
基于ID3—SMOTE结合算法的社会群体性事件预警模型
2017-12-13 03:47:56石拓魏新蕾邵旭芬
中国传媒大学学报(自然科学版) 2017年6期
石拓,魏新蕾,邵旭芬
(1.中国传媒大学信息工程学院,北京 100024;2. 浙江省乐清中学,乐清325600)
基于ID3—SMOTE结合算法的社会群体性事件预警模型
石拓1,魏新蕾1,邵旭芬2
(1.中国传媒大学信息工程学院,北京 100024;2. 浙江省乐清中学,乐清325600)
当前国内群体性事件表现出组织化、复杂化、政治化、暴力化的特征,严重影响了社会的和谐稳定。通过科学手段预测群体性事件是预防其发生的有效途径。在以往的群体性事件预警方法中,主要都是通过定性分析或简单的定量分析方法实现预测,相对缺乏科学可靠的数据事实作为支撑。文中笔者通过内部单位获取到近年来发生在我国境内的群体性事件的相关数据,创新性地将机器学习的思路引入群体性事件预警领域,颠覆了针对群体性事件的传统分析方法。从社会科学和自然科学的双重视角出发,我们利用机器学习技术科学预测群体性事件。这对政府在处置群体性事件过程中科学决策、有效预防和快速反应具有重要指导意义。
群体性事件;分类;决策树;ID3;SMOTE
1 引言
近年来,我国境内群体性事件时有发生,事件发生数量和参与人数都在不断攀升,且一旦事发,事件规模迅速扩大。如去年发生的泛亚事件、e租宝事件都引发了大规模涉事群体的上访请愿。类似事件涉及的人员数量较多,潜在的危害性也大大加强。稍不留意就可能造成社会治安不稳定、引发公共安全事件、发生违法犯罪行为、造成严重后果和损失。如今随着改革的不断深化、经济不断增长,各类社会矛盾更是日益凸显且不断加剧。为此,建立切实可行的群体性事件预警机制,运用现代化科技手段,对该类事件及时准确地预测、预判、预报,尽快尽早地做好预防和处置工作十分必要。当今时代,大数据技术方兴未艾,尤其是机器学习技术高速发展,为各个领域的科学预测和先期预警带来了新的契机。机器学习通过利用计算机模拟实现人类的学习行为,不断获取新的知识技能,并不断组织知识结构,实现了各行各业的“人工智能化”,尤其是针对互联网行业的发展起到巨大推动作用。然而,机器学习的科学能力在我国的公共安全领域却并没有得到充分应用,在群体性事件的预警领域更是寥寥无几,相关的文献也是十分罕见。笔者想通过此文将机器学习技术引入群体性事件分析,为后续类似研究开辟道路,提供方法和思路。
