
基于预测的Spark动态资源分配策略
2018-02-12 12:24梁毅程石帆常世禄刘飞
软件导刊 2018年12期
梁毅 程石帆 常世禄 刘飞
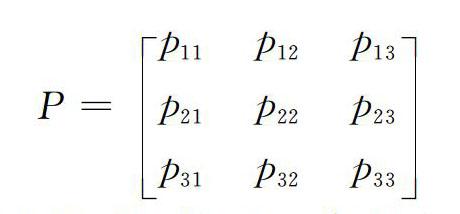

摘要:分布式内存计算平台Spark是海量数据处理领域的最新技术进展。动态资源分配下Spark可根据应用的负载情况动态地追增、关闭任务执行器。然而,关闭任务执行器会造成缓存数据丢失,导致不必要的重计算开销,该情况在Spark交互式数据查询应用中尤为常见。为尽量减少任务执行器关闭以提升查询效率,设计实现一种基于预测的Spark动态资源分配策略。该策略基于马尔科夫理论构建Spark交互式数据查询应用的非活跃期持续时间预测模型,并依据预测结果确定任务执行器的关闭时机。试验结果表明,相比既有的Spark动态资源分配策略,采用基于预测的资源分配策略可使Spark交互式数据查询效率平均提升59.34%。
关键词:分布式计算平台;Spark;大数据处理技术;动态资源分配;数据查询
DOIDOI:10.11907/rjdk.181493
中图分类号:TP3-05
文献标识码:A文章编号文章编号:1672 7800(2018)012 0043 05
Prediction based Dynamic Resource Allocation Strategy for Spark Platform
LIANG Yi, CHENG Shi fan, CHANG Shi lu, LIU Fei
(Computer Academy,Beijing University of Technology,Beijing 100124,China)
Abstract:The distributed in memory computing framework Spark is the latest technological advancement in the field of massive data processing. Under dynamic resource allocation, Spark can dynamically increase and close executors according to the workload of the application. However, removing executors would result in the loss of cached data and lead to unnecessary recomputing cost. This situation is particularly common in Spark interactive data query applications. Therefore, it is necessary to minimize the closing of the executors to improve the query efficiency. This paper designs and implements a prediction based dynamic resource allocation strategy for Spark platform. This strategy constructs a non active duration prediction model of Spark interactive data query application based on Markov theory, and determines the closing time of executors according to the prediction result. The experimental results show that compared with Sparks dynamic resource allocation strategy, the efficiency of Sparks interactive data query can be improved by 59.34%.
Key Words:distributed comuting platform; Spark; big data processing technology; dynamic resource allocation; data query
0 引言
隨着互联网蓬勃发展,当今社会已进入大数据时代[1]。与传统数据不同,大数据时代的数据具有4个显著特征:规模性、多样性、高速性和价值性。为了应对该新特征,利用多个计算节点协同计算以增强数据处理能力的分布式数据处理技术受到学术界和工业界广泛关注[2]。Spark是继Hadoop之后的下一代大数据核心处理技术,是海量数据处理领域的最新技术进展[3]。
