
基于聚类分析的农机化效率区划研究
2017-12-16 08:05:13吐尔逊买买提谢建华
农机化研究 2017年8期
吐尔逊·买买提,谢建华
(新疆农业大学 机械交通学院,乌鲁木齐 830052)
基于聚类分析的农机化效率区划研究
吐尔逊·买买提,谢建华
(新疆农业大学 机械交通学院,乌鲁木齐 830052)
针对农业机械化效率存在的差异,提出应用k均值聚类算法对新疆各地州按农机化效率进行区划,并以各地州2014年面板数据为研究对象进行区划。对区划结果应用误差平方和(Sum of Squares for Error) 、轮廊系数(Silhouette Coefficient)方法进行检验和定量分析,同时对结果根据地区农机化发展现状进行定性分析。结果表明:新疆各地州按其农机化效率分为4组(k=4):第1组昌吉、塔城、阿勒泰、巴州,第2组克拉玛依、博州,第3组哈密、伊犁、阿克苏、喀什,第4组乌鲁木齐、吐鲁番、克州、和田;组间差异最大,组内差异最小。该研究可为分类指导各地区农机化发展提供参考。
农机化;效率;聚类;区划
0 引言
省域不同地区或生产单元在农业机械化发展中呈现出不同的发展趋势,其农机化生产的效率表现出全局分异、局部聚集的特征[1]。依据多个区域农业机械化效率的差异,对其进行合理的区划,有利于明确不同地区农业机械化的发展目标和主要任务[2-3]。目前,农业区划方面的研究包括水文[4]、生态[5]、自然灾害[6]、地形[7]、农业机械化[8]、种植业、牧业、渔业区划,以及综合农业区划等[9]。
