散点图。实验对比不同失真图像稀疏系数矩阵的三维散点图,发现不同的失真程度影响了稀疏编码系数的空间分布规律,稀疏系数随着失真程度的增加呈现出越来越离散的特性,从稀疏系数中提取的特征具有量化图像质量的能力。
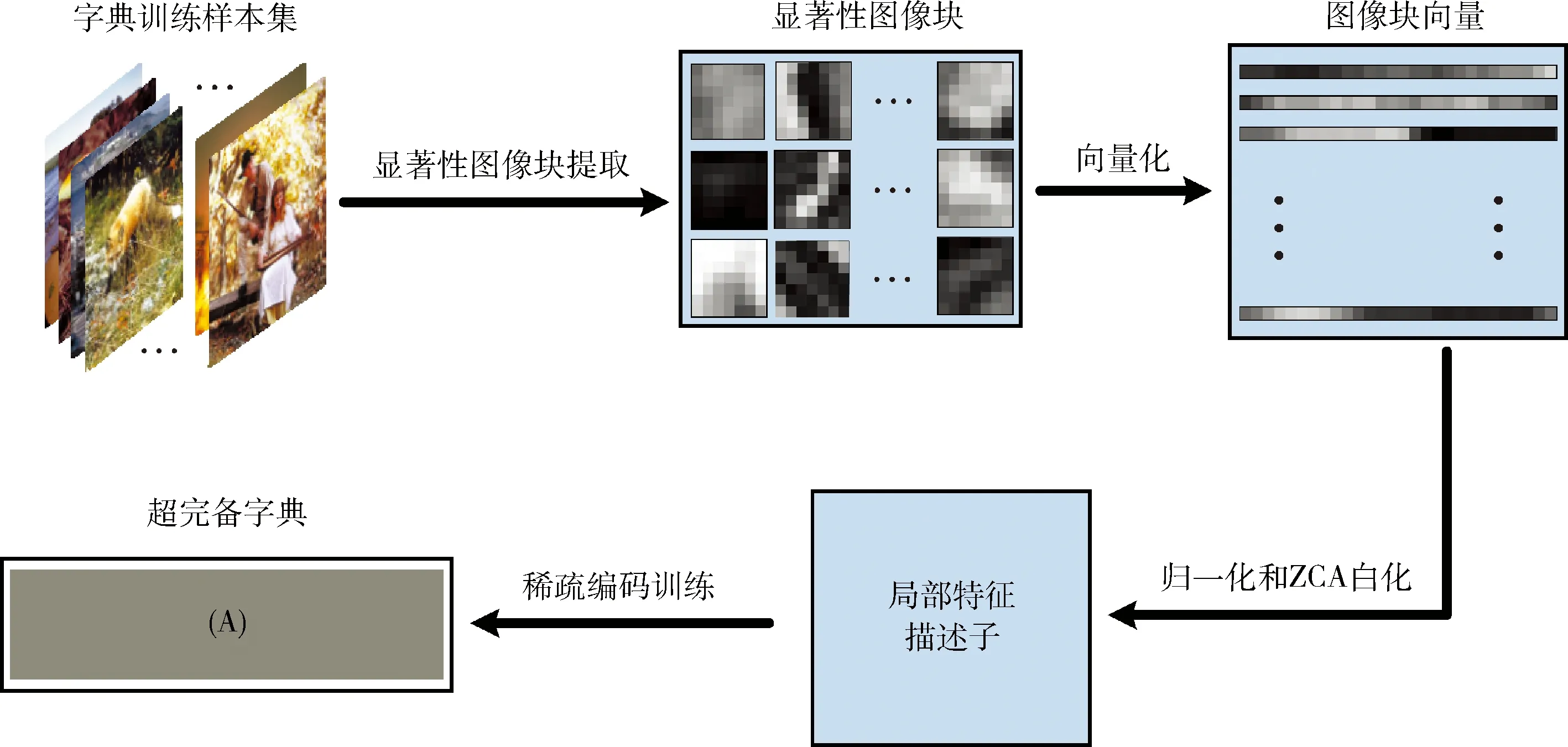
图2 稀疏编码字典的训练过程
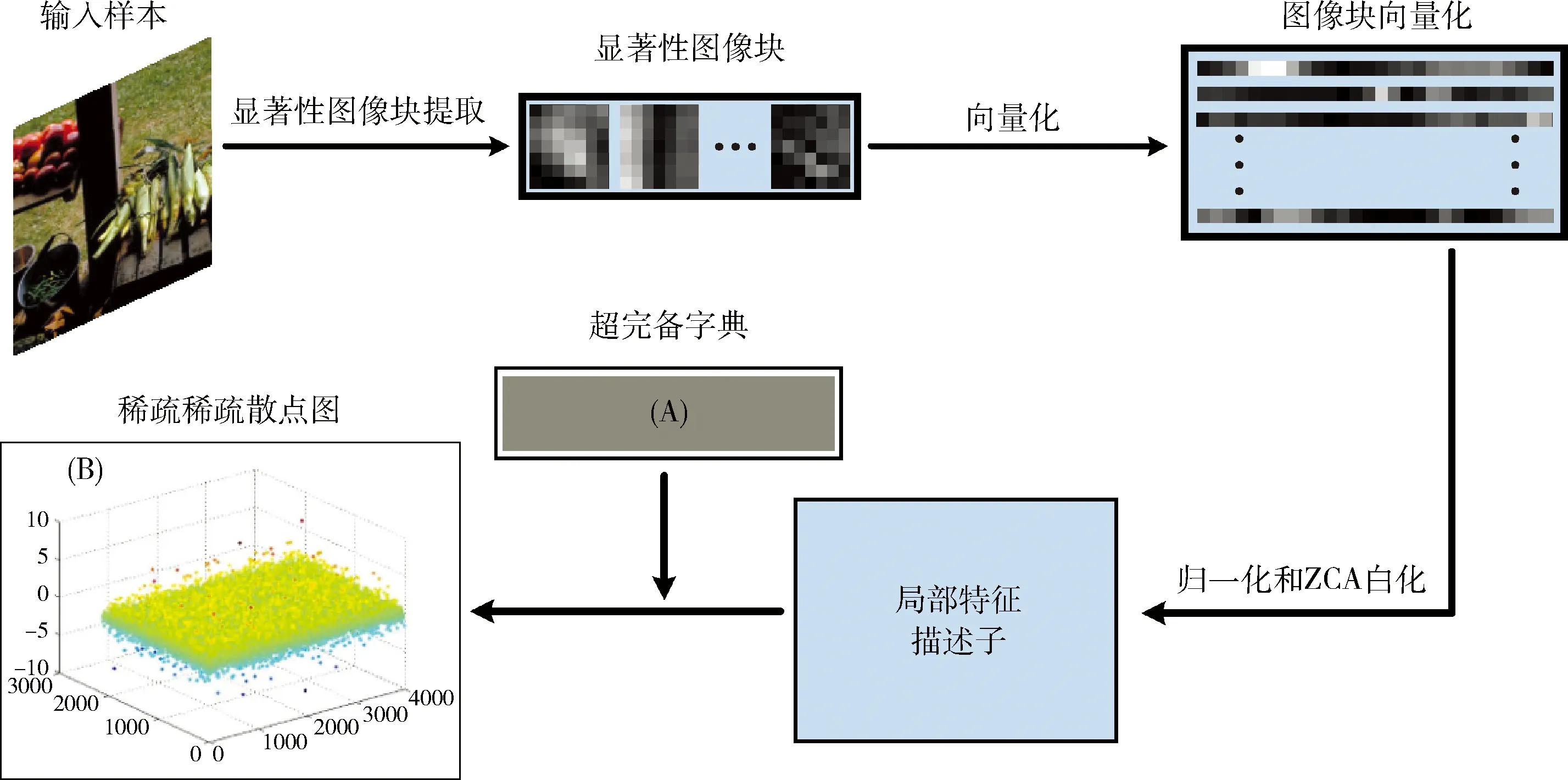
图3 稀疏表达系数求解过程
2.3 Fisher向量编码稀疏系数

2.3.1 高斯混合模型
高斯混合模型的定义为

(3)
其中,x∈RKα,x表示某个局部特征描述子在超完备字典C上的稀疏表示系数;(Θ;X)是用高斯混合模型拟合数据时常用的最大似然函数。该模型重要参数见表1,其参数集为Θ∈{πk,μk,Σk;k=1,…,Kβ}。

表1 高斯混合模型参数说明
2.3.2 Fisher向量编码
Fisher向量通常用作池化图像局部特征后的图像描述算子。它可以看作是Fisher核的特殊或近似表示。假设X=(x1,…,xN) 是一组Kα维特征向量的集合。高斯混合模型的参数集是Θ∈{πk,μk,Σk;k=1,…,Kβ}, 那么每个特征向量xi在第k个模型上的权重可由下列的后验概率给出
(4)
此时第j维 (j∈{1,2,…,Kα}) 特征在第k个高斯模型上的均值偏移μjk和协方差偏移νjk为
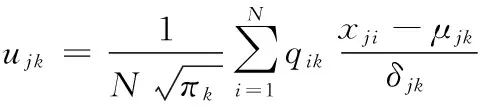
(5)
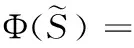
(6)
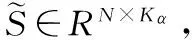
3 实验结果与分析
3.1 实验数据集与实验细节
本文选取LIVE[11]、CSIQ[12]、TID2013[13]作为本文图像质量评价方法(SCAFV)的实验数据库。LIVE库具有5种失真类型,由29个不同场景的982张图片组成;CSIQ库具有6种失真类型,由30个不同场景的866张图片组成;TID2013库具有24种失真类型,由25个不同场景的3000张图片组成。其中JPEG2000压缩、JPEG压缩、高斯模糊、白噪声这4种失真类型为3个库所共有,为了使基于稀疏编码的字典能够高效地表达这3个库中所有的失真类型,训练字典的样本集合需尽量涵盖库中大多数的失真类型,而对图像场景没有要求。实验从3个数据库中随机抽取了150张图像构成字典学习集合,其中也可能包括一些无失真图像,这种字典学习集合能够训练出更具一般性的超完备字典,统一使用此字典完成本文算法在不同数据库上的性能评估实验。为了全面验证SCAFV的主客观一致性,我们首先在 LIVE 库上对SCAFV的重要参数和关键模型进行了讨论,然后在 LIVE、CSIQ、TID2013数据库上进行了一系列实验。
