
基于相关反馈的时间序列相似性搜索
2018-03-13 07:23张鹏程王继民
计算机与现代化 2018年2期
刘 琪,张鹏程,王继民
(河海大学计算机与信息学院,江苏 南京 211100)
0 引 言
数据挖掘是从大型数据库的数据中提取人们感兴趣的、隐含的和事先未知的知识的过程[1]。现实中,绝大部分的数据都是时序数据,因此,从时序数据中挖掘潜在的有用知识具有重要的理论和实践意义。时序数据就是带有时间标签的一系列观测值,观测值可能会随时间变化而变化。针对时序数据的挖掘研究,主要包括时序数据的关联、分类、聚类、序列模式挖掘、相似搜索以及预测,其中,相似性检索是其他研究的重要基础。相似性检索由Agrawal[2]首次提出,广义的相似性搜索是在时间序列数据集中发现相似的变化模式。例如,根据各种商品的销售记录,找出相似的商品销售模式,帮助制定相似的销售策略[3];找出自然灾害发生的相同前兆,实现对自然灾害进行预报研究等[4]。
传统时间序列相似性搜索,先提取数据特征以降低数据维度[5-7],然后对特征数据建立索引[8-10],最后基于相似性度量函数[11-13],在索引结构中检索与查询序列相似的序列,并将结果展示给用户。而实际应用中,用户开始时可能并不能明确描述所要查询的序列,因此一次检索的结果往往不能满足用户的需求。基于反馈的策略是,通过用户对查询结果的反馈来修正查询系统,以提高查询精度以及用户的满意度。
相关反馈技术最早应用于信息检索领域,Keogh等人1998年在文献[14]中首次将相关反馈引入到时间序列中,由用户对查询结果设置不同的权值,表示其与查询序列相似或不相似程度的高低,通过反馈与给定序列叠加产生新的查询序列,再次进行查询。文献[15]提出一种基于多样化相关反馈的时间序列搜索方法,对用户标注的相关序列采用MMR方法[16]保证查询结果的多样性,然后组合产生新查询序列并再次进行检索,通过查询结果的多样性保证出现贴近用户意向的结果。
上述的几种时间序列反馈方法均限于正相关反馈,忽略了负相关序列的价值。Wang等人[17]针对由于查询主题较少造成查询困难的情况,在文本检索领域提出一种负相关反馈学习的方法,要求查询结果向量不但要与查询向量相似,同时要尽量与负相关向量不相似。Peltonen等人[18]提出了一种基于机器学习的负反馈信息检索系统,允许用户直接在交互式可视界面上进行正负反馈,研究表明负相关反馈同样也可以提高检索效率。本文在时间序列相似性领域,提出一种基于相关反馈的时间序列相似搜索方法。