Spark平台所有任务均在任务执行器中执行,任务执行器是包含CPU资源和内存资源的载体。为了充分利用平台资源,Spark提供动态资源分配技术。动态资源分配技术可根据Spark应用负载到达强度,追增或关闭任务执行器。如果任务执行器闲置时间超过用户设定的阈值,则会关闭该任务执行器。同样地,在交互式数据查询应用(下称“应用”)下,如果连续两个查询间隔时间超过了用户设定的阈值,也会关闭该应用任务执行器,造成缓存数据丢失。下次查询到来时,如果使用丢失的缓存数据就会带来重计算开销,影响查询的响应时间。因此,优化海量数据处理平台下的动态资源分配方式受到学术界广泛关注。Hadoop平台动态资源分配优化主要是解决Map和Reduce阶段的数据倾斜问题[4 5]以及任务执行本地化问题[6 7],通常依据对任务执行特征和数据分布特征调整不同节点的资源。也有一些动态资源分配研究是关于流式处理平台Storm[8]或Spark Streaming[9]的,主要针对流式处理中数据到达率的不同,对流式处理应用所占用资源进行动态增减[10 11]。还有一些针对云环境下的动态资源分配,面向云环境下不同计算框架对计算资源进行追增或减少[12 13]。
上述既有动态资源策略的优化方法不能平移到既有Spark平台的动态资源分配上。因为Spark以任务执行器作为任务载体,不存在Map和Reduce阶段,也不存在多计算框架共用资源,而Spark应用中除了流式应用,还包含在线交互式数据查询等多种应用。
本文分析了既有Spark动态资源分配的不足,提出基于马尔可夫预测结果的Spark动态资源分配策略。该策略可先根据应用历史非活跃期的持续时间预测应用下次处于非活跃期的时间变化,再根据预测结果决定应用下次处于非活跃期时是否关闭任务执行器。
1 相关技术
1.1 Spark系统简介
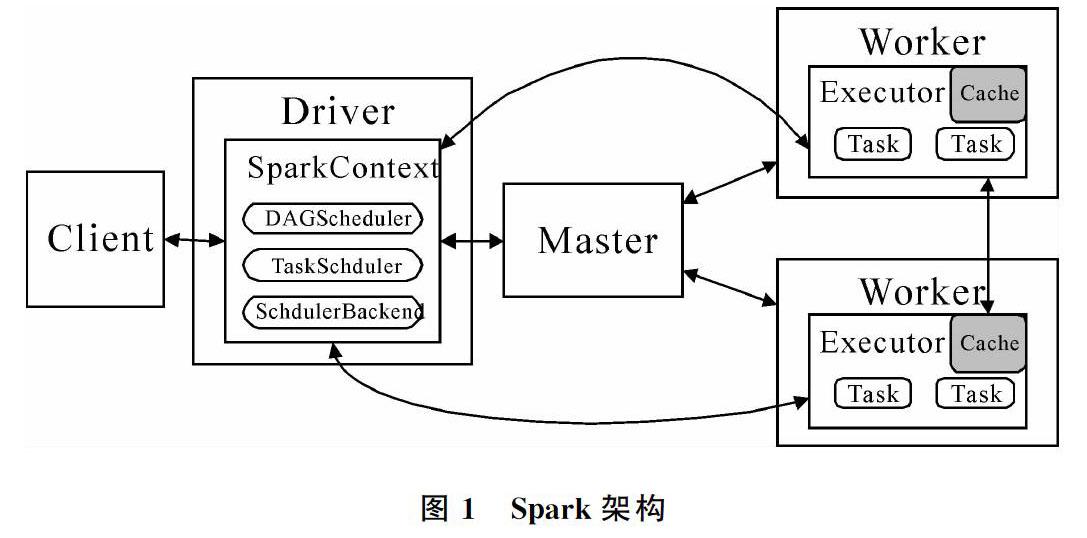
Apache Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架。最初在2009年由加州大学伯克利分校AMPLab开发,并于2010年成为Apache的开源项目之一。在Spark缺省的Standalone部署模式下,其架构如图1所示。
Spark平台采用Master/Slave架构,包含一个Master和多个Worker。其中,Master主要负责管理平台中用户提交的应用和资源分配,Worker主要负责为应用启动任务执行器(Executor);Driver中SparkContext是用户在客户端(Client)编写的对象。SparkContext中包含一个DAGScheduler对象、一个TaskScheduler对象和一个SchedulerBackend对象。在Spark平台架构中,Executor是任务真正执行和缓存数据真正存储的地方。
1.2 Spark运行环境
Spark运行环境如图2所示。Spark引入新的抽象弹性分布式数据集(Resilient Distributed Datasets,RDDs)[14]作为分布式数据集的抽象表达。RDDs将输入数据和计算过程中产生的中间数据尽量保存在内存中,直到计算流程的最后阶段才写入持久化存储,从而减少多次读写磁盘的I/O消耗。并且,Spark大数据平台以有向无环图(Directed Acyclic Graph,DAG)描述更加复杂的数据处理逻辑,并提供了更加丰富的操作算子[15 16]。
1.3 Spark动态资源分配
Spark提供了以任务执行器为粒度的动态资源分配方式[19]。以任务执行器为粒度是指动态资源分配方式可以根据不同阶段的负载强度,以任务执行器为粒度,动态地追增或回收该应用占用的CPU和内存资源。在以任务执行器为粒度的动态资源分配方式下,Spark会周期性地检测某个应用是否存在任务处于等待调度状态,如果是,就为该应用追增任务执行器;否则,结束该轮追增过程。Spark每次为应用追增任务执行器的数量与检测次数成2的幂次方函数关系。例如:Spark在第一次检测到应用需要被追增任务执行器时,只会追增1个任务执行器,在第二、三次检测到应用需要被追增任务执行器时,就会追增2、4个任务执行器,以此类推,直到检测到该应用不存在任务处于等待调度状态。回收任务执行器的流程相对简单,当任务执行器的“闲置(没有任务执行)”时间超过用户设定的阈值时,直接关闭任务执行器。关闭任务执行器既可以释放任务执行器的CPU资源,又可以释放任务执行器的内存资源。如果应用的任务执行器数量已达到用户设置的阈值,即使这些任务执行器处于闲置状态的持续时间已经超过用户设定的阈值,也不会触发关闭任务执行器机制。也就是说,每个应用都有自己的最小任务执行器数量。
