
基于ELM-AdaBoost.M2的污水处理过程在线故障诊断
2018-03-08 09:02谭承诚于广平邱志成
计算机测量与控制 2018年2期
谭承诚,于广平,邱志成
(1.华南理工大学 机械与汽车工程学院,广州 510640;2.中国科学院 沈阳自动化研究所广州分所,广州 511458)
0 引言
污水处理是一个典型的流程行业过程,具有数据量大、强耦合性、工业噪声和过程干扰多、动态性强等特点[1],对其过程的实时监控,在避免环境污染、降低经济损失、保障生产安全等方面具有重大意义。污水处理既有复杂机械电气系统的参与,又包含众多的生化反应过程,对其系统内在的运行原理进行研究,成本过高,然而污水处理过程会产生海量隐藏着工艺变动和设备运转的数据,于是如何利用好这些数据来提高污水处理过程的效率与安全,降低二次污染成为了一个急需解决的问题。因此基于数据驱动的污水处理过程故障诊断方法得到了广泛的研究。文献[2]利用BP神经网络对污水厂进行了实际污水处理过程运行状态的监控,显示了良好的效果和稳定性,文献[3]提出了一种基于支持向量机的污水处理过程故障诊断模型,文献[4]根据污水处理厂的实际情况,提出了一种改进的支持向量机故障诊断方法,结果表明该方法可以较好的满足污水厂对安全生产的要求。上述故障诊断模型都取得了一定了成果,但神经网络具有在学习过程易陷入局部极小值、过拟合、训练时间长等缺点[5],支持向量机随着样本量的增多,训练时间会变长,支持向量增多,模型的稀疏性渐失[6]。与此同时,污水处理过程的运行状态具有较强的不平衡分布,即正常运行状态所占比例远高于故障状态的所占比例,传统的神经网络与支持向量机故障诊断模型对少数类(故障类)的识别率极不理想。
根据现有成果与存在的问题,本文提出一种基于极限学习机(extreme learning machine, ELM)和AdaBoost.M2相结合的污水处理过程在线故障诊断模型。ELM在学习过程中随机产生输入层与隐含层之间的连接权值和隐含层神经元的阈值,无需调整参数,仅需设置隐含层神经元的个数,便可将传统单隐层前置神经网络参数训练问题转化为求解线性方程组[7],最终得到全局最优解。考虑到故障诊断是多分类问题,利用AdaBoost.M2算法的集成提升作用可将基于ELM的弱分类器构造为强分类器。通过分层组合,使迭代权重的重点聚焦于少数类或极少数类的困难数据上,提高了分类器的准确性和泛化性能,亦满足在线污水处理过程故障诊断对于实时性的要求,并通过仿真实验得到了验证。
1 基于ELM-AdaBoost.M2的污水处理在线故障诊断模型
1.1 极限学习机ELM
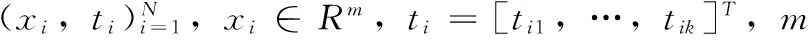
(1)
其中:xi表示数据集中的第i组样本数据,βi表示第i个隐含层神经元到输出层的连接权值,g(x)表示隐含层神经元的激活函数,wi表示输入层到第i个隐含层神经元到输入层的连接权值,bi表示第i个隐含层神经元的偏置。
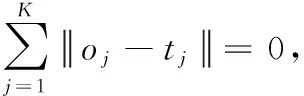
(2)
式(2)可以表示为:
Hβ=T
(3)
其中:
