
基于序列比对的勒索病毒同源性分析
2018-03-13 07:23曹金璇芦天亮
计算机与现代化 2018年2期
龚 琪,曹金璇,芦天亮
(中国人民公安大学信息技术和网络安全学院,北京 100076)
0 引 言
勒索病毒加密受害人重要文件或系统向其索求支付赎金以获得回报。病毒主要以邮件、exploit kits、网页广告嵌套等方式感染受害者[1]。近期影响颇大的WannaCrypt感染事件,病毒主要以社会工程学方式尝试感染目标环境,通过带有恶意宏Office文档附件的钓鱼邮件,感染环境中电脑后,该变种会尝试在内网中主动传播。据统计,勒索软件攻击从2015年380万次增至2016年6.38亿次。CTA报告[2]指出,勒索病毒新成员CryptoWall4在2016年造成了约1800万美元损失。另一报告指出[3],继政府和商业,医院已成为勒索软件下一个攻击目标。勒索攻击中,新出现家族并不多,多数为已有家族变种,所以研究勒索病毒的同源性能为对抗勒索病毒提供有力帮助。
检测勒索病毒属于恶意代码检测,目前的检测方法主要分有静态检测、动态检测。静态分析通过逆向工程抽取程序特征,分析函数调用、程序指令等序列。而勒索病毒使用了内存映射、混肴、花指令等手段躲避静态分析,所以特征不明显。为了克服这种困难,本文基于动态检测捕获勒索病毒行为,虽然它们的静态特征不明显,但是有相同的动态特征,如注册表特征、文件行为特征等。所以,本文提出一种基于动态行为特征结合序列比对算法对勒索病毒进行同源性分析。动态行为特征中,API调用最具代表性,API调用序列是程序与系统交互最基本的接口,通过对API序列进行编码,能全面捕获勒索病毒的动态行为。n-gram算法是一种简单序列比对算法,API调用序列中存在大量重复API序列调用,使用n-gram算法时,检测效果不理想。此外,动态规划算法以及多重序列比对算法已广泛应用于生物信息学领域。动态规划算法中包含局部序列比对以及全局比对算法,2类算法都提供了一种对齐解决方案来匹配2个目标序列最大公共序列。
本文首先对API调用序列分类,对API调用序列类别编码,结合Clustalw等算法计算样本之间最大公共序列进行建模,计算样本之间相似度。实验表明,本方法能很好地分析勒索病毒同源性,并能区分正常软件。
1 序列比对算法
在生物信息学研究中,将未知序列与已知序列进行相似性比较较为成熟。序列比对分为全局序列比对和局部序列比对,局部序列比对对2个序列局部区域相似性进行考察,对于序列的未对齐部分没有惩罚[4-5],从而找出序列之间公共部分。全局序列比对对2个序列全局相似性进行考察,从序列开始至结束进行对齐、比对以找出最佳比对。
1.1 局部序列比对算法
Smith-Waterman算法,基于动态规划思想比对过程包括初始化、计算打分矩阵、回溯3个步骤。给定2个序列A=a1a2a3…an和B=b1b2b3…bm,序列A和序列B中的元素相似度为s(a,b),长度为k的插入损失为Wk,初始化打分矩阵H:
Hx0=H0y=0, 0≤x≤n,0≤y≤m
(1)
H(i,j)=max{
0
H(i-1,j-1)+s(ai,bj)

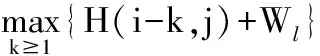
(2)
(3)
Wi=-i
(4)
其中H矩阵取4种情况下最大值,s(ai,bj)为序列a1a2a3…ai与b1b2b3…bj最大相似度,通过公式(3)进行计算。Wi为空位惩罚因子。
回溯寻找相似子序列过程为:在打分矩阵中找到数值最大元素,然后回溯找到该最大值上一个元素,重复以上过程,直至无法找到向上路径,得到序列就是最大相似子序列。
1.2 全局序列比对算法
Needleman-Wunsch实现大致如下,取罚分函数w(a,b)=dH(a,b)为Hamming距离,如A,B为需比对序列,则将输入序列A=(a1,a2,…,ana),B=(b1,b2,…,bnb)作为方阵第0行、第0列。再由A,B序列确定得分矩阵S=(Si,j),惩罚函数使用Hamming距离,打分函数定义如下,其中d为罚分值。
(5)
(6)
根据得分矩阵回溯确定最高得分对应序列比对。得到最后一个s(n,m)值,此值为(A,B)比对后最高得分。同时s(n,m)为回溯起点。
1.3 多重序列比对Clustaw
Clustaw是一种基于动态规划的算法,先对多重序列两两比对,得到最优解。由比对结果计算各序列间相互距离,得到多重序列两两比对距离矩阵。由结果距离矩阵做多重序列聚类分析,产生向导树。对向导树相邻矩阵再做比对,由此产生多重序列比对结果。其中时间复杂度为O(m2n2),m为输入序列的条数,n为输入序列的平均长度。
1.4 降低时间复杂度
Smith-Waterman算法搜索整个解空间,其计算时间复杂度为O(n2),n为输入序列的平均长度。Clustaw算法时间复杂度为O(m2n2),两者算法敏感性好,但时间复杂度随着输入序列的条数及长度而增长,计算时间较长。在研究API调用时发现调用序列包含许多重复子调用,重复调用通常发生于API调用陷入循环后,这类循环通常在一个家族中有不同表现,所以重复子序列应该被移除,来提高勒索家族检测率。此外,移除重复子序列也能减少API序列调用长度,同时提高算法执行效率。
2 勒索病毒同源性分析设计
2.1 同源性分析架构
勒索病毒使用API来执行各种恶意行为。本文基于API调用类别相似度计算方法进行勒索病毒同源性分析,图1为系统架构流程图。
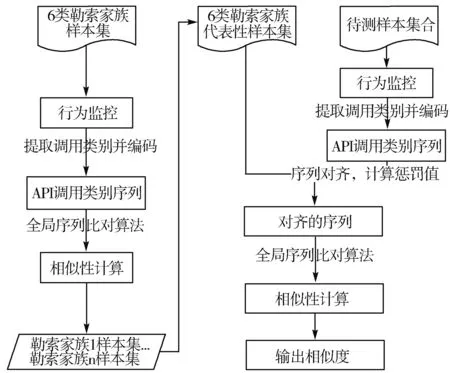
图1 勒索病毒同源性分析架构图
整个系统流程包括2部分。第1部分为选取模块,选取各家族中代表性强的样本作为比对样本。第2部分为相似度计算模块,包括4个子模块:1)行为监控模块,使用沙箱监控勒索病毒动态行为并提取API调用行为; 2)转换模块,对样本的API调用进行分类转换,再将调用类别编码为API类别序列; 3)比对模块,使用全局比对算法进行序列比对; 4)结果输出模块,计算相似度并输出。