2 基于马尔可夫模型预测的Spark动态资源分配
2.1 马尔可夫模型
马尔可夫模型(Markov Model)是一种统计模型,用于研究随机过程。适用于马尔可夫模型的随机过程称作马尔可夫过程。
2.1.1 馬尔可夫过程
马尔可夫(1956-1922)是俄国著名数学家,马尔可夫过程因被他提出而命名。马尔可夫过程简称马氏过程,它主要描述了实际可能会遇到的一种随机过程,其特点是在当前时刻状态已知的条件下,随机过程所处状态仅与当前时刻状态有关,而与过程在前的状态无关,该特性被称为马尔可夫性或无后效性。现实生活中有许多过程都是马尔可夫过程。马尔可夫过程的数学定义如下:
定义1 设 {X(t),t∈T}为一随机过程,如果对于时间t的任意n个值t 1<t 2<…<t n,在X(t i)=x i,i=1,2,…,n-1的条件下,X(t n)的分布函数恰好等于在X(t n-1)=X n-1条件下X(t n) 的分布函数,即:
则称随机过程 X(t) 为马尔可夫过程。
Spark交互式数据查询应用非活跃期持续时间的变化是无规律的,非活跃期持续时间变长、变短或不变都只与当前状态有关,而与历史状态无关。因此,可以使用马尔可夫模型预测Spark交互式数据查询应用非活跃期持续时间的变化。
2.1.2 马尔可夫链
马尔克夫链是马尔可夫过程中最简单的一类。定义如下:
定义2 设马尔可夫过程 {X(t),t∈T}的状态空间为I,且对离散空间I中的随机序列{X n,n=0,1,2…},若在任意时刻n以及任意的状态i 0,i 1,…,i n-1 ,满足:
则随机序列 {X n,n=0,1,2…} 为马尔可夫链。
2.1.3 一步转移概率
定义3 设随机序列 {X n,n=0,1,2…}为一条马尔可夫链,状态空间为I ,称条件概率,式(3)为马尔可夫链在时刻 n 的一步转移概率。
由于从状态i出发,经过一步转移后,必须能够到达状态空间I的一个状态,故一步转移概率p ij(n)需满足下列条件:①p ij(n)≥0,i,j∈I;②∑ p ij(n)=1,i∈I。
定义4 若任意 i,j∈I,马尔可夫链{X n,n=0,1,2…}的转移概率p ij(n)与n无关,则称马尔可夫链是齐次的,并令p ij(n)为p ij 。
2.1.4 状态转移矩阵
定义5 设 P为一步转移概率p ij 所组成的矩阵为一步转移概率矩阵,则式(4)为一步转移概率矩阵。
通过马尔可夫模型,可以对某个随机问题历史数据构成的时间序列进行分析,根据该时间序列中各状态之间的一步转移概率构造出一步转移概率矩阵,然后使用转移概率矩阵与当前状态作为输入,给出下一个状态的预测状态。
2.2 交互式数据应用非活跃期持续时间预测
由于Spark交互式数据查询应用非活跃期持续时间是波动的,该策略利用马尔可夫链方法,建立了一个随机状态链,将交互式应用非活跃期持续时间看作是马尔可夫过程中的各个状态,对交互式应用非活跃期持续时间进行基于概率的预测。该策略中状态空间的定义为定义6。
定义6 状态空间 I 。该策略中马尔可夫模型划分各个状态,用以描述未来交互式应用非活跃期持续时间的变化趋势,其定义如式(5)所示。
其中, X表示预测模型的状态空间,x 1表示交互式数据查询应用非活跃期持续时间变长,x 2表示交互式数据查询应用非活跃期持续时间不变,x 3 表示交互式数据查询应用非活跃期持续时间变短。
算法中一步状态转移概率可以通过对历史数据分析和当前状态求得,假设当前状态为 x i,转移之后可能的状态为x j(x i,x j∈I),那么当前状态从x i转移到x j状态的概率p ij 计算方法如式(6)所示。
其中,N x ix j表示历史数据中从x i转移到x j状态的总次数,∑N x i表示历史数据中从当前状态x i转移的所有可能的转移次数。有了p ij的值,就可以定义一步状态转移矩阵P:
P=p 11p 12p 13 p 21p 22p 23 p 31p 32p 33
根据一步状态转移矩阵 P 可求得当前状态转移的下一个最有可能的状态。
下面给出基于马尔可夫模型的交互式数据查询应用非活跃期持续时间预测算法。
算法1 交互式数据查询应用非活跃期持续时间预测算法
Input:交互式数据查询应用非活跃期历史持续时间数据T n,当前状态x i
Output:交互式数据查询应用下一次非活跃期持续时间的状态变化x j
//计算历史数据中从当前状态x i转移的所有可能的转移次数
∑N x i ←computeTotalTimes(T n,x i )
//計算历史数据中从当前状态x i转移的所有到x j状态的转移次数
for(j←1 to 3)
N x i x j←computeTimes(T n,x j,x i)
