
基于卷积神经网络的监控场景下行人属性识别
2018-02-09 17:54胡诚陈亮张勋孙韶媛
现代计算机 2018年1期
胡诚,陈亮,张勋,孙韶媛
(1.东华大学信息科学与技术学院,上海 201620;2.东华大学数字化纺织服装技术教育部工程研究中心,上海 201620)
0 引言
行人视觉属性识别,由于它的高层的语义信息,可以建立人的底层特征和高层认知的联系。因此在计算机视觉领域是一个很热门的研究方向。并且在很多的领域也取得了成功。例如:图片检索、目标检测、人脸识别。近些年,随着平安城市的概念的提出,数以万计的监控摄像头装在了城市的各个角落,保护着人们的安全。因此,监控场景下的行人视觉属性的识别具有重要的研究价值,并且它也在智能视频监控和智能商业视频有很大的市场前景。
当前大多数的行人属性识别研究主要在两个应用场景:自然场景和监控场景。自然场景下的属性识别研究较多,在目标识别、人脸识别等研究方向上也取得了很好的成绩。例如,自然场景下的属性识别的研究最早是Ferriari[1]提出。在他的论文中,提出了概率生成模型去学习低层次的视觉属性,例如:条纹和斑点。Zhang[2]提出了姿态对齐神经网络,在没有约束的场景下,对图片进行像年龄、性别和表情这些属性的识别。在自然场景下用于行人属性识别研究的样本图片的分辨率都很高。然而监控场景下的行人样本的图片分辨率较低,并且很模糊。像行人戴眼镜这样的细粒度的属性是很难识别出来的。主要是在真实的监控场景中,是远距离拍摄行人的,很少能拍摄的到近距离的清晰的人脸和身体。监控场景下的远距离拍摄也容易受到一些不可控的因素的影响。例如,光照强度的变化(例如白天和夜晚,室内和室外),监控摄像头不同的拍摄角度行人姿态的不同的变化,现实环境中物体的遮挡等等。因此,使用远距离拍摄的脸部或者行人身体的视觉信息来进行属性识别,这对监控场景下的行人属性识别的研究工作带来挑战。
由于上述的种种问题,国内外对于监控场景下的行人属性识别的研究工作还是比较少。Layne[3]是第一个通过使用支持向量机(SVM)去识别像背包、性别这样的行人属性,然后通过这些行人属性信息来辅助行人的重识别。为了解决混合场景下的属性识别问题,Zhu[4]引入了APis数据库,并用Boosting算法去识别属性。Deng[5]构建了最大的行人属性数据库,在这个数据集的基础上使用支持向量机和马尔科夫随机场去识别属性。然而这些方法,都是使用人工提取行人特征。而人工提取特征需要依赖人的经验。经验的好坏决定了属性特征识别的精确度。另外,这些方法也忽略了属性特征之间的关联。例如,长头发这个属性特征是女性的可能性一定是高于男性的。所以头发的长度有助于提高行人的性别的属性的识别精度。
受到卷积神经网络在计算机视觉领域上广泛的应用的启发。本文提出了一种在监控场景下基于卷积神经网络来识别行人属性的方法。卷积神经网络在训练过程中可以自动提取行人特征。重新定义新的损失函数,同时考虑所有行人属性特征之间的联系。与人工提取特征的方法相比,操作简单,有效地利用了行人属性特征之间的联系,提高了属性的识别精度。
1 网络结构
深度学习是机器学习研究中的新的领域。其目的是建立、模拟人脑进行分析学习的神经网络。模拟人脑的机制来解释数据,例如图像、语音等。
1.1 卷积神经网络
卷积神经网络(Convolutional Neural Networks)是深度学习的一种,目前已成为语音识别和图像识别领域的研究热点。一个典型的卷积神经网络结构,主要由卷积层、激励层、池化层、全连接层等叠加而成。由于卷积神经网络的局部感受野和权值共享的特点,降低网络参数选择的复杂度。图像可以直接作为网络的输入,避免了传统图像识别算法中的复杂的特征提取和数据重建的过程。
