
面向暴恐音视频的内容检测系统研究与实现*
2018-01-19 05:30黄超,易平,2
通信技术 2018年1期
黄 超,易 平,2
(1.上海交通大学 网络空间安全学院,上海 200240;2.上海市信息安全综合管理技术研究重点实验室,上海 200240)
0 引 言
随着网络的普及和音视频技术的高速发展,网络上的音视频数量呈现爆炸性增长。在海量的音视频中,混杂着一定数量的不健康音视频,如含暴力﹑恐怖内容的音视频,对社会和谐﹑网络环境的健康有着不容忽视的损害。
由于网络音视频的数目极为庞大且每天都会产生大量新数据,若仅依靠人工审核的方式进行检测,效率和时效上是无法应对的。因此,需要建立面向暴恐音视频的内容检测系统,不仅能对待检测音视频给出暴恐/非暴恐的分类标签,还能给出暴恐程度的评估;既要保持高准确率,也要
具有高时效性[1]。
当前,对于暴恐音视频的检测方法,主要可以分为声音﹑图像和时空三方面特征的方法。
声音特征。对于一段音视频来说,其音频处理所花的时间通常要比其视频处理所花时间的1/10还要少。因此,声音特征是音视频检测中时效性最高也最广泛应用的。Cheng[2]等人提出了一种基于分层模型的音频片段检测方法,最典型的是枪声和飙车声,以判定相应的场景。Smeaton[3]等人也通过选择音频特征来分类动作电影中的暴力镜头。典型的声音特征包括爆炸声﹑枪击声﹑尖叫声等。
图像特征对于暴恐音视频来说,有典型的火焰﹑血液﹑爆炸等,这些图像特征取自每一个帧。Lam[4]采用以拍摄为基础的方法,同时考虑一些全局特征(如颜色矩﹑边缘方向直方图和局部二进制模式等)。Nam等人[5]则提出了利用火焰﹑血液等图像特征来识别暴恐视频。然而,研究如何降低误检的概率,不能仅仅因为含有火焰的镜头多就认为是暴恐视频。
时空特征对于暴恐音视频来说,往往有人的动作。通过动作识别典型的暴力动作如挥拳﹑踢腿等,可以作为检测的依据。Datta等人[6]提出了一种基于加速运动矢量的暴力视频检测,主要用于检测打斗﹑拳击等场景。Ali等人[7]利用光流法提取人的运动信息,但计算量大,鲁棒性不足。Nievas等人[8]评价了利用现有的动作识别的办法去检测视频中的打斗画面的效率和性能,其中应用了STIP和Motion SIFT去检测。
本文的面向暴恐音视频的内容检测系统,选择音频特征MFCC,采用词袋模型建模,利用支持向量机分类。虽然只采用了听觉的MFCC特征做检测,但本文致力于在单个特征的利用上得到最佳的检测效果,以供后续研究中融合其他的听觉或视觉特征进行多模态检测。
1 理论基础
1.1 MFCC特征
MFCC(全称“Mel Frequency Cepstrum Coefficient”)即为Mel频率倒谱系数(梅尔频率倒谱系数)。Mel标度是一种非线性的频率单位,表征了人体耳朵对频率的感知。因为人耳就像滤波器,只对某些特定的频率分量进行感知。人的耳朵对于真实频率的感知是非线性的,在低频率段可以近似为线性,而在高频率的1000 Hz以上时则近似为对数增长关系。因此,Mel频域的滤波器可以用来模拟人体耳朵的临界频率和非线性特征。MFCC现在已经成为语音识别领域效果应用最好的特征[9],主要应用于语音识别和对说话者的识别上。