end for
//计算所有转移到x j的概率
for(j←1 to 3)
p ij←N x i x j∑N x i
end for
//构建一步转移矩阵
P←mat(p ij)
//从一步转移矩阵中找出从x i转移最大概率的x j
for(j←1 to 3)
p ij←max(P)
end for
//返回预测状态
return x j
通过上述算法,先构建马尔可夫模型的一步转移矩阵,然后根据一步转移矩阵中概率的最大值预测交互式数据查询应用非活跃期持续时间变化。
2.3 基于预测结果的Spark动态资源分配策略
基于马尔可夫预测结果的Spark动态资源分配策略,具体基于算法1的预测结果,判断应用下次处于非活跃期时是否应该关闭任务执行器。
算法2 基于预测结果的Spark动态资源分配算法
Input:算法1返回的预测状态
Output:是否应该移除任务执行器
Input:算法1返回的预测状态x j
Output:是否应该移除任务执行器isRemoving
if(x j==x 1)
isRemoving←true
end if
else
isRemoving←false
end else
算法2與算法1都是在作业提交时触发的。由算法2可知,如果预测到应用下次处于非活跃期时间变长,就认为应用下次处于非活跃期时应该关闭任务执行器;否则,认为应用下次处于非活跃期时不应该关闭任务执行器。当Spark达到满足关闭任务执行器的时间阈值时,如果为true,则关闭任务执行器;否则,不要关闭任务执行器。
2.4 系统实现
数据放置策略是基于Spark Standalone集群部署模式实现的。在Spark Standalone 集群部署模式下,改造后的Spark系统架构如图3所示。
在图3中,Driver端新增了统计历史非活跃期持续时间机制。DAGScheduler负责检测用户是否在交互式数据查询应用中提交了作业。一旦检测到用户提交了作业,算法1就会触发,同时,DAGScheduler会统计系统当前时间作为作业开始时间。当作业执行完毕后,Driver会把作业执行完毕时间作为非活跃期开始时间。T begin和T end都保存在BlockManagerMsater中。本轮作业开始时间与上一轮作业结束时间即为上一轮作业结束后应用非活跃期的持续时间。每当作业执行完毕,ExecutorAllocationManager(EAM)就会根据算法2决定应用下轮处于非活跃期时是否应该尝试关闭任务执行器。
3 性能评估
3.1 实验环境及负载选择
实验测试环境由7台物理节点构成,每台节点软、硬件配置如表1所示。在测试环境中,1台物理节点作为主节点,其余6个节点作为从节点。
为了验证预测策略所带来的性能提升及预测准确度,实验在输入数据、任务执行器保留数量和任务执行器内存一定的情况下进行,选取对象为Spark原始的动态资源分配策略。其中,输入数据为“TPC H”,生成12GB表数据,任务执行器保留数量为3个,内存为8GB,过期时间统一设置为30s。
实验选取Spark SQL作为测试应用,TPC H on Hive中的q1到q10作为查询负载,且每个查询负载的时间间隔如表2所示。表2中,q1的时间间隔为80s,指的是缓存12GB表数据后需经过80s提交查询q1;q2的时间间隔为60s指的是查询q1执行完成后需经过60s提交查询q2。以此类推,在每次查询结束后统计各个查询执行时间。
3.2 实验结果及分析
实验结果如图4所示。从图4可以看出,使用预测算法的Spark动态资源分配策略在查询q5、q7、q8和q9时,所用时间比原始Spark动态资源分配策略分别缩短了47.55%、56.72%、80.42%和52.7%。这是因为在q4、q6、q7和q8查询开始时,预测策略预测到该查询结束后Spark SQL的非活跃期时间变短,因此在查询该查询结束后均没有关闭任务执行器,从而提升了查询q5、q7、q8和q9的执行速度。综上所述,使用预测算法的Spark动态资源分配策略相比原始Spark动态资源分配策略,查询效率最大提升了80.42%,平均提升了59.34%。
4 结语
本文面向Spark海量数据处理平台的动态资源分配,设计并实现了基于马尔可夫的预测策略。通过对Spark交互式数据查询应用历史非活跃期的持续时间预测应用下一次处于非活跃期的时间变化,从而避免任务执行器频繁关闭带来的缓存数据重计算开销。基于马尔可夫预测模型对Spark交互式查询应用的非活跃期进行预测,再根据预测结果决定是否移除任务执行器,能够有效提高Spark查询的执行效率。实验表明,本文预测方法可以使Spark SQL查询效率平均提升59.34%。
参考文献:
[1] 陶雪娇,胡晓峰,刘洋.大数据研究综述[J].系统仿真学报,2013(s1):142 146.
