
一种基于区域建议网络的图像语义分割方法
2018-03-13 05:18杨志尧彭召意文志强
计算机与现代化 2018年2期
杨志尧,彭召意,文志强
(1.湖南工业大学计算机学院,湖南 株洲 412007;2.智能信息感知及处理技术湖南省重点实验室,湖南 株洲 412007)
0 引 言
图像分割作为计算机视觉领域的核心内容之一,相关的研究工作早在20世纪60年代就已经开始。传统的图像分割算法主要包括阈值法[1]、边界检测法[2]、区域法[3]等。近年来,随着深度学习在图像分类、检测与识别等方面有了重大的进展并逐渐扩展到图像分割领域,图像分割技术在此影响下也有了不少突破性进展。其中,图像语义分割领域因其所具有的重大应用价值越来越受人们的关注。目前,图像语义分割技术在自动驾驶、医学影像分析和地质勘探等多个领域都有着广泛的应用。
传统的图像分割算法往往是基于图像的底层信息,主要针对具有相同颜色、纹理或者形状的图像区域进行分割[4]。因此,当图像所含信息较为复杂时,使用这类分割算法通常达不到预期的分割效果。更为常用的方法则是利用图像中特征相似的相邻像素组成的图像块并结合其他学科或领域的理论和方法来辅助图像分割[5]。例如在图像分割问题中引入图论的理论方法,将对图像的分割转换成对带有权值的无向图的顶点标注问题,从而获得被称为超像素的图像块[6]。
图像语义分割通常需要结合图像所包含的具有某种特定语义的对象的分类信息来辅助图像分割。Ohta等人[7]将语义分割的概念归纳为:为图像中的每个像素赋予一个具有特定语义信息的分类标签。结合区域提取算法的图像语义分割是目前较为流行的方法[8]。
2012年,Krizhevsky等人[9]在Image Net大规模视觉识别挑战竞赛中使用卷积神经网络算法以接近10%的优势击败了其他传统方法,基于深度网络的图像分割方法便层出不穷。2014年,Sermanet等人[10]提出结合滑动窗口算法和卷积神经网络进行图像语义分割的网络框架。同年,Girshick等人[11]提出了基于区域提取的卷积神经网络分割算法,随后He等人[12]通过在网络中加入空间金字塔池化层对算法进行改进。Ren等人[13]通过改进区域提取算法,得到了一个用于提取候选区域的网络结构,即区域建议网络(Region Proposal Network,RPN),该网络有效加快了候选区域的生成效率。但是卷积神经网络存在只能接收和处理固定尺寸图像的局限性,同时卷积神经网络末端的全连接层也耗费了较大的计算资源。因此,Long等人[14]摒弃了传统卷积神经网络中的全连接层并用卷积层取代从而得到了全卷积网络(Fully Convolutional Network,FCN),成为图像语义分割网络的常用框架。
1 图像语义分割网络结构
图像语义分割网络通过区域建议网络提取候选区域,然后使用全卷积分割网络对图像进行语义分割。一般来说,使用单一的全卷积分割网络结构进行图像语义分割得到的结果过于粗糙,并不是很理想。通过区域建议网络提取出的候选区域可以对全卷积网络的分割结果进行精细化处理,得到更为精确的分割图像。
1.1 全卷积神经网络
语义分割网络中的区域建议网络和分割网络均使用的是全卷积网络。全卷积神经网络和卷积神经网络都是包含多个隐藏层的深度神经网络模型,两者的区别在于全卷积神经网络舍弃了全连接层,整个网络均由卷积层构成。因此,全卷积神经网络对输入图像的尺寸没有特殊的要求,无需对输入图像进行裁剪、拉伸等预处理。
全卷积神经网络同样是基于训练数据自主地学习图像特征,其网络结构主要包含了4种基本操作:卷积、池化、非线性变换和逆卷积,由于卷积和池化的过程会丢弃大量的信息,因此逆卷积得到的分割效果较为粗糙。为了获得更加精确的分割效果,将区域建议网络与全卷积网络相结合,从而得到一个联合网络来进行图像语义分割。
