
基于Hive的大数据在线分析处理
2018-01-26 16:04陈耀旺朱宁施扬朋
计算机时代 2018年1期
关键词:数据仓库
陈耀旺+朱宁+施扬朋
摘 要: 随着传统行业与互联网的快速匹配,企业面对大量堆积的业务数据和用户数据而无从下手,用户的查询需求也越来越复杂且涉及跨库、跨表的大数据量综合分析查询,传统关系型数据库的方式已无法满足企业大数据在线分析处理的要求。文章提出基于Hive的大数据在线分析的系统架构,研究数据仓库的主题构建、多维分析以及数据可视化的综合分析处理方案,满足在线查询分析结果的用户需求,相比于传统数据库的OLAP方案,查询的时间效率得到显著提升。
关键词: Hadoop; Hive; 数据仓库; 在线分析
中图分类号:TP399 文献标志码:A 文章编号:1006-8228(2018)01-01-03
Online analytic processing of big data based on Hive
Chen Yaowang1, Zhu Ning2, Shi Yangpeng2
(1. Hangzhou Dianzi University·School of Computer, Hangzhou, Zhejiang 310018, China; 2. Zhejiang Topcheer Information Technology Co., Ltd)
Abstract: Along with the traditional industry and the Internet fast matching, enterprises face large volumes of business data and user data but cannot handle, the user's query requirements are more and more complex and involve comprehensive analytical query of large cross-database data, the traditional way of using relational database has been unable to meet the requirements of enterprises online analysis and processing. In this paper, the system architecture of online data analysis based on Hive is proposed. The theme building and multidimensional analysis of data warehouse, and the comprehensive analysis of data visualization are studied to meet the needs of online query and analysis of the results. Compared with the OLAP of traditional database, the query time efficiency has been significantly improved.
Key words: Hadoop; Hive; data warehouse; online analysis
0 引言
隨着传统行业与互联网的快速匹配,运营模式迭代更新与用户量的飞速增长,企业面对大量堆积的业务数据和用户数据无从下手,在处理TB级别以上的数据,传统的关系型数据库在扩展性方面有一定的局限性,对于企业海量数据的存储和在线分析的需求已经无法满足,这是各行各业急需解决的问题。
1 现状分析
随着数据库的广泛应用,企业的数据海量增长,用户的查询需求也越来越复杂且涉及跨库跨表的大数据量的综合分析查询。同时数据仓库和商业智能(DW/BI)行业[1]逐渐成熟,商业智能主要是数据仓库、多维分析技术[2]、可视化技术的综合应用。