[2] 戴炳荣,宋俊典,钱俊玲.云计算环境下海量分布式数据处理协同机制的研究[J].计算机应用与软件,2013,30(1):107 110.
[3] ZAHARIA M, CHOWDHURY M, FRANKLIN M J, et al. Spark: cluster computing with working sets[J]. Usenix Conference on Hot Topics in Cloud Computing,2010,15(1):10.
[4] LIU Z, ZHANG Q, ZHANI M F, et al. DREAMS: dynamic resource allocation for MapReduce with data skew[C]. International Symposium on Integrated Network Management,2015:18 26.
[5] LIU Z, ZHANG Q, AHMED R, et al. Dynamic resource allocation for MapReduce with partitioning skew[J]. IEEE Transactions on Computers,2016,65(11):3304 3317.
[6] SHAO Y, LI C, DONG W, et al. Energy aware dynamic resource allocation on Hadoop yarn cluster[C]. IEEE International Conference on High PERFORMANCE Computing and Communications; IEEE International Conference on Smart City; IEEE International Conference on Data Science and Systems,2016:364 371.
[7] MADSEN K G S, ZHOU Y. Dynamic resource management in a map reduce style platform for fast data processing[C]. IEEE International Conference on Data Engineering Workshops,2014:10 13.
[8] FRACHTENBERG E, PETRINI F, FERNANDEZ J, et al. STORM: lightning fast resource management[C].Supercomputing, ACM/IEEE 2002 Conference,2002:1 26.
[9] ZAHARIA M, XIN R S, WENDELL P, et al. Apache Spark: a unified engine for big data processing[J]. Communications of the Acm,2016,59(11):56 65.
[10] CHENG D, CHEN Y, ZHOU X, et al. Adaptive scheduling of parallel jobs in spark streaming[C]. INFOCOM 2017 IEEE Conference on Computer Communications,2017:1 9.
[11] LIAO X, GAO Z, JI W, et al. An enforcement of real time scheduling in Spark streaming[C]. Green Computing Conference and Sustainable Computing Conference IEEE,2016:1 6.
[12] WARNEKE D, KAO O. Exploiting dynamic resource allocation for efficient parallel data processing in the cloud[J]. IEEE Transactions on Parallel & Distributed Systems,2011,22(6):985 997.
[13] AN B, LESSER V, IRWIN D, et al. Automated negotiation with decommitment for dynamic resource allocation in cloud computing[C]. International Conference on Autonomous Agents and Multiagent Systems,2010:981 988.
[14] ZAHARIA M, CHOWDHURY M, DAS T, et al. Resilient distributed datasets: a fault tolerant abstraction for in memory cluster computing[J]. Usenix Conference on Networked Systems Design and Implementation,2012,70(2):2.
[15] ISARD M, BUDIU M, YU Y, et al. Dryad: distributed data parallel programs from sequential building blocks[C]. Proceedings of the 2007 EuroSys Conference,2007:59 72.
[16] YU Y, ISARD M, FETTERLY D, et al. DryadLINQ: a system for general purpose distributed data parallel computing using a high level language[C]. Usenix Conference on Operating Systems Design &Implementation,2008:1 14.