1.2 区域建议网络
1.2.1 区域建议网络的构建
采用全卷积网络模型来构建区域建议网络,主要目的是为了便于和全卷积分割网络共享计算资源。实验在Zeiler和Fergus[15]所提出的网络模型上做出修改,得到所需要的全卷积神经网络,即ZF_FCN网络。
区域建议框的产生同样是一个卷积的过程。使用一个n×n的滑动窗口在共享卷积层末端的输出特征图上进行卷积操作,每一个滑动窗口都将作为一个输入被送入一个小型的网络中。该小型网络将传入的特征映射到一个256-d的向量上并将这个向量传输给2个同级的1×1卷积层。这2个卷积层分别为分类层(cls)和回归层(reg)。
滑动窗口的中心位置定义为锚点,通常每个滑动位置对应着3种尺度和3种长宽比,这样每个滑动位置都会有k=9个锚点,每个滑动窗口产生k个区域建议框。因此,回归层会有4k个输出(每个区域建议框的坐标包含4个参数),分类层会有2k个输出(每个区域建议框是否为目标的概率估计)。具体的区域建议网络如图1所示。
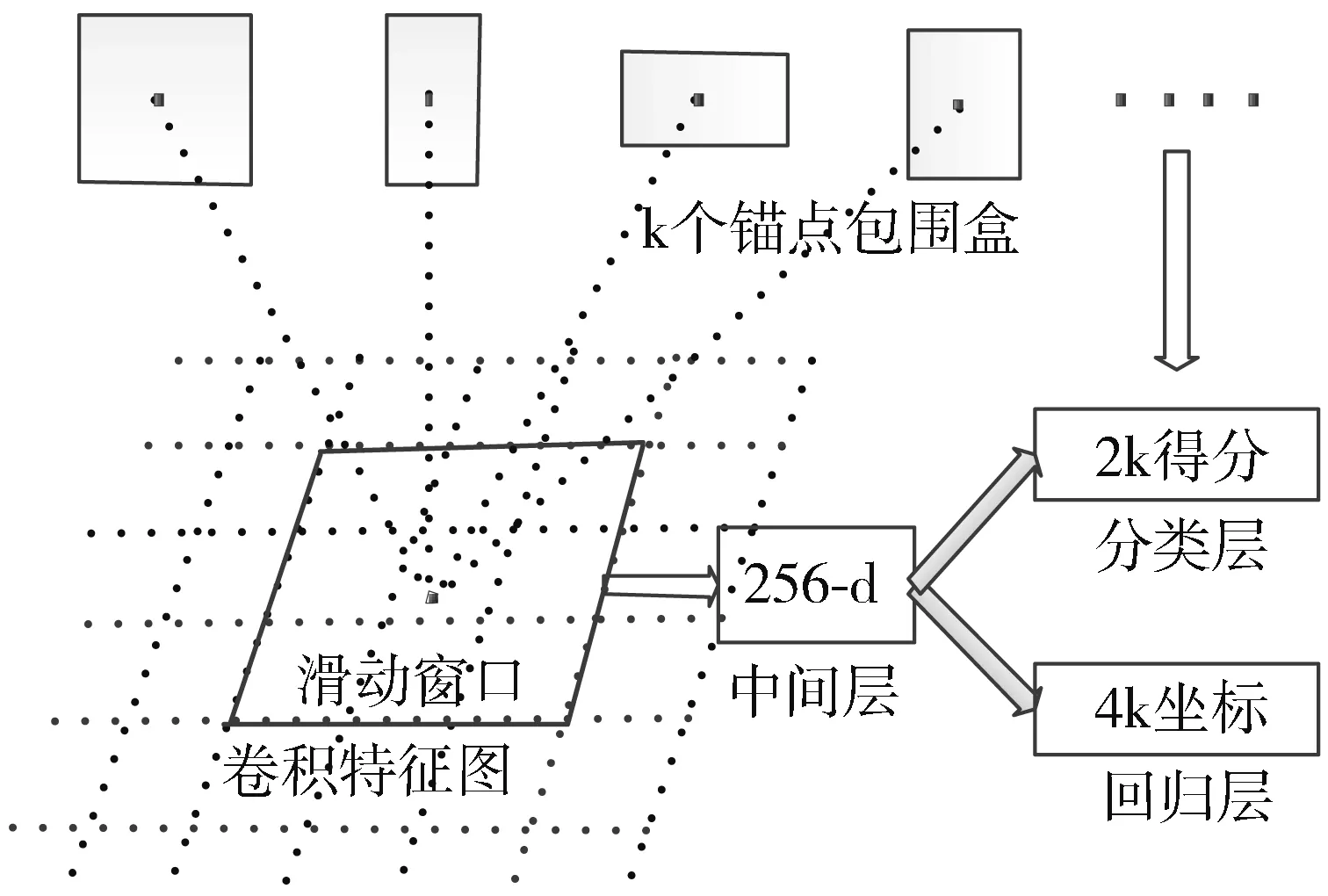
图1 区域建议网络结构图
1.2.2 定义区域建议网络的损失函数
区域建议网络是一个典型的全卷积网络,因此在网络的训练过程中,反向传播算法[16]和梯度下降算法[17]同样适用于区域建议网络。为了训练区域建议网络,使用一个二进制标签来标记一个锚点是否为目标。
对于一张输入图像,其损失函数可定义为:
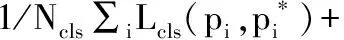
(1)
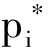
(2)
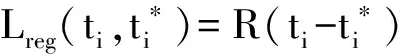
(3)
对于回归部分,参照Girshick等人[18]的论文采用4个坐标,分别为:
(4)
其中,x,y,w,h分别用来标识包围盒的中心位置坐标,宽和高。变量x,xa,x*分别表示预测包围盒、锚点的包围盒、真实的包围盒的x的坐标,对y,w,h也是如此。
1.3 联合的图像语义分割网络
通常,全卷积网络接收整张图像作为输入进行网络的训练和图像的分割,而需要分割的目标对象在图像中的位置和大小并不固定。当目标对象在图像中的尺寸较小时,图像的背景内容在训练的过程中会产生较严重的干扰。同样,在图像的分割阶段也会受到图像背景部分的影响。而区域建议网络的引入,可以较好地解决上述问题。
1.3.1 基本的网络结构
区域建议网络和全卷积分割网络具有共享的卷积层。输入的图像经过这个共享卷积层后生成的特征图不仅会继续沿着全卷积分割网络传播,同时也会传入区域建议网络通过计算处理得到候选区域以及区域得分。然后,采用极大值抑制算法获取排名前n(n通常取100)的得分区域并传入到池化层。在池化层中,区域建议网络输出的区域建议和全卷积分割网络输出的高维特征图相结合,通过上采样方法得到对应的语义分割图像。由区域建议网络和全卷积分割网络组成的联合网络结构如图2所示。
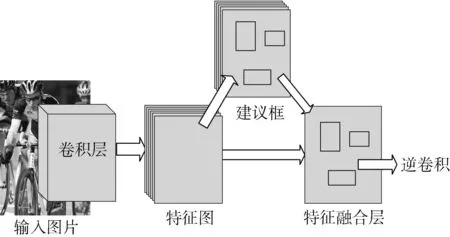
图2 联合网络的结构图
1.3.2 2种网络模型的联合方法
作为一个联合的网络结构,区域建议网络在网络训练阶段和图像分割阶段都起到了较为重要的辅助作用。
在网络的训练阶段,区域建议网络的主要作用在于接收一张完整的图像作为输入并产生一组具有区域得分的区域建议框。区域得分较高的建议框内通常包含更高比例的待分割目标物体,因此使用这类区域建议框所框选的图像区域来训练分割网络,可以使得网络对目标对象的分割更具有针对性。为了获取这类高质量的训练数据,首先要根据区域得分对区域建议框进行排序,利用排名靠前的区域建议框(通常取前10%的区域建议框)在原图像上裁剪获得一组候选区域图像。然后将这组候选区域图像作为输入传入全卷积分割网络,用于分割网络的训练和优化。在这一过程中,共享卷积层产生的特征图像只在分割网络内传输,不再传入到区域建议网络中。
