
基于Attention-based C-GRU神经网络的文本分类
2018-03-13 05:18王移芝
计算机与现代化 2018年2期
杨 东,王移芝
(北京交通大学计算机与信息技术学院,北京 100044)
0 引 言
文本分类作为自然语言处理中的经典任务,包括文本预处理、特征提取以及分类器训练等过程。其中最关键的问题是特征提取,传统的方式为词袋法或者空间向量模型,然而这些方式没有考虑文本的语序或上下文信息,且这种浅层表示方法在处理过程中会面临着稀疏性、维度灾难以及丢失大量文本信息等问题。
为了克服浅层表示的缺点,Word Embedding[1]这种词嵌入表示方法被提出,并且取得了良好的表现。同时,深度学习方法不仅在语音识别[2]和机器翻译[3]等领域取得了突出的成绩,在自然语言处理任务中也表现出色。LeCun等人[4]提出了将CNN应用于文本处理,采用卷积层和降采样来提取特征,通过共享权重减少模型参数数量,提高了文本分类的分类效果,CNN是一种典型的空间神经网络。
Mikolov等人[5]提出将基于时间序列的深度神经网络RNN应用于文本分类任务,该模型在隐层中加入了自连接和互连结构,这样当前的节点状态就可以影响下一个节点的状态。RNN在学习长期依赖信息时会面临梯度爆炸或梯度消失等问题,为了避免长期依赖,LSTM和GRU等众多改进结构及变体被提出,其把记住长期消息作为模型的默认行为,而不需付出很大代价去获得。
还有一些人提出了混合模型,例如Lai等人[6]提出了RCNN混合模型,该模型结合了CNN和RNN模型,通过循环网络结构去学习上下文信息,之后采用动态池化层提取文本的关键组成部分,从而提高文本分类的效果。
Attention机制是一种资源分配机制,即在某个时刻你的注意力总是集中在屏幕的某个固定位置而不去关注其他部分。Attention机制最初只应用于计算机视觉中的图片识别任务中,随后被应用于图文转换。在自然语言处理中,Attention机制通常结合Encoder-Decoder模型使用,应用场景非常广泛。
本文设计的混合模型Attention-based C-GRU所提取的深层次特征表示,既考虑了上下文词序关系,又能反映句中关键词的影响权重,通过该模型进一步优化了特征提取过程,并提高了分类器的分类效果。在相关数据集上与对比模型及表现最优方法相比,实验表明本文的模型表现出更好的分类效果。
1 相关工作
最近几年随着深度学习网络优化方法的突破,基于神经网络的表示方法也取得了很大的发展,在此基础上许多基于神经网络的文本分类任务获得了更大提升,其中CNN和RNN是最流行的模型。
CNN广泛用于文本分类是因为其与N-grams模型很类似,不同之处在于CNN拥有卷积层和池化层,其不仅可以减少训练参数,而且有能力提取文本的更高层次的文本特征。为了突出CNN的特性,许多CNN的优化结构也被提出,Kim等人[7]提出通过动态窗口和2个词向量频道的CNN结构来改进特征提取过程,Mou等人[8]则提出了基于树状结构的卷积模型来提高特征提取表现。
