
一种改进的基于核密度估计的DPC算法
2018-01-03 01:55:06仇上正张曦煌
计算机应用与软件 2017年12期
仇上正 张曦煌
(江南大学物联网工程学院 江苏 无锡 214000)
一种改进的基于核密度估计的DPC算法
仇上正 张曦煌
(江南大学物联网工程学院 江苏 无锡 214000)
快速搜索和找到密度峰DPC(clustering by fast search and find of density peaks)的聚类是一种新颖的算法,它通过找到密度峰来有效地发现聚类的中心。 DPC算法的精度取决于对给定数据集的密度的精确估计以及对截止距离dc(cutoff distance)的选择。dc主要是用于计算每个数据点的密度和识别集群中的边界点,而DPC算法中dc的估计值却主要取决于主观经验值。提出一种基于核密度估计的DPC方法(KDE-DPC)来确定最合适的dc值。该方法通过引用一种新的Solve-the-Equation方法进行窗宽优化,根据不同数据集的概率分布,计算出最适合的dc。标准聚类基准数据集的实验结果证实了所提出的方法优越于DPC算法以及经典的K-means算法、DBSCAN算法和AP算法。
概率密度估计 核密度估计 类簇中心 聚类
0 引 言
聚类在知识发现和数据挖掘的领域中起着重要作用。聚类算法试图将大量数据分配成不同的不相交的类别,其中更相似的数据点被分配到同一群集中,而不相似的数据点被分组到不同的群集中[1]。聚类分析是一种无监督的机器学习方法,在数据挖掘中,有着很重要的应用,在目前是重要的研究方向之一[2]。人们借助聚类分析,不仅可以从大量数据中发现所需的知识与信息,还可以降低工作量,提升工作效率。
目前,世界上存在的聚类算法有层次聚类方法、分层聚类方法、基于密度的聚类方法和基于网格的聚类方法,以及集成式聚类算法。在基于划分的算法中,K-means算法是目前运用最广泛的算法之一[3]。然而,严重依赖于初始聚类中心使得K-means算法的聚类结果难以满足目前人们的需求。
首先K-means算法很难发现非凸形状的簇,对噪声点和离群点敏感,而且严重依赖初始设定的K值。目前,K-means算法存在很大缺陷,文献[4-6]提出了GKM(Global K-means)算法等一系列改进的方法,来优化K-means算法。
2014年6月,由Alex和Laio在《Science》上发表了一种自动确定类簇数量和类簇中心的新型快速聚类算法,简称 DPC[7]。DPC算法存在两个优点:能快速发现任意形状数据集的密度峰值点 (即类簇中心),并且能够高效进行样本点分配,还可以快速进行离群点剔除工作。因此,DPC算法适用于大规模数据的聚类分析。然而,该算法存在一个重大的问题,在度量样本密度的时候,该算法根据主观经验,原文作者Alex选择2%作为截断距离参数dc的值,对聚类结果影响较大,可能丢失聚类中心,也可能无法识别所有核心点。
为了弥补该算法的不足,本文提出了一种改进的基于核密度估计的DPC算法(KDE-DPC)。为了减少因人为经验选取截断距离参数dc的因素对聚类结果造成的影响,在计算核密度的时候,我们通过引用一种新的Solve-the-Equation方法[8]来进行窗宽优化,然后设计一套迭代算法得出最优窗宽,利用最优窗宽从而产生较好的核密度估计结果。该方法避免了人工输入经验参数dc值的弊端,根据不同数据集,自动计算出最优窗宽,提高了核密度计算的准确性,同时还提高了样本分配边界点的结果。实验结果表明,该算法能够提高聚类的准确性,能准确识别所有聚类中心,还能更好地分配边界点。
1 相关研究
1.1 DPC算法
快速搜索和发现样本密度峰值的聚类算法(DPC)能自动发现数据集样本的类簇中心, 实现任意形状数据集样本的高效聚类。其基本原理是:理想的类簇中心(density peaks)具备两个基本特征:1) 与邻居数据点相比,类簇的中心点具有更大的密度;2) 与其他数据点相比,类簇中心点之间的距离相对较大。对于一个数据集,DPC 算法引入了样本i的局部密度ρi和样本i到局部密度比它大且距离它最近的样本j的距离δi,来找到同时满足上述条件的类簇中心,DPC算法的有效性很大程度上取决于密度和dc的准确估计。其定义如式(1)和式(2)所示:
(1)
其中:dij为样本i,j之间的欧氏距离,dc为截断距离,当x<0时,χ(x)=1,否则χ(x)=0。
δi=minj:ρj>ρi(dij)
(2)
对于局部密度最大的样本i,其δi=maxdij。
由式(1)可知,文献[7]引入的样本局部密度受截断距离dc影响。DPC算法中dc的选择基于启发式方法。数据集中的每个点邻居的平均数量应该仅为整个数据集的1%~2%。因此,截断距离dc与用户关于数据集性质的观察有关。为了避免截断距离对样本局部密度乃至聚类结果的影响, DPC 算法采用指数核[13]计算样本密度:
(3)
根据聚类心中定义,聚类中心有较大的密度ρi和较大的距离δi。选取28个据点以递减的密度顺序显示在图1中。根据计算每个数据点的值画出决策图,如图2所示。