分析已有的文献发现:目前,针对新疆的农业区划,已有综合自然区划、综合农业区划、农业气候与资源区划、农业地貌区划及种植业区划[10]等方面的成果;但针对新疆各地州农业机械化效率的差异方面,尚无发现有关文献。准确定位区域农业机械化效率及其水平所属的类,可以更直接地掌握各区域农业机械化发展的现状,从而为不同地区农业机械化和农业现代化的发展制定合理的战略和目标。因此,对区域农业机械化发展水平进行科学的区划,具有重要的理论意义和实践意义。农业机械化生产和管理中传统的区域划分方式一般按地理经纬度出发,缺乏对研究对象的针对性。新疆经纬度跨度较大,南北疆各地区在农业机械化以及其效率水平差异悬殊,对各地区农机化效率进行更为科学、有效的区划将有利于充分挖掘农业机械化发展潜力,为农业机械化管理和政策制定提供参考。本文采用聚类方法对各地州进行区划分析。
1 指标体系及数据来源
聚类效果能否反映研究对象的分布趋势取决于指标和数据的选择及聚类算法。地区农业机械化效率和农机化投入指标及其数量有关,因此参照文献[11-12]及根据新疆农机化发展现状,建立以农机总动力Z1、农机拥有量Z2(人/千人)、千瓦农机作业收入Z3(元/kW)、播面顷均农机动力Z4(kW/hm2)、农机人员受教育程度Z5(%)、农机教育培训程度Z6(%)和农业劳均播种Z7(hm2/人)组成的农机化效率指标体系。以新疆2014年统计年鉴、新疆2014年农机年报作为数据源关系数据模型,如表1所示。
表1 2014年新疆各地州农业机械化投入指标值
Table 1 Indicator value of agricultural mechanization investment in Xinjiang Prefecture in 2014
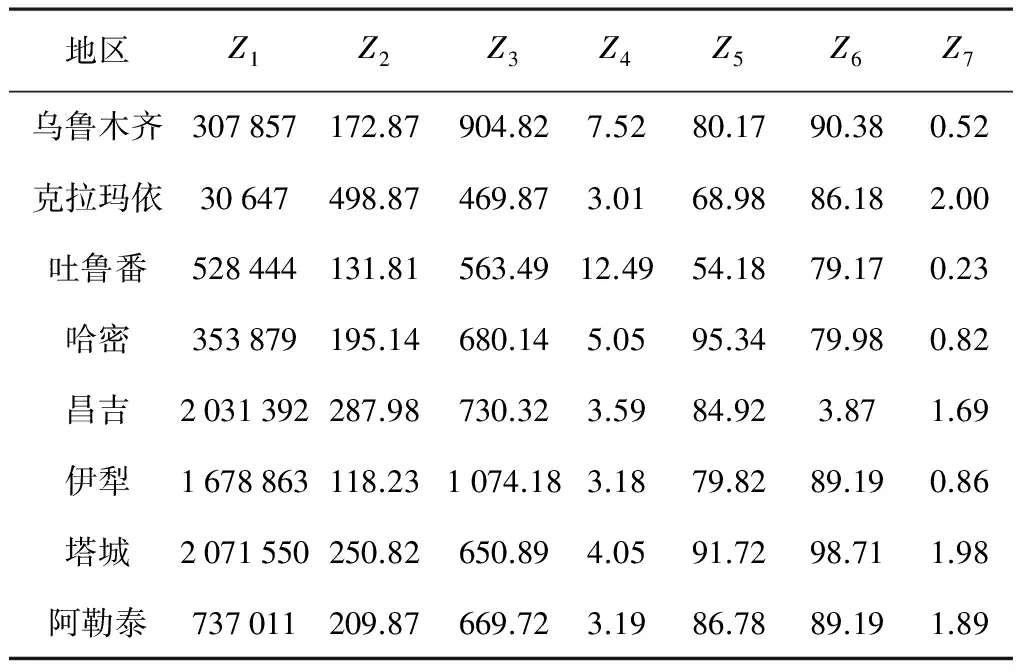