2.2 行为监控
在行为监控阶段,本文基于开源沙箱cuckoo监控勒索软件行为并捕获动态行为特征,从中提取样本API调用行为。本实验中,大部分样本能被检测到动态行为,小部分样本如果检测到在虚拟环境下不释放异常行为,考虑到样本在检测是否在虚拟环境时可能API调用类别的序列也不一样,所以本文将不释放异常行为的样本也包括在内来检测模型的效果。经实验,95.2%的样本捕获到API调用行为。
2.3 编码与转换
API由各种函数实现,如果对单个系统调用进行编码,不但消耗的时间复杂度高,而且表征勒索软件行为不明显。结合API调用类别进行行为表征研究[6-7],本文将API调用序列分为16类API调用类别,对API调用序列类别进行编码,使用API调用类别表示勒索病毒行为,编码表如表1所示。
表1 API调用类别与对应编码
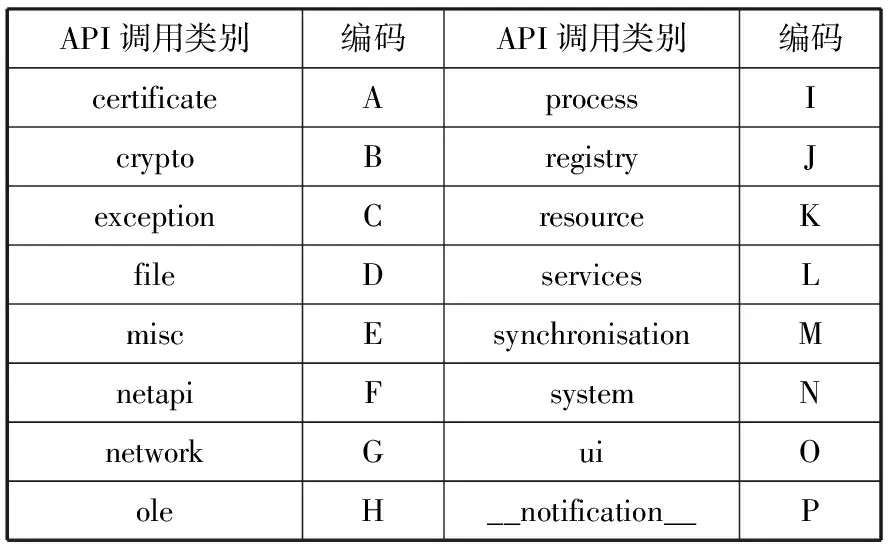
API调用类别编码API调用类别编码certificateAprocessIcryptoBregistryJexceptionCresourceKfileDservicesLmiscEsynchronisationMnetapiFsystemNnetworkGuiOoleH__notification__P
提取样本API调用序列后根据对应编码规则进行编码,获得API“基因”序列。
本文对重复子序列进行去重[8],虽然去重会影响序列之间的相似度,但不会对分类结果造成很大影响,参考研究者们去重方法[9-10],本文设计去重算法去除重复调用的API子序列来降低时间复杂度。如下伪代码为整个算法中去重部分,输入为已编码的API调用序列,a,b为训练样本i中长度为n的第k、k+1个子序列。
输入:训练集N;子序列长度n
输出:去重后的训练集
1 For i in N:
2 if k≤len(i):
3 ak=ink,bk=ink+1, k∈N+
4 if ak==bk:
5 删除bk,bk=bk+1
6 else:
7 ak=bk, bk=bk+1
8 Return已去重的序列
2.4 序列比对
完成编码后,使用算法[11-12]排列编码后的调用序列。对齐调用序列类似于图2中示例。算法通过将间隙gap插入到序列中以使它们正确对齐。
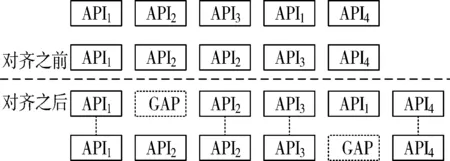
图2 序列对齐的例子
2.5 计算相似度
对齐后,从中提取匹配的子序列,计算相似度,相似度计算公式如下:
m=Length(A),n=Length(B)
(7)
其中,L为匹配的子序列长度,m,n分别为API类别调用序列A,B总长度,相似度取值范围在(0,1)之间。Sim(A,B)越大,意味A,B序列越相似。
3 模型验证与分析
3.1 实验数据
公开网站(http://www.malware-traffic-analysis.net)下载近几年勒索病毒,正常样本集从360官网下载所得,如表2所示。
