
基于Hadoop系统大数据平台在天津市地震局的应用
2018-01-28 23:10丁晶李刚谭毅培
电子技术与软件工程 2017年18期
丁晶+李刚+谭毅培


摘要
随着信息化技术的不断发展,我们所接触的数据量也在呈爆炸式增长,存储的数据也由GB、TB级迈向PB、ZB级,对传统的数据存储技术带来了巨大的挑战。而HDFS分布式存储系统以其低成本与高效率满足了我们海量数据存储的需求。天津市地震局也通过建立起了Hadoop大数据平台对测震台网产生的大量宝贵的地震数据进行存储与应用。
【关键词】地震 存储技术 数据 Hadoop HDFS
随着计算机技术、网络技术的不断发展,生活中我们所接触的信息量也在呈爆炸式增长。在地震行业中也是如此,每天最少会产生几GB的SEED文件,解压后的文件达到几十GB,加上其他一些辅助信息和索引信息,每年至少会产生几十TB的数据量。而且随着地震台站数量和强震数据的不断增多,可以预见今后的测震数据增速会越来越快。如何有效存储管理这些海量数据,确保这些珍贵数据在任何情况下都不会丢失,是我们急需解决的问题。
针对这一问题,天津市地震局从2014年开始,通过对11台PC服务器建立起了Hadoop大数据系统,用于进行测震台网数据的存储与应用。
1天津市地震局Hadoop系统介绍
Hadoop系统近几年发展迅速,它是由Apache基金会所开发的分布式系统基础架构,是一种分布式处理软件框架,用户可以在不了解分布式底层细节的情况下,开发分布式程序,并充分利用计算机集群的优势进行高速运算和安全存储。Hadoop包括分布式文件系统HDFS、分布式数据库HBase、海量数据并行编程模型与计算框架MapReduce、分布式数据仓库Hive、分布式协调系统zookeeper等等。
HDFS即基于Hadoop的分布式文件系统(Hadoop Distributed File System),HDFS具有高容错性的能力,使得该文件系统具有较好的容错特性,且可以在通用平台上使用,故此能够将该文件系统在廉价的机器上部署(郝伟姣等,2009);HDFS还具备高吞吐量特性,对超大数据集系统的应用程序有着良好的支持与服务。HDFS还可以以流的形式访问文件系统中的数据。
Hbase是一个分布式的、面向列的开源数据库;它的底层数据存储是基于HDFS之上的,采用了主/从架构的模式即Hmaster/Hregionserver结构。
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算,包括大规模的文字处理、数据挖掘等。
Hive是一个构建在Hadoop上的数据仓库,通过hive存储在HDFS平台上的数据操作与传统SQL结合起来,让精通SQL编程而不太擅长java的开发人员能够轻松的向Hadoop平台迁移(刘鹏,2013)。
Zookeeper是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
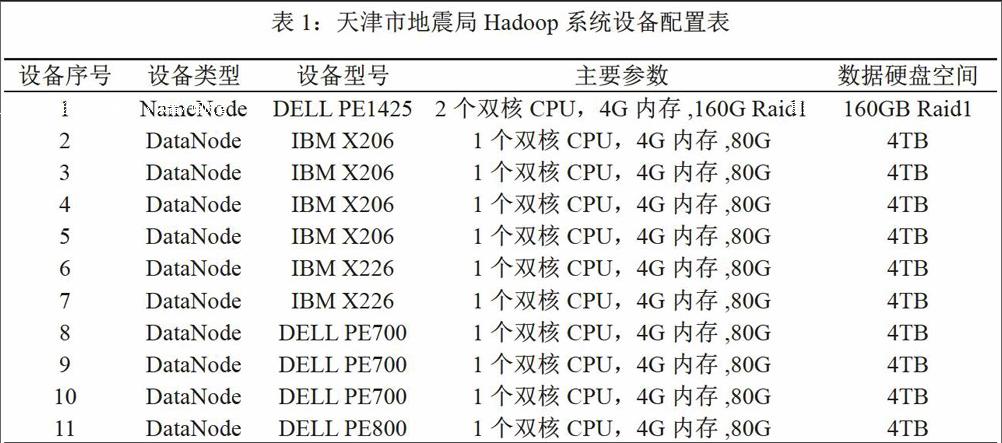
天津市地震局于2014年开始建立测试的Hadoop系统,共采用11台廉价的PC服务器来组建,存储能力为40TB,采用了主/从(Master/Slave)体系结构(刘鹏,2013),包括1个NameNode主节点、10个DataNode从节点,其中一台从节点上部署了Secondarynamnenode进程用于主节点的备份,系统结构图和配置情况如表1所示。
搭建好的系统用于天津市地震局测震台网连续波形数据在线存储与服务试验。
2Hadoop系统的设计
2.1HDFS数据存储
存储的数据由TB级迈向PB、ZB级的需求,对传统的数据存储技术带来了巨大的挑战。而HDFS分布式存储系统以其低沉本与高效率满足了我们海量数据存储的需求。
分布式文件系统HDFS将海量文件存储在一个大集群的多台计算机上。HDFS将每一个文件以分块序列的形式进行存储。
HDFS架构中包含的节点和其对应的功能:
2.1.1Namenode
Namenode即主控制器服务器,是HDFS系统的管理者,记录文件数据块在每个Datanode上的位置和副本信息,协调客户端对文件的访问,以及记录命名空间内的改动或命名空间本身属性的改动。
由于一旦主节点Namenode的设备发生故障或者Namenode进程宕掉,那么会造成系统中的文件丢失,所以为了提高我局hadoop系统的信息安全性,防止由于单点故障引起的数据丢失,故对Namenode进行备份,将Secondarynamenode节点部署在从节点(dd-11)上。
2.1.2Secondarynamenode