1.2 AlexNet卷积神经网络
Krizhevsky[6]等人提出了一种新型卷积神经网络(简称AlexNet)在2012年大规模视觉识别挑战竞赛中,赢得了第一名,Top-5错误率为15.3%,比上一届冠军下降了10%。该网络模型在图片识别上十分出色。典型的AlexNet网络结构如表1所示。总共有8层,其前五层是卷积层,即卷积层1、卷积层2、卷积层3、卷积层4、卷积层5。卷积层的作用是进行特征提取。后三层是全连接层,即全连接层6、全连接层7、全连接层8。全连接层的作用是连接所有的特征,将输出值输入给Softmax分类器。每一层都采用ReLu函数,能保证数据输入与输出是可微的。在第一个和第二个ReLu函数后是响应归一化和最大化池化操作,同时第五个卷积层后也是最大化池化操作。另外,全连接层8,也是输出层,输出1000个节点,对应1000个类别,应用Softmax回归函数得到分类值。
尽管AlexNet网络模型在图像识别上表现很出色,但是却存在两方面的问题:第一,该网络模型目前应用的场景是自然场景,图片样本的分辨率高。第二,AlexNet处理的图片识别问题都是单标签分类问题。即卷积神经网络训练的时候,输入给网络是一张图片和对应的单个标签。真实监控场景中,每一个行人样本图片中有性别、头发、上下身衣服类型和颜色等多种属性。所以,AlexNet网络模型无法直接解决行人属性识别问题。
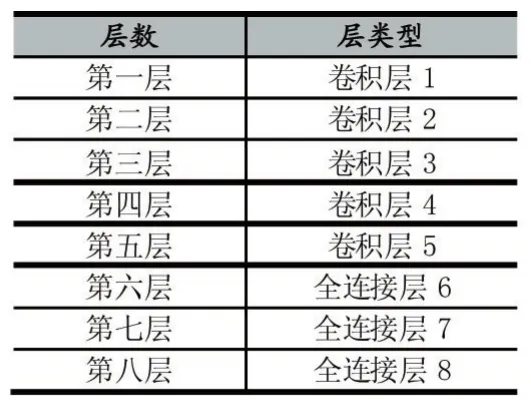
表1 AlexNet卷积神经网络结构
1.3 行人属性识别模型
假设行人样本中有N张图片,每张图片标注了L个行人属性。比如性别、头发长度、年龄等。每张行人图片可以表示xi,i∈[1,2…,N]。每张图片xi对应的行人属性标签向量为yi。每个标签向量yi对应的属性值为如果yil=1,表明这个训练样本xi有这个属性;yil=0,表明这个训练样本xi没有这个属性。
本文提出了一种基于卷积神经网络的行人属性识别模型(如图1)。该模型是基于AlexNet网络模型微调的。基本网络结构与AlexNet相同,层数也是8层(前五层是卷积层,后三层是全连接层)。在模型训练阶段,本文模型的输入是一张行人图片和对应的行人属性标签向量。测试阶段,模型的输出是对行人样本图片预测的属性类别。
通常,属性之间是有关联的。而大多数的属性识别方法会把每一个属性独立起来,忽略了属性之间的关联信息。例如头发的长度可以提高性别的识别精度。为了更好地利用属性之间的关联,提高行人属性的识别精度。本文重新提出了一种新的损失函数,这样本文的模型在训练过程中可以同时学习所有的行人属性。损失函数(loss fuction)PLOSS如下所示。
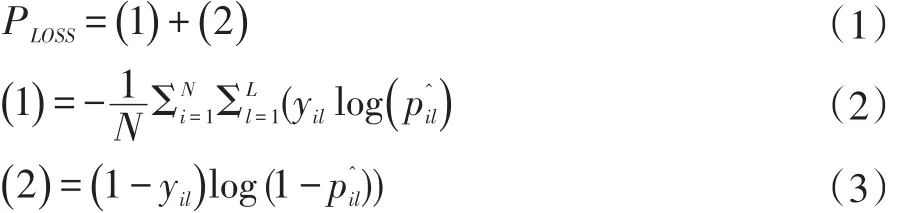
表示是行人样本x的第l个属性的概率。y是iil真实属性标签,表示行人样本xi有没有第l个属性。

图1 本文的属性识别模型
2 实验
2.1 实验环境
本文算法采取的实验的软硬件环境配置:操作系统是Ubuntu14.04,内存是 8GB,CPU是Intel i5-6600,GPU是NVIDIA GTX1070,运算平台是CUDA8.0。使用深度学习的Caffe框架。Caffe是纯粹的C++/CUDA架构,支持命令行、Python和MATLAB接口,可以直接在CPU和GPU之间无缝切换。
2.2 实验数据