本文选择 Spearman等级相关系数(spearman rank order correlation coefficient,SROCC)、Pearson线性相关系数(Pearson linear correlation coefficient,LCC)、均方根误差(root mean square error,RMSE)这3种指标来对SCAFV的性能进行评估。SROCC衡量质量评价算法客观预测的单调性,LCC、RMSE衡量质量评价算法客观预测的准确性。SROCC、LCC最大值为1,最小值为-1,SROCC值越大说明模型的单调性越好,LCC值越大说明模型预测准确性越高。RMSE则相反,值越小说明模型预测准确性越高。
在评价模型构建中,本章SCAFV评价方法的实验结果均由SCAFV+SVR模型提供,本文使用LibSVM-3.18工具箱完成线性epsilon-SVR预测模型的训练,其中,设置损失函数惩罚因子C为1,λ为0.5。
实验硬件平台为:Intel Core i7-4790 CPU @ 3.60 GHz,8GB RAM,配有NVIDIA Geforce GTX 980M图形处理器。软件平台为:64位Windows7操作系统,MATLAB(R2014a)等。若没做特别说明,均采用80%样本训练,20%样本测试的策略。
3.2 参数设置
本算法中稀疏编码超完备字典尺寸Kα和Fisher向量中用到的高斯混合模型类数Kβ是需要调节的变量,本文的做法是:先用参考文献[7]中的特征各维最大汇总(Max-Pooling)进行实验,确定稀疏编码超完备字典尺寸Kα;在确定Kα以后,调节Fisher向量中的高斯混合模型类数Kβ。实验对比了3个评估标准(SROCC、LCC、RMSE)在LIVE库上的实验结果,每一组对照不同的字典尺寸,包括200、500、1000、2000、3000、4000、5000。实验发现,应用SR显著性检测算法之后,从显著性图像块构建而来的小尺寸字典可以代替大尺寸字典,当稀疏编码字典个数到4000时(此时Fisher向量中用到的高斯混合模型类数Kβ=16),效果趋于稳定。相比于参考文献[7],本算法的小尺寸字典可以达到与之相当的实验效果,这也是本算法的优势所在。
3.3 实验结果分析
该部分选取了当前比较主流的无参考图像质量评价算法进行对比分析。其中包括两种不需要知道人工打分的算法:QAC、IL-NIQE,和5种需要知道人工打分的算法:BIQI、DIIVINE、BLIINDS2、BRISQUE、CORNIA。本文在LIVE、CSIQ和TID2013数据库按80%训练-20%测试比例在样本中随机选取,并将执行了1000次测试后的SROCC、LCC中值结果汇总在表2中。
从表2可以看出,本文算法SCAFV在LIVE 库和TID2013库上的评价效果要优于其它算法,通过与CORNIA的实验结果进行比较可知,在字典原子个数相同情况下,SCAFV指标的实验结果几乎要全面优于CORNIA,证实符合HVS视觉注意特性和稀疏表达特性的SCAFV评价方法能获得更好的主客观一致性。虽然SCAFV在CSIQ库上的测试结果没有在LIVE库和TID2013库上理想,但是SROCC值仍然较高,说明本算法仍能保持很高的主客观一致性。在CSIQ库上的LCC值还有待提升,这是因为CSIQ库中每种失真类型样本之间失真程度的差距比较小,对于失真程度差距小的样本集,训练回归模型时会遇到特征线性可分性差的情况,从而导致模型预测时出现一定偏差。