Secondarynamenode是为了防止Namenode成为系统的单点故障而设置的,Secondarynamenode进程会按照一定的时间间隔保存着文件系统元数据的快照,这样在系统主节点发生故障时能尽可能的减少数据的损失。(由于Secondarynamenode总是落后于Namenode,所以在Namenode宕机时,会造成部分数据的丢失。)
2.1.3Datanode
Datanode是HDFS文件系统中保存数据的节点,HDFS系统会根据你在hdfs-site.xml中设置的值将文件分割成若干的数据块,存储在不同的Datanode上。达到冗余备份的作用。
Hadoop平台可以通过修改配置文件来动态的增删计算节点,具有良好的可扩展性。Hadoop平台可以扩展到数千个节点进行大规模集群运算,并且具有对数据的自动备份功能,防止硬件的损坏造成的数据丢失(肖卫青等,2015)。
2.2Hbase简介
Hbase是基于Hadoop的开源数据库,是一套具有高可靠性、高性能、列存儲、可伸缩、实时读写的数据库系统。endprint
利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。其目的是处理庞大的表,可以用普通的计算机处理10亿行数据,并且有数百万列元素组成的数据表这张表的索引是行关键字。HBase可以直接使用本地的文件系统和Hadoop作为数据存储方式,不过为了提高数据的可靠性和系统的健壮性,发挥HBase处理大数据量等功能,需要使用Hadoop作为文件系统。
Hbase中主要包含以下几部分:
2.2.1Hmaster
Hmaster是整个Hbase系统中的主节点,它负责对各个用户的数据表进行增删改查,负责管理HRegionServer的负载均衡,调整Region分布,并且在HRegionServer停机后,负责失效HRegionServer上Region迁移。
2.2.2HRegionServer
Hbase中HRegionServer主要负责一些具体的数据存储,向HDFS文件系统中读写数据等。
2.2.3Zookeeper
Zookeeper是Hbase体系中的协调管理节点,提供分布式协作、分布式同步、配置管理等功能。
3Hadoop系统安装调试与配置
Hadoop系统的安装:
3.1软件及版本
如表2所示。
3.2在所有机器上建立相同的用户(如grid)
useradd –m grid passwd grid之后提示为用户grid设置密码
3.3下载安装Java安装在/usr下的java文件夹下
注意:安装前需提高权限(chmod755/mnt/jdk-6u24-linux-i586.bin)
3.4下载hadoop,并且解压在文件夹下
tar-zxvf/mnt/hadoop-2.5.2
3.5修改各主机名及/etc/hosts
Namenode、datanode中设置所有主机的ip和主机名。
3.6SSH的配置
该配置主要是实现各主机之间执行指令时不需要输入密码,需要在所有主机上建立.ssh目录,执行:mkdir.ssh;在namenode上生成密钥对,执行ssh-keygen-trsa;将生成的密钥远程复制到其他从节点上,执行如下命令:
cd?/.ssh
cpid rsa.pubauthorized keys
scpauthorized keysdd-ll:/home/grid/.ssh
最后进入所有主机的.ssh目录改变该文件的许可权限:
chmod 644 authorized keys
这样的话从主节点向其他从节点发起SSH连接时,只有第一次登录时才需要输入密码,以后可以实现无密钥登录。
3.7配置相应的环境变量
exportJAVA_HOME=/usr/java/jdkl.6.027/
exportJRE_HOME=/usr/java/jdkl.6.027/
jre
exportPATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
exportHADOOP_HOME=/home/grid/hadoop-2.5.2
exportHADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
exportPATH=$PATH:$HADOOPHOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/lib
3.8配置etc/hadoop/core-site.xml、etc/hadoop/hdfs-site.xml、etc/hadoop/mapred-site.xml、etc/hadoop/yarn-site.xml等四个文件
如表3所示。
