
基于扩展质量功能展开和网络图的产品大数据分析方法及其应用探讨
2017-12-20 09:21唐中君崔骏夫禹海波
中国科技论坛 2017年12期
唐中君,崔骏夫,禹海波
(北京工业大学经济与管理学院北京现代制造业发展研究基地,北京 100124)
基于扩展质量功能展开和网络图的产品大数据分析方法及其应用探讨
唐中君,崔骏夫,禹海波
(北京工业大学经济与管理学院北京现代制造业发展研究基地,北京 100124)
现有大数据分析方法存在侧重算法提升而忽视数据固有关系、难以综合分析网络形态数据之间连动关系的问题。为解决这些问题,提出了一个基于扩展QFD和网络图的产品大数据分析方法。该方法由面向数据关系的扩展QFD、基于网络图的产品大数据关系描述模型和基于该描述模型的产品大数据分析模型组成。该方法有助于厘清产品各类数据间的固有关系,可将具有复杂结构、多重关系的数据以清晰的网络结构表现出来,并可综合利用多种大数据分析模型对产品大数据进行模式探索,从而达到从海量数据中获取关键数据、发现新数据及数据间的新关系等目标。解决了现有大数据分析方法忽视数据固有关系、难以综合分析数据间连动关系的问题,使数据建模与算法技术更好地结合。
大数据分析;质量功能展开;网络图;产品大数据
1 引言
数据采集和存储技术的长足进步使企业得以拥有大量与产品有关的数据,其主要来源有企业自有数据、公开信息和有偿获取数据[1]。来自各类信息源的数据存在不同表现形式,如历史数据和实时数据、线上和线下数据、传感数据和社会数据等。这些多源异构数据产生于产品全生命周期的不同阶段,共同组成了产品大数据。多源异构和产生于全生命周期不同阶段的性质使得产品大数据呈现出复杂的结构、多重的关系,使数据及其关系具有了网络形态特性。产品的全生命周期包含需求分析、设计、制造、销售和售后阶段。本文结合产品全生命周期各阶段将产品大数据分为需求类、产品属性要求类、制造要求类(零部件要求子类、工艺要求子类、生产要求子类)、销售要求类、运营类和售后使用类。其中运营类数据产生于供应链活动,涉及原材料采购、产品制造、生产、销售和售后服务等活动。各类产品大数据产生于产品生命周期不同阶段,反映产品处于不同阶段的状态,将这些数据融合分析能够清晰地识别产品全生命周期内各类数据之间的关系,有助于提取新的关系与模式,从而为开拓市场和制定商业模式提供决策参考。
大数据分析方法源于多个领域,如统计学、计算科学和经济学等,主要有关联规则学习、分类、聚类、网络分析、神经网络等方法[2]。这些方法侧重于算法性能优化和处理技术的提升。例如,Zhang等使用spark技术提升了关联模式挖掘中频繁集挖掘的迭代计算效率[3]。Wu等使用基于迭代样本的频繁模式挖掘方法优化了大数据处理的效率问题[4]。Sarma等使用一种寻找分割面的方法优化了K-means聚类方法;该方法以牺牲聚类质量为代价,显著增加了大数据集的聚类速度[5]。一些学者改进了支持向量机方法,降低了原有算法的时间复杂度和空间复杂度[6-8]。Jiang等结合约束聚类和KNN算法生成增强型KNN算法;该算法降低了文本相似度的计算量,提升了对文本型大数据分类的效率[9]。可以看出目前有关大数据分析方法的研究主要针对算法本身,欠缺对数据之间固有关系的分析研究。