表2 使用的勒索样本所属家族及数量
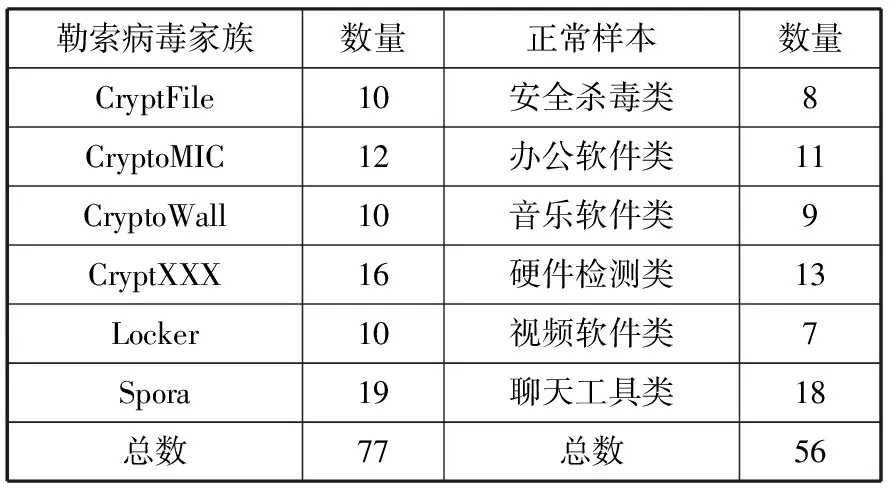
勒索病毒家族数量正常样本数量CryptFile10安全杀毒类8CryptoMIC12办公软件类11CryptoWall10音乐软件类9CryptXXX16硬件检测类13Locker10视频软件类7Spora19聊天工具类18总数77总数56
其中正常样本集包含6类共56个样本软件。勒索样本集中包含6类共77个勒索样本,为了减少污染[13],正常样本集仅从360官方应用商店,按软件使用比例下载软件。检测所有数据在Virus Total上结果,选择样本集为已去除被污染样本集。实验环境如表3所示。
表3 实验环境
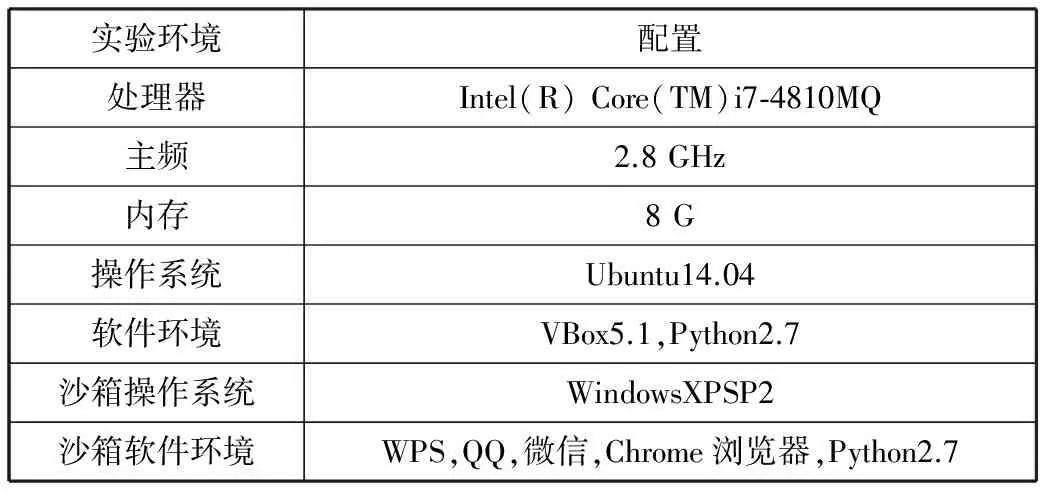
实验环境配置处理器Intel(R)Core(TM)i7⁃4810MQ主频2.8GHz内存8G操作系统Ubuntu14.04软件环境VBox5.1,Python2.7沙箱操作系统WindowsXPSP2沙箱软件环境WPS,QQ,微信,Chrome浏览器,Python2.7
3.2 实验结果与分析
3.2.1 形成比对对象
本实验中使用的样本集为已知家族的样本,在获取所有样本集的动态行为后,根据本文提出的编码方式分别生成各家族“序列图谱”和样本集的“序列编码”。图3、图4当取子序列为1时,CryptoMic家族样本集的“序列编码”。可以看出去重前CryptoMic21.fasta序列大小为285.2 kB,去重后为20.4 kB。

图3 未去重的“API调用行为类别序列”

图4 去重后的“API调用行为类别序列”
3.2.2 进行比对
图5为子序列为3时,CryptoFile家族的样本与CryptoMic家族的“序列图谱”的比对结果,其中相似度为1.1%,Gaps值为98.9%。
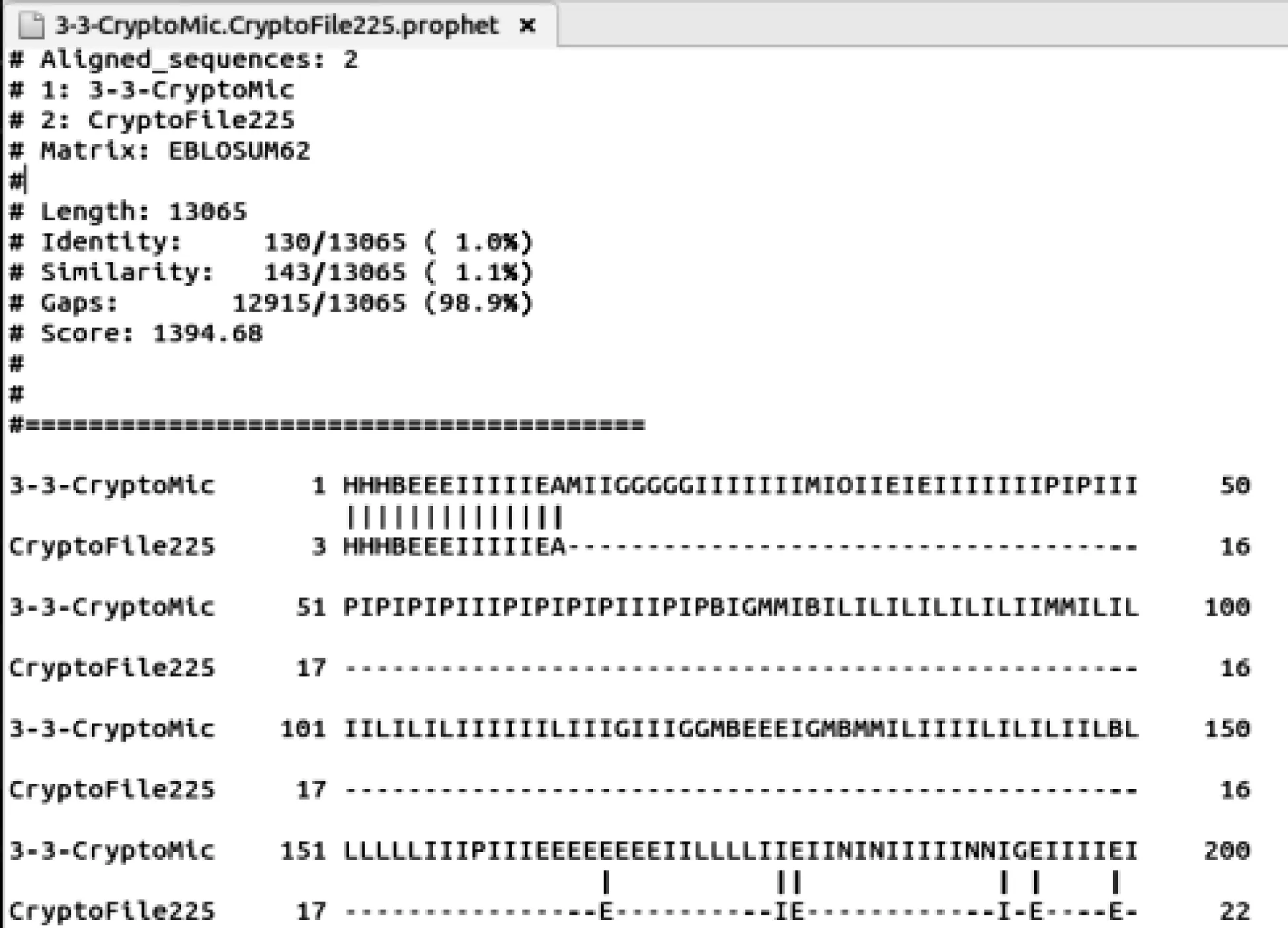
图5 CryptoFile-CryptoMic比对结果
3.2.3 实验结果
如表4~表7所示,横轴为各家族,纵轴为已知所属家族的样本集。表示每类样本集与各家族的相似度Sk:
其中k∈[1,6],n表示样本总量,xi表示样本集中样本i与家族k的相似度。
表4 子序列长度为1 /%

Len(1)CRYPTOFILECRYPTOMICCRYPTOWALLCRYPTOXXXLOCKERSPORACryptoFile643746465540CryptoMic445541413841CryptoWall261746465738CryptoXXX38958586361Locker272762626557Spora22356262476
表5 子序列长度为2 /%
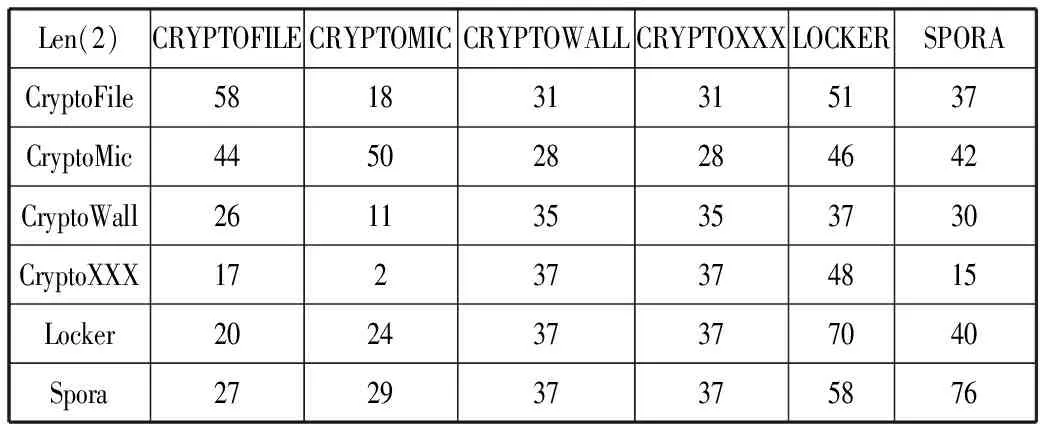