联机分析处理(OLAP)是数据仓库[3]系统重中之重的应用技术,用于服务繁琐的分析操作,按照决策者的业务需求,从初始的数据转换到能够展现企业真实面貌的多维特性数据,使用户能准确、迅速、一致的从多角度对信息和数据进行分析处理,并且能够依据主题构建多维查询,灵活准确的进行大数据处理,直观清晰的展现给决策人员所需的查询处理结果,以便可以直观准确的把握企业各方面的现状。目前的离线数据的解决方案是在Hive数据仓库的基础上的多维分析系统,将多维分析操作利用HQL语句转化成Map/Reduce任务运行以后得到分析结果。
大数据技术不局限于结构化数据,它能处理各种非结构化和半结构化数据,并且整个过程都是基于分布式存储的数据进行分析,Hadoop以及全部hadoop生态系统也给商业智能供应了一套完备的、高效率的解决方案。虽然基于 hive 的数据仓库可用于离线数据的处理,但对于在线数据处理存在查询速度较慢的问题,以及如何解决查询分析结果的实时显示,使企业能快速的从海量数据中得到数据各个维度的分析结果,这是本文需要解决的问题。
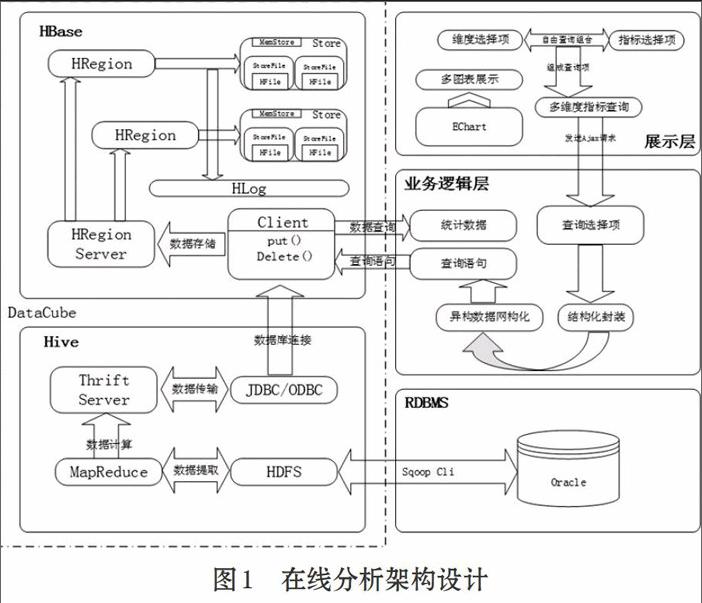
2 在线分析架构设计
基于对大批量数据统计和分析的考虑,选用建立在hadoop生态圈[4]上的Hive作为数据仓库,它提供了一些用于对hadoop文件中的数据集进行数据过滤、特殊查询和分析存储的工具。Hive提供的是一种结构化数据的机制[5-6],可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析,但Hive的执行速度慢,不能支持用户实时的查询,所以在Hive的基础上结合使用HBase。endprint
基于用户对统计分析结果[7]快速展示在页面上的考虑,选用了HBase数据库,它是一个分布式、面向列的开源数据库,能提供低延迟的数据库访问。它能提供实时计算服务主要原因是由其架构和底层的数据结构决定的,即由LSM-Tree(Log-Structured Merge-Tree)+HTable(region分区)+Cache决定的,客户端可以直接定位到要查数据所在的HRegion server服务器,然后直接在服务器的一个region上查找要匹配的数据,并且这些数据部分是经过cache缓存的。读取速度快是因为它使用LSM树型结构,而不是B或B+树。磁盘的顺序读取速度很快,但是相比而言,寻找磁道的速度就要慢很多。HBase的存储结构将磁盘寻道时间控制在可预测范围内,并且读取与所要查询的rowkey连续的任意数量的记录都不会引发额外的寻道开销。故选用HBase作为实时查询统计分析后的结果。
数据处理采用Ajax+Servlet进行前后端交互,Hive技术用于对海量的原始数据进行ETL处理,并将分析结果存入HBase数据库中,HBase数据库用于实时查询统计结果返回前台。具体架构设计如图1所示。
本文数据可视化采用EChart前端框架,能够生成包括曲线图、区域图、柱状图、饼状图、散状点图在内的多种动态图表[8],清晰鲜明地展现数据内容指标。数据处理采用Hive预处理+HBase实时查询的方式,首先利用后台离线操作将hive中的数据进行ETL处理,对原始数据进行主题的维度项与指标项的CUBE构建分析,并得出结果存入HBase数据库中,然后提供在线实时查询,即从HBase数据库中提取所需的统计信息返回前台展示,并且响应时间能够达到毫秒级,因此可以带来良好的用户体验。
3 ETL处理与DataCube构建
ETL是数据抽取(Extract)、清洗(Cleaning)、转换(Transform)、装载(Load)的过程。用户从数据源抽取出所需的数据,需要对导入的数据进行数据清洗工作,对数据进行去重,清除错误的、无关的数据,清除相关表中与主题无关的多余列,将多表连接成最大维度的事实表,最终按照预先定义好的数据仓库模型,将数据加载到hive数据仓库。Hive没有专门的数据存储格式,只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,Hive 就可以解析数据。Hive中所有的数据都存储在 HDFS 中,Hive中包含以下数据模型:表(Table),外部表(External Table),分区(Partition),桶(Bucket) [9]。