RNN用来处理序列数据,该模型具有处理变长输入和发掘长期依赖的能力。许多RNN的变体被提出用来克服RNN的不足之处,并且获得了很好的表现。例如Koutnik等人[9]提出了CW-RNNs,其使用时钟频率来驱使RNN获得优于序列LSTM的结果表现,Cho等人[10]提出GRU模型,该模型采用更新门和重置门处理节点的隐层状态和新记忆内容来获得最终的记忆内容。
基于Attention机制的学习模型可以有效应对信息冗余和信息丢失等问题。Attention是通过计算历史节点对当前节点的影响权重,其本质就是注意力分布概率。Luong等人[11]在机器翻译中定义了全局Attention和局部Attention的概念。
本文设计一种名为Attention-based C-GRU的模型,该模型将CNN中的卷积层和GRU以统一的架构组合,并且在卷积层与GRU之间引入Attention机制。该模型的工作原理如下:首先通过卷积层去捕获初步的特征表示,之后利用Attention机制和GRU模型,在GRU隐层获得具有关键词区分度的深层特征表示,最后将隐藏状态输入到Softmax进行回归完成分类。该模型不仅融合了CNN和GRU的模型优势,而且通过Attention机制计算输入节点的注意力概率,进一步优化语义特征表示。通过在主题分类、问题分类及情感分类等3类文本分类任务的实验表明,本文提出的混合模型能够突出关键信息,挖掘更加丰富的语义,获得更佳的分类表现。
2 模 型
本文提出的模型结构如图1所示。首先,模型通过卷积层模块来提取初步的特征表示,然后通过Attention机制和GRU模块来对初步特征表示进行关键词加强和进一步的优化,最后在GRU的隐层生成最终的深层特征表示,并将其输入到Softmax中进行回归,完成分类。
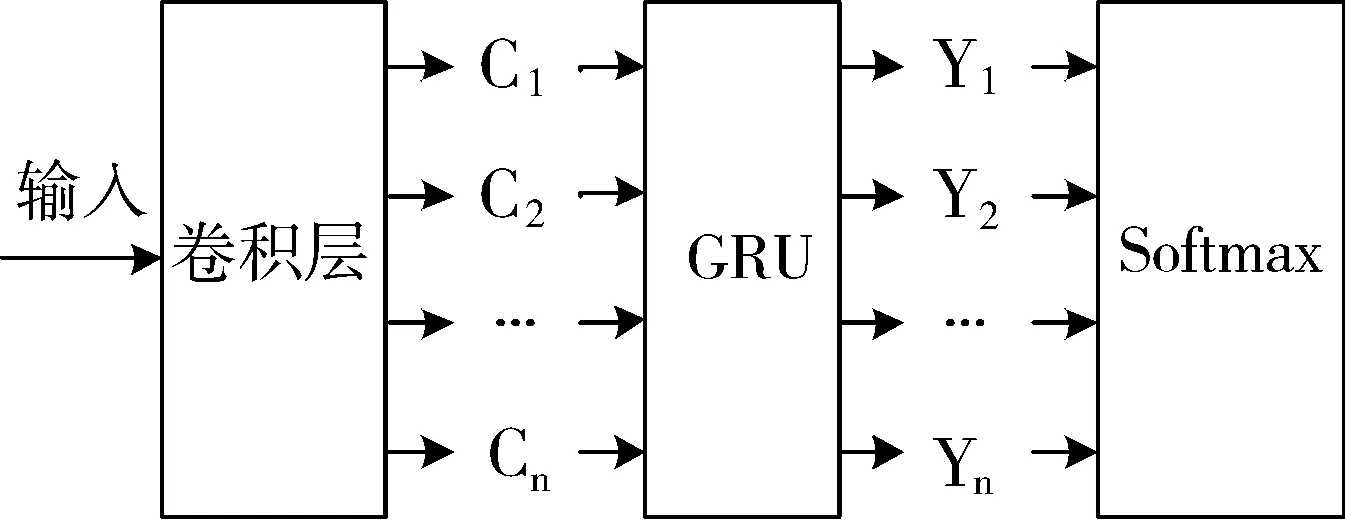
图1 Attention-based C-GRU文本分类模型架构图
2.1 卷积层特征提取
模型的第一个模块是通过CNN中的卷积层来提取初步特征表示。该模块中新定义一个向量:区域序列向量RSV,通过该向量保持与输入语句对应的原始序列,这为指定序列输入的GRU模型提供了合理的输入。在一维卷积层中定义过滤器用来提取不同位置的局部特征表示。其中wj∈RD表示句中第j个单词的D维词嵌入表示,x∈RL×D表示长度为L的输入语句的表示,f∈Rk×D为在卷积层长度为k的过滤器。用Si标记区域序列向量,其构成是由输入语句i位置开始的连续k个词的词嵌入表示组构成,定义如下:
si=[wi,wi+1,…,wi+k-1]
(1)
对输入语句中的位置i,通过卷积层的过滤器对其进行处理,产生一个新的特征映射c∈RL-K+1,转换公式如下:
ci=ReLU(si∘ f+θ)
(2)
其中∘ 表示元素级相乘,θ∈R表示偏移量,ReLU函数是一种经典的非线性激活函数。在该模块中,采用若干个相同长度的过滤器来生成特征,然后将这些特征表示成一个如下的特征矩阵:
(3)
该矩阵中行向量表示通过第n个过滤器产生的特征向量映射,列向量表示n个过滤器在i位置产生的多个区域序列向量表示。矩阵中的所有列向量构成输入语句的顺序语义表示,作为后面GRU的输入向量。在该模块中只使用卷积层,而不使用池化层的原因是,池化层会破坏句子的原始语序,否则经过池化层处理形成的输入表示对指定序列输入的GRU是不合理的。
2.2 引入Attention机制
Attention机制在NLP中通过计算注意力分布概率,可以突出输入对输出的影响,优化传统模型。本文模型中通过在卷积层模块与GRU模块之间引入Attention机制,生成含有注意力概率分布的语义编码,并生成最终的特征向量,由此突出输入语句中不同的关键词对不同输出的区分化影响作用,引入Attention机制后的混合模型结构如图2所示。

图2 引入Attention机制的模型结构图
在本文提出的模型中每一个输出元素按公式(4)计算得到:
yi=F(Ci,y1,y2,…,yi-1)
(4)
从公式中可以看出每一个输出都有一个对应的语义编码Ci,该编码是在卷积层模块中根据输入语句的分布生成的,具体而言,Ci由输入语句x1,x2,x3在卷积层中经过卷积运算后的隐层状态进行非线性转化得到的,转化公式如下:
(5)
其中S(xj)表示经过卷积模块的隐层状态值,即第j个词的词嵌入表示经过卷积层处理所对应的隐层状态,T表示输入序列元素的个数。aij表示输入j对输出Yi的注意力分布概率,定义如下:
(6)
eij=score(si-1,hj)=vtanh(Whj+Usi-1+b)
(7)
其中eij是由Babdanau等人[12]提出的一种校验模型,其本质为第j个输入对第i个输出的影响力评价分数,hj为卷积层模块中第j个输入的隐层状态,si-1为上一步GRU的输出,W和U是权重转化矩阵,b为偏移量。最终形成的Attention语义编码会作为GRU模块的输入,生成最后的深层特征表示,突出了关键信息的语义表示和区分化作用。
2.3 Gated Recurrent Unit(GRU)模型
传统的RNN模型在处理长期依赖问题时面临着梯度爆炸或者梯度消失的问题,为此很多改进结构被提出,其中作为一种经典的改进模型,GRU在很多任务中表现良好,GRU模型结构如图3所示。
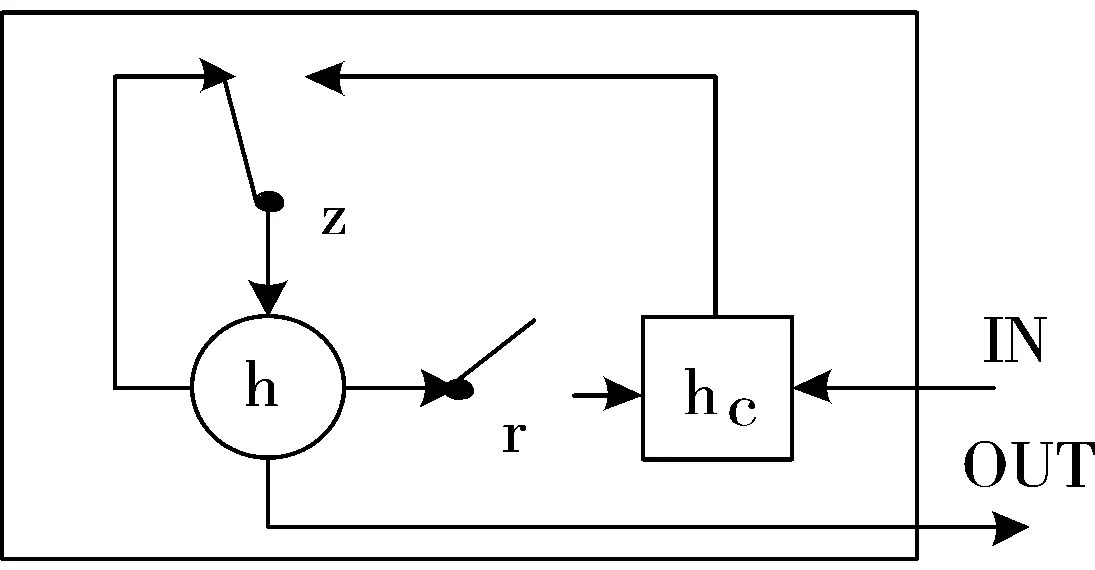
图3 GRU模型结构
图3中r,z分别表示重置门和更新门,h和hc表示激活状态和候选激活状态。可以看出该模型处理信息流是通过内置在结构单元中的门结构来完成的,GRU结构中t时刻的激活状态ht:
ht=(1-zt)ht-1+zthc
(8)