在分析具有复杂结构和网络型多重关系的数据时,一些学者使用了网络分析方法。例如Sudhahar等使用中心度、同配性等多种网络分析指标对2012年美国大选期间的网络新闻数据进行了分析,找出了竞选期间候选人在其社交网络中与其他节点的关系;各节点代表资助方或党派候选人,节点间连线表示资助关系[10]。He等构建了一个基于随机矩阵论的统一数据分析模型用于分析移动网络数据的特点[11]。Alamsyah等人使用社交网络方法分析了某组织内员工的36000多封邮件的收发关系,以帮助该组织实施组织内部的知识管理[12]。Lobb等利用网络分析方法对癌症项目进行分析并提出优化建议[13]。Chopade等利用节点属性和边的结构对网络数据进行分析,并根据网络属性设计了网络社区识别算法[14]。可以发现网络分析方法广泛用于描述数据之间的关系。但是,运用网络分析方法分析数据之间关系的文献鲜有利用数据之间的固有关系。此外,目前学者在分析具有复杂结构和网络型多重关系的数据时仅使用单一的分析方法,尚未发现将多种大数据分析模型综合运用于数据分析的研究。因而目前的大数据分析方法难以综合利用各类数据建模与算法技术,难以综合分析数据之间的联动关系。
针对上述问题,本文将提出一个基于扩展QFD和网络图的产品大数据分析方法。该方法由三部分组成:面向数据关系的扩展QFD,基于网络图的产品大数据关系描述模型和基于该描述模型的产品大数据分析模型。其中面向数据关系的扩展QFD能将复杂的数据类抽象为变量集,并识别出变量之间的固有关系。基于网络图的产品大数据关系描述模型能将扩展QFD识别出的数据及其多重关系以直观清晰的网络形式表现出来。基于描述模型的产品大数据分析模型通过联用多种大数据分析方法对描述模型的网络图进行研究,对数据之间的关系进行综合分析,以实现多角度的模式探测。该方法解决现有大数据分析方法侧重算法提升而忽视利用数据间固有关系的问题,并能综合多种大数据分析方法分析具有复杂结构和网络型多重关系数据之间的联动关系,使数据建模与算法技术高效地结合。
2 面向数据关系的扩展QFD
传统QFD是一种重要的产品设计技术,通过四个质量屋的顺次分析将顾客要求转化成产品属性要求、零部件要求、工艺要求和生产要求[15]。QFD通过描述数据及其之间的关系实现各类信息之间的转化,从而使QFD可用于识别数据之间的固有关系。传统QFD涉及的数据有顾客需求类数据、产品属性要求类数据、零部件要求类数据、工艺要求类数据和生产要求类数据。这些数据类涉及的数据间关系有两类。一类是同类数据之间的关系,包括顾客不同类别要求之间的相互约束关系、产品属性要求间的相互约束关系、零部件要求之间的相互约束关系、工艺要求之间的相互约束关系、生产要求之间的相互约束关系。另一类是不同类数据之间的关系,包括顾客要求与产品属性要求之间的因果关系、产品属性要求与零部件要求之间的因果关系、零部件要求与工艺要求之间的因果关系、工艺要求与生产要求之间的因果关系。然而传统QFD是一种以顾客需求为起点的产品设计工具,从描述产品全生命周期内数据之间关系的角度看,存在两方面局限。首先,传统QFD的信息转化过程是单向的[16],仅考虑产品生命周期中相邻阶段数据类之间的关系,没有同时考虑所有阶段所有数据间可能存在的关系。其次,传统QFD的四个质量屋仅反映产品生产之前的数据类及其关系,无法体现全生命周期的产品大数据及各数据类之间的关系。
针对上述局限,本文提出了如图1所示的“面向数据关系的扩展QFD”。图中,平行四边形代表数据类,矩形代表质量屋的左墙和天花板,虚箭线连接了数据类与质量屋,表示质量屋所需的数据由所连数据类提供,实折线表示质量屋之间的信息传递。在传统QFD的基础上,本文从数据类、质量屋和数据关系等方面进行了扩展。

图1 面向数据关系的扩展QFD
首先,根据产品全生命周期数据的分类,将销售要求类数据、运营类数据和售后使用类数据加入传统QFD中。销售要求类数据用于提供营销要求。运营类数据包含供应链活动所涉及的企业采购、生产、营销和售后等活动数据。相较于要求类数据(产品属性要求类、制造要求类、销售要求类),运营类数据属于动态数据。售后使用类数据包含产品使用数据、服务数据、维护数据和回收数据。这些数据与顾客相关,对这些数据的分析能析出消费者的新需求,为新一阶段扩展QFD提供需求类数据。产品全生命周期所有数据类的加入,使得面向数据关系的扩展QFD可以进行全生命周期内多重数据类关系识别。
