
基于四层树状语义模型的场景语义识别方法
2018-01-06 12:24陈燕平宋曰聪
电子设计工程 2017年23期
李 敏 ,陈燕平 ,宋曰聪
(1.绵阳师范学院信息工程学院,四川绵阳621000;2.中国工程物理研究院五所四川绵阳621000)
基于四层树状语义模型的场景语义识别方法
李 敏1,2,陈燕平1,宋曰聪1
(1.绵阳师范学院信息工程学院,四川绵阳621000;2.中国工程物理研究院五所四川绵阳621000)
场景分类的主要方法是基于底层特征的方法和基于视觉词包模型的方法,前者缺乏语义描述能力并且时间复杂度大,后者识别率低。借鉴两类方法的优势,提出了基于四层树状语义模型的场景语义识别新方法。四层语义模型包括视觉层(图像的底层特性)、概念层(场景实物的名称)、关系层和语义层。提取训练样本场景实物的颜色、颜色层次和轮廓得到视觉层;同类场景中实物的名称(概念单词)的交集构成了概念层;统计概念单词的频率并对概念单词的空间位置关系进行关联规则的数据挖掘得到关系层;计算关键概念单词与PSB标准模型语义属性分类树的语义相似度得到场景高层语义。计算测试样本的底层特征后,通过视觉层的检索得到概念单词。通过概念单词的频率和空间位置关系关联规则的检索得到场景分类。由场景分类、场景高层语义、场景概念单词构成场景语义的识别结果。实验显示:新方法提高了识别率,降低了识别时间,并且具有场景高层语义的描述能力。
场景语义识别;四层树状语义模型;位置关系关联规则;场景高层语义;概念单词频率
图像场景的分析和理解是图像检索、机器视觉和智能监控发展的重要基础,在这几个领域都成为了研究热点,同时也被定义为21世纪初必须攻克的关键技术之一[1]。目前场景分类的第一类方法是基于形状、颜色、纹理等图像底层分类特征来建立不同图像的分类模型,典型的代表是Fei-fei L[2]研究了卧室、海岸、森林、办公室等13种场景的分类方法。图像的SIFT特征具有旋转和尺度不变的特性[3],使其成为场景分类特征表示的主要方法。目前基于底层分类特征(ILF)的场景分类方法的发展趋势是分类特征融合局部特征之间的空间布局信息。比如Lazebnik[4]采用的空间金字塔(SPM)匹配法,文献[5]中提出的用Gensus变换获取图像的局部特征的空间布局信息。基于底层分类特征的场景分类方法已经有了较高的分类识别率,主要缺陷是底层视觉特征与场景高层语义之间存在语义鸿沟,分类结果缺乏对场景语义的描述。同时由于该方法未对图像进行压缩描述,分类识别的时间复杂度也较大。
视觉词包模型(bag-of-visual-words-BVW)是一种基于中间特征的场景语义建模方法,可以克服图像底层特征与图像高层语义之间的鸿沟[6]。但经典词包模型方法的识别率低于基于底层分类的场景识别方法[7]。视觉词包模型方法和基于底层分类的场景识别方法目前都缺乏对场景高层潜在语义的描述能力。
针对这种现状,本文借鉴两类方法各自的优势,提出了基于四层树状语义模型的场景语义识别方法。四层语义树包括视觉层(图像的底层特性)、概念层(场景实物的名称)、关系层和语义层。构建四层场景语义树时,提取训练样本场景实物的颜色、颜色层次和轮廓得到视觉层;同类场景中实物的名称(概念单词)的交集构成了概念层;统计概念单词的频率并对概念单词的空间位置关系进行关联规则的数据挖掘得到关系层;计算概念单词与PSB标准模型语义属性分类树的语义相似度得到场景高层语义。识别场景语义时,通过视觉层的计算和检索得到概念单词,通过概念单词的频率和空间位置关系的检索得到场景分类,由场景分类、场景高层语义、场景概念单词构成场景语义的识别结果。
1 场景语义识别方法的技术路线
图1是本文场景语义识别方法的技术路线图,图中的技术路线主要包括以测试样本为数据源的四层语义树构建和以检测样本为数据源的场景语义识别两个模块。图中的特征提取主要是场景实物的颜色、颜色层次和轮廓特征。场景实物之间的关系主要是指空间位置关系和概念单词的词频分布。后续小节将分别介绍该技术路线各个环节的具体实现方法。图像分割参考文献[8]的方法,不在这里详细介绍。