1.2 词袋模型
词袋模型,“Bag of Words”[10],即用词汇(可以类比于“基底”的概念)来表征不同词汇的集合模型。这里的词汇可以是文字﹑图像或者音频等。在分析文字时,仅仅考虑每个单词词汇出现的频次,而不考虑他们的出现顺序和相互之间的联系(即组合方式),这样虽然带来一定程度上的信息损失,但提高了分析文字的效率,可以高效地构建模型并进行模型应用,且关键词出现的频次在某些应用场景下更具实用性。词袋模型在文字建模和分析上取得成功后,继而被用于图像识别领域。文字中有一个个单词可以作为词汇,图像中也有类似的“基底”,但图像的“基底”不是小区域的图像特征,而是局部区域匹配特征,如SIFT(Scale-invariant Feature Transform,尺度不变特征转换)[11]在图像识别领域的应用愈加广泛。
音频词袋模型和图像词袋模型类似,它们的词汇不像文字词汇可以很容易地完全匹配,而是采用局部特征,需要应用聚类算法对特征相似距离进行计算和分类。音频中常用的有MPEG-7(多媒体内容描述接口)中的一些特征如音频签名﹑MFCC特征等。
1.3 支持向量机
支持向量机(Support Vector Machine)是Vapnik等人[12]于1995年首次提出的基于统计学理论的新型机器学习算法,是一种有监督学习模型。它的学习机制是全新的,有着坚实的理论基础和统计学算法,能够从训练数据中寻找并发现内在的规律,通过“学习”后能够对待检测样本进行预测。支持向量机致力于得到的最优分离超平面,不仅要能够将待检测样本无差错地分为两类,还要使得这两类样本之间的距离最大化。
2 算法研究
2.1 算法整体框架
本文设计的面向暴恐音视频检测的内容过滤系统,整体框架如图1所示。
检测模型基于音频词袋模型,采用语音识别中最常用到的MFCC特征。对MFCC特征聚类可以得到词袋模型的词汇,再通过对词频的计算分别表征训练集和测试集的词袋模型表示。对于训练集的词袋模型表示,用支持向量机SVM去训练。得到训练模型后,用此训练模型对测试集进行分类测试。
2.2 MFCC特征维数选取
MFCC是当前语音识别领域最常用的检测特征。在本文实验数据集中,由于电影镜头中暴恐和非暴恐镜头的音频能量特征差异较大,因此本文考虑MFCC中能量很大的C0,即取13维的MFCC作为识别特征。考虑到暴恐镜头的音频识别检测效率,提取的MFCC特征为较低维数,舍弃了其一阶导数(总共26维)和二阶导数(总共39维)。因此,对每一帧的MFCC向量聚类得到的音频词袋的词汇也是13维,聚类﹑匹配效率高。
2.3 词袋模型的词汇生成
采用k-means算法对数据集的全部帧的MFCC特征进行聚类,聚类得到的k个聚类的中心——聚类质心作为词袋模型的“词汇”。
在聚类过程中,相似度高的向量容易被聚类到一个聚类中。聚类完成后,同一个聚类中的各帧的MFCC特征是相对接近的,很可能同属于一类声音。将聚类的质心作为词汇,通过计算词频去表征不同的镜头特征,即为词袋模型的核心。
对于每一帧的MFCC向量来说,它们之间的相似程度用欧几里德距离来衡量最合适。欧几里德距离越小,代表相似程度越大。例如,对于13维的