其次,增加了两个质量屋。随着销售要求类数据的加入,添加了产品属性要求、零部件要求、工艺要求及生产要求与营销要求的质量屋。该质量屋用于识别产品属性要求数据、零部件要求数据、工艺要求数据及生产要求数据和营销要求数据之间的关系。供应链活动受传统QFD中各类要求数据的影响,例如原材料采购与零部件要求有关、生产制造活动与工艺要求及生产要求有关、产品销售活动与营销要求有关等。因此,本文添加了一个将产品属性要求、零部件要求、工艺要求、生产要求和营销要求共同作用于供应链活动的质量屋。
最后,根据新加入的数据类和质量屋,扩展得到两类新的数据关系。一是有关同类数据之间的关系,包括营销要求之间的相互约束关系、不同类别售后使用数据之间的约束关系、不同供应链活动数据之间的约束和反馈关系。二是有关不同类数据之间的关系,包括产品属性要求、零部件要求、工艺要求、生产要求分别与营销要求之间的因果关系,以及产品属性要求、零部件要求、工艺要求、生产要求、营销要求分别与供应链活动之间的因果关系。
从图1可知,面向数据关系的扩展QFD可以识别两大类数据关系。一类是依据数据产生于生命周期的阶段而得的关系,即扩展QFD中全部质量屋内左墙数据间关系、屋顶数据间关系以及两者相互之间的关系,形成了如图1所示的从左上到右下的依产品生命周期不同阶段的瀑布型关系。
另一类是如表1所示依据数据间抽象关系的种类而得的五种关系。第一种关系是层级关系,表示数据类A可以细分为若干子类。例如制造要求类数据可以细分为零部件要求、工艺要求和生产要求类数据。第二种关系是约束关系,表示数据类A和数据类B中任一类的变动将导致另一类的变动。例如任一质量屋中位于屋顶的数据之间可能存在约束关系。第三种关系是反馈关系,表示数据类A在影响数据类B后,数据类B又反馈影响数据类A。例如供应链活动数据中的生产类数据会影响营销类数据,营销类数据又将反馈作用于生产类数据。第四种关系为因果关系,表示数据类A在受到一定影响后,产生数据类B。例如售后使用类数据可以析出消费者对产品的部分新需求。第五种关系是自更新关系,表示数据类A随着时间的推移,对自身状态进行更新。

表1 数据关系
面向数据关系的扩展QFD将产品全生命周期内产生的大数据融入传统QFD,延长了传统的信息转化过程,并在延长的过程中丰富了数据类固有关系。数据类关系分为依据生命周期产生阶段而得的关系和依据数据间抽象关系种类而得的关系,两类关系皆借助QFD中质量屋结构来体现。在大数据时代,每个数据类都与其他数据类之间存在多重复杂关系,无法脱离其他数据类而单独发挥作用,故利用扩展QFD能以结构化方式识别数据类间固有关系,为后续分析提供便捷。此外,供应链活动质量屋的加入将直线式的QFD变成了闭环式的结构。这种闭环式结构将QFD中多个质量屋分别与营销要求质量屋和供应链活动质量屋相连,可同时考虑相连两者所涉及数据类的固有关系。
总之,面向数据关系的扩展QFD是一种帮助识别数据类间固有关系的工具。使用该工具可以对数据分类,并识别出产品大数据间存在的两大类固有关系。
3 基于网络图的产品大数据关系描述模型
网络图由节点和连线构成。节点可以具有不同属性,两个节点之间的连线反映节点之间的关系。该关系可以通过节点间连线的方向性、强弱等多种方式加以描述。网络图中所有连线反映了所有节点之间的全局关系,可以通过节点的度、中心性、最短路径和介数等方式加以描述。