图1 四层语义树模型场景语义识别技术路线
2 四层树状语义模型的引入
2.1 视觉词包模型的基本概念
视觉词包模型(bag-of-visual-words)是用于跨越图像底层视觉特征与高层语义鸿沟的一种中层特征模型,在图像场景分类中已经有了多年的研究[6]。视觉词包模型包括4个基本概念:①视觉单词;②视觉词典;③视觉词包;④潜在语义。视觉单词是场景实物的不同语义概念(如高楼、街道、树木等);视觉词典是概念单词的集合;视觉词包是场景图像中概念单词的统计分布情况,常用概念单词频度直方图来进行描述;潜在语义是对单词语义的进一步概括或抽象。比如沙滩、天空、海洋属于自然事物,高楼、码头属于人工建筑。论文以视觉词包模型为基础,提出了四层树状语义模型,下面介绍该模型的原理。
2.2 四层树状语义模型结构
图2是树状语义模型的结构,图3是足球机器人比赛对应的树状语义模型分解。
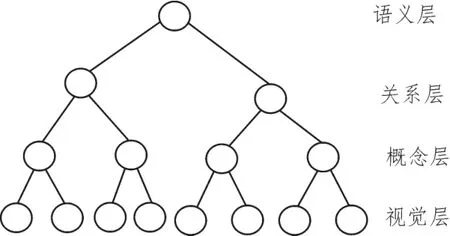
图2 四层语义树模型场景语义识别技术路线

图3 四层语义树模型分解过程及结果(足球机器人比赛)
3 四层树状语义模型视觉层的构建方法
将图像的颜色、颜色层次图、场景实物的轮廓进行融合,得到视觉层,具体融合方法如下:设待查图像P和数据库中某一标准样本Q之间的直方图距离为D1(P,Q),则D1(P,Q)的计算方法如公式(1)所示。
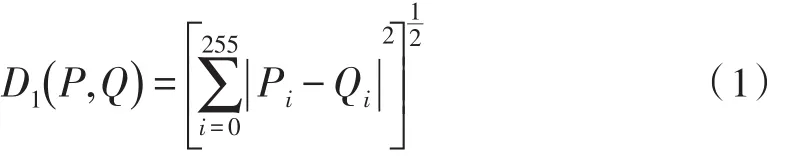
公式中,Pi和Qi是待查图形P和样本库Q的直方图i的具体数值。
设待查图像P和数据库中某一标准样本Q之间的颜色层次距离为D2(P,Q),则D2(P,Q)的具体计算方法如公式(2)所描述:

式(2)中PYi,QYi是P和Q第i个Y对应的DCT系数值,PCbi,QCbi是P和Q第i个Cb对应的DCT系数值,PCri,QCri是P和Q第i个Cr对应的DCT系数值。(ωy,ωcb,ωcr)是对应PYi与QYi,PCbi与QCbi,PCri与QCri的权值,在我们的方案中按照公式(3)取经验值,此经验值受图像采集系统的影响,可以通过样本训练进行调整。