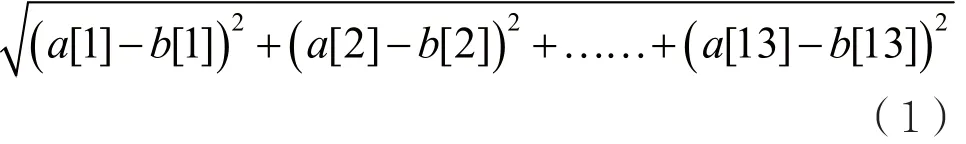
待检测短镜头的帧数长度变化很大,从最短的3帧到最多的4 846帧。因此,本文实验中聚类了不同个数(参数设为k)的质心,分别为8个﹑16个﹑32个﹑64个﹑128个﹑256个﹑512个﹑1 024个,然后再通过实验来选取最佳的聚类个数。聚类得到k个13维的MFCC向量,则为音频词袋的k个词汇。
2.4 特征的词袋模型表征
训练时,要用音频词袋模型的词汇去表征一段单位镜头的音频特征,这里的特征定义为每个音频词汇出现的词频。这里定义的单位镜头不是数据集定义的短镜头或长镜头,而是拟定的100帧长度(时间长度4 s)的单位镜头。三部用于分类测试的电影的短镜头共有6 564个,总的帧数为606 302帧,平均每一个短镜头有92帧,因此取100帧作为一个单位镜头是合理的。
每一个单位镜头中,每一帧的MFCC向量去和聚类得到的k个音频词汇的MFCC向量求欧几里德距离,认为每一帧的MFCC向量可以用离它最近(欧几里德距离)的那个MFCC词汇去表征,即该词汇的出现频次加1。这样每100帧的单位镜头都能表示为一个k维的词汇频次向量,其k维的频次总和为100。
同理,需要先对分类测试集做同样的词袋模型词汇表示后,才能对其进行支持向量机的分类。不过,分类测试的对象不是100帧的单位镜头,而是给定好的帧数长短不一的短镜头。这里需要用到“归一化”的方法。假设一个待检测短镜头的帧数为x帧,对每一帧的MFCC特征求得最近的音频词汇后,得到k维词汇频次向量,其k维的频次总和为x,归一化将k维向量每一维的元素值除以x再乘以100,则归一化后k维的频次总和为100,才可以使用先前通过支持向量机训练得到的模型进行分类。
2.5 支持向量机参数选取
本文实验采用的是台湾大学林智仁等人开发的LIBSVM系统的MATLAB版本[13]。支持向量机有2个重要参数——损失函数和gamma参数,对分类结果影响较大。为了便于求出最佳的损失函数和gamma参数,这里使用一种网格搜索(grid search)方法。与LIBSVM自带的grid.py思想相同,即遍历每一组损失函数和gamma参数,用交叉验证的办法求出交叉验证准确度最高的组合。由于过高的损失函数有可能造成过拟合而影响分类的准确性,所以相同准确度下将损失函数最小的那一组认为是最佳的参数设定。
本文实验中,将支持向量机svmtrain中参数b设置为1,这样能够输出支持向量机分类的概率值结果,是一个二元值。显然,属于暴恐的概率加上属于非暴恐的概率相加为1;且哪一个概率值越大,则该条向量便归属为哪一类。
3 实验分析
3.1 数据集介绍和优化处理
本文实验基于多媒体benchmark评估组织MediaEval中的一个竞赛项目——“暴力场景检测任务VSD(Violent Scenes Detection)”[14],致力于研究对暴力音视频片段的自动检测。它的官方数据集由Technicolor提供,有14部电影作为训练集,3部作为测试集。每一部电影的时长都在2 h左右。数据集提供了40 ms/帧(即25帧/s)的音视频特征,则14部电影共有2 411 714帧。