由上节可知,通过面向数据关系的扩展QFD可以帮助识别产品大数据包含的数据类及其间的固有关系。对数据类及数据关系的描述,既要描述所有的数据类,还要描述局部数据类之间的关系,更要从整体描述所有数据类之间的全局关系。基于网络图的上述特点,本文提出如图2所示的产品大数据关系描述模型。图中平行四边形代表不同的数据类,虚线表示不同颗粒度数据之间的关系,圆圈代表数据。圈中的符号代表数据类别;类别符号含义如表2所示。C代表顾客要求变量;D代表产品属性要求变量;M代表制造类数据变量,其子类有零部件要求变量Part、工艺要求变量Tech和生产要求变量Prod;S代表营销要求变量;As代表售后使用数据变量;Sc代表供应链活动变量。图中每层内的连线表示数据间的关系;关系类型如表1所示。
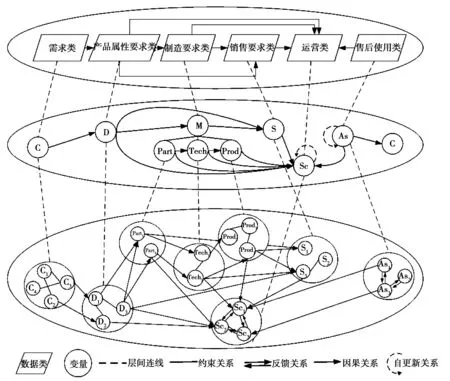
图2 基于网络图的产品大数据关系描述模型
图2所示的模型是一个三层网络结构。上层从宏观角度描述产品大数据间的关系。中层描述数据类变量集间的关系,由上层各数据类具体化而成。下层从微观角度全面描述各数据类变量间的关系,是对中层数据间关系的细化。

表2 数据类变量
上层网络中各数据类间的连线表示数据类间具有因果关系。需求类与产品属性要求类、产品属性要求类与制造要求类、制造要求类与销售要求类均呈因果关系。此外,产品属性要求类、制造要求类共同与销售要求类数据呈因果关系。产品属性要求类、制造要求类、销售要求类和售后使用类数据共同与运营类数据呈因果关系。
中层网络描述各数据变量集及其关系形成的数据关系网。关系网中体现的关系类型有质量屋中左墙数据与屋顶数据之间的因果关系、数据自身固有的层级关系和自更新关系。存在的因果关系有需求变量集C和产品属性要求变量集D间的关系、产品属性要求变量集D和制造要求变量集M间的关系。其中制造要求变量集的子变量集间也呈因果关系(零部件要求变量集Part和工艺要求变量集Tech,工艺要求变量集Tech和生产要求变量集Prod)。产品属性要求变量集D、制造要求变量集M共同与营销要求变量集S呈因果关系。产品属性要求变量集D、制造要求变量集M、营销要求变量集S和售后使用变量集As共同与供应链活动变量集Sc呈因果关系。售后使用变量集As和新需求变量集C也呈因果关系。
中层网络中的层级关系有制造要求变量集M及其三个子类变量集(零部件要求变量集Part、工艺要求变量集Tech、生产要求变量集Prod)。中层网络中的自更新关系有售后使用变量集As对自身的更新,供应链活动变量Sc对自身的更新。
下层网络描述各数据变量及其关系形成的数据关系网,关系网中体现的关系类型有质量屋中同一数据类变量之间的约束关系、左墙数据和屋顶数据之间的因果关系、数据自身固有的反馈关系。同一数据类变量之间的约束关系体现在每个数据变量集中的变量间相互影响。左墙数据和屋顶数据之间的因果关系同中层数据网络所体现的一致。存在反馈关系的有各供应链活动变量Sc和售后使用变量集As。
图2所示的描述模型具有以下三方面特点:
(1)该模型通过网络结构可以直观清晰地描述数据类型、其间关系和关系强度。网络结构中的节点表示数据类型,数据节点之间不同类型的连接反映各数据类之间的关系、各数据类形成的网络之间的关系,边的不同连接强度反映各数据类之间、各数据类网络之间的相互影响程度。
(2)将上节所述的两大类数据关系融入该模型,能从全局出发,体现数据之间的相互作用。两类关系互不排斥,相互补充。
(3)由于网络关系可以转换为矩阵形式,该描述模型易于用矩阵表达。矩阵的行和列均由变量节点组成。所形成的矩阵中,每个位置的元素都表示特定位置两个变量的关系强度。例如,由图2下层网络图生成的矩阵中,变量D2与变量D3因在图中不相连,故变量D2所在行与变量D3所在列相交位置的值为0。变量D3与变量Part2相连,则两个变量节点相交处的值为行变量节点对列变量节点的关系强度。图2所示模型的矩阵形式可以方便描述因产品大数据节点过多导致的复杂网络结构[17]。此外,多数大数据分析方法在处理数据时需将数据转换为矩阵形式,因此使用矩阵表示网络关系将增加图2所示模型的分析效率。