地区Z1Z2Z3Z4Z5Z6Z7乌鲁木齐307857172.87904.827.5280.1790.380.52克拉玛依30647498.87469.873.0168.9886.182.00吐鲁番528444131.81563.4912.4954.1879.170.23哈密353879195.14680.145.0595.3479.980.82昌吉2031392287.98730.323.5984.923.871.69伊犁1678863118.231074.183.1879.8289.190.86塔城2071550250.82650.894.0591.7298.711.98阿勒泰737011209.87669.723.1986.7889.191.89
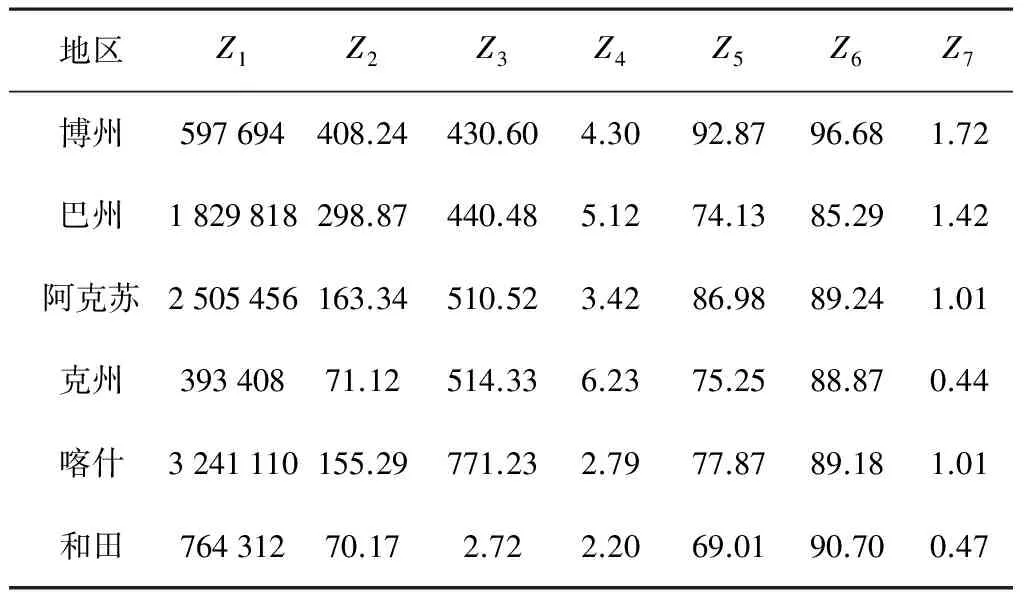
续表1
2 研究方法
2.1 聚类算法
聚类分析是数据挖掘中的重要的方法,目前常用的聚类方法有划分聚类、层次聚类及密度聚类等。应用聚类分析时,应根据研究对象的特征(如取值范围、分布等)选取不同的算法。本文根据研究对象的数据量少、波动不大等特征,结合常用的聚类算法的特点,选取k-means聚类方法对数据进行分析。K-means算法原理见文献[13]。
2.2 聚类检验
聚类分析中评估算法在聚类对象中的分簇性能是检验聚类效果的有效方法。第1种聚类检验方法是判断误差平方和(Sum of Square Error,SSE)。本文中计算k=n(n=3~8)时的SSE,即各簇内的每个点到其所在簇质心的距离之平方之和,按此方法计算所有簇SSE的平均,从而获得k=n时总的SSE。聚类中SSE越小,可判定簇中元素越相似,聚类质量越高。
