
数据挖掘技术在医疗大数据中的应用研究
2018-01-22 01:48:34陈闽韬匡芳君
电脑与电信 2017年11期
陈闽韬 匡芳君*
(温州商学院信息工程学院,浙江 温州 325035)
1 引言
信息技术的发展与进步,为医疗服务提供了便利,对转变传统医疗服务具有积极的作用与意义。医院通过构建监管系统,完成对医院异常的数据信息进行采集。但是,由于医疗行业本身特性和复杂性,造成医疗大数据所包含的数据信息驳杂,数据信息利用率相对较低,亟需改进与完善。本文研究基于遗传算法的K-means改进聚类方法,再结合实例对数据挖掘技术在医疗大数据中的应用进行分析。
2 相关关键技术
2.1 数据挖掘技术
实际医疗大数据涵盖患者、费用、药物以及相关管理信息等数据。但是这些信息中包括作用显著的信息和作用不够明显的信息。为了从这些冗杂的数据信息中获取作用显著的数据信息,如患者的病例信息、费用信息等,则需选择适宜的技术类型,完成对这些信息的获取。数据挖掘技术能够将作用显著的数据信息提取出来,从而满足医疗服务的需求[1,2]。数据挖掘技术可以从存在噪声、模糊的数据中,将目标信息进行提取。医疗大数据结合数据挖掘技术,能够实现医疗成本的预测和控制,明确医用药物的各项信息,统计分析药物不良反应、为医疗服务提供基础帮助,对推动医院的综合服务水平具有明显的正向作用。
2.2 遗传算法
遗传算法是一类借鉴生物界的进化规律演化而来的随机化搜索方法。遗传算法模拟一个人工种群的进化过程,通过选择、交叉和变异等机制,在每次迭代中都保留一组候选个体,重复此过程,种群经过若干代进化后,理想情况下其适应度达到近似最优状态。自从遗传算法被提出以来,其得到了广泛的应用[3],特别是在函数优化、模式识别、神经网络、自适应控制等领域,遗传算法发挥了很大作用,提高了问题求解的效率。本文选择基于遗传算法的数据挖掘技术,并运用到医疗大数据中,实现有效的医疗大数据挖掘。
2.3 K-means算法研究
K-means算法是一种聚类算法,其具有较高的应用价值。其主要原理是抽取k个数据实例,并将其作为聚类中心。聚类中心的选择,可以选择随机的方式,或选择人为指定或是计算得到。完成后,在聚类中心,遍历剩余数据实例,并取距离聚类中心最近的实例加入到簇中,完成一次迭代。第一次迭代后,可以保证每个簇中,均有≥1个数据实例,然后生成新的中心点,将其作为新的聚类中心,重复第一步。之后不断对第二步进行重复,展开迭代,最终输出结果。
但考虑到数据挖掘应用到医疗大数据中,存在应用效果不够理想、数据挖掘效率低下等问题,本文将遗传算法和K-means算法相结合,达到提升数据挖掘效率的目的。
3 数据挖掘技术在医疗大数据中的应用分析
将数据挖掘技术应用到医疗大数据中,对推动医疗行业的服务水平与质量具有积极的作用,在实际的应用中,需要对具体数据挖掘对象进行研究,将应用的算法进行改进,以保障数据挖掘的整体效果,满足医疗服务的基本需求。
3.1 数据挖掘对象研究
医疗大数据中数据挖掘技术的应用,需明确具体数据挖掘对象。结合当前医疗行业的实际情况,可以得到数据挖掘的主要对象为互联网的相关医疗数据信息、患者病例、药物信息和相关的费用等信息。在明确具体的数据挖掘对象的基础上,再展开对数据挖掘技术的运用。另外,数据挖掘技术应用之前,需对数据挖掘的基本流程进行研究。展开数据挖掘的第一步为问题定义与数据选择,这一步是关系数据挖掘的关键。第二步是对数据进行预处理,并将一致、完整和正确的数据存入到数据库中。第三步为数据集成,主要是用于完成对数据共享问题的处理。第四步展开数据的清理,将错误数据删除。第五步是数据交换,促使数据可以转变为适宜挖掘的形式,确保挖掘的效果。第六步为数据规约,借助删除行、列等方式,保障挖掘算法的运行量。第七步则是对数据挖掘,完成对目标信息的采集。最后为结果评价与展示。具体的数据挖掘流程如图1所示。

图1 数据挖掘基本流程
3.2 基于遗传算法的K-means改进聚类方法
K-means算法属于距离聚类迭代的算法,其是将相似性大的数据点聚集在一个簇中,将差异较大的数据放到其他簇中,借助相关约束条件,完成具体迭代。为进一步发挥数据挖掘在医疗大数据中的应用,需对K-means算法进行改进,本文提出基于遗传算法的K-means改进聚类方法。
(1)编码方案与种群初始化。在具体的改进算法中,将遗传算法与K-means算法相结合,首先对具体中心坐标进行定义,设为d维。再假设具体簇的染色体长度为k×d。具体的染色体设置为{P1,P2……Pk},其中 Pi={Pj1,Pj2……Pjd}。编码方案和种群初始化后,随机从n个对象中确定k个初始聚类中心坐标。
(2)适应函数选择。适应函数主要是对适应度值计算的基础,对迭代和最优解获取具有积极的作用。适应函数如公式(2)所示:

(3)操作选择。为保障具体算法操作性能,在具体的迭代过程中,将免疫机制引入其中,从而完成操作。改进算法的具体流程图如图2所示。

图2 基于遗传的K-means算法流程图
结合上述方法完成对K-means算法的改进,从而满足医疗大数据中数据挖掘的应用需求,并可以减少算法的运算时间,在理想的时间内,完成对最优解的获取,从而提升数据挖掘的效率。
4 应用实例分析
本文结合实际情况,研究分析数据挖掘在医疗费用数据中的应用。医疗费用信息具有真实性、隐私性、多样性、不完整性和冗杂性等特点。鉴于医疗费用数据的特点,其符合医疗大数据的基本特性。为实现有效的费用结算和费用查询,则需借助数据挖掘实现,从而提升医疗服务水平的效果。
4.1 分类算法
具体数据挖掘过程中,由信息采集系统对患者的基本信息进行采集,需对分类算法进行选择。通常选择易于理解的四分位数法[4],再由四分位数法对患者展开分组,具体信息包括年龄、费用、疾病和药物等。本文主要选择费用的25%、50%和75%作为分割点,按照这3个分割点,将数据展开区间化,使用传统四分位分类方法的分类结果如表1所示。

表1 传统四分位分类方法分类结果
4.2 聚类算法
采用上文所述的基于遗传算法K-means方法进行数据挖掘,分类结果如表2所示。该算法对数据分类的效果显著,能够将不同聚类中心进行表述,并得到详细费用情况及例数。

表2 基于遗传算法的K-means改进后的聚类方法分类结果
4.3 结果评价
对上述的两种算法运用C4.5决策树[5]模型对影响因素进行分析,基于传统四分位分类方法和基于遗传算法的K-means改进聚类方法生成的决策树分布分别如图3和图4所示,从图3、图4可知,采用传统四分位分类方法分类过程中,分类项目相对较多,且涉及内容较为广泛,在具体的分类过程中,过程较为繁琐,且易造成数据误差的情况,影响效果,且其预测的精度约为80.26%;采用基于遗传算法的K-means改进后的聚类方法的分类方法,在提升效率的同时,且能够综合提升预测精度,其具体预测精度约为93.08%,比较上一分类方法,差异明显。
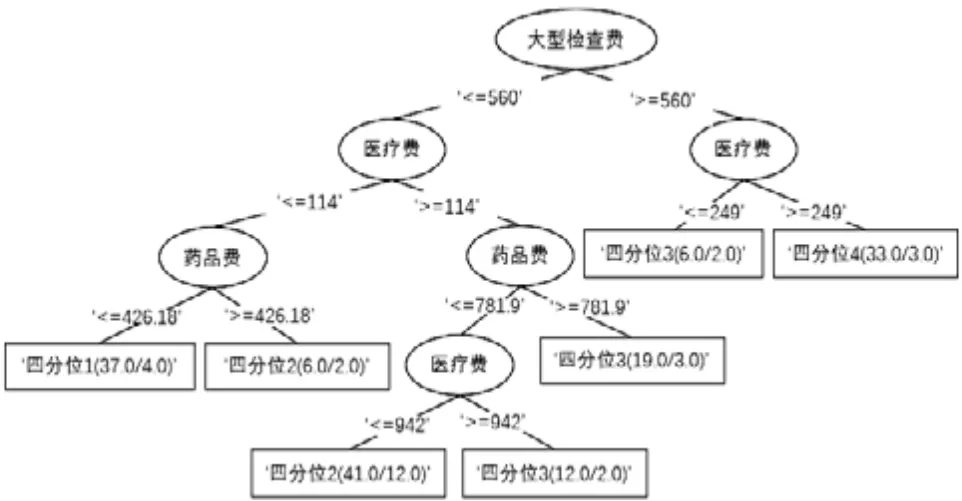
图3 传统四分位分类方法生成的决策树

图4 采用基于遗传算法的K-means改进后的聚类方法生成的决策树
5 结束语
随着医疗行业的不断发展,大数据技术在医疗行业中的运用更为普遍,借助有效的信息采集技术,对医疗服务及相关内容的数据信息进行采集,并展开管理与服务等内容,是影响信息利用效率和服务质量的关键。但受海量数据特性影响,造成数据信息冗杂和相关重点信息不能获取与运用。因此,本文研究数据挖掘在医疗大数据中的应用分析,包括具体流程、数据挖掘算法等,最后以医疗费用数据为例,利用基于遗传算法的K-means聚类方法进行分析,为提高医疗服务质量提供有效数据信息。
[1]朱欣欣.数据挖掘技术在医疗大数据中的应用研究[J].医药卫生:文摘版,2016(10):00102-00102.
[2]罗堃,代冕.数据挖掘技术在医疗大数据中的应用研究[J].信息与电脑:理论版,2016(6):45-47.
[3]吕峰,杨宏,普奕,等.遗传算法的数据挖掘技术在医疗大数据中的应用[J].电子技术与软件工程,2017(5):203-203.
[4]李梅.大数据时代中如何进行医疗数据挖掘与利用[J].数字通信世界,2016(1):23-24.
[5]李楠,段隆振,陈萌.决策树C 4.5算法在数据挖掘中的分析及其应用[J].计算机与现代化,2009(12):160-163.
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
电子测试(2017年15期)2017-12-18 07:19:27
石油地球物理勘探(2017年2期)2017-11-23 06:02:04
中央民族大学学报(自然科学版)(2017年1期)2017-06-11 07:13:32
电力与能源(2017年6期)2017-05-14 06:19:37
统计与决策(2017年2期)2017-03-20 15:25:24
智能系统学报(2015年4期)2015-12-27 09:38:39
信息通信技术(2015年6期)2015-12-26 01:16:46
电子设计工程(2015年6期)2015-02-27 12:04:53
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