1 基于相关反馈的时间序列相似性检索
1.1 基于向量模型的反馈算法
基于向量模型的反馈算法一般通过查询修改来实现,查询修改由Van Rijsbergen在1986年首次在信息检索领域提出[19]。通过对原查询进行修改,并反馈给查询系统重新查询,以提高系统检索性能,查询扩展技术已经成为改善信息检索的查全率和查准率的关键技术之一。
1)Rocchio算法。
经典的反馈算法是由Rocchio在SMART系统[20]中提出,其修改查询向量的公式如下:
(1)
其中,qnew是新的查询向量,q是原始向量,Dr是已知的相关文档集合,Dnr是已知的不相关文档集合,α,β及γ是三者的权重,能够控制新的查询向量和原始查询向量之间的平衡,这些权值的最优值可以凭经验或对数据的认识进行赋值,也可以通过实验确定。
2)Ide dec-hi算法。
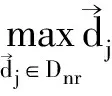
(2)
3)负反馈。
上述的2种反馈算法都较大程度地依赖正相关反馈,当查询主题较为困难即正相关样本很少或没有时,难以发挥作用。Wang等人[17]针对这种较为极端的情况提出了一种负相关反馈的算法,该算法通过分别建立正查询(依据查询向量进行相似性度量)和负查询(由负相关向量组成查询向量,并依据它进行相似度量),最后通过组合得到相似程度。如公式(3)所示,其中D表示待查文档向量,Q表示原始查询向量也是正查询向量,S(Q,D)为正查询的相似结果,Qneg表示负查询向量,S(Qneg,D)为负查询的相似结果,Scombine(Q,D)为最终的Q和D相似程度。由该公式可以看出要想D和Q相似程度高,则D必须远离Qneg。
Scombine(Q,D)=S(Q,D)-β×S(Qneg,D)
(3)
1.2 基于相关反馈的时间序列相似性查询方法
上述的前2种反馈都是将正负反馈融合在一起创建新查询向量,这样并没有充分利用负反馈序列的价值,而且容易对初始查询向量进行过多的更改,本文在时间序列相似性领域引入上述的负反馈策略,提出一种基于相关反馈的时间序列相似搜索方法,将正反馈和负反馈分开进行。用户对查询结果标注出正相关的序列以及负相关的序列,通过正相关序列修改查询序列进行查询扩展,通过负反馈分别建立正查询和负查询,最后通过组合得出最终的相似度,并按照相似度排序展示给用户。主要包括:1)修改查询序列;2)正查询和负查询组合。
1.2.1 查询序列修改