总之,基于网络图的产品大数据关系描述模型能将面向数据关系的扩展QFD识别出的产品大数据间关系进行网络化可视化构建,得到一个直观描述产品大数据间关系的模型。无形的数据可以通过该描述模型有形化,无序的数据可以通过该描述模型有序化。借助矩阵形式,运用该模型可以发现数据之间的关系模式。
4 基于大数据关系描述模型的产品大数据分析模型
基于大数据关系描述模型的产品大数据分析模型是一个数据分析的过程模型,过程步骤如下。
(1)利用面向数据关系的扩展QFD 识别产品大数据及各类关系。
(2)将面向数据关系的扩展QFD识别得到的产品大数据间关系以网络图形式表现出来。数据类变量为节点,关系为连接节点的边,形成基于产品大数据关系的描述模型。
(3)利用多种大数据分析方法对上一步构建的描述模型进行分析处理,得出各关系间相互作用程度,并分析数据间的联动反应。例如,多源数据类包含大量异构数据,由数据类抽象为数据变量的过程前需使用数据融合的方法预处理。对数据类进行变量提取时,需根据数据的本质特性、应用特性和表现特性等采取不同的方法。如对文本数据进行自然语言处理后使用有向主题建模可获取特征,或利用聚类方法发现数据相似性聚集所体现的特征等。获得变量集后,可以使用关联规则学习的方法识别变量间的关系。在利用各种关系构建出网络图后,可利用网络分析等方法对数据变量网进行分析。
该模型具有三方面功能。第一,基于数据变量间相互作用程度,可识别出如图3所示依据数据分析目标所得的数据之间的关键路径。关键路径是根据数据分析目标得出的一条从初始变化数据到目标数据之间的一条特殊路径[18]。关键路径可以识别出为达到分析目标所涉及的重要数据,从而达到从海量数据中识别关键数据的目的,并有助于明确数据之间相互作用的机理。第二,可以实现数据连动反应的动态分析。这种连动反应主要体现在数据变化所引起的关系变化和关系网络结构变化两方面。首先,数据的更新变化将影响变量之间原有关系作用程度的变化。其次,关系的变化将引起网络结构的变化。对连动反应进行动态分析可获取信息流传递方向,从而识别市场的动向。第三,可以识别出新的数据和关系。若某数据的加入能改变数据关系网的结构,则该数据为新数据。新数据可用来监控市场中出现的新动向。随着新数据的出现,可获得数据关系网中存在但未被识别的连接,从而发现新的关系模式。关系模式可以通过矩阵运算发现。

图3 关键路径图
总之,基于大数据关系描述模型的产品大数据分析模型是一种综合运用多种大数据分析方法分析处理数据的过程模型。该模型根据数据自身的特性和数据变量间固有关系从已有的大数据分析方法中选取合适的方法进行分析处理,其目的在于利用已有的大数据分析方法对面向数据关系的扩展QFD识别出的关系进行量化分析,即得出数据变量之间的相互作用程度,进而分析数据之间的联动反应,通过多角度建模实现数据建模和算法技术的高效结合。
5 应用前景
基于扩展QFD和网络图的产品大数据分析方法是一种具有一般性的数据分析方法。一般性在于两方面。首先,该方法分析的产品大数据不限于实体商品的数据,亦可是服务数据。其次,在产品全生命周期中,只要获得不少于两类数据即可进行相应环节的建模分析。例如,利用制造要求类和运营类数据可以构建用于决策支持的智能制造模型,并利用大数据分析来优化生产性能和改进产品工艺[19]。因此,本文构建的方法既可用于有形产品,也可用于无形服务;可应用于数据类不少于两类的产品大数据分析。
应用本文提出的方法分析产品大数据的流程如上文所述:先识别数据类之间的关系和数据间的固有关系,再用网络图的方式对数据关系进行可视化,最后综合多种现有大数据分析方法实现多角度建模分析。通过上述流程和多角度建模可实现多种目标的产品大数据分析。目标包括对任意不少于两类的数据进行建模分析、从海量数据中识别关键数据、对数据进行联动关系分析和利用新数据发现新关系模式等。这些目标的组合可实现多种实际用途。例如可用于提高生产决策的准确率、提供智能制造的决策支持、进行需求预测、识别各类客户以实现多角度精准营销,以及实现整个产业链的动态战略规划。总之,本文构建的产品大数据分析方法可以实现多种分析目标和多种实际用途。