H=H(w1,…,wK,b1,…,bK,x1,…,xN)=
其中:H为隐含层输出矩阵,β为输出权值矩阵,T为输出层输出矩阵。

(4)
其中:H+为隐含层输出矩阵H的Moore-Penrose广义逆。
具体地,ELM算法有以下几个步骤[9]:
1)确定隐含层神经元个数,随机设定输入层与隐含层的连接权值w和偏置b;
2)选择一个无限可微的激活函数,计算隐含层输出矩阵H;
1.2 AdaBoost.M2算法
AdaBoost算法在解决二类分类问题时,只需弱分类器对任意样本分类准确率比0.5略高,然而,若直接将AdaBoost应用于多分类问题,这一条件过强,同时,要求弱分类器比随机猜测准确率略高的条件又过弱,因此会导致集成的强分类器准确率较低[10]。针对多分类问题,可以选择AdaBoost的扩展算法AdaBoost.M2。
AdaBoost算法的错分概率为:
(5)
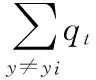
(6)
从而可得AdaBoost.M2算法的伪误差:
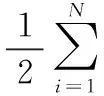
(7)
式中,ht(xi,y)表示弱分类器ht将xi分为y的置信度;qt(i,y)为标签加权函数,表示将样本xi错误分为类别y的概率,值越大表示样本被错分的概率越大,则该样本在下一次迭代的时候会得到重点学习。qt(i,y)在多次的循环迭代过程中不断的改变样本的权重,对易错分样本进行重点学习,继而提高了弱分类器的泛化能力和学习能力,提高了分类的准确率和稳定性[11]。
1.3 ELM-AdaBoost.M2算法流程
针对污水处理过程运行状态分布不平衡,其本质是一个多分类的问题,ELM-AdaBoost.M2算法将多个ELM弱分类器集成为强分类器,在集成为强分类器的过程中对被错分样本赋予更大权值,使错误分类的样本在下一次迭代中被重点学习,最终可以提高模型的分类准确率和泛化能力。ELM-AdaBoost.M2算法的实现流程如下所示。
对于污水处理过程原始数据进行归一化处理,得到个样本的训练集:(xi,yi),xi∈Rm,yi∈(1,2,…,k),其中为类别数。定义D为样本上的分布,T为弱分类器的个数,即循环迭代的次数。
2)fori=1:T
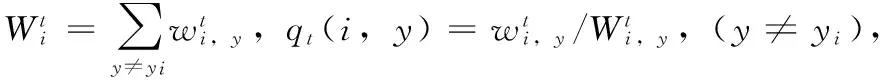
(2)根据样本分布Dt(i)选择新样本训练极限学习机ELM,得到弱分类器ht:X*Y→[0,1];
(3)根据式(7)计算伪误差εt,若εt≥0.5:转到步骤3);
(4)令βt=εt/(1-εt),更新权值向量:
(8)
其中:bt=(1/2)(1-h(xi,yi)+h(xi,y));
end
3)结束循环,输出强分类器H:
(9)
2 实验仿真与结果分析
2.1 实验数据
本文所用污水处理过程数据来源于加州大学欧文分校机器学习数据库,该数据集共包含527个样本,每个样本具有38个属性,其中无缺失值的样本380个,具有13种运行状态,为简化分类难度,污水处理过程的运行状态分为4类,其中类别1为正常运行状态,类别2为运行性能为高于均值的正常状态,类别3为进水量较少的正常运行状态,类别4表示运行故障状态。4中运行状态的比率为23.7∶8.29∶4.64∶1,属于典型的不平衡分布数据集。