此外,在训练超完备字典的150张样本中,有46张样本来自TID2013,这46张样本几乎涵盖了TID2013上所有失真类型,因此SCAFV对这些失真能够很好地描述,这也说明SCAFV虽然对数据库具有很好的可扩展性,即对各种失真类型保持了很好的预测效果,但这需要建立在一个前提条件下:计算编码系数的超完备字典尽量描述到场景中各种类型的信息,而此条件实际上很难得到满足,这也是基于码本方法的缺点所在。
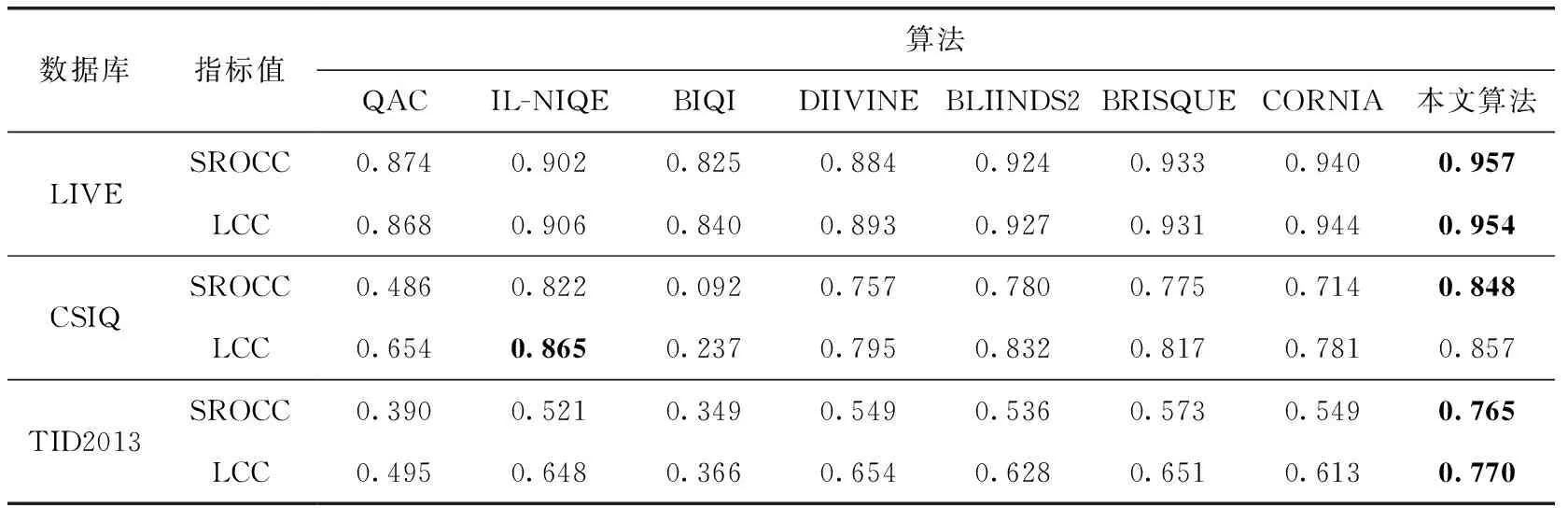
表2 各算法在各数据库上执行1000次随机训练-测试的中值结果
3.4 跨数据库实验及时间复杂度分析
前面实验的训练-预测均在单独数据库上完成,而本节将测试SCAFV方法的跨数据库性能。跨数据库实验是为了评估算法对数据库的独立性,具体操作方式是在某一数据库上训练预测模型,而在其它库上进行质量评估,即训练和测试分别在两个不同的数据库上完成。数据库的独立性能够反映算法的泛化能力,而泛化能力又是衡量算法好坏的一个重要指标,因此,十分有必要对质量评价模型进行跨数据库实验。
本节针对SCAFV评价方法的跨数据库实验在LIVE和CSIQ库上完成。这是因为LIVE库和CSIQ库之间样本的场景信息完全不同,且LIVE库中每种失真类型对应样本之间的失真程度差异较大,而CSIQ库中样本的失真差异较小,因此基于这两种数据库的实验结果更具说服力。表3列出了在LIVE库训练,在CSIQ库测试的SROCC和LCC结果,可以看出本文算法在跨数据库测试中,也能取得较好的效果。

表3 数据库独立性测试:在LIVE库训练,在CSIQ库测试
时间的复杂度往往决定着算法的实用价值,表4给出了各算法在一幅512×512彩色图像上的平均耗时。由于算法中的训练部分以及聚类部分都可以在线下完成,所以本文主要讨论图像预处理和特征提取上所耗费的时间。本算法的时间开销主要在显著性图像块的提取和ZCA白化等预处理操作,利用Fisher向量对稀疏系数进行编码的时间可忽略不计(应用了VLFEAT库中高度优化过的编码函数),算法耗时约3 s左右。分析可知,本算法在时间性能优越的同时也取得了较好的图像质量评价效果。

表4 各算法平均耗时对比
4 结束语
本文针对现有无参考图像质量评价领域存在的字典基数大、特征描述不全面等缺点,提出了一种称为SCAFV的特征提取算子。SCAFV利用显著性信息辅助筛选图像块并生成显著性局部特征描述子,有效剔除了图像冗余信息,论证了结合显著性检测后,建立小尺寸字典也能达到高效的预测结果。随后,利用稀疏编码算法训练字典并计算编码系数,相比聚类和主成分分析的字典,编码系数的高度稀疏性更符合HVS稀疏表达特性,能够提高质量预测性能。另外,在特征提取阶段,SCAFV评价方法采用Fisher向量进行特征编码,使从稀疏系数中得到的特征既能保留系数局部最优信息,又能较完整地保留各个维度的系数信息。最终通过epsilon-SVR算法训练预测模型实现对图像质量的精确评估。在LIVE、CSIQ、TID2013库的实验结果表明,其预测性能不弱于目前比较优秀的评价方法,跨数据库实验部分验证本算法具有不错的泛化能力。