6 结论
本文针对现有大数据分析方法只侧重算法性能优化以及现有大数据分析方法难以综合分析网络形态数据之间连动关系的问题,提出了一个基于扩展QFD和网络图的产品大数据分析方法。该方法可识别出产品大数据之间的固有关系,并以网络图的方式表示数据关系,最终用于多目标分析。多目标分析包括从海量数据中获取关键数据、识别产品在市场中的动向等,故使用基于扩展QFD和网络图的产品大数据分析方法将对决策者有重要意义。
[1]化柏林,李广建.大数据环境下的多源融合型竞争情报研究[J].情报理论与实践,2015,38(4):1-5.
[2]MANYIKA J,CHUI M,BROWN B,et al.Big data:the next frontier for innovation,comptetition,and productivity[J].Analytics,2011:27-31.
[3]ZHANG F,LIU M,GUI F,et al.A distributed frequent itemset mining algorithm using spark for big data analytics[J].Cluster computing,2015,18(4):1493-1501.
[4]WU X,FAN W,PENG J,et al.Iterative sampling based frequent itemset mining for big data[J].International journal of machine learning and cybernetics,2015,1(6):1-8.
[5]SARMA T H,VISWANATH P,REDDY B E.A fast approximate kernel k-means clustering method for large data sets[C]// Recent Advances in Intelligent Computational Systems.IEEE,2011:545-550.
[6]TSANG I W,KWOK J T,CHEUNG P M.Core vector machines:fast SVM training on very large data sets[J].Journal of machine learning research,2005,6(1):363-392.
[7]LEE L H,WAN C H,RAJKUMAR R,et al.An enhanced support vector machine classification framework by using euclidean distance function for text document categorization[J].Applied intelligence,2012,37(1):80-99.
[8]WAN C H,LEE L H,RAJKUMAR R,et al.A hybrid text classification approach with low dependency on parameter by integrating K-nearest neighbor and support vector machine[J].Expert systems with applications,2012,39(15):11880-11888.