本文的实验数据来源于合肥寰景信息技术有限公司与安徽大学联合创办的实验室在合肥市某地点抓拍的行人图像,通过人工标注得到每张行人图像的标注结果,以XML的形式保存。本文选取了19000张行人样本。这些行人样本都是监控摄像头远距离拍摄,然后通过行人检测算法剪切出来的,因此图片的分辨率都不高。按照一个被大家广泛采取的实验数据集划分原则,我们把19000张图片分成三部分:训练集,验证集,测试集。9500张用于训练,1900张用于验证,7600张用于测试。在网络模型训练之前,将所有图片的缩放到宽为256,高为256这样的大小。另外,本文对每一张图片都标注了12个属性标签:性别(男、女)、头发长度(长发、短发)、3种上身衣服类型(T恤、衬衫、外套)、3种上身衣服颜色(黑色、白色、红色、)、2种下身衣服的类型(长裤、长裙)、2种下身衣服的颜色(黑色、白色)。并且每一个属性标签都是二进制标签,标签值分别为0或者1,0代表这个行人样本没有这个属性,1代表这个行人有这个属性。
2.3 实验参数设置
一般而言,卷积神经网络的最低层,可以学习到一些局部的颜色和纹理特征信息。利用这些特征信息,可以进行大多数的物体的分类识别。同时,卷积神经网络的层数越多,可以学习到更高层次的语义信息,更丰富的细节信息。本文采取的卷积神经网络模型,是基于AlexNet网络模型来微调的,这样可以更好的去学习到低层次和高层次的特征信息。另外,本文是在监控场景下来进行行人的属性识别,而AlexNet是在自然场景下。所以为了使我们的网络也适应监控场景,所以设置最初的学习率(base_lr)为0.001,权重衰减(weight decay)为0.005。总共迭代20000次,每迭代2000次,学习率降为原来的1/10。为了把属性之间的联系考虑起来,采取公式(1)的损失函数。
2.4 实验流程
将用于训练的9600张和用于验证的1900张及其对应的属性标签向量,作为本文的卷积神经网络模型的输入数据。通过20000次的不断迭代学习,直至模型收敛并保存模型参数。模型训练完成的时间,根据训练模型的日志,大约耗时3个小时。然后用训练好的模型参数来对剩余的7600张测试图片进行预测。
2.5 实验指标
对于属性识别算法,大多数文献都采取平均精度(mA)作为评判指标。本文也采取平均精度作为本论文的属性识别结果的评价指标。对每一个行人属性,分别计算正样本和负样本的分类识别的精确度,然后把正样本和负样本的识别精确度的平均值来作为该属性的最终的识别精度。平均精度会把所有的行人属性的识别精度的平均值来作为本文论文算法的最后的识别率。
平均精度的计算方式,如下:
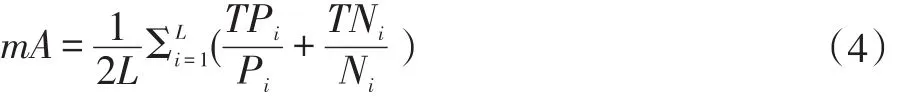
公式说明:Pi表示测试样本中第i个属性的正标签的数目,TPi表示测试样本中第i个属性的正标签被预测正确的数目。Ni表示测试样本中的第i个属性的负标签的数目,TNi表示测试样本中第i个属性的负标签被正确预测的数目。L表示行人属性总的数量。
2.6 实验结果分析
用训练好的模型,对行人样本图片进行测试,实验结果如表2示。同时为了显示本文算法的优越性。用2.2小节中的实验数据,也实验了文献[5]的方法。该论文是采取人工提取特征,并且没有考虑到属性之间的相互联系。从表3可以看出,本文提出的算法的平均精度明显高于文献[5]。行人属性的识别精度都超过了80%以上。同时下身裙子、性别的识别精度都很高,因为两者是有联系的。生活中很常见穿裙子的女性,而不常见穿裙子的男性。这说明考虑属性的相互联系,可以提高属性的识别精度。另外,头发”、“上.红”这两个属性的识别精度不是很高。主要是行人样本图片中,有些行人戴了帽子,无法检测到脸部区域的头发长度信息,导致检测头发的效果不佳。衣服颜色中某些衣服颜色的识别精度不高,比如上身红色。主要是衣服颜色与行人佩戴的围巾、背包颜色较近,在行人属性标注的时候,把它们都标注在一个包围框里,识别时产生了干扰,因而识别精度不高。