图1 数据点分布图

图2 聚类中心决策图
从决策图中可以发现点1和10具有较大的密度值和距离值,根据聚类中心定义,可以确定这两个点位聚类中心。由于点26、27和28是孤立的,它们具有较高的δ和较低的ρ,可以被认为是噪声或异常值。 因此,使用决策图,可以容易地识别出期望的聚类中心。 在成功识别聚类中心之后,DPC算法基于它们在单个回合中的δ值,将剩余的数据点分配给最近的聚类中心,从而完成聚类。
1.2 核密度估计
核密度估计,是一种用于估计概率密度函数的非参数方法[9],为独立同分布F的n个样本点,设其概率密度函数为f,核密度估计为公式:
(4)
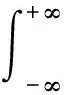
高斯核密度估计是一种常用的核密度估计方法:
(5)
式(5)的性能在很大程度上取决于窗宽h的选择。均方积分误差被用来衡量估计h的最佳标准:

(6)
高斯核密度估计具有一些限制,例如,敏感的参数h(带宽)难以选择、边界偏置,以及欠平滑或过平滑等缺点。
2 改进的DPC算法
针对上述DPC算法的问题,本文提出一种改进的基于核密度估计的密度峰快速聚类算法(KDE-DPC)。该算法包括各步骤:
(1) 计算出核密度的最佳带宽h;
(2) 根据h计算每个点的密度ρ;
(3) 计算出每个点的距离δ;
(4) 画出决策图;
(5) 从决策图中选取聚类中心;
(6) 将点分配给聚类中心;
(7) 检查边界点,形成聚类簇。
2.1 最优带宽h的选择
由文献[8]给出的核指数密度计算公式和核密度估计函数公式可以发现,dc相当于核密度估计函数公式中的窗宽h,我们想要得到最优的dc,可以转变为得到最优的窗宽h。
上面提到评价h优劣的标准为MISE,在弱假设下,其中AMISE为渐进的MISE,而AMISE如下:

(7)
为了使MISE最小,则转化为求极小值问题,如下:

(8)
其中:
通过式(8)得:

(9)
对于高斯核函数,R(K)=1,m2(K)=1。对于R(f″),我们引入一种新的方法Solve-the-Equation方法对R(f″)求解得:
(10)
由于式(10)中,在最优化hopt的表达式中含有未知量h,因此,我们设计一套迭代算法来计算最优的窗口值。令hopt=F(h),则计算最优窗口宽度值如下:
Step1h1=F(h0),h0=s,对于s的初始值我们对在后面阐述。初始化参数k,其中k为一极小值。
Step2当|h1-h0|>k时,循环执行下面步骤:
(1) 将h1的值赋给h0,即执行h0=h1;
(2) 对于新的h0值,利用表达式h1=F(h0)计算出新的h1值;

