
基于Scrapy的深层网络爬虫研究
2018-01-24 21:54刘宇郑成焕
软件 2017年7期
关键词:网络爬虫
刘宇 郑成焕


摘要:随着大数据时代的到来,网络爬虫已经成为很普遍的技术,无论是做项目、科研、创业或者写论文,获得大量数据并且对数据进行分析都是必不可少的。但是目前存在深层网(DeepWeb)的数据量是表层网(surface Web)数据量的数百倍,乃至上千倍。传统的爬虫对表层网数据进行获取已经无法满足我们的需求,同时因为深层网数据通常没有各种复杂的标签结构等,使得其本身更加清晰,干净,故而我们深入研究深层网络爬虫是非常有必要的。本文将会通过Python的Scrapy爬虫框架,对深层网络爬虫进行研究,通过分析深层网络特点制定合适的Scrapy爬虫策略,最后通过实际操作,对指定的爬虫策略进行验证。
关键词:深层网;网络爬虫;Scrapy;Python
0前言
近些年,随着人们对信息重要性认识的加深,对数据量的需求增大,网络又作为各种信息的载体,蕴含大量的资源,网络爬虫技术显得越发的重要。无论是对数据进行简单分析还是对数据进行深入研究,抑或对数据进行预测或者可视化,这一切的基礎都是需要先获得数据,然而互联网上表层网(Surface Web)数据资源量有限,并且数据质量不高,但是深层网(Deep Web)数据量却是表层网的数百倍乃至上千倍,而且数据质量相对来说更好。所以对深层网数据获取技术逐渐走人人们的视野。
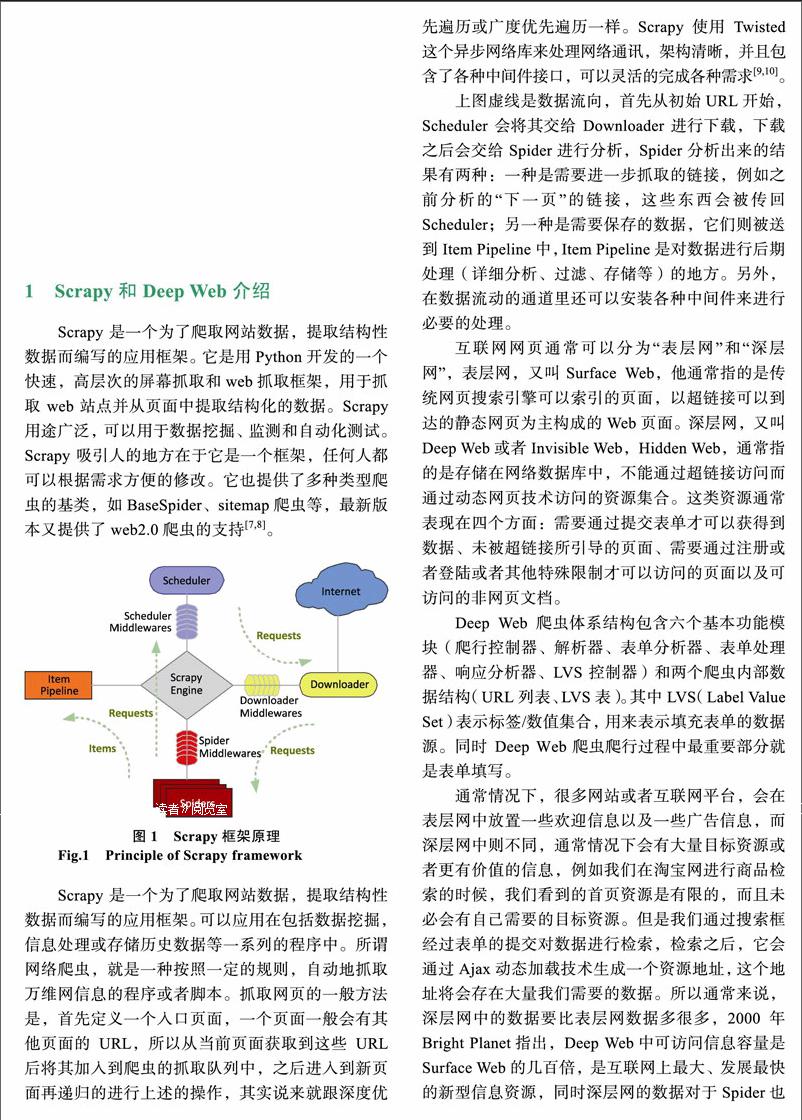
网络爬虫,又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。传统的网络爬虫,更多的是获得表层数据,通过对表层网资源发起请求,并对response进行目标数据提取和整理,但是表层网资源通常存在大量问题,例如页面上有很多的广告代码或者是样式代码等,数据量不全面,有的网页甚至直接表明需要登陆等才可以获得更多资料信息等,所以表层数据已经远远不能满足我们学习,写论文,做研究等需求,我们需要更加简单便捷框架,需要更加简洁的代码结构,更加快速高效的获得深层网资源就变得越来越重要。本文将会以Python语言的经典爬虫框架——Scrapy框架为例,通过对深层网的特点进行详细的分析,进而对深层网数据的数据的特点进行分析,同时对深层网数据价值进行描述,最后根据深层网和深层网数据的特点进行爬虫策略的制定。endprint