2.2 性能评价指标
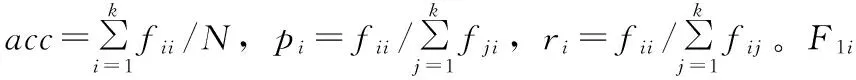
(10)
其中:N表示样本总数,k表示类别数。
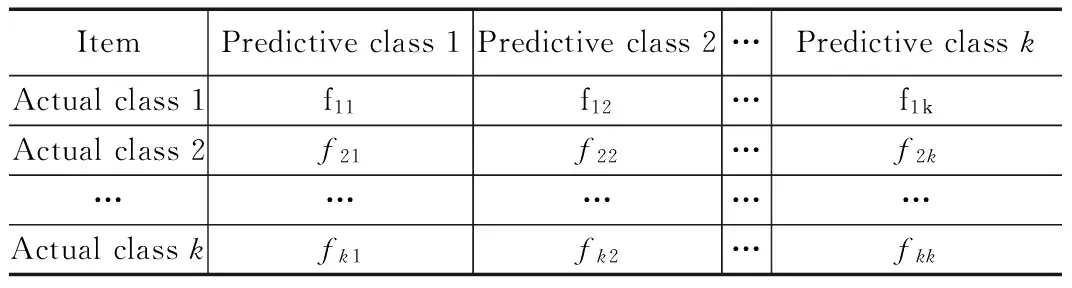
表1 多分类问题的混淆矩阵
2.3 在线仿真实验
仿真实验中,仅提取出数据集中具有完整属性的380个样本,按2:1的比例随机分层抽样,得到训练集Xtr和测试集Xte。对训练集Xtr进行归一化处理,将处理后的数据分别输入BP神经网络模型,支持向量机(SVM)模型,相关向量机(RVM)模型,极限学习机(ELM)模型以及本文提出的基于ELM-AdaBoost.M2的故障诊断模型中进行离线建模和故障诊断测试。其中BP神经网络为三层结构,隐含层节点数由5折交叉验证法在一定的范围内搜索,最终确定BP神经网络采用38-10-4结构;SVM模型采用径向基(RBF)核函数,利用遗传算法来搜索惩罚参数c和径向基函数参数g,采用一对一(one-versus-one)的分类方法实现。ELM模型和ELM-AdaBoost.M2模型选用sigmoid函数为激活函数,隐含层节点个数使用5折交叉验证法在[10,200]内择优选取。ELM-AdaBoost.M2模型迭代次数T初始化为10。
选择不同的隐含层节点个数对ELM模型和ELM-AdaBoost.M2模型的交叉验证准确率均有影响,如图1和图2所示。从图1可以看出,ELM模型的节点在45个时,交叉验证的准确率最高,随着节点个数的增加,交叉验证准确率整体呈下降趋势,可见对于ELM模型,隐含层节点的个数不是越多越好,过多的隐含层节点会造成过拟合现象。从图2可以看出,ELM-AdaBoost.M2相对于ELM模型,模型整体的交叉验证准确率有明显的提升,同时该模型验证准确率最高是在25个节点左右,45个节点左右的验证准确率在模型中并不突出,该模型对于交叉验证准确率较低的弱分类器提升效果明显,较强的弱分类器提升效果一般,由此可见不同的弱分类器对于模型最终准确率的提升效果不同。
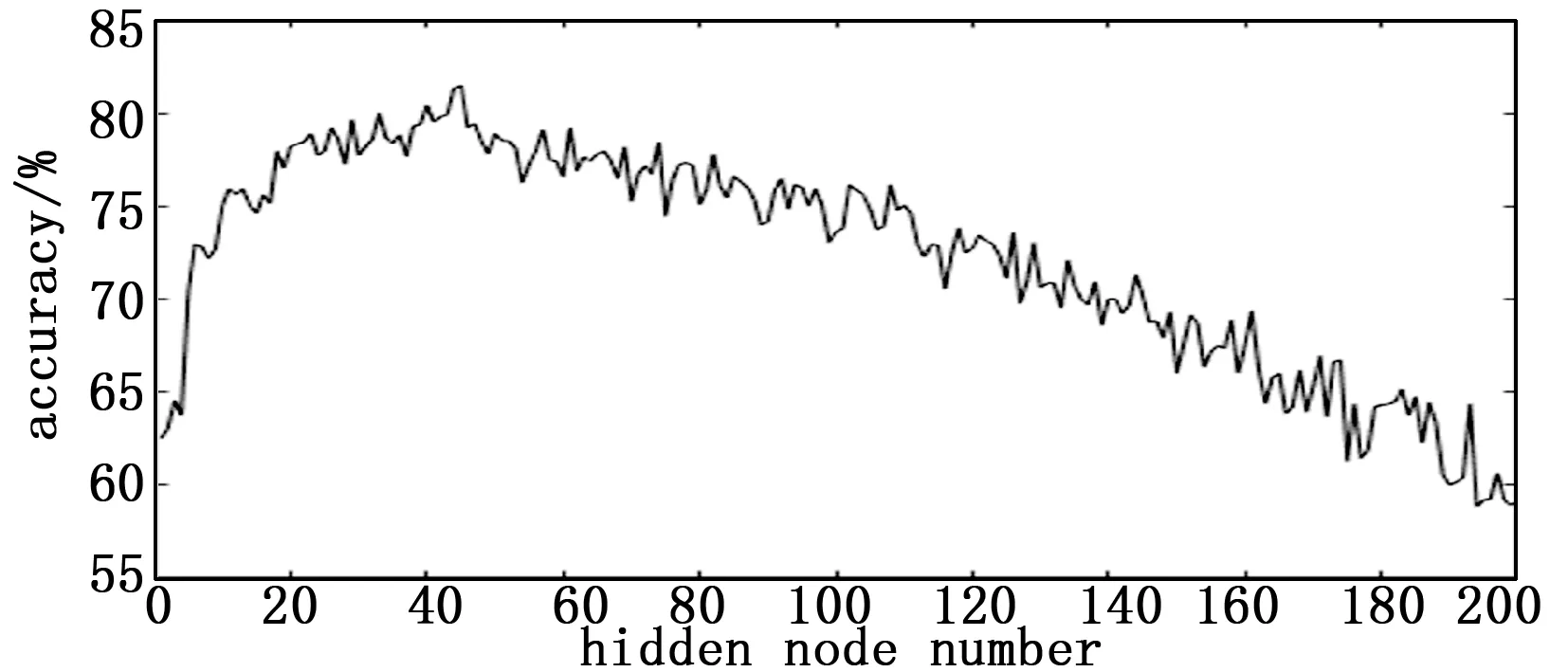
图1 ELM模型不同隐含层节点个数的验证准确率

图2 ELM-AdaBoost.M2模型不同隐含层节点个数的验证准确率
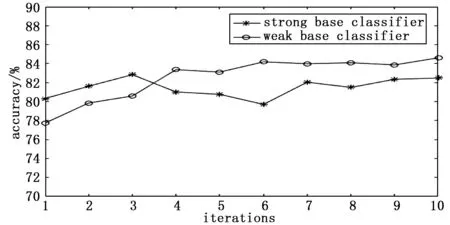
图3 基分类器验证准确率
图3所示为弱分类器迭代10次的交叉验证准确率趋势图,可以看出,较强的弱分类器随着迭代次数的增加,不仅最终交叉验证准确率提升远低于较弱的弱分类器,同时鲁棒性也低于较弱的弱分类器,而较弱的弱分类器的交叉验证准确率稳中有升,最终迭代组成的强分类器的交叉验证准确率提升明显。综合对图1~图3的分析可知,对于ELM-AdaBoost.M2模型而言,隐含层的节点数与弱分类器的个数对模型的性能均有较大的影响。所以利用GA算法对隐含层节点个数与迭代次数进行寻优,隐含层节点的搜索范围为[10,200]和迭代次数的搜索范围为[5,20]。得到结果,当ELM-AdaBoost.M2模型在节点数为23和迭代次数为15次数时,交叉验证的准确率达到最佳。