其中ht与前一个时刻的激活状态ht-1是线性相关的,公式(8)中zt表示更新门状态,zt和候选激活状态hc的计算如下:
zt=σ(Wzxt+Uzht-1)
(9)
hc=tanh (Wxt+U(rtΘht-1))
(10)
rt=σ(Wrxt+Urht-1)
(11)
公式(10)中rt表示重置门。GRU相比于LSTM有更少的参数,更简单的结构,且更容易收敛,所以选择GRU作为最后一层去提取深层的特征表示。通过如上所述的模型,可以获得一种深层次特征表示,最后采用Softmax进行回归获得最终的文本分类结果。
3 实验设置
分别在主题分类、问题分类和情感分类这3类文本分类任务上对提出的Attention-based C-GRU模型进行评估,对应的数据集分别为20Newsgroups,TREC以及SST-1数据集。本章分别从数据集和实验设置2个方面进行阐述。
3.1 数据集
1)20Newsgroups。
该数据集包含20组不同主题的英文新闻数据,目前共有3个版本,本文选取共有18828篇文档的第三个版本,以及采用按照类别相似合并的6大类划分分类标签。
2)TREC。
该数据集是一个经典的问题分类语料集,这里使用Silva等人的标准TREC[13],它将所有的问题分为6类,分别是位置、人类、描述、实体、数字和缩写,共包含5452条带有问题标签的训练集和500个问题的测试集。
3)SST-1。
该数据集为情感分类数据集,共包含11800条电影评论语句。本文采用Socher标记的语句情感分类版本[14],其将数据集按8544,1101,2210划分为训练集、开发集和测试集,标签设置共有非常积极、积极、中性、消极和非常消极5类。
3.2 实验设置
在TensorFlow平台上对本文的模型进行实验,该平台集成了CNN,RNN以及LSTM等深度学习模型,此外它也支持例如逻辑回归等其他算法。因为除SST-1数据集外,其他2个数据集没有预定义训练集、开发集、测试集的划分,所以对20Newsgroups数据集采用7:1:2的比例随机分为训练集、开发集、测试集;对TREC数据集,随机选取训练集10%的语料作为开发集,具体划分情况如表1所示。
表1 数据集信息划分表
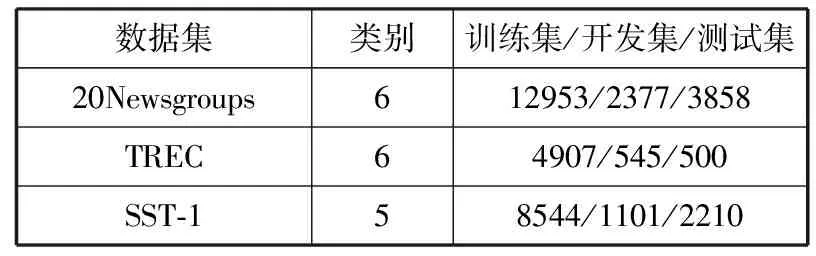
数据集类别训练集/开发集/测试集20Newsgroups612953/2377/3858TREC64907/545/500SST⁃158544/1101/2210
对语料集利用Stanford Tokenizer进行预处理,并且把数据集中的所有字符全部转化为小写,所有单词通过Word2Vec处理成50维的词嵌入表示。