第2种方法是轮廊系数(Silhouette Coefficient)法,是评估簇的凝聚度和分离度的参数。簇的评估中这两个指标用来判断近似的、确定正确的或自然的簇个数,其计算方法见文献[14]。对于聚类而言,轮廊系数值在-1~1之间变化,负值表示点到簇内点的平均距离a(i)大于颠倒其他簇的最小平均距离b(i)。分析可知:当a(i)趋向于0、轮廊系数趋向于1时,说明同一簇内元素的凝聚度和不同簇的分离度达到理想状态。
3 农业机械化效率区划
聚类分析中,聚类对象有时可能含一些异常点,或其数据格式不符合聚类算法要求,因此需要通过数据清洗、离群点检测等方法对其进行预处理。另外,为了避免因为各变量的量纲不同而引起聚类的性能下降,需要对数据进行标准化。
本文通过最大、最小化方法进行标准化。根据新疆地州数量以及聚类算法自身的规则,设定最小簇数和最大簇数分别3和8,即k=3~8。为了降低出现局部最优的概率,最大迭代次数设定为15并MatLab2014a中进行聚类。聚类结果如表2所示。
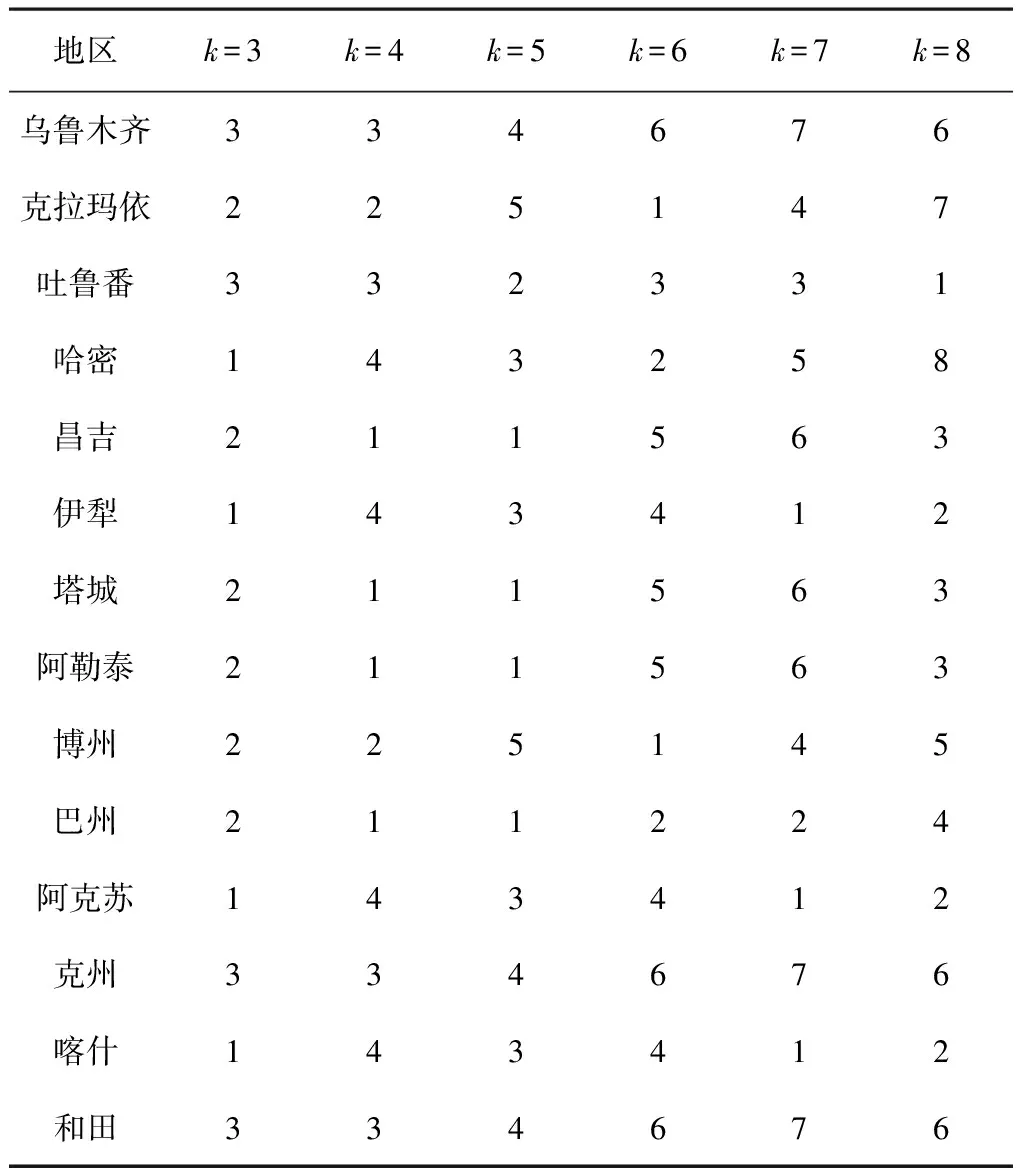
表2 新疆各地区2014年农业机械化区域聚类(k=3~8)
为了直观地观察各簇的元素的分布情况,对聚类结果进行可视化(Visualization)。因原始为多维数据,应用文献[15]中的方法对标准化后的数据进行降维,并获取2维的指标数据。可视化后结果如图1所示。


图1 k=3~8时的聚类结果
图1中,x轴和y轴分别为将原地区农机化效率指标应用Factor analysis算法降维到2维后的结果。由于有些点高度相似,因而图中存在数据点合并显示的情形。
应用2.1簇检验方法检验K-means算法的聚类效果,针对本文的研究对象而言,轮廊系数越小就说明分配到一个簇内的地州农业机械化效率指标越接近、越相似,簇内地区在农业机械化效率方面有较高的相似度。通过计算可以获得SSE和轮廊系数,如表3所示。