在图像的分割阶段,区域建议网络产生的区域建议框及对应的区域得分会辅助语义分割网络对图像进行分割。这一阶段同样是利用区域建议框所具有的分割目标所占图像比例大,背景图像干扰小的特点。
首先,采用极大值抑制算法获取区域得分排名前n个区域建议框。
然后,分别为这些区域建议框分配相应的权重。在权值的分配过程中,通常会给图像中心位置的像素分配较大的权值,并且像素的权值由中心向四周逐渐降低。本文采用正态分布为区域建议框分配权值,具体函数如公式(5)所示,其中x,y表示区域建议框上对应像素点的位置。
G(x,y)=1/2πσ2e-(x2+y2)/2σ2
(5)
最后,使用这些带权区域建议框与分割网络的输出图像相结合,利用带权区域建议框的区域得分和权值来调整输出图像中对应位置像素所属类别的概率值,从而得到最终的分割结果。
2 语义分割网络的训练
由于区域建议网络和全卷积分割网络是独立训练的,因此语义分割网络训练的关键在于卷积层的共享。实现卷积层共享的方法有多种,如交替训练法、近似联合训练法、非近似联合训练法等。交替训练算法将整个训练过程划分为3个阶段,逐步学习共享的特征,实现卷积层的共享。
区域建议网络的训练阶段,区域建议网络的训练可以使用原始图像数据进行训练,但是该方法的训练周期较长,需要的数据量也很大。通常采用迁移学习方法,用在ImageNet图像库上训练好的模型参数对区域建议网络进行初始化。
全卷积分割网络的训练阶段,使用第一步中区域建议网络生成的候选框来训练一个全卷积分割网络。为了得到更好的训练效果,全卷积分割网络同样可以使用ImageNet图像库的预训练模型参数来初始化。
联合网络相互微调阶段,使用全卷积分割网络的参数再次初始化区域建议网络,不同的是,此次初始化的过程中需要保持共享卷积层的参数不变,只微调区域建议网络的其他层。相同地,保持共享卷积层参数不变,使用区域建议网络的参数再次初始化全卷积分割网络,交替进行上述步骤,即可实现卷积层的共享,从而构建成为一个统一的网络。
3 实验结果与分析
实验中采用的ZF-FCN网络有5个共享卷积层,并在PASCAL VOC 2012图像数据集分别验证ZF_FCN网络和改进后的ZF_RPN_FCN网络对图像的分割效果。主要的评估参数包括像素分类的正确率(Pixel Accuracy)以及分割图像与标准图像的平均交集并集比(Mean IU)。
表1展示了在相同配置环境下,不同的分割方法得到的分割结果。R-CNN网络在进行图像分割时,只是利用简单的线性回归来获取待分割目标的最小边界框,因此它的分割效果远不如基于全卷积网络的语义分割方法。对比ZF_RPN_FCN网络和FCN_8s网络可以看出,在像素分类准确度和分割效果上,ZF_RPN_FCN网络都要好于FCN_8s网络。
表1 不同网络的图像分割效果对比(%)
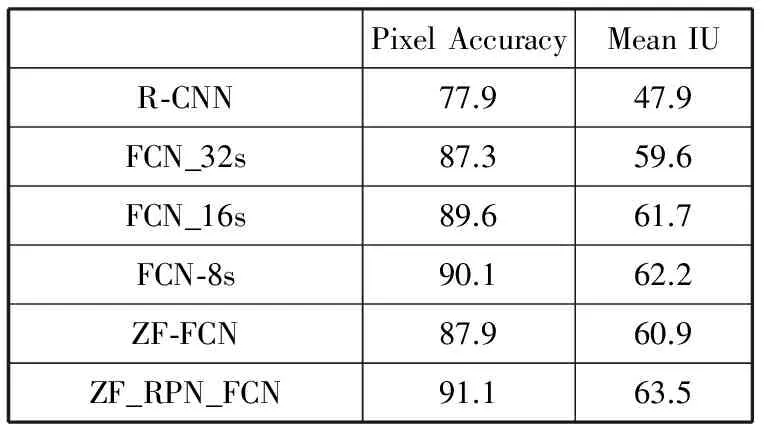
PixelAccuracyMeanIUR⁃CNN77.947.9FCN_32s87.359.6FCN_16s89.661.7FCN⁃8s90.162.2ZF⁃FCN87.960.9ZF_RPN_FCN91.163.5
在对图像特征的抽象和提取方面,ZF_RPN_FCN网络和FCN_8s网络采用了不同的策略和方法。FCN_8s网络是在FCN_32s网络和FCN_16s网络的基础上,逐步实现对图像特征的抽象和提取。同时,FCN_8s还利用全卷积网络中不同层之间的特征融合来实现对图像更精确的分割。因此从表1可以看出,FCN_32s网络到FCN_16s网络再到FCN_8网络,像素分类准确率和平均交集并集之比都在逐渐提高。