时间序列相似性检索也是一种信息检索,因此,可以通过修改查询序列来使得查询结果更加全面,由于Rocchio算法是较为成熟可用的查询修改公式,本文采用公式(1)作为查询序列修改的原型公式。通常用户给的初始查询序列是能表达其大部分意图,查询序列修改仅做一些微调,因此为了保证修改后的查询序列与原序列不会偏离很大,故将α取值为1。本文中负相关序列用于调整结果序列与查询序列的相似度,不参与组合产生新查询序列,因此将γ取为0。在本文中用qnew表示新的查询序列,q为旧的查询序列,si表示相关序列(本文中认为用户所有的标注都是正确标注)。此时公式(1)变形为:
(4)
因为si是正相关序列,即用户感兴趣的序列,所以得到的序列qnew从理论上来说也应该是用户满意的序列。
算法1查询修改算法
输入:查询序列q,权重α,β,正相关序列集Sr=(s1,s2,…,sn)
输出:新的查询序列qnew
1 sr=s1//初始化sr
2 for j=1 to m do //设数据集中各序列均是m维的向量
3 begin
4 for i=2 to n do
5 begin //将相关序列集合同一维数据相加取平均值存到序列sr
6 sr[j]=(1/i)*(sr[j]+si[j]); //初始sr[j]表示序列sr中第j维的数据
7 end
8 qnew[j]=α*q[j]+β*sr[j];
9 end
1.2.2 正负查询组合
正查询是依据新的查询序列进行相似性度量,负查询就是由负相关序列组成一个查询序列,并依据它在数据集中查询相似序列。相似度量公式如下:
Sc(qnew,si)=Sim(qnew,si)-λSim(qneg,si)
(5)
其中,qneg是负相关序列组成的查询序列,λ为控制负相关序列影响大小的参数。λ取值可以根据经验设定或者通过实验确定最优的取值。Sc(qnew,si)代表si与qnew最终的相似程度。Sim(qnew,si)即序列si与查询序列qnew的相似程度。由该公式可知,要想Sc(qnew,si)的值高,要么Sim(qnew,si)的值高,即qnew与si的相似程度高;要么Sim(qneg,si)的值低,即qneg与si的相似程度低。
算法2正负查询组合
输入:查询序列qnew,负相关序列qneg,数据集S=(s1,s2,…,sn)以及参数β
输出:数据集S中序列si与查询序列qnew的相似度Sc(qnew,si)
1 for i=1 to n do
2 begin