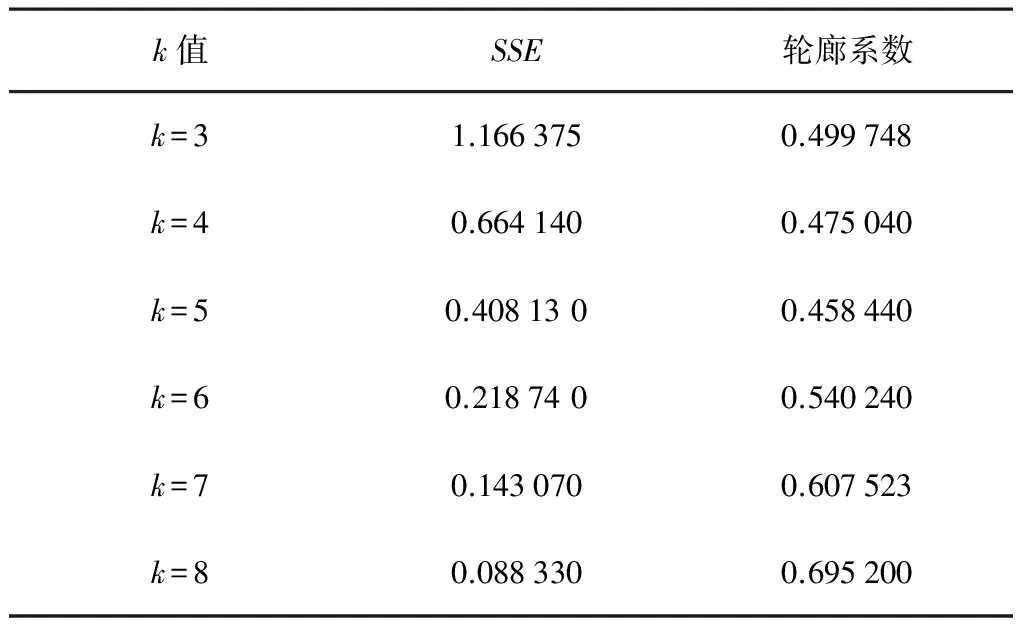
表3 SSE和轮廊系数
表3数据表示:SSE随着簇的个数增加,逐步变小,而轮廊系数先下降后增加。
图2和图3分别为SSE和轮廊系数分布曲线。由图2、图3可知:当k=4时,轮廊系数取最小值,且其曲线有明显的拐点,SSE也有一个下降趋势放缓过程。即通过评估度量方法确定的结果是:当k=4时获得的4簇中,簇内对象高度相似,而簇间不相似。通常通过SSE和轮廊曲线评价聚类效果或簇的个数时,可以通过SSE和轮廊线的拐点、尖峰、下降点或上升点找到簇的自然个数,这种方法通常在数据量较少、并簇中无复杂嵌套簇时比较实用。由于k=7、k=8时轮廊系数较高,不考虑这种分组情况下。各簇相对应的各地州分组结果如表4所示。
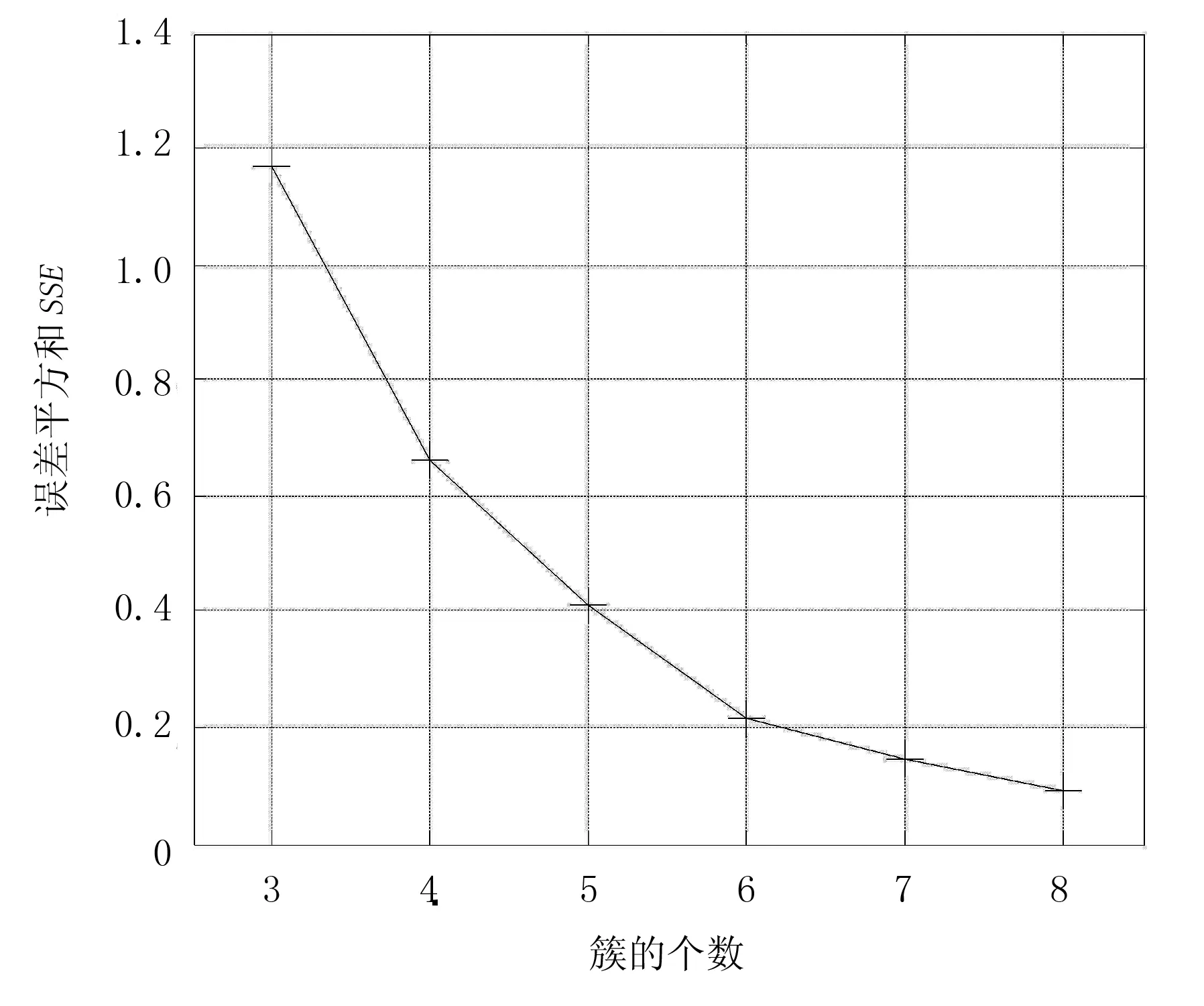
图2 误差平方和分布

图3 轮廊系数分布

组别k=3k=4k=5k=6第1组克拉玛依、昌吉、塔城阿勒泰、博州、巴州昌吉、塔城、阿勒泰、巴州克拉玛依博州吐鲁番第2组乌鲁木齐、吐鲁番克州、和田克拉玛依、博州乌鲁木齐克州、和田伊犁、阿克苏喀什第3组哈密、伊犁阿克苏、喀什哈密、伊犁阿克苏、喀什昌吉、塔城阿勒泰、巴州乌鲁木齐克州、和田第4组乌鲁木齐、吐鲁番克州、和田哈密、伊犁、阿克苏、喀什哈密、巴州

续表4
由于各次聚类分析中使用了统一的数据标准化、降维方法和聚类算法,所以聚类后的以上4种分类保持了较好的一致性。也就是说,在农业机械化及效率影响因素指标值方面,具有接近或相似特征的地区始终分到同一组。