模型中第一个模块是卷积层模块,因为卷积层要求是固定长度的输入,为此定义一个阈值maxsize来表示输入语句所允许的最大长度。通过阈值对输入语句进行处理,对于语句长度比maxsize小的句子,在句尾通过填充一定数量特殊的字符来格式化语句;对于长度比maxsize大的句子,可以将句末多于阈值长度的句子清除掉。通过以上措施,得到固定长度的输入语句。除此之外,设定以下参数:区域序列向量的长度设为5,过滤器的数量设为2。
模型中的下一个模块是基于Attention机制的GRU模块,本文定义该模块中只有1个隐层状态,隐层节点数量为256,学习率为0.01,batch_size为20。GRU的隐层状态作为Softmax的输入,分类器中检测间隔步数设为100,batch_size为20,优化方法采用随机梯度下降法。
将本文提出的模型与文本分类常用模型及3个数据集上表现最优的方法进行对比,采用准确率和F1值作为评价指标,来验证本文模型的有效性。以下为对比模型及各个数据集的最优方法:
1)CNN。Kim等人提出采用CNN进行语义分类,而且提出了很多改进结构,并列举了详细的调参过程。在此选用该模型作为对比试验,它包括卷积层,动态池化层和Softmax回归分类。
2)GRU。该模型由Cho等人[15]提出,是RNN的改进模型,它的参数相对于LSTM更少,而且在收敛方面表现更优。采用该模型作为对比试验,分类过程包括GRU特征提取,然后Softmax进行分类。
3)Attention-based LSTM。该模型由张冲[16]提出,首先通过Word Embedding获得输入语句的词嵌入表示,之后利用结合Attention机制的LSTM模型进行特征提取获得深层特征表示,将其输入到Softmax中完成分类。
4)HDBN。闫琰等人[17]提出了将深度玻尔兹曼机(DBM)和深度置信网络(DBN)混合的HDBN模型,该模型利用底层的DBM对文档进行去噪降维,利用高层的DBN进行特征抽取形成高层次文本表示,然后采用Softmax作为分类层,该模型目前是20Newsgroups六大类划分数据集上表现最优的模型。
5)S-LSTM。该模型由Zhu等人[18]提出,将LSTM模型拓展到树结构,并通过记忆单元反映历史信息。目前该模型是SST-1数据集上表现最优的模型。
6)SVMs。该模型由Silva等人提出,是TREC数据集上表现最优的模型,它是一个基于规则的问题分类器,通过结合了uni-bi-trigrams,POS,语义树等众多特征的紧凑特征空间来进行匹配,获取更加准确的分类。
4 结果与分析
实验结果如表2和表3所示。
表2 数据集分类正确率/%
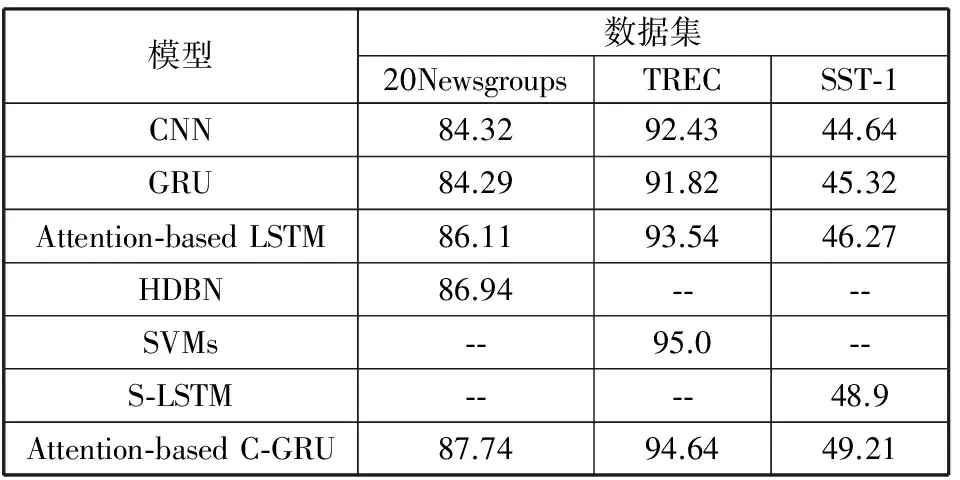
模型数据集20NewsgroupsTRECSST⁃1CNN84.3292.4344.64GRU84.2991.8245.32Attention⁃basedLSTM86.1193.5446.27HDBN86.94⁃⁃⁃⁃SVMs⁃⁃95.0⁃⁃S⁃LSTM⁃⁃⁃⁃48.9Attention⁃basedC⁃GRU87.7494.6449.21