3 计算si与qnew的相似程度Sim(qnew,si);
4 计算si与qneg的相似程度Sim(qneg,si);
5 计算组合相似度Sc(qnew,si)=Sim(qnew,si)-λSim(qneg,si)
6 end
在算法中主要需要解决的问题是,确定si与负相关序列的相似程度Sim(qneg,si)。本文提出了2种策略,一种是单负相关反馈模型,另一种是多负相关反馈模型。
1)单负相关反馈模型。
2)多负相关反馈模型。
查询结果中的负相关序列可能包含多个类别,单负反馈将所有负相关序列合并为一个负相关序列,不能体现不同类别的负相关序列的差异。多负相关模型先对负相关序列进行聚类,并将每一类合并成一个序列,然后再分别进行负查询。假设聚为m类,每类序列合并得到qneg1′,qneg2′,…,qnegm′,分别计算qneg1′,qneg2′,…,qnegm′和序列集中的序列si的相似程度,选择其中最为相似的一组,记为max(Sim(qneg,si))。公式(5)则变形为下列公式:
Sc(qnew,si)=Sim(qnew,si)-λmax(Sim(qneg,si))
(6)
2 实验验证与分析
2.1 实验数据与方法
本文采用UCR数据集[22]中的17组子数据集进行实验,每个数据集中所有序列都已经被标注类别。UCR数据集中标注的类别是分类得来的,而分类是根据它们的相似程度进行,因此,在同一个类别的序列是具有一定相似性的。各子数据集的信息如表1所示。
表1 各子数据集特点
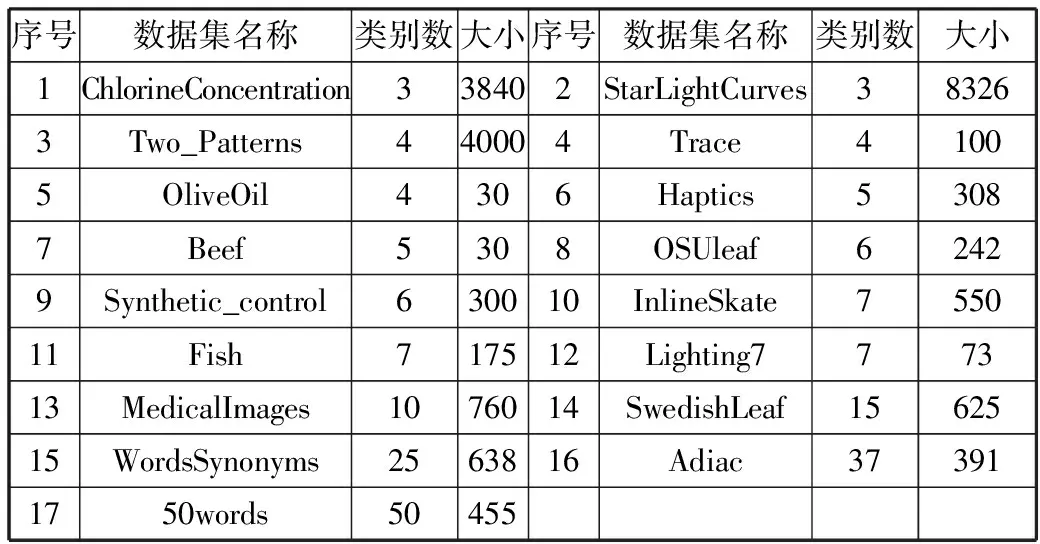
序号数据集名称类别数大小序号数据集名称类别数大小1ChlorineConcentration338402StarLightCurves383263Two_Patterns440004Trace41005OliveOil4306Haptics53087Beef5308OSUleaf62429Synthetic_control630010InlineSkate755011Fish717512Lighting777313MedicalImages1076014SwedishLeaf1562515WordsSynonyms2563816Adiac373911750words50455