例如:①克拉玛依和博州始终分到同一个组。②昌吉、塔城、阿勒泰和博州分别在k=3、4、6时分配到相同的组。其中,昌吉、塔城、阿勒泰始终分配到一个组。③乌鲁木齐和克州在四种聚类中分配到同一组。④作为相邻的地区,阿克苏和喀什这4种聚类中始终呈现出较高的相似性,即k=3~8时被分配到相同的组。从地区农业发展的基本面来分析可知:上述各组之间相似性较弱,而组内在各地区相关指标之间距离较小。
不同之处在于:①k=6时,昌吉、塔城、阿勒泰构成一组,巴州和哈密构成一组;而k=5时,这两组被分配到同一组。②吐鲁番始终被分配到单独的一组。③k=5时的第3组成员昌吉、塔城、阿勒泰、巴州和第4组成员哈密、伊犁、阿克苏和喀什在k=4时分别分配到第1组和第3组,这说明这两组地区的农业机械化效率指标方面有较高的相似性。从当前的地区各项发展现状分析,哈密、伊犁、阿克苏和喀什分配到同一组较合适,组内相似性也较高。另外,从近年来各地区的农业机械化发展情况来看,随着国家对农业的投入的加大,尤其是随着对南疆扶持力度的加大,克州、和田等南疆地区农业机械化方面的投入也较大,这些地区和吐鲁番和乌鲁木齐也具有较好的凝聚度。从轮廊系数的计算可知:k=4时,各组之间的簇内差异较小,簇间差异较大。从技术角度分析,这正好达到聚类的基本宗旨。
综合以上的情况,加上SSE和轮廊系数的分析,本研究倾向于k=4的聚类方案。即新疆各地州农业机械化效率指标区划时,从技术角度和地区发展水平出发,分4个区是比较合理。第1组:昌吉、塔城、阿勒泰、巴州;第2组:克拉玛依、博州;第3组:哈密、伊犁、阿克苏、喀什;第4组:乌鲁木齐、吐鲁番、克州、和田。
4 农机化效率聚类结果与讨论
1)区划与地理位置的相邻性特征不强,传统划分方式和本文区划结果相差较大。例如:第1组南北纬度跨度较大,即有传统划分上北疆地区,也有南疆地区;第3组地区分布于新疆东部哈密到西部喀什;第4组也说明此种情况,打破了传统南北疆、东疆等区划的局限性。