数据集的每部电影都提供了官方的短镜头分割结果,由Technicolor的镜头分割软件产生,下文中的“短镜头”都指这个定义。
数据集由官方划分为诸多长镜头,有着唯一的暴恐或非暴恐标注;下文中的“长镜头”都指这个定义。每一个暴恐/非暴恐的长镜头中都包含了若干个短镜头。
当短镜头落在带有暴恐标注的长镜头中时,则认为该短镜头为暴恐短镜头;反之,亦然。3部测试集的暴恐短镜头比例分别为1.771%﹑12.773%和10.481%。
3.1.1 无用镜头的过滤
对于电影来说,需要过滤掉一些非常规的镜头,以提升后续词袋模型构建的准确度。因为电影的片头和片尾有一些非常规镜头(非自然生活)如片头的厂家logo和片尾的字幕。考虑到非常规镜头不可能为暴恐镜头,因此每部电影从第一段暴恐长镜头起始帧开始到最后一段暴恐长镜头结尾帧结束。过滤之前14部电影总帧数2 411 714帧,过滤后为2 029 984帧。待聚类的样本无用干扰项被清除,降低训练复杂度,且暴恐镜头没有被过滤,最终的1 920 507帧的非暴恐镜头仍然大于109 477帧的暴恐镜头。可见,这样的过滤对最后分类精确度提升很有意义。
3.1.2 欠采样的样本平衡
14部训练集电影中的暴恐长镜头数目为962个,共109 477帧。在分类测试集中的短镜头共有6 564个,总帧数为606 302帧,每一个短镜头平均帧数为92帧。因此,在训练集中取100帧为单位长度镜头最合适。下文实验也验证了50帧和150帧的结果明显不如100帧好。
从每个暴恐长镜头中取100帧为单位长度的镜头,共取出662个单位长度镜头(部分长镜头的尾部不满100帧的被舍弃)。训练电影中的非暴恐镜头总帧数约为暴恐镜头总帧数的17倍,因此提取的100帧的单位镜头的数目也相差了17倍左右。正负样本的不平衡问题,导致支持向量机分类得到的超平面靠近数量多的负样本。由这样的模型进行分类,结果是倾向于把全部结果都分类到负样本。
为了解决正负样本不平衡问题,本文实验采用文献[15]提出的欠采样(Undersampling)方法。欠采样和增采样可以用来解决正负样本不平衡的问题,相比之下欠采样在训练过程中的复杂度更低,训练效率也更高,更适用于样本数目较多的情况。本文采用的欠采样方法是均匀间隔取样的方式,使得取得的负样本(非暴恐)数目和正样本(暴恐)数目一样。这是考虑到电影剧情较为连贯,相同镜头里相邻的几个100帧之间的MFCC特征差距较小。因此,均匀间隔取样方法不仅可以平衡正负样本数目,而且减少了相似累赘的训练样本,缩小了训练复杂度。
3.2 算法验证实验
3.2.1 客观评估方法
VSD规定要使用同一训练集,以提取任意多个模态特征,经过算法模型给出待检测样本的暴恐/非暴恐标签,并给出相应的概率,然后使用VSD官方认定的平均准确率Average Precision@100评估分类测试的结果。Average Precision@n是按检测概率从大到小,统计前n个被检测到的样本,计算其统计准确率,计算公式如下:
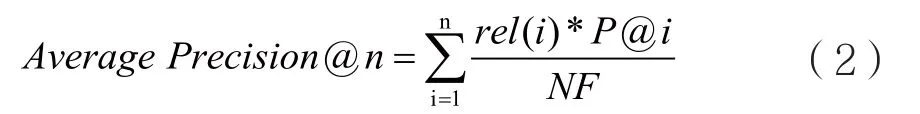