3.9配置masters、slaves等参数
主节点设置为master,从节点设置为slaves
3.10将hadoop主节点的安装文件复制到其他从节点上
scp-r/home/grid/hadoop-2.5.2dd-ll:/home/
grid
scp>r/home/grid/hadoop-2.5.2dd-12:/home/grid
……
scp-r/home/grid/hadoop-2.5.2dd-20:/home/grid
3.11格式化分布式系統,命令如下
/home/grid/hadoop-2.5.2/bin/hadoopnamenode-format
3.12在主节点上启动hadoop进程
/home/grid/hadoop-2.5.2/sbin/start-all.sh
3.13在各个节点上运行/usr/java/jdkl.6.O-27/bin/jps检查各节点进程的启动情况结果
如图1所示。
Hbase系统的安装。
3.14配置Hbase环境变量
exportJAVA_HOME=/usr/java/jdkl.6.0_27/exportHADOOP_HOME=/home/grid/hadoop-2.5.2/
exportHBASE_CLASSPATH=/home/grid/hadoop-2.5.2/etc/hadoopendprint
exportHBASE_MANAGES_ZK=true(表示由Hbase负责启动和关闭Zookeeper)
3.15配置/conf/hbase-site.xml文件
修改hbase.rootdir,将其指向Hadoop集群的Namenode(端口也必须保持一致),指定Hbase的存储路径;设置Zookeeper目录以及Hmaster的路径及端口。
3.16配置Hmaster与Hregionserver
在/conf/master中输入Hmaster的节点,/conf/regionservers中输入Hregionserver节点。
3.17把Hbase复制到其他机器上命令如下:
scp-r/home/grid/hbase-0.98.11-hadoop2dd-ll:/home/grid
3.18在主节点上启动hbase进程
/home/grid/hbase-0.98.11-hadoop2/bin/start-hbase.sh
3.19在各个节点上运行/usr/java/jdkl.6.O-27/bin/jps检查各节点进程的启动情况
如图2所示。
4Hadoop系统的应用效果
根据前面方法建立起来的hadoop大数据系统与基于hadoop系统的hbase开源数据库,可以对天津市地震局测震台网产生的地震大数据进行分布式存储与应用,大量的地震波形数据可以以seed格式文件存储于HDFS文件系统中,也可以以一定时间尺度解析载入Hbase
Hadoop系统HDFS的web管理界面,此图中可以看到HDFS系统整体运行情况、快照以及任务运行状态,可以看到整个系统包含有10个从节点,总存储总容量为35.81TB。图4是各从节点的运行状况,其中可以清晰的看到各DataNode的使用情况以及磁盘利用率等数据。图5是基于Hadoop系统的Hbase开源数据库系统。可以看到各个Hregionserver节点的基本信息、存储任务以及数据表的基本情况。
感谢
系统在研究、开发和测试过程中,得到了天津市地震局周利霞、王晓磊、刘磊等的大力支持和帮助,在此表示衷心的感谢。
参考文献
[1]郝伟姣,周世健,彭大为等.基于HADOOP平台的云GIS构架研究[J].江西科学,2009,31(01):109-112.
[2]劉鹏.实战hadoop—开启通向云计算的捷径[M].北京:电子工业出版社,2013.
[3]刘军.大数据处理[M].北京:人民邮电出版社,2015.
[4]王文青.大数据架构下的地震波形数据分析应用浅析[J].电脑编程技巧与维护,2016(09).
[5]肖卫青,杨润芝,胡开喜等.Hadoop在气象数据密集型处理领域中的应用[J].气象科技,2015,43(05):823-828.endprint
猜你喜欢
高速铁路技术(2022年2期)2022-05-05
科技研究(2021年6期)2021-09-10
小学生作文(低年级适用)(2021年5期)2021-05-24
艺术启蒙(2020年6期)2020-07-16
防灾减灾学报(2018年3期)2018-10-12
中等数学(2018年1期)2018-08-01
雷达与对抗(2015年3期)2015-12-09
自动化博览(2014年12期)2014-02-28
城市道桥与防洪(2013年5期)2013-03-11
华南地震(2012年2期)2012-09-11