[1]Saad M A,Bovik A C.Blind image quality assessment:A na-tural scene statistics approach in the DCT domain[J].IEEE Transactions on Image Processing,2012,21(8):3339-3352.
[2]Mittal A,Moorthy A K,Bovik A C.No-reference image qua-lity assessment in the spatial domain[J].IEEE Transactions on Image Processing,2012,21(12):4695-4708.
[3]YANG Lingxian,CHEN Heping,CHEN Li.Model of no reference image quality assessment based on steerable pyramid[J].Computer Engineering and Design,2013,34(8):2769-2773(in Chinese).[杨玲贤,陈和平,陈黎.基于可控金字塔的无参考图像质量评价模型[J].计算机工程与设计,2013,34(8):2769-2773.]
[4]Ye P,Doermann D.No-reference image quality assessment using visual codebooks[J].IEEE Transactions on Image Processing,2012,21(7):3129-3138.
[5]Tang H,Joshi N,Kapoor A.Blind image quality assessment using semi-supervised rectifier networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Columbus:IEEE,2014:2877-2884.
[6]Kang L,Ye P,Li Y,et al.Convolutional neural networks for no-reference image quality assessment[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Columbus:IEEE,2014:1733-1740.
[7]Ye P,Kumar J,Kang L,et al.Unsupervised feature learning framework for no-reference image quality assessment[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Rhode Island,America:IEEE,2012:1098-1105.