设D(P,Q)是线性融合后的欧几里德距离,其计算公式如式(4)所示。

公式中的D3(P,Q)是场景实物的轮廓特征,提取方法参照文献[9]进行。ω1、ω2、ω3是联合系数,可以通过一定数量的样本训练调整得到,约束条件是3个参数的和为1。
4 四层树状语义模型概念层的生成
这里的概念层由场景实物的名称组成,场景实物的颜色,颜色层次图,轮廓形状对应一个场景实物的名称,在样本训练时由交互的方式输入,在样本测试时,通过颜色、颜色层次图、轮廓形状从视觉层进行查找,找出对应的场景实物名称。
5 四层树状语义模型关系层的构建
5.1 场景实物空间位置关系的语义描述方法
1)场景实物距离计算
选择目标物边缘的任意一点(xm,ym),选择周围备选参照物边缘的任意一点(xn,yn),按照式(5)计算目标物与备选参照物之间的距离。

2)场景实物之间方向关系计算
借鉴Roop K[10]提出的(3×3)方向关系矩阵模型来表示整场景实物中的方向关系,以参照物为中心,方向被分成9个区域,W=左、N=上、S=下、E=右、SW=左下、其他以此类推。目标物在9个区域中有分布,3×3矩阵对应位置取1或0。
3)场景实物之间拓扑关系的计算
9交模型[11]被认为是经典的空间拓扑关系模型,其定义如下:A,B为简单空间的两个几何对象,∂A,∂B为A,B的边界,A0,B0为A,B的内部,A-,B-为A,B的外部,A与B的空间拓扑关系表示为:

其中的元素都用0,1表示空和非空两种取值。
5.2 场景实物空间位置关系关联规则的数据挖掘
1)关联规则概念的引入
给定场景包含不同的项目集I={i1,i2,…,im},T={t1,t2,…,tn}是由同类场景的不同图像构成的空间位置关系数据库,且有tj⊆I,关联规则是类似于X→Y(X⊆I,Y⊆I,XIY=∅)的蕴涵式,若T中包含X⋃Y的比例为sup,则X→Y在T中的支持度为sup,T中包含X中包含Y的比例为conf,则X→Y在T中以置信度conf成立,即:

支持度表示空间位置数据库中规则出现的频率,置信度表示规则的可行程度。
2)寻找强关联规则的实现算法[12]

算法名称:AssociationRules
输入:空间关系数据表,支持度阈值minsup,置信度阈值minconf;
输出:满足支持度(minsup)和置信度(minconf)的空间位置关系关联规则。
算法中FIND_FREQUENT_1-ITEMSETS()是扫描整个关系数据表,统计每个item的支持数和支持度,将支持度>=minsup的放入L1中;apriori_gen()是对项目集进行组合,生成候选集Ck;sub set()是对数据关系表中的每个关系,找出所有候选集,放入Ct;genrules()设计成一个产生规则的递归函数。
6 四层树状语义模型语义层的描述方法
6.1 高层潜在语义计算方法
为了得到场景的高层潜在语义,需要得到场景实物的分类属性,为此需要计算场景实物名称与标准分类库之间的语义相似度。本文采用了比较典型的通用本体库和Rodriguez和Egenhofer方法[13-16]。对于一个实物的名称C,首先计算其在Word Net库中的信息量(Information Content,IC)值,如公式(8)所示。
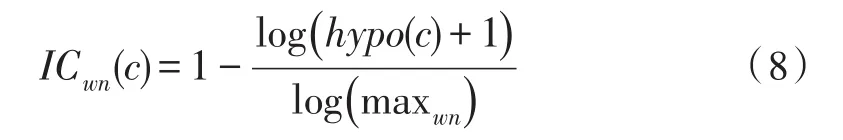
其中,hypo返回给定概念的下位词量,maxwn是分类中概念的最大数量,归一化处理后,IC∈[0,1],检索词Ci与模型库语义树某节点Cj的语义相似度用式(9)计算。