2)新的地域分组特征明显,组内差异小,组间差异大。从最近几年农业机械化发展情况来分析,每组都有较强的特征。例如,第1组中各地区属于农业生产发展较快的地区,有较好的土地资源优势;而各组之间在农业生产投入、农业生产资源、社会经济水平方面差异较大。
3)获取的分组结果是从技术和综合等纬度进行分析的结果。
本研究结果基于聚类14个地区的影响农业机械化效率影响因素指标值、评估k值和结合地区社会经济发展水平分析得到,有较大的可信度。
5 结论
1)以新疆各地区农业机械化效率投入指标作为影响农业机械化效率的主要因素, 以2014年新疆各地区指标值作为源数据,应用K-means聚类对14地区进行聚类,并应用基于技术和综合的方法进行分析,结果表明:k=4时,组间农业机械化效率差异大,组内差异小,所分的组能够反映新疆各地区农业机械化效率实际情况。
2)和传统的地区分组方法相比,本研究主要聚焦于区域农业机械化效率的区划,更具有针对性,且强调了影响农业机械化效率的因素对农业机械化效率的重要性。通过合理的分组,把相似性较高的地区放在第1组,提高组内相似性。
[1] 张建升.省域全要素生产率地区差异的动态演进[J]. 经济经纬,2011,28(6):37-41.
[2] 李新广,郭文杰. 节约型农机化生产体系的研究[J]. 农机化研究,2009,31(9):241-243.
[3] 张宗毅,曹光乔. "十五"期间中国农机化效率及其地区差异[J].农业工程学报,2008,24(7):284-289.
[4] 余世勇,王佳.中国农业机械化效率分析[J].江苏农业科学,2013,41(12):420-422.