Len(2)CRYPTOFILECRYPTOMICCRYPTOWALLCRYPTOXXXLOCKERSPORACryptoFile581831315137CryptoMic445028284642CryptoWall261135353730CryptoXXX17237374815Locker202437377040Spora272937375876
表6 子序列长度为3 /%

Len(3)CRYPTOFILECRYPTOMICCRYPTOWALLCRYPTOXXXLOCKERSPORACryptoFile71327114654CryptoMic3972363852CryptoWall18157394656CryptoXXX6210784744Locker16279127761Spora26388125180
表7 子序列长度为4 /%

Len(4)CRYPTOFILECRYPTOMICCRYPTOWALLCRYPTOXXXLOCKERSPORACryptoFile71345314152CryptoMic27691284642CryptoWall111768355351CryptoXXX11310695154Locker23318377758Spora18346376477
如表6所示,选取子序列长度为3时,检测效果最好,检测集与本家族平均相似度在75%以上,与其他家族的平均相似度在50%以下。本文样本集都为勒索病毒,大部分存在同样的勒索行为,如频繁的文件读写操作、频繁的注册表操作等,都会增加与其他家族的相似度。同时本文比较的是勒索病毒每个家族存在变种以及进化的版本,所以系统调用上存在一定的差异,及相似度上会产生差异。
表8表示取子序列长度为3时各家族样本间的gap值。Locker家族与Spora家族的勒索病毒”序列编码”相似度为61%,但gap值90%。可以得出,基于序列比对算法,结合序列间相似度与gap值可以很好的分析勒索病毒同源性。
表8 子序列长度为3时与各家族gap值 /%

Len(3)CRYPTOFILECRYPTOMICCRYPTOWALLCRYPTOXXXLOCKERSPORACryptoFile275873928158CryptoMic633079966652CryptoWall921468959091CryptoXXX928992259092Locker858590913090Spora828690789122
如表9所示,子序列取3时,正常软件与勒索家族相似度,可以看出硬件检测类软件与CryptoXXX家族的相似度最高,相似度为39%,说明该模型能很好地区分正常软件与勒索病毒。
表9 正常软件与各勒索家族的相似度 /%
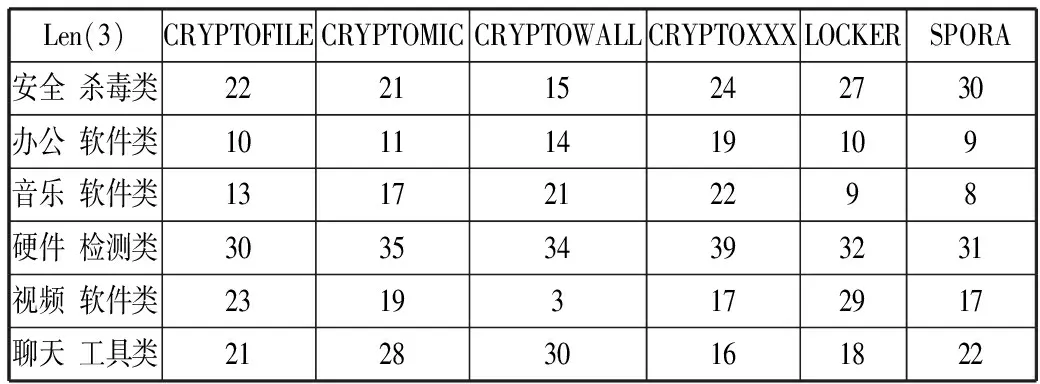
Len(3)CRYPTOFILECRYPTOMICCRYPTOWALLCRYPTOXXXLOCKERSPORA安全杀毒类222115242730办公软件类10111419109音乐软件类1317212298硬件检测类303534393231视频软件类23193172917聊天工具类212830161822