本文针对每个子数据集分别进行5种相似查询,即无反馈、基于Rocchio算法反馈、基于Ide dec-hi算法反馈以及基于单负反馈和多负反馈,采用欧氏距离作为相似度量函数。基于Rocchio算法相关反馈查询中,α取值为1,β,γ从0到1以步长0.1递增;基于Ide dec-hi算法反馈的α取值为1,β,γ从0到1以步长0.1递增;单负反馈以及多负反馈各数据集正负查询组合中α取值为1,β,λ从0到1以步长0.1递增,在多负反馈中,针对负相关序列的聚类处理,直接根据负相关序列的类别,将类别相同的序列作为同一类。

(7)
本文中R取1~10,计算该查询序列对应的P-R值,形成对应P-R曲线,但由于数据集较多生成的图也较多,为更方便展示,采用各组数据集的P-R均值进行衡量。在带反馈的查询中,针对每个查询序列,共进行3轮查询,前两轮各返回10个结果序列,并根据结果序列的类别与查询序列类别是否相同,判断其为正、负相关序列,第三轮时,采用与无反馈查询相同的方法计算子数据集的P-R均值。
2.2 实验结果分析
表2~表5显示的是4种反馈查询中,各子组数据集对应的最优P-R均值以及参数值表,其中maxAv_p表示的是最优P-R均值。
表2 单负反馈各子数据集最优P-R均值以及对应β,λ值

数据集名称maxAv_pβλ数据集名称maxAv_pβλChlorineConcentration0.8810.71Trace0.6980.90.7StarLightCurves0.9270.81Beef0.4700.80.9Two_Patterns0.9590.91Fish0.8930.90.8Synthetic_control0.9620.60.3Adiac0.6300.70.5MedicalImages0.8050.90.950words0.6620.90.7WordsSynonyms0.7110.90.7Haptics0.5650.81InlineSkate0.4530.70.6OliveOil0.8720.70.5SwedishLeaf0.8660.80.8OSUleaf0.7280.80.8Lighting70.6850.90.8
表3 多负反馈各子数据集最优P-R均值以及对应β,λ值
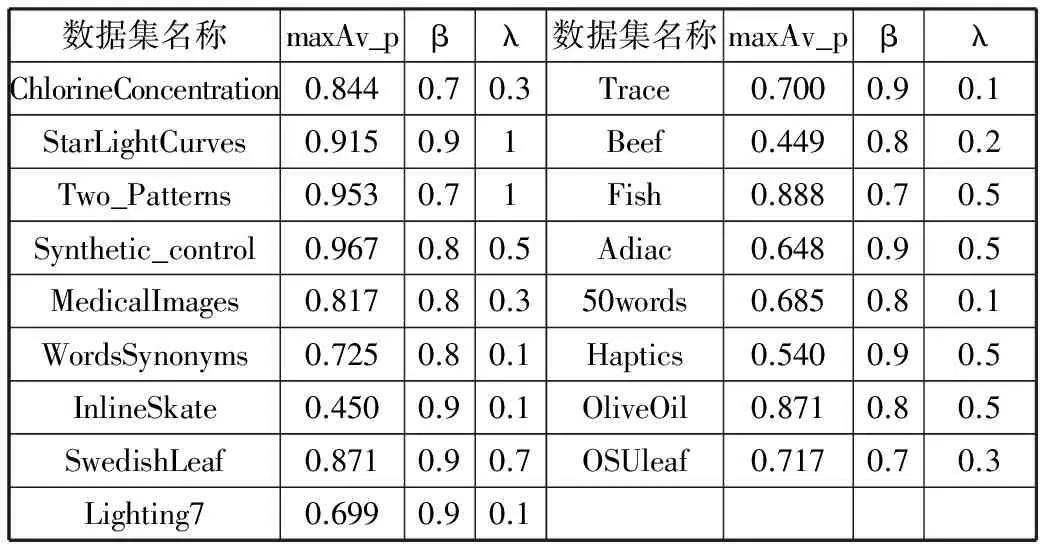