模型进行在线故障诊断后,得到的每一组新样本都需加入模型进行更新。历史数据集通常采用限定记忆法来保持其容量,即当加入一组新数据时,便删除最早的一组样本数据,从而保证模型始终包含新数据的信息。本文中各模型的在线仿真实验均进行10次,得到的数据为10次试验的算术平均值,各模型的在线诊断结果如表2所示。

表2 4种模型的在线诊断结果Model
从表2中可以看出,BP神经网络模型的模型训练时间尚可,但准确率acc和F1-score皆为最低,原因在于BP神经网络在学习过程中陷入了局部最小点未达到全局最优,其中对少数类的识别率过低是造成其F1-score最低的主要原因;相对于BP神经网络模型,SVM模型的acc仅提高0.54%,但F1-score却提高了9.82%,原因在于SVM基于核函数将原始数据映射到高维特征空间后降低了原始数据的强非线性,对于少数类的识别率有所提升,但数据维数的增加也大幅的增加了模型的训练时间,所耗时间远大于文中其他模型;ELM模型将传统的SLFN参数的训练转换成对线性方程组的求解问题,大大地减少了模型训练时间,相比于BP神经网络模型降低了12倍,另外acc提高了1.07%,F1-score提高了6.17%,原因是ELM模型对于少数类的识别率高于BP模型;ELM-AdaBoost.M2模型消耗的训练时间多于ELM模型是因为组合弱分类器的过程造成,集成的ELM-AdaBoost.M2强分类器模型,相比于基于BP、SVM和ELM的故障诊断模型,acc分别提高了4.53%、3.99%和3.46%,F1-score分别提高了21.67%、11.85%和15.5%,不仅提升了模型的准确率,也大幅提升了F1-score,可以看出该模型对于少数类的识别率较为理想,较好地克服了具有不平衡分布数据集对传统分类算法带来的影响,该模型一次更新和测试的总时间平均为0.77s,可以满足污水处理过程故障诊断对于实时性的要求。
结合以上分析,基于ELM-AdaBoost.M2的污水处理故障诊断模型综合性能优于其他模型,满足实际污水处理中对于
实时性和准确性的要求。
3 结论
污水处理是一个复杂的生化反应过程,具有强非线性特征,对其运行过程进行在线故障诊断是减少污染和保障安全生产的重要方法之一。针对污水处理过程运行状态的不平衡分布造成故障诊断准确率下降的问题,本文提出一种基于ELM-AdaBoost.M2的污水处理过程在线故障诊断模型。该模型以ELM为弱分类器,利用AdaBoost.M2算法对弱分类器的集成提升作用,组成强分类器,建立了污水处理过程的在线故障诊断模型。仿真实验结果表明,相对传统模型,该模型兼具学习速度快、分类准确率高和泛化能力强等优点,克服了污水处理过程状态不平衡分布带来的不良影响,较好地实现对污水处理过程的在线故障诊断。
[1] 张瑞成,王 宇,李 冲. 基于NW型小世界人工神经网络的污水出水水质预测[J]. 计算机测量与控制, 2016, 24(1): 61-63.