4 结束语
针对勒索软件,本文提出一种基于序列比对的方法进行同源性分析,通过使用API类别表述样本行为, 能较好解决特征表征问题。此外,结合序列比对算法,在检测勒索软件同源性以及区分正常软件与勒索病毒实验中效果明显。
在使用序列比对算法时,存在计算时间长、时间复杂度高的问题。本文使用去重的方式,较好解决了这些问题。将来继续深入研究基于序列比对的方法,由于网络安全威胁不仅是勒索软件,因此希望能将该方法应用于其他类型恶意软件同源性分析中。
[1] Sgandurra D,Muoz-González L, Mohsen R, et al. Automated dynamic analysis of ransomware: Benefits, limitations and use for detection[J]. Computer Science, 2016: arXiv:1609.03020.
[2] Cyber Threat Alliance. Lucrative Ransomware Attacks: Analysis of the Cryptowall Version 3 Threat[EB/OL]. http://www.doc88.com/p-7714530017104.html, 2016-01-13.
[3] McAfee. Part of Intel Security. McAfee Labs Threats Report: September[EB/OL]. https://www.mcafee.com/us/resou-rces/reports/rp-quarterly-threats-sep-2016.pdf, 2016-09-30.
[4] Altschul S F, Gish W, Miller W, et al. Basic local alignment search tool[J]. Journal of Molecular Biology, 1990,215(3):403-410.
[5] Cohen J. Bioinformatics_an introduction for computer scientists[J]. ACM Computing Surveys (CSUR), 2004,36(2):122-158.
[6] Yakup K. Automated detection and classification of malware used in targeted attacks via machine learning[D]. Bilkent University, 2015.