表中的上.T恤表示的是上身的衣服类型是T恤。上.黑表示的是上身的衣服的颜色是黑色。
3 结语
本文提出了基于卷积神经网络的行人属性识别算法来识别行人属性。通过实验验证,该算法可以很好地完成行人多属性识别任务,具有良好的检测效果。并且同传统的方法相比,该算法还可以自动学习特征,操作简单。但某些属性,例如“头发”、“上.红”没有达到预期的效果,原因是行人样本中的有围巾、背包、戴帽子这些干扰属性,导致本文行人属性识别模型识别时无法区分,识别到有效行人特征。在未来的工作中,希望该算法,提高这些属性的识别精度。
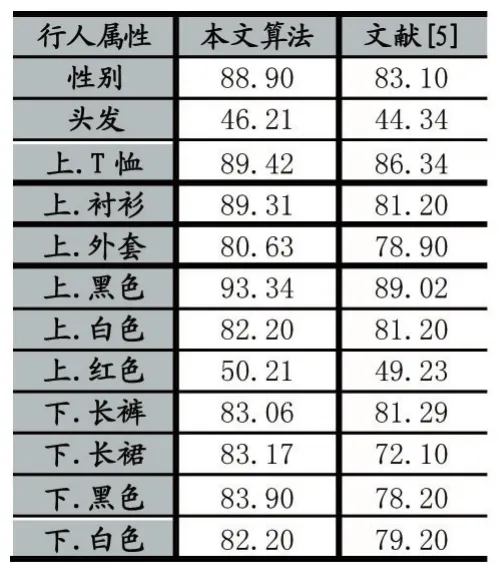
表2 不同算法的行人属性识别率的比较
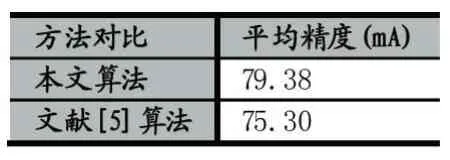
表3 本文算法与文献[5]的平均精度的比较
[1]Ferrari V,Zisserman A.Learning Visual Attributes.[J].Advances in Neural Information Processing Systems,2007:433-440.
[2]Zhang N,Paluri M,Ranzato M,et al.PANDA:Pose Aligned Networks for Deep Attribute Modeling[C].Computer Vision and Pattern Recognition.IEEE,2014:1637-1644.
[3]Layne R,Hospedales T M,Gong S.Person Re-identification by Attributes[C]//BMVC.2012.
[4]Zhu J,Liao S,Lei Z,et al.Pedestrian Attribute Classification in Surveillance:Database and Evaluation[C].IEEE International Conference on Computer Vision Workshops.IEEE,2013:331-338.
[5]Deng Y,Luo P,Chen C L,et al.Pedestrian Attribute Recognition At Far Distance[C].ACM International Conference on Multimedia.ACM,2014:789-792.
[6]Krizhevsky A,Sutskever I,Hinton G E.ImageNet Classification with Deep Convolutional Neural Networks[C].International Conference on Neural Information Processing Systems.Curran Associates Inc.2012:1097-1105.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
意林(2021年5期)2021-04-18
电子制作(2019年11期)2019-07-04
扬子江(2019年1期)2019-03-08
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
北京航空航天大学学报(2018年1期)2018-04-20
小天使·一年级语数英综合(2017年6期)2017-06-07
汽车与安全(2016年5期)2016-12-01