数据集名称maxAv_pβλ数据集名称maxAv_pβλChlorineConcentration0.8440.70.3Trace0.7000.90.1StarLightCurves0.9150.91Beef0.4490.80.2Two_Patterns0.9530.71Fish0.8880.70.5Synthetic_control0.9670.80.5Adiac0.6480.90.5MedicalImages0.8170.80.350words0.6850.80.1WordsSynonyms0.7250.80.1Haptics0.5400.90.5InlineSkate0.4500.90.1OliveOil0.8710.80.5SwedishLeaf0.8710.90.7OSUleaf0.7170.70.3Lighting70.6990.90.1
表4 基于Ide dec-hi算法反馈各子数据集最优P-R均值以及对应β,γ值
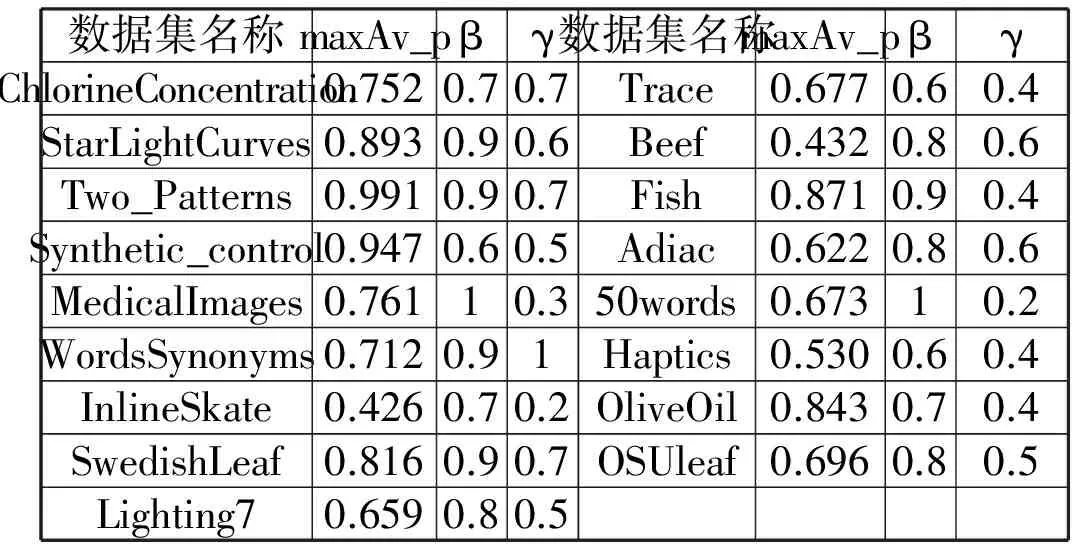
数据集名称maxAv_pβγ数据集名称maxAv_pβγChlorineConcentration0.7520.70.7Trace0.6770.60.4StarLightCurves0.8930.90.6Beef0.4320.80.6Two_Patterns0.9910.90.7Fish0.8710.90.4Synthetic_control0.9470.60.5Adiac0.6220.80.6MedicalImages0.76110.350words0.67310.2WordsSynonyms0.7120.91Haptics0.5300.60.4InlineSkate0.4260.70.2OliveOil0.8430.70.4SwedishLeaf0.8160.90.7OSUleaf0.6960.80.5Lighting70.6590.80.5
表5 基于Rocchio算法反馈各子数据集最优P-R均值以及对应β,γ值
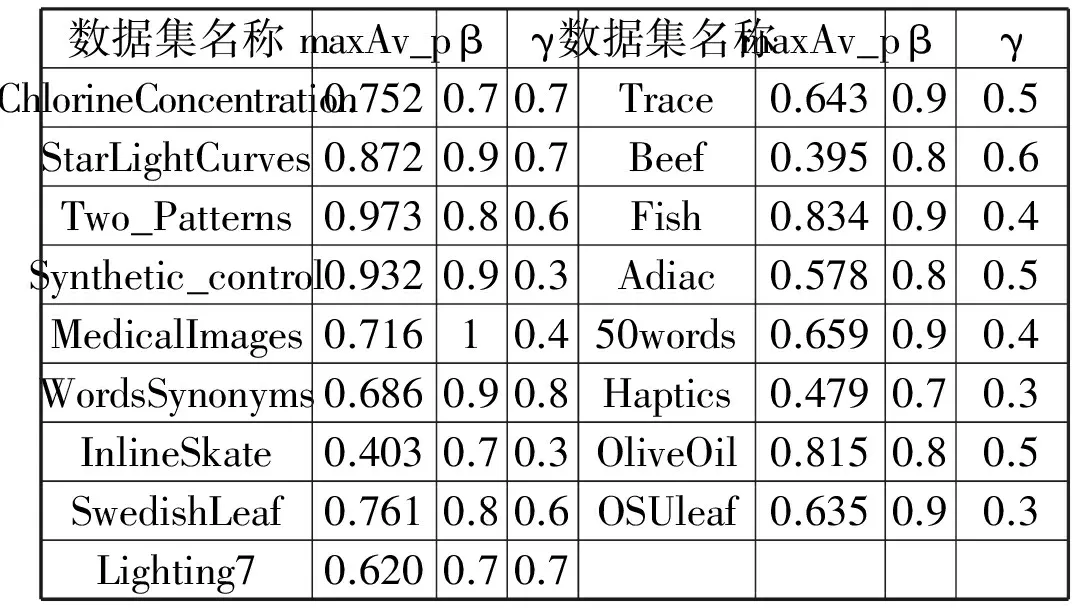
数据集名称maxAv_pβγ数据集名称maxAv_pβγChlorineConcentration0.7520.70.7Trace0.6430.90.5StarLightCurves0.8720.90.7Beef0.3950.80.6Two_Patterns0.9730.80.6Fish0.8340.90.4Synthetic_control0.9320.90.3Adiac0.5780.80.5MedicalImages0.71610.450words0.6590.90.4WordsSynonyms0.6860.90.8Haptics0.4790.70.3InlineSkate0.4030.70.3OliveOil0.8150.80.5SwedishLeaf0.7610.80.6OSUleaf0.6350.90.3Lighting70.6200.70.7