[9]JIANG S,PANG G,WU M,et al.An Improved k-Nearest Neighbor Algorithm for Text Categorization[C]// Advances in Computation of Oriental Languages—Proceedings of the,International Conference on Computer Processing of Oriental Languages.2003:1503-1509.
[10]SUDHAHAR S,VELTRI G A,CRISTIANINI N.Automated analysis of the US presidential elections using big data and network analysis[J].Big data & society,2015,2(1):1-28.
[11]HE Y,YU F R,ZHAO N,et al.Big data analytics in mobile cellular networks[J].IEEE access 2017,4:1985-1996.
[12]ALAMSYAH A,PERANGINANGIN Y.Effective knowledge management using big data and social network analysis[J]Learn organ manage bus int J.2013,1(1):17-26.
[13]LOBB R,CAROTHERS B J,LOFTERS A K.Using organizational network analysis to plan cancer screening programs for vulnerable populations.[J].American journal of public health,2014,104(2):358-364.
[14]CHOPADE P,ZHAN J,BIKDASH M.Node attributes and edge structure for large-scale big data network analytics and community detection[C]// IEEE International Symposium on Technologies for Homeland Security.IEEE,2015:1-8.
[15]赤尾洋二,水野滋.Quality function deployment:integrating customer requirements into product design[M].Productivity Press,1990.
[16]MEHRJERDI Y Z.Applications and extensions of quality function deployment[J].Assembly automation,2010,30(4):388-403.
[17]王国顺,曹峰彬.基于产业网络的企业BP评价模型——以湖南现代制造业为例[J].中南大学学报(社会科学版),2009,15(6):771-775.
[18]曹霞,张路蓬.基于扎根理论的合作创新网络可拓机理与优化路径[J].中国科技论坛,2015(9):24-30.
[19]NI M,XU X,DENG S.Extended QFD and data-mining-based methods for supplier selection in mass customization[J].International journal of computer integrated manufacturing,2007,20(2):280-291.
ABigDataAnalyticMethodBasedonAnExtendedQFDandWebGraphandItsApplication
Tang Zhongjun,Cui Junfu,Yu Haibo
(School of Economics and Management,Beijing University of Technology, Research Base of Beijing Modern Manufacturing Development,Beijing 100124,China)
Extant big data analytic methods focus on boosting performance of algorithm but ignore to take inherent relationships of data into consideration.And the methods are lack of ability to process web-based data thoroughly.This paper has proposed a big data analytic method based on extended QFD and web graph.The method consists of①an data relationship-oriented extended QFD that can identify relationships of big product data categories,②a description model of product big data’s categories that is constructed to web form to display the relationships of data categories,and③a description model-based big data analytic model which is aimed to recognize patterns in a multi-dimensional way.The proposed method can display the data with complex shape and multiple connections in an explicit way via web form and then explore the big product data by making use of various suitable big data analytic methods for identifying the key data among huge data and finding new data and its relationship.The method can make it possible to combine the algorithm and data modeling more effectively.
Big data analytics;Quality function deployment;Web graph;Big product data
国家自然科学基金面上项目“基于类比推理的短生命周期无形体验品需求预测”(71672004)。
2017-04-13
唐中君(1969-),男,湖南人,北京工业大学经济与管理学院博士生导师;研究方向:需求预测、运营与营销。
F272.3
A
(责任编辑 刘传忠)
猜你喜欢
小学生学习指导(高年级)(2021年4期)2021-04-29
科学与信息化(2021年8期)2021-03-31
河北理科教学研究(2020年2期)2020-09-11
活力(2019年21期)2019-04-01
Coco薇(2015年1期)2015-08-13
快乐作文·中年级(2015年3期)2015-03-26
新高考·高二数学(2014年7期)2014-09-18
科学之友(2010年17期)2010-08-23
玩具(2009年10期)2009-11-04
个人电脑(2009年9期)2009-09-14