与FCN_8s网络不同的是,ZF_RPN_FCN网络是在ZF_FCN网络的基础上,通过引入区域建议网络来更好地实现对图像特征的抽象和提取。改进后的ZF_RPN_FCN网络的像素分类正确率提高了3.2%,而且平均交集并集之比也提高了2.6%。通过与FCN_8s网络的分割结果对比可以看出,ZF_RPN_FCN网络对图像的分割效果要稍优于FCN_8s网络。这说明,ZF_RPN_FCN网络有着不弱于FCN_8s网络的图像特征提取能力,而且其实现过程要比FCN_8s网络更为简易。同时,由于区域建议网络产生的建议框对图像语义分割有较好的辅助作用,这使得ZF_RPN_FCN网络对像素的分类和图像的分割都更加的精确。
为了更加直观地展示改进后网络的分割效果,将图像分别使用ZF_FCN网络和ZF_RPN_FCN网络进行分割,得到分割图像的结果如图3所示。对比标准分割图可以看出,ZF_FCN网络的分割结果较为粗糙,虽然分割得到了飞机的整体轮廓,但细节上缺失明显。而改进后网络的分割结果相对来说更加精细,ZF_FCN网络分割时所忽略的飞机尾翼在ZF_RPN_FCN网络分割得到的图像中有一定的体现,因此最终的分割效果也更好。

图3 算法分割示意图
4 结束语
如今,深度学习网络在图像语义分割领域上的应用已经成为主流。卷积神经网络在图像的特征提取和抽象等方面有着得天独厚的优势,但是在图像的细节处理方面也有一定的不足。如何将传统图像分割算法与深度学习网络更好地融合在一起,从而获得高质量的分割结果成为图像分割领域一个重要的研究方向。
[1] Ostu N. A threshold selection method from gray-level histograms [J]. IEEE Transactions on Systems Man & Cybernetics, 1979,9(1):62-66.
[2] Muthukrishnan R, Radha M. Edge detection techniques for image segmentation[J]. International Journal of Computer Science & Information Technology, 2011,3(6):259-267.
[3] Adams R, Bischof L. Seeded region growing[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1994,16(6):641-647.
[4] 魏云超,赵耀. 基于DCNN的图像语义分割综述[J]. 北京交通大学学报, 2016,40(4):82-91.
[5] 姜枫,顾庆,郝慧珍,等. 基于内容的图像分割方法综述[J]. 软件学报, 2017,28(1):160-183.
[6] Ren Xiaofeng, Malik J. Learning a classification model for segmentation[C]// Proceedings of the 9th IEEE International Conference on Computer Vision. 2003:10.
[7] Otha Y, Kanade T, Sakai T. An analysis system for scenes containing objects with substructures[C]// Proceedings of the 4th International Joint Conference on Pattern Recognitions. 1978:752-754.