Step3返回窗口宽度最优值hopt=h1。
对于s的确定,我们采用如下标准:
其中:n为样本观察值的个数,σ为样本观察值的标准差。
2.2 算法性能分析
本文改进的算法复杂度主要由下面几个方面决定:1) 计算样本之间的距离,此过程的时间复杂度为O(n2);2) 计算hopt,时间复杂度为O(n2);3) 迭代求出最优h,时间复杂度为O(n)。
因此经过对比分析,相比于原算法,改进后的算法复杂度一样。
3 实验结果与分析
3.1 人工数据集实验结果分析
为了评估我们提出的KDE-DPC方法的效果,我们将提出方法的实验结果与DPC算法的结果作对比。所用的人工数据集如表1所示。DPC 算法是文献[7]作者提供的源代码。本文KDE-DPC算法采用 Matlab R2010a实现。本实验的所有实验运行环境均为Win 8 64 bit操作系统,Matlab R2010a软件,12 GB内存,Intel(R) Core(TM)2 Quad CPU I5-5200U@2.7 GHz。
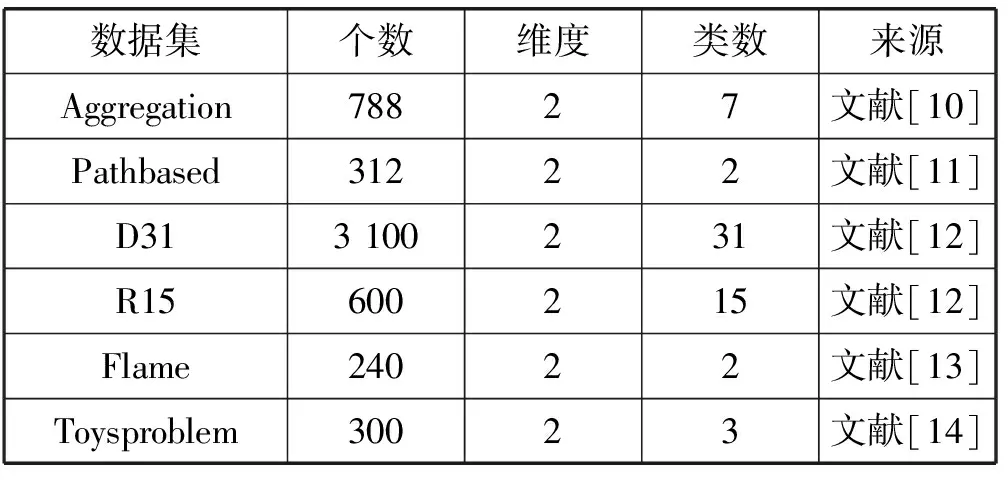
表1 数据集的基本信息
为了能更全面地展现本算法的效果,我们采用对比实验来分析算法。图3展现的是提出的KDE-DPC算法与DPC算法分别在D31数据集和R15数据集上做纵向对比实验的结果。


图3 DPC算法与KDE-DPC算法对R15数据集和D31数据集的聚类结果
从图3中,我们可以发现提出的KDE-DPC算法能够更好地处理噪声点,准确分配样本点。
表2展示了本文提出的KDE-DPC算法与DPC算法在识别聚类点和错误分类点方面的详细比较。从表中可以发现KDE-DPC算法无论数据集的性质如何,都能准确识别聚类群的核心点。

表2 对比DPC和KDE-DPC检测核心点和错误点的分类情况
因此,本文提出的KDE-DPC算法是一种能适用于不同数据集的有效的聚类通用解决方案。
3.2 真实数据集实验结果分析
本文还采用真实的UCI数据集来验证改进的KDE-DPC算法的聚类性能,并采用Acc、AMI和ARI三个聚类指标来做综合评价。表3给出了本文KDE-DPC算法,以及对比算法DPC、AP、K-means、DBSCAN算法在真实UCI数据集上的聚类结果。