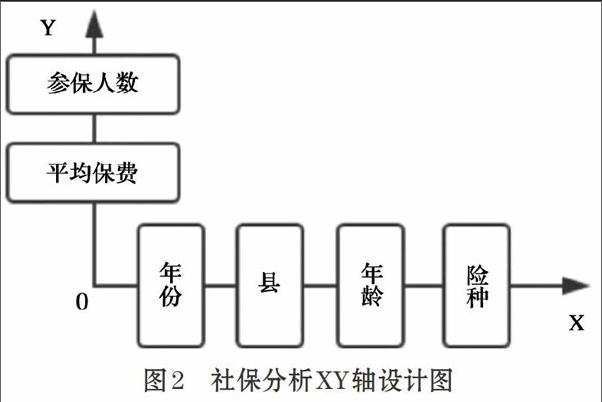
本文选定某省人力社保系统的数据集,异地系统中单表数据量级为百万级,需统计的表数为十多张,因此,异地系统总的数据量为千万级别[10]。通过业务问题分析得到多维分析的维度:年份、县、年龄、险种、参保人数、平均保费。XY轴设计,如图2所示,X轴:年份、县、年龄、险种,Y轴:参保人数、平均保费。
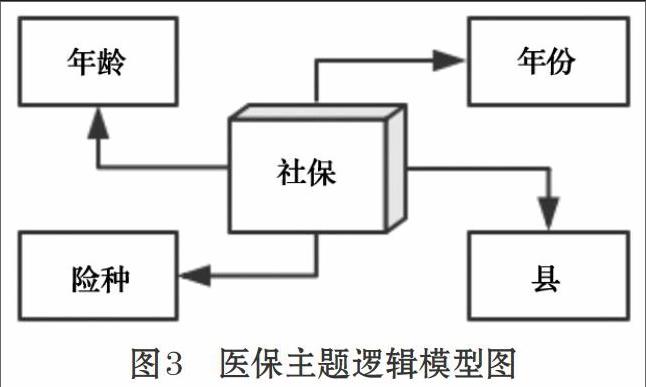
事实表与维度表以最典型的星型模型进行关联构建,是为事实表为中心,维度表向外扩散的几个角度,通过关键字来联系。如图3所示。
经过ETL数据处理和主题构建,实验采用四条SQL查询语句进行对比操作,具体语句如表1。
实验采用3台物理机测试,配置如下:Intel(R) Core (TM) i7-4500u 1.8GHz,内存4.0GB,操作系统是,Master和Slave节点均使用ubuntu12.04,hadoop2.2.0、HBase0.96.0、hive0.13.0,JDK1.7.0,2G数据量。进行Hive与oracle数据库查询测试对比,随着查询的字段及分组(Group)操作的字段增加,查询时间效率的差别显著。如表2及图4的对比结果。
因为通过DataCube的构建,查询分析结果保存在HBase中,经过测试,首次业务操作界面响应速度在6秒以内,之后业务普通查询、跨多表综合查询的业务操作界面响应速度均在 0.05秒以内。
4 结束语
本文基于Hive的技术特点,进行数据处理和构建多维数据的主题,采用HBase数据库存储分析结果,满足实时展现的需求。实验表明,在Hive上构建多维数据主题后的数据仓库对比Oracle数据库,查询效率得到显著提升,并且HBase的响应时间能够达到毫秒级,因此可以带来良好的用户体验。
參考文献(References):
[1] 范东来.Hadoop海量数据处理[M].人民邮电出版社,2015.
[2] 沙倩.基于云平台的多维数据分析的研究与应用[D].北京邮
电大学,2013.
[3] (美)金博尔(Kimball, R.),(美)罗斯(Ross).数据仓库工具箱[M].
清华大学出版社,2015.
[4] 陆嘉恒.Hadoop实战[M].机械工业出版社,2011.
[5] 唐榕蔚.基于HIVE电子商务多维分析技术应用研究[D].北方
工业大学硕士学位论文,2015.
[6] Hu P. The Cooperative Study Between the Hadoop Big
Data Platform and the Traditional Data Warehouse[J]. Open Automation & Control Systems Journal,2015.7(1):1144-1152
[7] 吴明礼,唐榕蔚,李也白.基于HIVE面向多企业的经营分析
技术应用研究[J].工业技术创新,2014.5:609-613
[8] 左谱军,朱晓民.基于Hive的数据管理图形化界面的设计与
实现[J].电信工程技术与标准化,2014.1:89-92
[9] Thusoo A, Sarma J S, Jain N, et al. Hive: a warehousing
solution over a map-reduce framework[J].Proceedings of the Vldb Endowment,2010.2:1626-1629
[10] 秦玉兰.基于HIVE的海量数据报表服务系统的设计与实现[D].北京邮电大学硕士学位论文,2014.endprint
猜你喜欢
电子乐园·下旬刊(2021年3期)2021-02-08
自然资源信息化(2019年4期)2019-03-29
录井工程(2017年3期)2018-01-22
电子制作(2016年15期)2017-01-15
山东工业技术(2016年15期)2016-12-01
中国教育信息化(2015年10期)2015-08-23