[8] 张继昊. 基于SOFM自组织特征映射网络的图像语义分割与标识[D]. 上海:上海交通大学, 2010.
[9] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]// Proceedings of the 25th International Conference on Neural Information Processing Systems. 2012:1097-1105.
[10] Sermanet P, Eigen D, Zhang Xiang, et al. Overfeat: Integrated recognition, localization and detection using convolutional networks[J]. Computer Science, 2013:arXiv:1312.6229.
[11] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2014:580-587.
[12] He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2015,37(9):1904-1916.
[13] Ren Shaoqing, He Kaiming, Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017,39(6):1137-1149.
[14] Shelhamer E, Long J, Darrell T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2014,39(4):640-651.
[15] Zeiler M D, Fergus R. Visualizing and understanding convolutional networks[C]// European Conference on Computer Vision. 2014:818-833.
[16] Baydin A G, Pearlmutter B A, Radul A A, et al. Automatic differentiation in machine learning: A survey[J]. Computer Science, 2015.
[17] Bottou L. Large-scale machine learning with stochastic gradient descent[C]// Proceedings of COMPSTAT’2010. 2010:177-186.
[18] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2014:580-587.
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
北京航空航天大学学报(2021年9期)2021-11-02
开放教育研究(2020年2期)2020-03-31
电子制作(2019年13期)2020-01-14
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
中国与非洲(法文版)(2017年10期)2017-11-23
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
