
一卡通食堂消费数据的聚类及关联规则分析
2018-01-26 04:58:08南京市第九中学马乐之
电子世界 2018年1期
南京市第九中学 马乐之
0 引言
近年来,随着学校信息化建设的飞速发展,校园一卡通系统得到了广泛应用,也累积了海量的信息,通过对这些数据进行深入的用户行为分析,可以为教学、科研、后勤和管理等多个部门提供有价值的参考意见[1][2]。以某高中校园一卡通数据为例,由于卡中最为频繁、交易量最大的消费行为是在校高中生的食堂消费,其隐含的信息量也最为丰富,故本文针校园一卡通的食堂消费记录进行数据分析和挖掘。
1 数据来源与预处理
以2016年9月至2017年1月,某高中秋季学期的一卡通食堂消费记录作为数据来源,按期初考、第一次月考、期中考、第二次月考、期末考的顺序,将该学期划分为四个时间段,将每个时间段均至少有一次外卖记录的2015级70名学生作为研究对象。
为便于后续处理,根据不同编号窗口所售食品的种类将售卖窗口分为两大类:若某个编号的窗口专售各种中式套餐,由于所用餐具需回收,据此推测,购买者必须堂食,不会外带,故将该窗口称为堂食窗口;而另一编号的窗口专售汉堡、饮料等快餐食品,采用纸质或塑料包装,便于携带,据观察,凡只购买此类食品的学生,一般都是将食品直接带回教室,故将该窗口称为外卖窗口;如果在同一餐次中,堂食窗口和外卖窗口均产生消费记录,则划归为堂食。据此,可得到该用户每日三餐的就餐方式(堂食或外卖),并统计出日外卖次数。
2 基于时间序列聚类方法的就餐行为模式分析
2.1 时间序列构建
聚类的用途很广,典型作用是挖掘数据中的一些深层信息,并概括出每一类的特点,或者把注意力放在某一个特定的类上,以作进一步的分析。时间序列是一条由n个实数变量组成的有序序列,其中对象点以时间先后排列、并且时间间隔相等。基于时间序列的聚类挖掘是一种常用的基础性数据处理和分析方法[3][4]。
在本文研究中,考虑到不同用户选择堂食或外卖的原因各不相同:也许是随机的,例如下课时间延迟、身体不适等,也许是出于其他某种特定的需求,而后者可能与相应的上课日期即时间因素有关。因此,时间因素是就餐行为模式聚类分析的关键。在上述任意一个统计时间段内,可以通过任意两个用户日外卖次数逐日变化规律的相似度度量进行聚类分析。
基于以上设想,构建该时间段内每个用户的日外卖次数时间序列,即:

2.2 时间序列聚类实现
K-means聚类算法是典型的基于距离的非层次聚类算法,在最小化误差函数的基础上将数据划分为预定的类数K,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大[2]。这里以欧式距离作为聚类距离的度量,即:[3]

分别取聚类数K=2、3、4进行分析。经试验,当聚类数K=3时,聚类结果最佳,如表1所示。结合实际情况分析,认为本次聚类结果划分为三类相对合理。

表1 K=3时的聚类结果
以横坐标表示该月正常上课日期,以纵坐标表示人均日外卖次数,分别画出表1中三个簇的人均日外卖次数在某时间段内的变化情况,如图1所示。
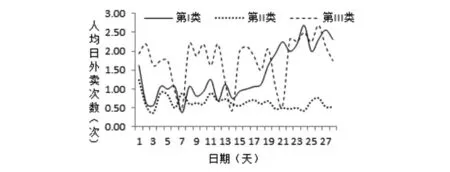
图1 三个簇的人均日外卖次数变化情况
由图1可知,第I类人群的人均日外卖次数在时间轴的分布上不均匀,后两周显著增加;第II类人群的人均日外卖次数较少,且比较随机;第III类人群的人均日外卖次数最多,在时间轴上的分布基本比较均匀,但最后1周有增加。
以上三个簇代表了三种不同特点的就餐行为模式。
3 就餐行为模式与学习成绩的关联规则分析
关联规则分析是数据挖掘中最活跃的研究方法之一,目的是在一个数据集里找出各项之间的关联关系。Apriori算法是经典的挖掘频繁项集的算法,其主要思想是找出存在于事物数据集里最大的频繁项集,利用得到的最大频繁项集与预先设定的最小置信度阈值生成强关联规则[3][4]。
为方便利用Apriori算法进行关联分析,结合上述三类学生的考试成绩(通过总分排名反映),对数据进行离散化处理。选择最小支持度阈值为5%,最小置信度阈值为20%,经计算得到关联规则,如表2所示。

表2 关联规则计算结果
由规则1可知,第I类与排名位于1~20名同时发生的概率为11.4%、第I类中排名位于1~20名的概率为50%,说明第I类学生中约半数成绩优秀;由规则2和规则3可知,第I类与排名位于21~50名或51~70名同时发生的概率均为5.7%、第I类中排名位于21~50名或51~70名的概率均为25%,说明第I类学生中的另一半成绩中等或较差。这可能是因为,第I类上游和中游的学生其学习自觉性和紧迫感随着考试的临近而加强,因此选择外卖的次数越来越频繁,意味着用餐时间的缩短、复习备考时间的延长。
由规则4可知,第III类与排名位于1~20名同时发生的概率为12.8%、第III类中排名位于1~20名的概率为56.3%;由规则5可知,第III类与排名位于51~70名同时发生的概率为8.6%、第III类中排名位于51~70名的概率为37.5%。以上数据说明,第III类学生的学习成绩具有两极分化倾向,一部分名列前茅,另一部分趋于下游。可能的原因在于,表面上两者均经常性地购买外卖,但前者的目的是以快餐的方式挤出完成作业的时间,从而提高学习效率;而后者的目的主要是为了能有更多的时间消遣在手机游戏等娱乐活动上。因此,看似相似的行为模式却导致了截然不同的结果。
4 结束语
本文利用基于时间序列的K-means聚类算法进行了就餐行为模式的聚类分析,并在此基础上运用Apriori算法研究不同模式与其学习成绩之间的关联规则,所做工作对于今后进一步深入挖掘校园一卡通消费数据具有实际意义和应用价值。教学管理部门可以以相关分析结论为参考,对重要的阶段性考试进行考前预测和考后综合评估,从而提高学习成效评价的准确性和时效性,并对部分有可能成绩下滑的学生发出预警。
[1]陈锋.基于校园一卡通系统的高校用户就餐消费行为分析与数据挖掘[J].中国教育信息化,2014(5).
[2]董新科,等.基于校园一卡通消费数据的几种聚类算法的分析比较[J].计算机系统应用,2014(1).
[3]张良均,杨坦,等.MATLAB数据分析与挖掘实战[M].北京:机械工业出版社,2015,6.
[4]周英,卓金武,等.大数据挖掘系统方法与实例分析[M].北京:机械工业出版社,2016,4.
猜你喜欢
现代苏州(2022年10期)2022-06-07 18:18:30
现代苏州(2022年10期)2022-06-01 06:19:48
绥化学院学报(2021年3期)2021-02-13 05:46:00
环球时报(2021-01-20)2021-01-20 05:17:59
当代陕西(2019年15期)2019-09-02 01:52:00
学苑创造·A版(2018年11期)2018-02-01 06:29:20
读者(2017年5期)2017-02-15 18:04:18
电子制作(2016年19期)2016-08-24 07:49:44
中学生数理化·高一版(2016年2期)2016-05-30 10:48:04
新高考·高一物理(2015年5期)2015-08-18 18:52:01