图1为17组不同数据集的5种方法的P-R均值结果图。从图1中可以看出,在这些数据集中有反馈的相似性搜索性能比无反馈的相似性搜索的性能都要好,本文提出的单负反馈和多负反馈明显比基于Rocchio算法反馈检索性能好,同时也比基于Ide dec-hi算法反馈检索性能好,这可能是因为本文对初始查询序列仅做微调并且充分利用负相关序列;而单负反馈和多负反馈这两者之间效果差别较小。在置信度0.05下,Wilcoxon符号秩和检验显示p=0.97583(双侧检验),表示针对17组子数据集,单负反馈和多负反馈查询性能基本相同。
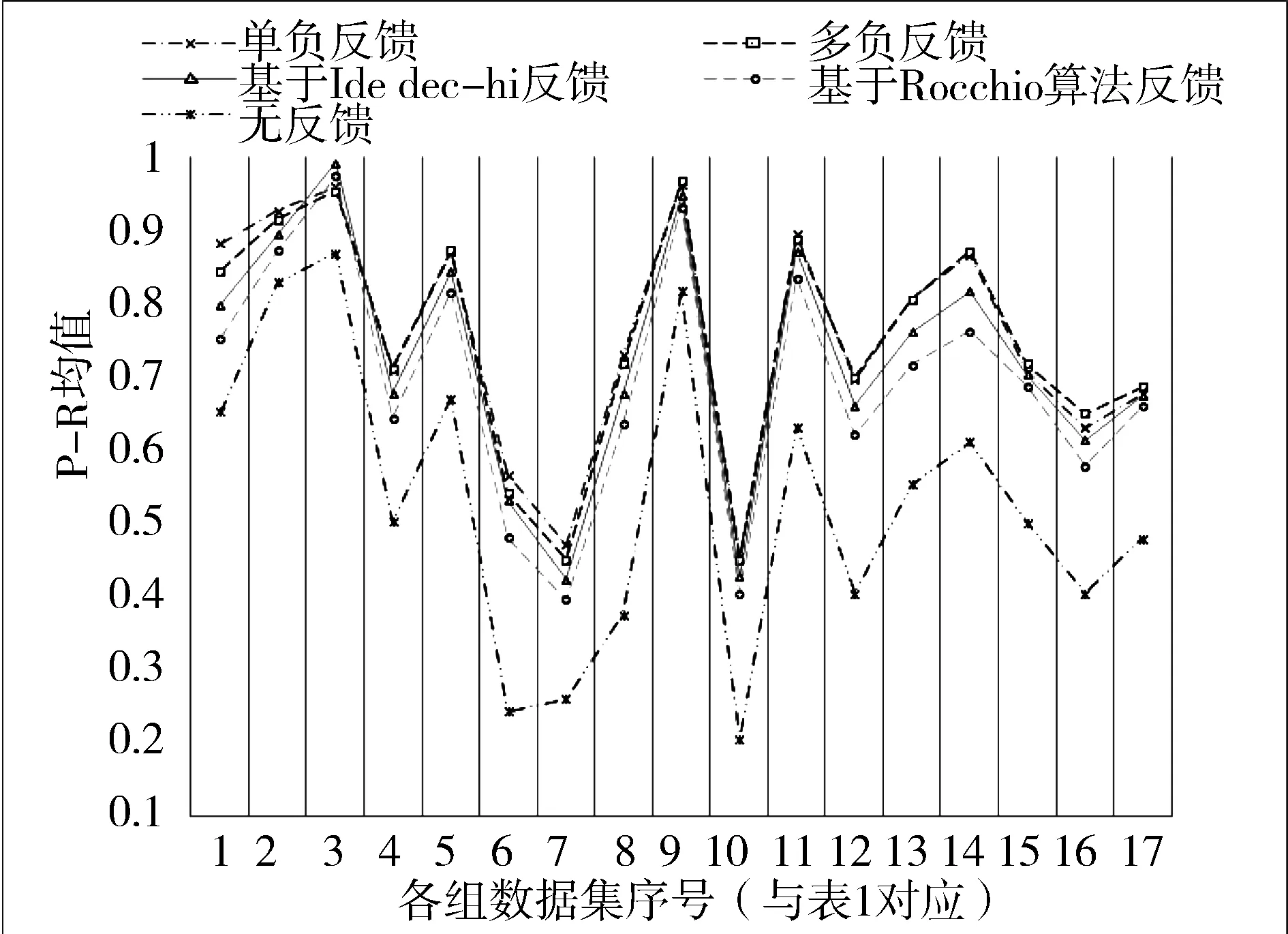
图1 各组数据集P-R均值指标结果
但是从图2加上分类数来看,可以看出当分类数比较小的时候,使用了单负相关反馈的模型比多负相关反馈模型好,当分类数较多时,多负相关反馈的模型比单负相关反馈的模型结果好。这可能是因为单负反馈模型简单地将各负相关序列当成一个类别来处理所导致的:在负相关序列较集中时即类别较少时,求均值所得到的结果能较好地代表各负相关序列的特性;在负相关序列较为分散时即类别较多时,求均值所得到的结果并不能很好地代表各负相关序列的特性。

图2 各组数据集P-R均值指标结果以及分类数
3 结束语
本文结合时间序列的特点,提出了基于相关反馈的时间序列相似性搜索方法,与已有相似性搜索方法相比,在进行相似性搜索时充分利用了负相关序列,解决了查询过程中用户难以参与搜索过程以及难以查找到使用户满意的序列问题。实验数据表明,该方法提高了查询的准确率和查全率。
[1] 王雅轩,顼聪. 数据挖掘技术的综述[J]. 电子技术与软件工程, 2015(8):204-205.
[2] Agrawal R, Faloutsos C, Swami A N. Efficient similarity search in sequence databases[C]// Proceedings of the 4th International Conference on Foundations of Data Organizations and Algorithms. 1993:69-84.