当@n不指定时,则默认为对全部被检测到的样本进行统计,计算统计准确率。
在本文实验得到的支持向量机分类结果中,首先对每一个结果属于暴恐类别的概率做排序,再取排序前n=100个结果做统计。
3.2.2 初步验证实验结果
本文构建的词袋模型维数为8维﹑16维﹑32维﹑64维﹑128维﹑256维﹑512维﹑1 024维共8种维数。本文选定的单位长度镜头为100帧。为了对比,同时选取50帧和150帧做实验。图2是分别取3种单位长度镜头下的检查结果。
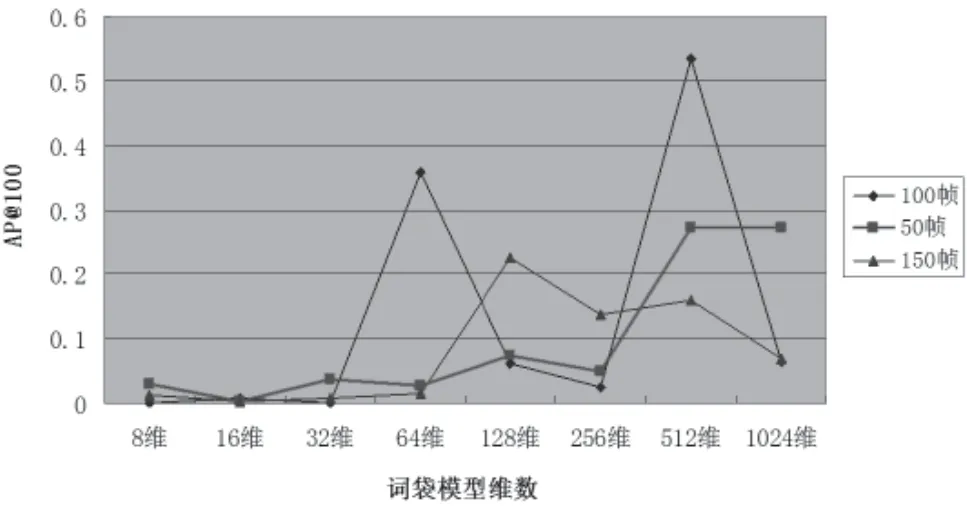
图2 初步实验结果AP@100
由图2的折线图可以看到如下规律:
(1)在8维﹑16维﹑32维时,因为维数还过小,AP@100都很低;
(2)100帧和50帧的单位长度镜头下,在512维时的AP@100最高,150帧的512维结果也不错,在后续改进实验中也是512维的结果最好;
(3)3种词袋模型最高的AP@100都有超过0.2;(4)100帧的结果明显优于50帧和150帧。当前,最佳的结果在维数为100帧单位长度镜头﹑512维词袋模型的参数情况下,为AP@100=0.532 792。
3.2.3 实验结果对比
本文应用的数据集和采用的运行水平﹑评估指标等都按照VSD官方指定。将初步实验的结果按官方评估指标即最佳AP@100放入其他队伍中进行对比[16],画出柱状图将更为直观,如图3所示。
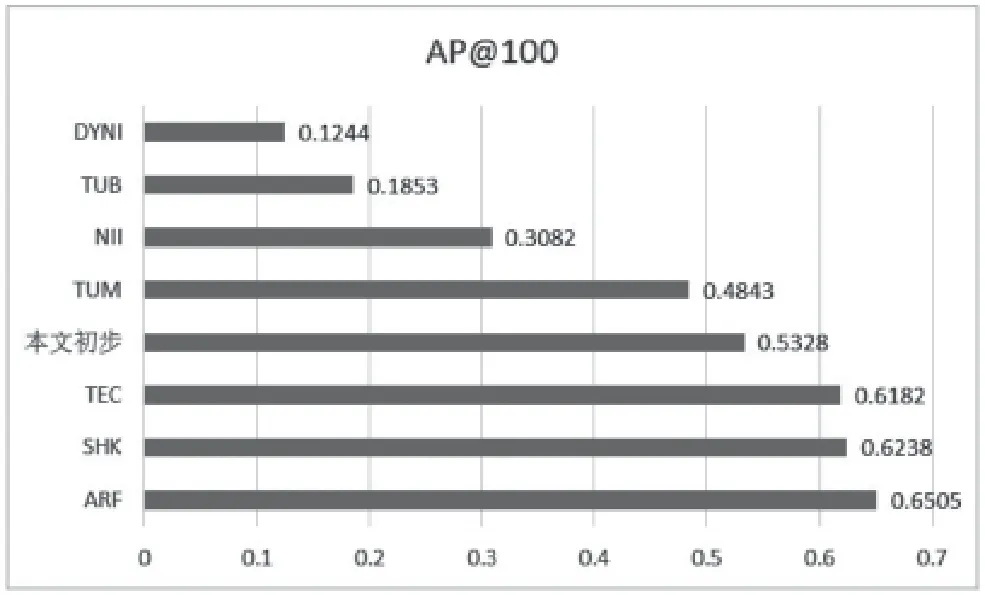
图3 AP@100结果对比
由对比实验结果可以看到,本文实验中最佳参数下的AP@100属于较高水平,排名第四。AP@100的和通常意义的准确率不同,是统计意义上的准确率,很难达到80%的水平,另一个原因是测试电影中的暴恐镜头比例很低,在1.7%~12.7%。
其他队伍都选取了多模态或者视频特征,训练复杂度高,而本实验仅仅选取了音频的一种特征就达到了理想结果,因此本方法具有较好的应用前景和可拓展性。
3.3 算法改进实验
3.3.1 词频加权参数的改进算法
通常情况下,对于词袋模型的表示方法,是对每一帧的MFCC向量计算和它距离最近的词汇向量,将这个词汇的词频加1。当词袋模型的维数即词汇个数较多时,如k维有512个词汇,每一个MFCC向量可能和周围的几个词汇向量距离都相近,如果仅仅将距离最近的词汇词频加1,那么对于仅比其最短距离多了微小距离的词汇来说是“不公平”的,也会损失部分有效信息。因此,在改进的词频加权中,对于距离最近的词汇的词频加1,对于距离第二近的词汇的词频加1/2,对于距离第三近的词汇的词频加1/4。以此类推,直到距离第c近的词汇的词频加上1/2c-1。
对于词袋模型维数k分别为8维﹑16维﹑32维﹑64维﹑128维﹑256维﹑512维﹑1 024维共8种维数,每一种模型的实验中都设置了6种词频加权方式进行检测,都是为距离最近的c个词汇进行词频加权。下文中的“词频加权参数c”都指的是这个定义。6种方式的区别在于c的取值,分别为1﹑2﹑3﹑5﹑k/2﹑k/4。在取k/2和k/4时,由于过大的c对应的加权数值1/2c-1过于小,为减少没有意义的计算加权带来的系统检测复杂度的大幅提升,本文规定当k/2和k/4的数值超过8时,也将该值取为8。
