
云环境下并行DBSCAN聚类算法研究
2017-12-20 03:42:50邓青,杨宁
山西电子技术 2017年6期
邓 青,杨 宁
(1.山西轻工职业技术学院,山西 太原 030013;2.山西云时代技术有限公司,山西 太原 030006)
云环境下并行DBSCAN聚类算法研究
邓 青1,杨 宁2
(1.山西轻工职业技术学院,山西 太原 030013;2.山西云时代技术有限公司,山西 太原 030006)
DBSCAN算法是一种基于密度的快速聚类算法,虽然在处理大规模数据时可以发现其中的噪声数据,但聚类效率不高,输入/输出消耗大,聚类结果准确率低。本文在云计算平台 Hadoop环境下,将MapReduce编程模型的高并行性引入该算法,设计出一种并行 DBSCAN算法,提高传统DBSCAN算法的执行效率,通过对比实验结果证明了该算法聚类的准确性和时效性。
聚类分析;云计算;DBSCAN;HDFS; MapReduce
聚类分析作为数据挖掘与统计分析的重要研究领域,近年来倍受关注。所谓聚类就是将物理或抽象对象的集合组成为由类似的对象组成的多个类的过程。现代社会各行各业产生的数据是海量的,如何从中挖掘出有用的信息,需要借助有效的聚类算法。传统的聚类算法在处理海量数据时,在时间复杂度和空间复杂度方面很高。而基于云计算的Mapreduce模型具有较高的并行性,可以与聚类算法进行有效结合,提高聚类算法处理海量数据时的性能。
云计算作为一种新兴的商业计算模型,是并行计算、分布式计算和网格计算机的发展[1]。Hadoop作为一种能够对大量数据进行分布式处理的软件框架,具有伸缩性强、成本低、效率高、可靠性好等优点。Hadoop平台的核心框架有:分布式文件系统HDFS[2]和计算模型MapReduce[3]。
HDFS是一个主从结构,一个HDFS集群是由一个名称节点(Namenode)和多个数据节点(Datanode)组成。名称节点是一个管理文件命名空间和调节客户端访问文件的主服务器,管理对应数据节点的存储。在使用上,HDFS与单机上的文件系统非常类似,同样可以建目录,创建、复制、删除文件,查看文件内容等[4]。
MapReduce是一种并行计算与运行软件框架,用于大规模数据集(大于1TB)的并行运算,也是一种基于集群的高性能并行计算平台。它将数据处理分为Map和Reduce两个阶段,用Map和Reduce两个函数编程实现基本的并行计算任务,提供了抽象的操作和并行编程接口。Map过程处理接受一个键值对(key-value对),产生一组中间键值对,以[key,value]对方式输出;Reduce过程接受一个键,以及相关的一组值,将这组值进行合并产生一组规模更小的值,最后输出结果。所以实现DBSCAN算法的并行化处理,需要对Map和Reduce过程进行改进设计。
1 基于Hadoop的并行DBSCAN聚类算法设计
1.1 DBSCAN算法描述
DBSCAN算法是一种简单、有效的基于密度的聚类算法,该算法可以过滤密度较低的样本点,发现密度较高样本点区域,可以快速发现任意形状的类。基本思想是:对于一个类中的每个样本,在其给定半径的邻域中包含的样本数不能少于某个给定的值。
DBSCAN算法涉及到几个重要概念:
Eps邻域:对于任意点p,以p为中心,Eps为半径的区域构成p点的Eps邻域。
核心点:对于任意点,如果该点的Eps邻域内的点个数超过给定的阈值MinPts,则该点为核心点。
边界点:空间中任意点,本身不是核心点,但是落在某个核心点的Eps邻域内,该点被称为边界点。边界点可能落在多个核心点的邻域内。
直接密度可达:对于样本集合D,如果样本点q在p的Eps邻域内,且p为核心点,那么样本点q从p直接密度可达。
密度可达:对于样本集合D,给定一串样本点p1,p2……pn,p=p1,q=pn,如果pi从pi-1直接密度可达,则q从p密度可达。密度可达是直接密度可达的一个扩展,密度可达是可以传递的,但密度可达不对称。
密度相连:对于样本集合D中的任意一点O,若存在点P到O密度可达,并且点q到O密度可达,那么q到p密度相连。密度相连是一个对称关系。
噪声点:既不是核心点也不是边界点的任何点。