模型库语义树采用PSB(PrincetonShape Benchmark)标准库。
实物分类的语义检索从语义树的叶子节点开始检索,根据语义相似度找到匹配的实物名称,根据其父节点或祖父节点得到实物的类别。
6.2 语义层的语法生成规则
语义层为多维词组,词组的中文语法规则为:{高层潜在语义+场景类别+(主要场景实物+谓语+宾语)(可缺省)}。
7 四层场景语义树分类模型的构建算法
前面介绍了四层场景语义树相关具体步骤的实现方法,现在介绍语义树分类模型的构建算法。
名称:Produce_four_layer_semantic_tree()
输出:该类场景的四层场景语义树分类模型。
1)开始周期为n的循环;
2)构建视觉图像特征层:在每类场景中,统计该场景样本中各种概念单词出现的频率,设Th为阈值参数,选择概念单词出现频率高于该阈值的场景实物的特征按照以下方法建立叶节点。视觉层的叶节点为三元组元素,,其中为场景实物的颜色特征向量,为场景实物的颜色层次特征向量,为对象的轮廓特征向量,(同类场景概念单词的求交集不重复构建);
3)构建Tree4的父节点(概念层);
4)以场景中语义级别最高(以概念单词的词频和占场景面积大小为评价依据)的概念单词作为参照物,计算场景实物之间的位置(方向、拓扑、距离)关系,并进行关联规则数据挖掘;
6)构建语义层Tree1={Tk},语义层为多维词组,词组的中文语法规则为:{高层潜在语义+场景类别+(主要场景实物+谓语+宾语)(可缺省)}。
8 测试图像与分类模型语义相似性计算方法
8.1 语义特征的获取
对于测试用的一幅新图,对其进行图像分割后,首先提取其颜色、颜色层次图、对象轮廓等参数。通过对四层语义树叶节点的检索,得到概念单词并计算概念单词频率分布向量。按5.1节提供的方法得到概念单词的空间位置关系向量,按6.1提供的方法计算出高频率概念单词的高层潜在分类属性。设Wfrequency为概念单词频率分布向量,Sfrequency为概念单词空间位置关系向量,则语义特征Semantic_feature的表示公式为:
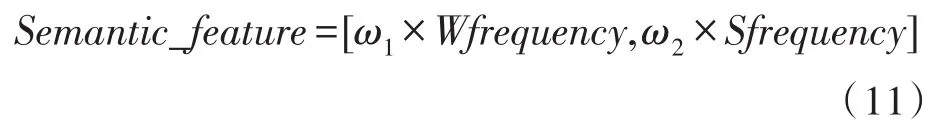
其中ω1,ω2为经验权值系数。
8.2 语义相似性计算方法
对于分类模型和测试图像均可以用式(11)计算其语义特征,判断测试图像属于哪一类则用χ2相似度来进行语义特征之间的比较,具体实现如公式(12)。

公式中的h是测试样本的语义特征,Hi是某一类分类模型的语义特征,K表示语义特征的维数,判断的分类规则是χ2越小,h则属于该Hi类图像。
9 实验与实验分析
赵理君[6]在其综述中指出,常用的场景分类库如表1所示。从表中可以看出,FP是目前比较经典的场景分类数据集,因为该数据集分出了13类场景,而其他的场景分类只有8类,LF场景库还是专门针对运动场景。但FP提供的是灰度图像,不能满足本文方法提取颜色直方图和颜色层次图的需要,故采取的策略是借鉴FP数据库的场景类别,自己建立场景分类的测试库,图像来源包括Corel图像集和百度搜索引擎,这样可以保证测试样本的普适性。实验选择了12类场景,每类场景400幅图像,其中300幅用于建立对应场景的场景语义树,另100幅用于测试检验。