本文实验选取8种词袋模型的维数,每种维数有6种词频加权方式。进行组合实验,对最高结果中对应的词频加权参数c的出现比例总计做出饼状图,如图4所示。
从统计结果来看,最高结果对应的词频加权参数c中,c=1只占据了13.33%,c>1的情况占据了86.67%。因此,可以证明词频加权考虑最近的几个词汇的加权方法在普遍情况下是可以使词袋模型的表示更为准确,从而使得后续的支持向量机的训练和分类更加准确。
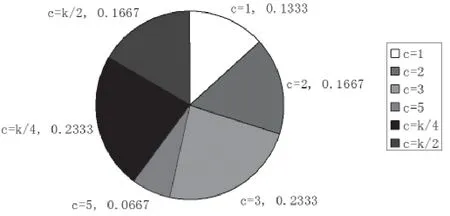
图4 最高结果中对应的词频加权参数c比例
3.3.2 基于距离倍数的词频加权改进算法
在上文的词频加权中,统计了最近c个词汇进行加权,是考虑到可能有几个词汇都和某MFCC向量的距离接近。进一步来看,在计算复杂度允许的情况下,距离也可以直接作为标尺。因此,在改进的词频加权方式中,考虑了距离的数值。首先选取最近的距离对该词汇的词频加1,然后对后续的距离进行区间分段。对于落于最近距离的1~2倍中的词汇,词汇词频加1/2;落于2~3倍中的词汇,词汇词频加1/4;以此类推,直到9~10倍距离中的词汇,词汇词频加1/29。这里需要进行归一化,使得词汇频次总和仍为之前设定的100。
改进后的词频加权方式为对最短距离的1~10倍的词汇进行词频加权,与词频加权最近c个词汇中的c=1﹑c=2﹑c=3﹑c=5做实验对比,结果如图5所示。
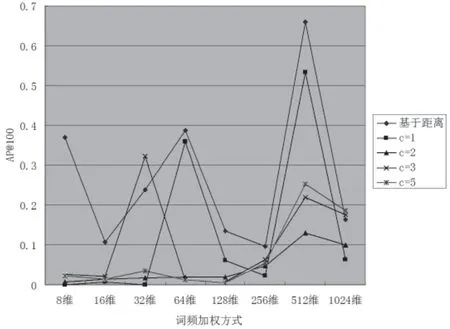
图5 优化算法AP@100对比
从图5的折线图可以看出,优化后算法的AP@100基本上包络着原有不同参数c的AP@100结果(即在它们的上面),即结果更优,具有普遍适用性。最重要的是,改进算法使得最优结果AP@100从原先的0.532 792提升到了0.658 726,略高于VSD中最高的0.650 5。
4 结 语
网络上海量的音视频中存在着数量不容忽视的暴恐音视频,在人工检测无法满足现实要求的情况下,本文研究了面向暴恐音视频的内容检测系统,既保持高准确率,也致力于提升检测的时效性。本文选择的检测特征是音频特征MFCC,采用词袋模型建模,利用支持向量机分类。虽然只采用了音频的MFCC特征做检测,但本文致力于在MFCC单个特征的利用上做到精益求精,得到最佳的检测效果,以供后续研究融合其他听觉或视觉特征进行多模态检测。因此,本文优化了多个全局参数,选取了13维作为MFCC特征的维数,过滤了无用镜头,选取100帧长度作为单位镜头并验证了合理性。此外,采用欠采样的方法来平衡正负样本的数目差距,减少了样本冗余和训练复杂度。最后,实现的检测系统取得了理想结果,不仅能给出镜头为暴恐/非暴恐的检测结果,还能给出暴恐的程度评估,具有高实用性。
本文的创新之处在于提出了词频加权参数c的改进算法,又提出了基于距离倍数的词频加权改进算法,改进的词频加权能使词袋模型的表示更精确,提高了检测准确率。
[1] 吴震.联网报警与视频监控系统平台实现技术[J].通信技术,2010,43(05):195-197.