DBSCAN发现类的过程如下:step1,确定算法运行所需的两个参数:Eps和MinPts;step2,从样本集D中选取任意一个样本点p,判断其Eps邻域内点的数目,如果点数大于或等于参数MinPts,则p为核心点;step3,如果p为核心点,构建以p为中心的簇,依次将p的Eps邻域内的各点标记为与p相同的类标识。如果该邻域内的点q也为核心点,那么q是p的密度可达点,将点q及其Eps邻域内的点也标记为p的类p的E标识;如果q不为核心点,则直接将其标记为p的类标识。如果p为边界点,则p的Eps邻域包含点数小于参数MinPts,没有点从p密度可达,则p标记为噪声点。step4,从样本集D中选择下一个样本点,重复进行step2、step3,直到样本集D中没有未遍历的点,聚类过程结束。
在数据空间中,存在一个边界点的邻域内可能包含多个核心点,这些核心点可能属于不同的簇。DBSCAN算法没有对这样的边界点归属问题进行进一步甄别,而采取简单的“谁发现归谁所有的策略”[6]。为了提高聚类精度,可以使用基于距离的方法处理边界点,将边界点划入离它距离最近的核心点所属类中。
DBSCAN算法的思路是通过对样本集D中每个点Eps邻域来判断其是否为核心点,进而决定如何进行簇扩展。该算法中对每个样本点进行计算,计算每个点的时间复杂度为O(n),因此,算法的时间复杂度为O(n2)。随着n的数量级增大,串行DBSCAN算法的运行时间也增大,因此对于串行DBSCAN算法不适合大数据量的环境。而采用并行化处理方式可以提高算法执效率。可以对样本集D均分为q个子样本集,对每个q进行独立局部DBSCAN聚类,然后通过通信输出全局聚类结果。
1.2 DBSCAN的MapReduce实现
MapReduce是一种高效的分布式编程模型,也是一种用于处理和生成大规模数据集的实现方式。它将数据处理分为Map和Reduce两个阶段。Map过程处理输入的
1.2.1 Map过程
各节点将收到的子样本集归并为
函数的伪码为:
Map (
输入
调用initial Cluster ( )函数; //initial Cluster ( )为初始聚类函数;
输出
}
当样本集很大,划分后的每个子样本集中的样本较相近时, Map过程会产生成千上万的中间输出结果[ key1,value1]记录,这些庞大的数据量将增加网络传送过程中的通讯代价。所以,设计一个Combine函数,对每个Map函数的输出结果进行本地分类和合并,可以降低网络通讯延迟,提高I/O性能。
1.2.2 Combine过程
Combine函数将Map函数的输出作为输入,输出
Combine(
输入Map函数输出的
将pid值相同的点归为一组,存储为中间键值对
Maple在求解推广的Clairaut型方程中的应 用 …………………………………………… 吕晓静,赵向东(47)
利用分区函数hash mod R将中间键值对分成R个不同的分区;
输出不同分区的键值对;
}
1.2.3 Reduce过程
执行Reduce任务的处理机收到Combine过程分配给自己的那部分数据
Reduce (
输入收到的
While (存在公共点) {
}
输出结果
}
2 实验结果分析
为验证基于Hadoop平台的DBSCAN算法准确性和时效性,分别从标准数据集KDD Cup’99和UCI数据集中选取两组数据分别进行验证。
表1给出单机环境和基于Hadoop平台下算法对数据样本集Dataset1(KDD Cup’99选取)的聚类结果。对比两种模式下聚类正确率差异,验证了基于Hadoop平台的聚类准确性不差。
为验证基于Hadoop平台算法的时效性,将从UCI数据集中选择的样本集Dataset2进行多次复制获得大规模数据,并在单机和平台上进行运行。其对比结果如图1所示。
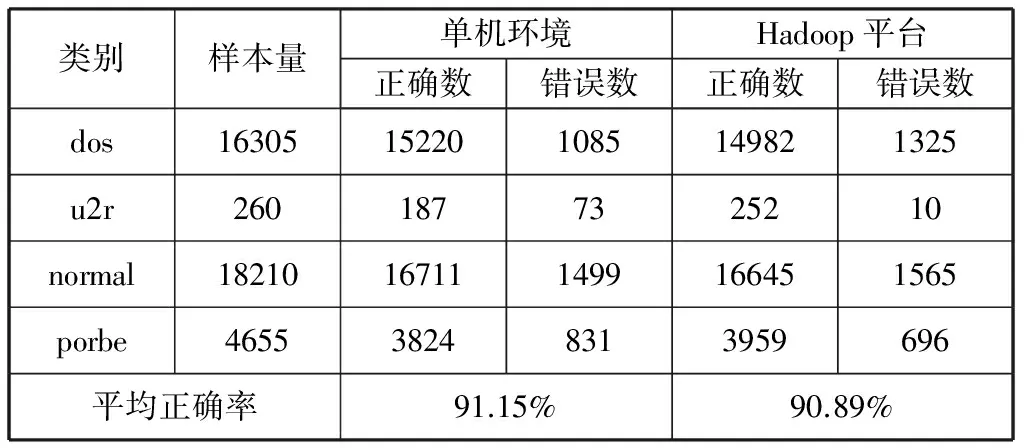
表1 单机和基于Hadoop平台聚类准确率比较
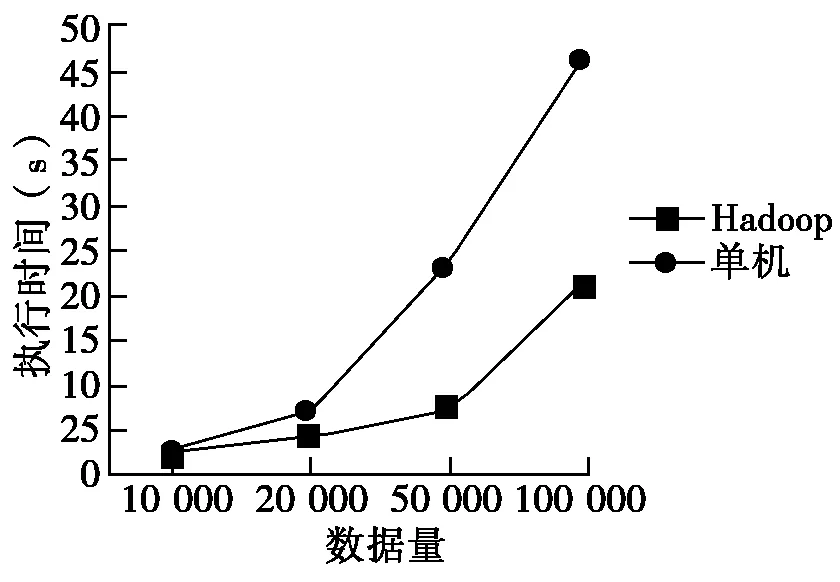
图1 单机和基于Hadoop平台聚类时效性对比
从图上看出,基于Hadoop平台的DBSCAN算法执行时效性很高,特别是数据量越大,优势越明显,因此更适合于对大数据的挖掘和分析。
3 总结
本文介绍了云平台Hadoop的MapReduce分布式编程模型,并对基于密度的DBSCAN算法的思想和流程进行了描述,给出基于MapReduce的并行DBSCAN算法的实现思路并给出Map、Combine、Reduce过程的伪代码设计,通过实验数据证明了算法的正确性和时效性。