表3 数据集分类F1值/%

模型数据集20NewsgroupsTRECSST⁃1CNN85.3485.7846.71GRU85.6184.2247.23Attention⁃basedLSTM87.7382.4348.45Attention⁃basedC⁃GRU89.2883.8650.87
表2以准确率作为评价指标,表3以F1值作为评价指标,将本文提出的模型与对比模型及各数据集上表现最优的方法作对比。从整体来看,在20Newsgroups和SST-1这2个数据集上,本文提出的模型与对比实验相比均表现出很好的准确率,F1值提升,而且胜过了各个数据集上表现最优方法;在TREC数据集上,本文模型的正确率虽然没有胜过最优结果,但也与之较为接近。由此证明本文提出的模型在文本分类任务的有效性。
将本文模型与Attention-based LSTM模型进行对比,在3个数据集上正确率、F1值均有很好的提升,这说明混合模型在一定程度上可更好地弥补单一深度学习模型CNN,LSTM或GRU所缺失的学习能力。
在TREC数据集的实验中,本文模型的准确率并没有胜过最优模型,F1值也低于CNN,GRU等对比实验。通过分析数据集的特点以及本文模型对不同数据集的优化程度,可以发现20Newsgroups和SST-1数据集的平均句长分别为20和19,而TREC数据集的平均句长为10,且在多组对比实验中本文模型在前者的优化程度要明显大于后者。由此对本文模型进一步分析,模型中的Attention机制和GRU都是基于历史节点对当前节点的影响,而在文本特征提取的过程中,当文本平均句长太短时,无法充分发挥本模型的学习能力,由此说明本文设计的模型对于长文本分类提升效果更加明显,更能发挥本文模型能够学习长期信息的特性。由此得出,该模型的使用场景更适合于新闻文本类的长文本分类,而不适应于微博、推特等短文本类分类任务。
5 结束语
本文提出了一种新颖的混合模型Attention-based C-GRU,并将其在主题分类、问题分类及情感分类3个文本分类任务上进行评估。通过与目前比较流行的几种模型以及最优方法的对比实验,表明本文模型可以考虑上下文信息,获得更深层次的特征表示,不仅如此,引入的Attention机制可以捕获输入节点对输出节点的影响力度,更加丰富语义,减少特征提取过程中的信息丢失问题。
在未来的工作中,笔者将继续探究类似于改进Attention计算方法的优化方法,使得文中的混合模型在文本分类中获得更好的表现,并将该模型应用于其他的场景中。
[1] Bengio Y, Dvcharme R, Vincent P, et al. A neural probabilistic language model[J]. Journal of Machine Learning Research, 2003,3(6):1137-1155.