表1 典型的场景分类数据库
实验1:为了验证算法的有效性,对各类场景做如下编号:卧室(1),高楼(2),街道(3),郊区住房(4),乡村(5),办公室(6),停车场(7),高速公路(8),商场(9),住宅小区(10),厨房(11),起居室(12)。为了进行功能验证和对比实验,所有的程序都用matlab-R2009a实现,测试在一台配置为(CPUAMD 3600+2.00 GHz,内存1.00G)的PC机上进行。图4是各种场景对应的识别率直方图。
从图4中不难看出,在12类场景中,分类准确率较低的是商场(9),起居室(11),厨房(12)等室内的场景,原因是这些场景中对象数目多而且有比较复杂的位置重叠关系,所以分类准确率较低,提高其分类准确率需要底层图像特征的处理技术的提升。
实验2:为了验证所提出的新方法与传统算法相比场景语义识别能力是否提高,选择了3个传统的场景分类方法与本文提出的方法进行了对比实验,训练样本容量为12×300=3 600幅场景图片。实验主要从平均分类准确率,计算时间和高层语义描述能力3个方面进行了对比,表2给出了实验结果。

图4 每类场景的分类准确率
本文提出的方法的分类模型在构建视觉特征层时,对每类场景概念单词的选择设置了阀值,压缩了图像的描述。而各类场景概念单词不重复构建原则(即求交集)也压缩了图像描述。与基于底层分类特征(简称ILF)的场景分类方法相比,本文提出的方法在实现概念单词提取时,不需要象ILF方法那样对样本库中每幅图像进行遍历比对(语义相似度计算是少数几次的计算,时间可以忽略)。所以,本文方法的时间复杂度理论上应低于ILF方法,如文献[4-5]中的方法。本文的方法充分考虑了图像的底层特征和概念单词的空间位置关系,所以识别率应高于ILF方法和基于视觉词包(BVW)模型方法。
从表2中的实验结果也可以看出,本文提出的方法平均分类准确性比ILF方法提高了7%,比BVW方法高10%以上。由于本文的方法采用的压缩存储结构,比ILF方法计算时间节约了约30%,而且具有了场景语义描述和高层潜在语义描述的能力,这是传统方法所不具备的优势。