[8]Wei Z,Borji A,Zhou W,et al.The application of visual salie-ncy models in objective image quality assessment:A statistical evaluation[J].IEEE Transactions on Neural Networks & Learning Systems,2016,27(6):1266.
[9]Hong Z,Ren F,Ding Y.Saliency-based feature learning for no-reference image quality assessment[C]//Proceedings of the IEEE International Conference on Green Computing and Communications.Beijing:IEEE,2013:1790-1794.
[10]Feng Tianpeng,Deng Dexiang,Yan Jia,et al.Sparse representation of salient regions for no-reference image quality assessment[J].Internal Journal of Advanced Robotic Systems,2016,13:1-11.
[11]Sheikh H R,Wang Z,Cormack L,et al.LIVE image quality assessment database release2[EB/OL].[2017-03-15].http://live.ece.utexas.edu/research/quality/.
[12]Larson E C,Chandler D M.Most apparent distortion:Full-reference image quality assessment and the role of strategy[J].Journal of Electronic Imaging,2010,19(1):011006.
[13]Ponomarenko N,Ieremeiev O,Lukin V,et al.Color image database TID2013:Peculiarities and preliminary results[C]//4th European Workshop on Visual Information Proces-sing,2013:106-111.
猜你喜欢
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
小学阅读指南·低年级版(2019年11期)2019-07-01
电子制作(2019年24期)2019-02-23
疯狂英语·新读写(2018年3期)2018-11-29
西南交通大学学报(2018年5期)2018-11-08
苏州科技大学学报(自然科学版)(2017年1期)2017-03-20
知识产权(2016年8期)2016-12-01
创新作文(小学版)(2016年19期)2016-08-22