[2]FuenteMJ,VegaP.Neuralnetworksappliedtofaultdetectionofabiotechnologicalprocess[J].EngineeringApplicationofArtificialIntelligence, 1999, 12(5): 569-584.
[3] 王华忠,张雪申,俞金寿.基于支持向量机的故障诊断方法[J]. 华东理工大学学报: 自然科学版, 2004, 30(2): 179-182.
[4] 李晓东, 曾光明, 蒋 茹, 等. 改进支持向量机对污水处理厂运行状况的故障诊断[J]. 湖南大学学报: 自然科学版, 2007, 34(12): 68-71.
[5]TianY,QiaoJF.NeuralnetworksoftmeasurementofBODbasedongeneticalgorithm[J].ComputerTechnologyandDevelopment, 2009, 19(3): 127-133.
[6]TippingME.SparseBayesianlearningandtherelevancevectormachine[J].JournalofMachineLearningResearch, 2001, 1(3): 211-244.
[7]HuangGB,ZhuQY,SIEWCK.Extremelearningmachine:anewlearningschemeoffeedforwardneuralnetworks[A].Proceedingsof2004IEEEInternationalJointConferenceonNeuralNetworks[C]. 2004: 985-990.
[8]HuangGB,ZhuQY,SIEWCK.Extremelearningmachine:theoryandapplication[J].Neuro-computing, 2006, 70(1): 489-501.
[9] 许有才,万 舟,汤 超.基于IFD与DE-ELM的轴承故障诊断[J]. 计算机测量与控制, 2015, 23(12): 3990-3994.
[10] 曹 莹, 苗启广, 刘家辰, 等AdaBoost算法研究进展与展望[J]. 自动化学报, 2013, 39(6): 745-758.
[11]ZhuJ,ZouH,RossetS,etal.Multi-classAdaBoost[J].StatisticandItsInterface, 2009, 2(1): 349-360.
猜你喜欢
中国应急管理科学(2022年2期)2022-05-23
电子产品世界(2022年4期)2022-04-21
建材发展导向(2022年2期)2022-03-08
今日农业(2021年20期)2021-11-26
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
计算机系统应用(2021年2期)2021-02-23
健康体检与管理(2021年10期)2021-01-03
电子技术与软件工程(2019年18期)2019-11-18