WU Zhen.Implementation of Social Networking Alarm and Video Surveillance Platform[J].Communication Technology,2010,43(05):195-197.
[2] Cheng W H,Chu W T,Wu J L.Semantic Context Detection based on Hierarchical Audio Models[C].ACM Sigmm International Workshop on Multimedia Information Retrieval ACM,2003:109-115.
[3] Smeaton A F,Lehane B,O'Connor N E,et al.Automatically Selecting Shots for Action Movie Trailers[C].ACM Sigmm International Workshop on Multimedia Information Retrieval,2006:231-238.
[4] Lam V,Le D D,Phan S,et al.NII-UIT at MediaEval 2014 Violent Scenes Detection Affect Task[C].Media Eval,2014.
[5] Nam J,Alghoniemy M,Tewfik A H.Audio-Visual Content-Based Violent Scene Characterization[J].IEEE International Conference on Image Processing,1998(01):353-357.
[6] Datta A,Shah M,da Vitoria Lobo N.Person-onperson Violence Detection in Video Data[C].Pattern Recognition,2002:433-438.
[7] Ali S,Shah M.Human Action Recognition in Videos Using Kinematic Features and Multiple Instance Learning[J].IEEE Transactions on Software Engineering,2010,32(02):288-303.
[8] Nievas E B,Suarez O D,Garc´ ıa G B,et al.Violence Detection in Video Using Computer Vision Techniques[C].Computer Analysis of Images and Patterns,2011:332-339.
[9] Ahmad J,Fiaz M,Kwon S,et al.Gender Identification Using MFCC for Telephone Applications-A Comparative Study[J].arXiv preprint arXiv:1601.01577,2016:351-355.
[10] Peng X,Wang L,Wang X,et al.Bag of Visual Words and Fusion Methods for Action Recognition:Comprehensive Study and Good Practice[J].Computer Vision & Image Understanding,2016,150(C):109-125.
[11] Yang Q,Peng J Y.Chinese Sign Language Recognition Research Using SIFT-BoW and Depth Image Information[J].Computer Science,2014(02):302-307.
[12] Vapnik V N.The Nature of Statistical Learning Theory[J].Neural Networks IEEE Transactions on,1995,10(05):988-999.
[13] Hsu C W,Chang C C,Lin C J.A Practical Guide to Support Vector Classication[D].Taibei:National Taiwan University,2010.
[14] Sjöberg M,Ionescu B,Jiang Y G,et al.The Media Eval 2014 Affect Task:Violent Scenes Detection[C].Media Eval.2014.
[15] Pozzolo A D,Caelen O,Bontempi G.When is Under sampling Effective in Unbalanced Classification Tasks?[C].Joint European Conference on Machine Learning and Knowledge Discovery in Databases,2015:200-215.
[16] Demarty C H,Penet C,Soleymani M,et al.VSD,A Public Dataset for the Detection of Violent Scenes in Movies:D esign,Annotation,Analysis and Evaluation[J].Multimedia Tools & Applications,2015,74(17):7379-7404.
猜你喜欢
内江科技(2021年8期)2021-09-13
汽车零部件(2021年4期)2021-04-29
家庭影院技术(2019年7期)2019-08-27
家庭影院技术(2018年11期)2019-01-21
电子制作(2018年19期)2018-11-14
电子制作(2018年12期)2018-08-01
中国交通信息化(2017年2期)2017-06-06
电子制作(2017年9期)2017-04-17
中国修辞(2017年0期)2017-01-31
人间(2015年8期)2016-01-09