表3 DPC、AP、K-means、DBSCAN算法在真实UCI数据集上的实验结果
从表3中可以明显看出我们提出的KDE-DPC算法在Acc、AMI和ARI三项指标明显优越于DPC、AP、DBSCAN,以及K-means等经典算法。
总之,本文提出的KDE-DPC算法在复杂度上与DPC算法相同,但在精度上明显优越于DPC算法以及其他经典算法。
4 结 语
DPC算法思想新颖,而且简单快速的特点。算法效率上明显优越于其他经典算法,但是在参数dc的选择上有很大的缺点。本文通过基于核密度估计优化的思想改进了该算法,达到了不错的效果。并且,通过对人工数据以及真实数据的测试,验证了本算法的优点。
在决策图中,需要人工肉眼来选择聚类中心,在很多情况下,聚类中心难以分辨,容易造成错误的聚类中心或者聚类中心的缺失。未来,我们将进一步优化该算法,能够实现自动准确选取聚类中心的功能。
[1] Han J W,Kamber M.Data Mining Concepts and Techniques[M].2nd ed.New York:Elsevier Inc,2006:383-424.
[2] Lu J,Liong V E,Zhou X,et al.Learning Compact Binary Face Descriptor for Face Recognition[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2015,37(10):2041-2056.
[3] Jain A K.Data Clustering:50 Years Beyond K-means[M]//Machine Learning and Knowledge Discovery in Databases.Springer Berlin Heidelberg,2008:651-666.
[4] Likas A,Vlassis N,Verbeek J J.The global k-means clustering algorithm[J].Pattern Recognition,2003,36(2):451-461.
[5] Xie J,Jiang S,Xie W,et al.An Efficient Global K-means Clustering Algorithm[J].Journal of Computers,2011,6(2):271-279.
[6] Ester M,Kriegel H P,Sander J,et al.A density-based algorithm for discovering clusters in large spatial databases with noise[C]//Proceedings of ACM SIGKDD’96,Portland,1996:226-231.
[7] Rodriguez A,Laio A.Machine learning.Clustering by fast search and find of density peaks[J].Science,2014,344(6191):1492-1496.
[8] Alexandre L A.A Solve-the-Equation Approach for Unidimensional Data Kernel Bandwidth Selection[OL].2008.http://www.di.ubi.pt/~lfbaa/entnetsPubs/bandwidth.pdf.
[9] Alan Julian Izenman.Review Papers:Recent Developments in Nonparametric Density Estimation[J].Journal of the American Statistical Association,1991,86(413):205-224.
[10] Gionis A,Mannila H,Tsaparas P.Clustering Aggregation[J].Acm Transactions on Knowledge Discovery from Data,2007,1(1):4.
[11] Chang H,Yeung D Y.Robust path-based spectral clustering[J].Pattern Recognition,2008,41(1):191-203.
[12] Veenman C J,Reinders M J T,Backer E.A maximum variance cluster algorithm[J].Pattern Analysis & Machine Intelligence IEEE Transactions on,2002,24(9):1273-1280.
[13] Fu L,Medico E.FLAME,a novel fuzzy clustering method for the analysis of DNA microarray data[J].Bmc Bioinformatics,2007,8(1):3.
[14] Pedregosa F,Gramfort A,Michel V,et al.Scikit-learn:Machine Learning in Python[J].Journal of Machine Learning Research,2011,12(10):2825-2830.
ANIMPROVEDDPCALGORITHMBASEDONKERNELDENSITYESTIMATION
Qiu Shangzheng Zhang Xihuang
(SchoolofInternetofThingsEngineering,JiangnanUniversity,Wuxi214000,Jiangsu,China)
Clustering by fast search and find of density peaks (DPC) is a novel algorithm that efficiently discovers the centers of clusters by finding the density peaks. The accuracy of DPC depends on the accurate estimation of densities for a given dataset and also on the selection of the cutoff distance (dc). Mainly, dc is used to calculate the density of each data point and to identify the border points in the clusters. However, the estimation of dc largely depends on subjective experience. This paper presents a method based on kernel density estimation (KDE-DPC) to determine the most suitable dc. This method performs window width optimization by referencing a new Solve-the-Equation method. According to the probability distributions of the different data sets, the optimal dc is obtained. The experimental results of standard clustering benchmark data sets confirm that the proposed method is superior to DPC algorithm, as well as classic K-means algorithm, DBSCAN algorithm and AP algorithm.
Probability density estimation Kernel density estimation Cluster center Clustering
2016-12-22。江苏省产学研合作项目(BY2015019-30)。仇上正,硕士生,主研领域:计算机应用技术。张曦煌,教授。
TP391
A
10.3969/j.issn.1000-386x.2017.12.053
猜你喜欢
统计与管理(2024年5期)2024-10-19 00:00:00
廊坊师范学院学报(自然科学版)(2022年3期)2022-10-11 04:32:06
北京航空航天大学学报(2022年8期)2022-08-31 08:58:24
科技视界(2021年4期)2021-04-13 06:03:56
小学生导刊(2018年34期)2018-12-18 01:53:14
电子测试(2017年15期)2017-12-18 07:19:27
山东青年(2016年3期)2016-02-28 14:25:55
智能系统学报(2015年4期)2015-12-27 09:38:39
母子健康(2015年1期)2015-02-28 11:21:33
电子设计工程(2015年6期)2015-02-27 12:04:53