[7] Kirda E. UNVEIL: A large-scale, automated approach to detecting ransomware (keynote)[C]// IEEE 24th International Conference on Software Analysis, Evolution and Reengineering. 2017:1.
[8] Cho I K, Kim T G, Shim Y J, et al. Malware similarity analysis using API sequence alignments[J]. Journal of Internet Service and Information Security, 2014,4(4):103-114.
[9] Kim H, Kim J, Kim I. Implementation of malware detection system based on behavioral sequences[C]// Security Technology 2016. 2016,139:348-353.
[10] Cho I K, Im E G. Malware family recommendation using multiple sequence alignment[J]. Journal of Molecular Evolution, 2016,43(3):289-295.
[11] 刘阳,王小磊,李江域,等. 局部序列比对算法及其并行加速研究进展[J]. 军事医学, 2012,36(7):556-560.
[12] Smith T F, Waterman M S. Identification of common molecular subsequences[J]. Journal of Molecular Biology, 1981,147(1):195-197.
[13] Rossow C, Dietrich C J, Grier C, et al. Prudent practices for designing malware experiments: Status quo and outlook[C]// IEEE Security & Privacy. 2012:65-79.
猜你喜欢
看世界(2021年11期)2021-06-08
红蜻蜓·低年级(2020年12期)2020-06-20
商品与质量(2019年34期)2019-11-29
西藏文学(2019年4期)2019-09-17
——美创科技“诺亚”防勒索系统向勒索病毒“宣战”
网络安全和信息化(2019年8期)2019-08-28
计算机系统应用(2019年3期)2019-03-11
民族古籍研究(2018年1期)2018-05-21
西夏学(2016年2期)2016-10-26
浙江大学学报(工学版)(2015年1期)2015-03-01
中国中医药现代远程教育(2014年16期)2014-03-01