[2] Graves A, Mohamed A R, Hinton G. Speech recognition with deep recurrent neural networks[C]//2013 IEEE International Conference on Acoustics, Speech and Signal Processing. 2013:6645-6649.
[3] Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems. 2014:3104-3112.
[4] Lecun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998,86(11):2278-2324.
[5] Mikolov T, Sutskever I, Chen Kai, et al. Distributed representations of words and phrases and compositionality[C]// Proceedings of the 26th International Conference on Neural Information Processing Systems. 2013:3111-3119.
[6] Lai Siwei, Xu Liheng, Liu Kang, et al. Recurrent Convolutional neural network for text classification[C]// The 29th AAAI Conference on Artifical Intelligence. 2015,333:2267-2273.
[7] Kim Y. Convolutional neural networks for sentence classification[J]. Computer Science, 2014: arXiv:1408.5882.
[8] Mou Lili, Peng Hao, Li Ge, et al. Discriminative neural sentence modeling by tree-based convolution[J]. Computer Science, 2015: arXiv:1504.01106.
[9] Koutnik J, Greff K, Gomez F, et al. A clockwork RNN[L]. Computer Science, 2014: arXiv:1402.3511.
[10] Cho K, Merrienboer B V, Gulcehre C, et al. Learning Phrase representations using RNN encoder-decoder for statistical machine translation[J]. Computer Science, 2014: arXiv:1406.1078.
[11] Luong M T, Pham H, Manning C D. Effective approaches to attention-based neural machine translation[J]. Computer Science, 2015: arXiv:1508.04025.
[12] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. Computer Science, 2014: arXiv:1409.0473.
[13] Mendes A C, Wichert A. From symbolic to sub-symbolic information in question classification[J]. Artificial Intelligence Review, 2011,35(2):137-154.
[14] Socher R, Perelygin A, Wu J, et al. Recursive deep models for semantic compositionality over a sentiment treebank[C]// Conference on Empirical Methods in Natural Language Processing (EMNLP 2013). 2013:1631-1642.
[15] Collobert R, Weston J, Bottou L, et al. Natural language processing(almost)from scratch[J]. Journal of Machine Learning Research, 2011,12(1):2493-2537.
[16] 张冲. 基于Attention-Based LSTM模型的文本分类技术的研究[D]. 南京:南京大学, 2016.
[17] Yan Yan, Yin Xu-Cheng, Li Sujian, et al. Hybrid deep belief network[J]. Computational Intelligence and Neuroscience, 2015(5):650527:1-650527:9.
[18] Zhu Xiaodan, Sobhani P, Guo Hongyu. Learning document Semantic representation with long short-term memory over recursive structures[C]// Proceedings of the 32nd International Conference on International Conference on Machine Learning. 2015:1604-1612.
猜你喜欢
浙江大学学报(理学版)(2022年4期)2022-07-25
复旦学报(自然科学版)(2022年1期)2022-06-16
新世纪智能(语文备考)(2020年4期)2020-07-25
电子制作(2019年15期)2019-08-27
人民珠江(2019年4期)2019-04-20
电子制作(2018年19期)2018-11-14
铁路计算机应用(2018年5期)2018-06-01
自动化学报(2017年11期)2017-04-04
噪声与振动控制(2015年4期)2015-01-01
小学生·多元智能大王(2014年6期)2014-07-09