[3] 罗洪奔. 基于灰色-ARIMA的金融时间序列智能混合预测研究[J]. 财经理论与实践, 2014,35(2):27-34.
[4] 朱跃龙,李士进,范青松,等. 基于小波神经网络的水文时间序列预测[J]. 山东大学学报(工学版), 2011,41(4):119-124.
[5] 李正欣,郭建胜,惠晓滨,等. 基于共同主成分的多元时间序列降维方法[J]. 控制与决策, 2013(4):531-536.
[6] 李海林. 时间序列数据挖掘中的特征表示与相似性度量方法研究[D]. 大连:大连理工大学, 2012.
[7] 肖瑞. 不确定性时间序列的降维与相似性匹配研究[D]. 上海:东华大学, 2014.
[8] 李正欣,张凤鸣,李克武,等. 一种支持DTW距离的多元时间序列索引结构[J]. 软件学报, 2014,25(3):560-575.
[9] 戴珂. 基于线性散列索引的时间序列查询方法研究[J]. 软件工程师, 2016,19(8):1-8.
[10] Zhang Qiang, Zhao Zheng. Z Tree: An index structure for high-dimensional data[J]. Computer Engineering, 2007,33(15):49-51.
[11] 肖瑞,刘国华. 基于趋势的时间序列相似性度量和聚类研究[J]. 计算机应用研究, 2014,31(9):2600-2605.
[12] 张海涛,李志华,孙雅,等. 新的时间序列相似性度量方法[J]. 计算机工程与设计, 2014,35(4):1279-1284.
[13] Goldin D Q, Millstein T D, Kutlu A. Bounded similarity querying for time-series data[J]. Information & Computation, 2004,194(2):203-241.
[14] Keogh E J, Pazzani M J. An enhanced representation of time series which allows fast and accurate classification, clustering and relevance feedback[C]// Proceedings of the 4th International Conference on Knowledge Discovery & Data Mining. 1998:239-241.
[15] Eravci B, Ferhatosmanoglu H. Diversity based relevance feedback for time series search[J]. Proceedings of the VLDB Endowment, 2013,7(2):109-120.
[16] Carbonell J, Goldstein J. The use of MMR, diversity-based reranking for reordering documents and producing summaries[C]// Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. 1998:335-336.
[17] Wang Xuanhui, Fang Hui, Zhai Chengxiang. A study of methods for negative relevance feedback[C]// International ACM SIGIR Conference on Research and Development in Information Retrieval. 2008:219-226.
[18] Peltonen J, Strahl J, Floréen P. Negative relevance feedback for exploratory search with visual interactive intent modeling[C]// Proceedings of the 22nd International Conference on Intelligent User Interfaces. 2017:149-159.
[19] Van Rijsbergen C J. A new theoretical framework for information retrieval[J]. ACM Sigir Forum, 1986,21(1-2):23-29.
[20] Rocchio J J. Relevance feedback in information retrieval[M]// The SMART Retrieval System: Experiments in Automatic Document Processings. 2000:313-323.
[21] Ide E. New experiments in relevance feedback[M]// The SMART Retrieval System: Experiments in Automatic Document Processings. 2000.
[22] Chen Yanping, Keogh E, Hu Bing, et al. The UCR Time Series Classification Archive[EB/OL]. http://www.cs.ucr.edu/~eamonn/time_series_data/, 2017-06-10.
猜你喜欢
数学物理学报(2022年5期)2022-10-09
天津医科大学学报(2021年1期)2021-12-05
四川大学学报(自然科学版)(2021年1期)2021-01-26
河北画报(2020年8期)2020-10-27
电子制作(2019年23期)2019-02-23
现代计算机(2017年4期)2017-03-29
中国医学影像技术(2017年11期)2017-01-16
上海海事大学学报(2016年3期)2016-12-19
考试周刊(2016年63期)2016-08-15
浙江大学学报(工学版)(2016年2期)2016-06-05