表2 各种识别方法性能对比
10 结论
论文提出的方法实现了场景分类和语义描述,平均识别率约为79.3%,分类准确率较低的是商场,起居室,厨房等室内的场景,原因是这些场景中对象数目多而且有比较复杂的位置重叠关系。与传统的ILF方法相比,本文提出的方法平均分类准确性提高了7%,计算时间节约了约30%,识别率明显高于BVW方法,而且具有了场景语义描述和高层潜在语义描述的能力。
将来的工作应放在3个方面:1)如何提高底层视觉特征提取的准确性,以提高复杂室内场景的分类识别率;2)在大样本的情况下,场景分类的计算时间复杂度还是偏大,需要降低1至2个数量级才能达到实时性的要求,将来的工作应关注如何降低算法的时间复杂度,以达到工程应用中实时性的要求。3)目前的方法缺乏动态场景的描述能力,这也是将来的研究方向之一。
[1]Datta R,Joshi D,Li J,et al.Image retrival:ideas,influences,and trends of the new age[J].ACM Computing Surveys,2008,40(2):1-60.
[2]Fei-fei L,Perona P,A Bayesian hierarchical model for learning natural scene categories[C]//IEEE computer Society Conference on Computer Vision and Pttern Recognition,Washington,DC,USA,2005:524-531.
[3]Mikolajczyk K,Schmid C.A performance evaluation of local descriptors[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2005,27(10):1615-1630.
[4]Lazebnik S,Schmid C,Ponce J.Beyond bags offeature:Spatial pyramid matching for recognizing natural scene categories[C]//Computer Vision and Pattern Recogintion ,New York City,USA,2006:2169-2178.
[5]Wu Jian-xin,Rehg J M.Where am I:Place instance and category recognition using spatial using spatial PACT[C]//ComputerVisionandPatternRecogintion,Anchorage,Alaska,2008:24-26.
[6]赵理君,唐娉,霍连志,等.场景分类中视觉词包模型方法综述[J].中国图象图形学报,2014,19(3):333-343.
[7]王宇新,郭禾,何昌钦,等.用于图像场景分类的空间视觉词袋模型[J].计算机科学,2011,38(8):265-268.
[8]陈坤,马燕,李顺宝.基于直方图和模糊C均值的彩色图像分割方法[J].计算机应用与软件,2012,29(4):256-259.
[9]伊力哈木·亚尔买买提.基于粒子滤波的彩色图像轮廓提取算法研究[J].计算机仿真,2013,3(15):15-20.
[10]Roop K,Goyl.Max J.CA92373-8100.USA Similarity of cardinal Directions[J].Computer Science ,2001,21(21):36-55.
[11]沈敬伟,温永宁.时空拓扑关系描述及其推理研究[J].地理与地理信息科学,2010,26(6):1-5.
[12]李德毅.不确定性人工智能[M].北京:国防工业出版社,2005.
[13]Candamo J,Shreve M,Goldgof D B,et al.Understanding transit scenes:A survey on human behavior-recognition algorithms[J].IEEE Trans.Intell.Transp.Syst,2010,11(1):206-224.
[14]R.Poppe.A survey on vision-based human action recognition[J].Image Vision Compute.,2010,28:976-990.
[15]ZHANG Lu-ming,HAN Ya-hong.Discovering discriminative graph lets for aerial image categories recognition[J].IEEE Transactions on Image Processing,2013,2(12):5071-5083.
[16]LIU Shuo-yan,FENG song-he.Discriminating semantic visual words for scene classification[J].ICIE Trans.INE&SYST,2010,93(6):1580-1588.
The scene semantic recognition method based four layers treelike semantic model
LI Min1,2,CHEN Yan-ping1,SONG Yue-cong1
(1.Mian Yang Normal University Information Department,Mianyang621000,China;2.5Institute,China Academy of Engineering Physics,Mianyang621000,China)
The main ways of scene classification are based low-level image feature and based bag-ofvisual-words,the former lack the ability of semantic description and has large time complexity,the latter has low recognition rate.A new way of scene semantic recognition based four layers treelike semantic model is purposed by using the advantage of the two methods for reference.The four layers semantic model includes visual layer which is the low-level image feature and the concept layer which is the name of scene entity and relation layer and semantic layer.The visual layer is obtained by extracting the color and color gradation and outline of scene entity in training sample.The concept layer is constituted by intersection of the same kind scene entity name which is concept words.The relation layer is obtained by counting the frequency of concept words and data mining of concept words space location relationship association rules.The scene high level semantic is gotten by calculating the semantic similarity between PSB standard semantic attribute classification trees and key concept words.After calculating the lowlevel image features,the concept words are gotten by searching visual layer.The scene classification is obtained by searching the frequency and space location relationship association rules of concept words.The scene semantic recognition result is constituted by scene classification and scene high level semantic and concept words.The experiments show that the new way can improve the recognition rate and reduce the recognition time and has the ability of high level semantic description.
scene semantic recognition;four layers treelike semantic model;position relation association rules;scene high level semantic;concept word frequency
TN0
A
1674-6236(2017)23-0024-06
2016-12-01稿件编号:201612001
四川省教育厅资助项目(14ZA0257,142A0260);绵阳师范学院资助项目(2011A13,2013A10)
李敏(1975—),男,四川三台人,博士研究生,副教授。研究方向:模式识别,人工智能。
猜你喜欢
中学生数理化·中考版(2022年10期)2022-11-10
开放教育研究(2020年2期)2020-03-31
阅读(快乐英语高年级)(2020年8期)2020-01-08
作文小学中年级(2018年10期)2018-10-29
智慧少年·故事叮当(2018年11期)2018-05-14
电子制作(2018年1期)2018-04-04
意林(绘英语)(2017年5期)2017-05-15
湖南农业(2016年3期)2016-06-05
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