[5] Yang J,Huang Z,Zhang X,et al. The Rapid Rise Of Cross-Regional Agricultural Mechanization Services In China[J].American Journal of Agricultural Economics,2013,95(5):1245-1251.
[6] 王珺鑫,杨学成.山东省粮食生产波动及主要投入要素效应的实证分析—基于17地市的面板数据[J].中国农业资源与区划,2015,36(3):18-23.
[7] 刘玉海,武鹏.转型时期中国农业全要素耕地利用效率及其影响因素分析[J].金融研究,2011(7):114-127.
[8] 钱玉皓,聂艳,罗毅.基于能值分析的县域耕地利用效益比较研究[J].湖北大学学报:自然科学版,2012,34(4):387-392.
[9] Kopp R J. The measurement of productive efficiency:reconsideration[J].the Quarterly Journal of Economics,1981,96(3):477-503.
[10] 邓依萍,刘涛.新疆节水农业区划及分区对策研究[J].节水灌溉,2008(10):8-11.
[11] 李卫,薛彩霞,朱瑞祥,等. 基于前沿面理论的中国农业机械生产配置效率分析[J].农业工程学报,2012,28(3):38-43.
[12] 李卫.区域格局划分与农业机械化发展不平衡定量研究[D].杨凌:西北农林科技大学,2015.
[13] 周爱武,于亚飞. K-Means聚类算法的研究[J]. 计算机技术与发展,2011,21(2):62-65.
[14] 朱连江,马炳先,赵学泉. 基于轮廓系数的聚类有效性分析[J]. 计算机应用,2010(S2):139-141.
[15] Maaten L J P V D,Postma E O,Herik H J V D. Dimensionality Reduction: A Comparative Review[J].Journal of Machine Learning Research,2007,10(1):2579-2605.
Regionalization of Agricultural Mechanization's Efficiency Base on Cluster Analysis
Tursun Mamat, Xie Jianhua
The regionalization approach was proposed based on k-means clustering algorithm. On the clustering experiments, the 14 regions was zoned 3, 4, 5, 6,7and 8 zone according to efficiency of agricultural mechanization of each region.The SSE (Sum of squares for error) and silhouette coefficient method was applying for validation the quality of zoning (clustering).On the same time the qualitative analysis for clustering result was applying on the basis of current situation of agricultural mechanization on each region in Xinjiang. The results show that, according to each region’s efficiency of agricultural mechanization in 2014, if the all regions in Xinjiang be zoned for 4 group(k=4), regions were in the same group(cluster)are more similar to each other than to those in other groups(cluster) ,meanwhile the better SSE and silhouette can be obtained as well. The first group included Changji, Tarbaghatay, Altay and Bazhou. The second group included Karmay, Bortala, The third group included Kumul, Yili, Ahsu and Kashghar. Urumqi, Turpan, Kezhou and Hotan were included in forth group. Our approach and results provide useful information for development of agricultural mechanization in management.
agricultural mechanization; efficiency; clustering; regionalization
2016-06-13
国家自然科学基金项目(51465057)
吐尔逊·买买提(1975-),男(维吾尔族),新疆阿克苏人,讲师,博士,(E-mail)tursun@xjau.edu.cn。
S23-01
A
1003-188X(2017)08-0027-05
猜你喜欢
农业科技通讯(2023年1期)2023-02-12 07:08:20
贵州农机化(2019年3期)2019-11-05 06:46:42
成都信息工程大学学报(2019年6期)2019-08-13 03:31:12
贵州农机化(2019年1期)2019-05-21 07:34:46
四川环境(2019年6期)2019-03-04 09:48:54
昌吉学院学报(2018年1期)2018-12-06 08:13:02
西南石油大学学报(社会科学版)(2018年5期)2018-11-08 10:55:44
贵州农机化(2018年2期)2018-08-28 07:47:20
新农业(2016年22期)2016-08-16 03:34:46
山东农机化(2015年6期)2015-01-03 08:09:47