[1] Kai Hwang,Geoffrey C.Fox ,Jack J.Dongarra.云计算与分布式系:从并行处理到物联网[M].北京:机械工业出版社,2013.
[2] Ghemawat S,Gobioff H,Leung S.The Google File System[J].SACM SIGOPS Operating Systems Review,2003,37(5):29-40.
[3] Dean J,Ghemawat S.Map Reduce: Simplified Data Processing on Large Clusters[C]//Proceedings of Operating Systems Design and Implementation.San Francisco,CA,2004:137-150.
[4] 赵卫中,马慧芳.基于云计算平台Hadoop的并行k-means聚类算法设计研究[J].计算机科学,2011(10):166-168,+176.
[5] 谢雪莲,李兰友.基于云计算的并行K-means聚类算法研究[J].计算机测量与控制,2014,22(5):1510-1512.
[6] 蔡颖琨,谢昆青.屏蔽了输入参数敏感性的DBSCAN改进算法[J].北京大学学报(自然科学版),2004,40(3):480-486.
ResearchonParallelDBSCANClusteringAlgorithminCloudEnvironment
Deng Qing1, Yang Ning2
(1.ShanxiLightIndustryCareerTechnicalCollege,TaiyuanShanxi030013,China;2.ShanxiCloudTechnologyCo.,Ltd.,TaiyuanShanxi030006,China)
DBSCAN algorithm is a density-based fast clustering algorithm. Although the noise data can be found when dealing with large-scale data, the clustering efficiency is not high, the input / output consumption is large and the accuracy of clustering results is low. In this paper, the parallelism of the MapReduce programming model is introduced into the Hadoop environment, and a parallel DBSCAN algorithm is designed to improve the efficiency of the traditional DBSCAN algorithm. The accuracy of the algorithm is proved by comparing the experimental results and timeliness.
clustering analysis; cloud computing; DBSCAN; HDFS; MapReduce
2017-10-10
邓 青(1983- ),女,山西大同人,讲师,硕士研究生,研究方向:数据挖掘、智能算法。
1674- 4578(2017)06- 0087- 04
TP311.13;TP301.6
A
猜你喜欢
测绘学报(2021年11期)2021-12-09 03:13:12
激光技术(2021年5期)2021-08-17 03:36:02
吉林大学学报(理学版)(2020年3期)2020-05-29 06:32:16
自动化学报(2018年7期)2018-08-20 02:59:04
电子测试(2017年15期)2017-12-18 07:19:27
周口师范学院学报(2016年5期)2016-10-17 06:36:47
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
电脑与电信(2014年6期)2014-03-22 13:21:06
华东理工大学学报(自然科学版)(2014年2期)2014-02-27 13:48:48