关于群体性事件预警机制研究的相关文献数量很多,但大多数文献都集中于研究群体性事件预警机制体制建设和相关指标构建领域。如余光辉等人撰写的《我国环境群体性事件预警指标体系及预警模型研究》[1]、吴竹撰写的《群体性事件预警机制研究》[2]等文章都是在分析社会系统稳定因素及社会评价指标体系的基础上,运用管理学定性、定量及定时等研究方法,对群体性事件的预警指标体系及群体性事件预警预测管理系统模式展开讨论,并提供群体性事件预警预测管理体系运行影响因素分析和执行效果评估方法。显有的几篇如胡诗妍撰写的《群体性事件风险定量预测》[3]从数据的角度出发,利用数据的统计分析方法,结合应用德尔菲法(Delphi)、层次分析法(AHP)、经验统计分析等定量化分析方法,提出了一些关于群体性事件风险的定量化评估方法。辛越等人撰写的《基于灰色分析的群体性事件情报预警》[4]利用灰色预测理论提出了一种基于灰色理论的群体性事件分析模型构想。
总体来说,关于群体性事件预警分析的研究大多聚焦于社会科学层面的理论研究,而针对基于机器学习技术的群体性事件分析和预警的研究难觅踪影,甚至利用大数据相关分析技术的群体性事件预警文献也是十分罕见。可见,目前将机器学习技术引入群体性事件分析预测还是相对空缺的,缺乏比较成熟的方法和科学模型及实践尝试。
2 基于ID3的群体性事件预警模型构建
2.1 数据准备
本文中所用数据是内部单位提供的近年来发生在我国境内的部分群体性事件,数据主要包含2000-2013年的比较有代表性的事件。数据包含群体性事件发生的时间、区域(省份)、事件持续时间、社会关系定位、参与主体、诉求目的、事件表现形式、事件规模、危害程度、媒体影响共10个属性特征。
为建立科学的数学模型对群体性事件进行科学预测,本文首先对上述共971条数据进行清洗:
1、解析文本文件:由于该数据的多数属性特征是以文本形式呈现的,只有时间相关属性是通过数字符号形式展现的,为了实现后续模型计算,首先利用Python编程对文本文件进行了解析,将每条样本数据的各项特征用向量的形式描述。通过筛选过滤,最终选择省份、月份、社会关系、参与主体、述求目的、事件规模、表现形式作为群体性事件的特征。
2、数据处理:笔者根据数据整体情况,将相关信息缺失较为严重的60条数据进行删除,由于所占比例较小,不会对整体数据分析结果产生较大影响;又对个别样本的个别缺失特征取值进行了插值,以满足后续分类模型要求。
3、数据特征划分:该类数据中的几个特征需要预先标注分类等级,便于后续挖掘数据关联性和类别预测。我们把地区、月份、社会关系、参与主体、诉求目的、事件规模、表现形式作为群体性事件的特征节点逐个进行划分和统计,结果如表1-表7 所示:
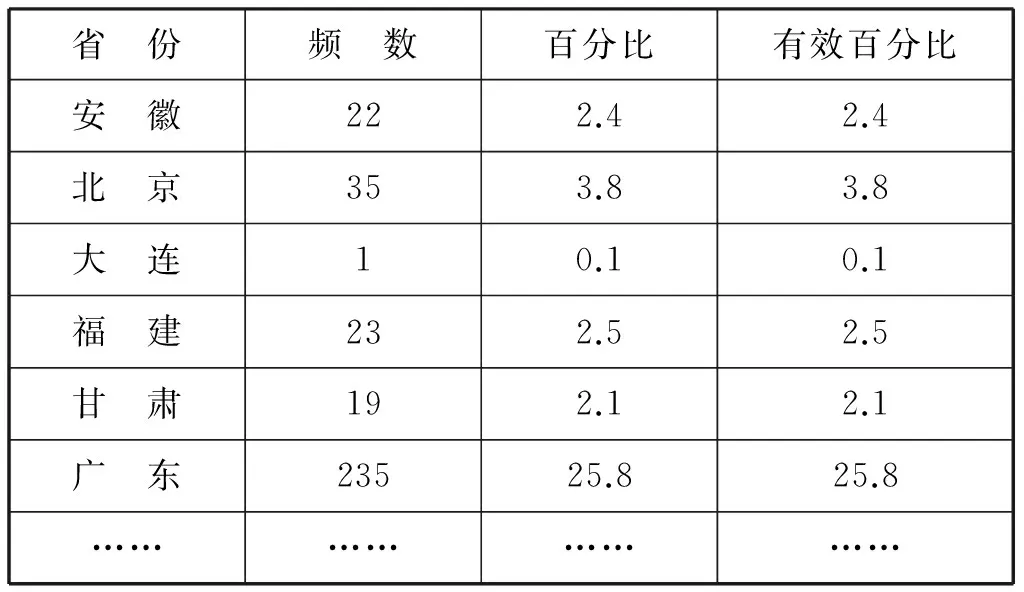
表1 群体性事件发生省份及频数统计
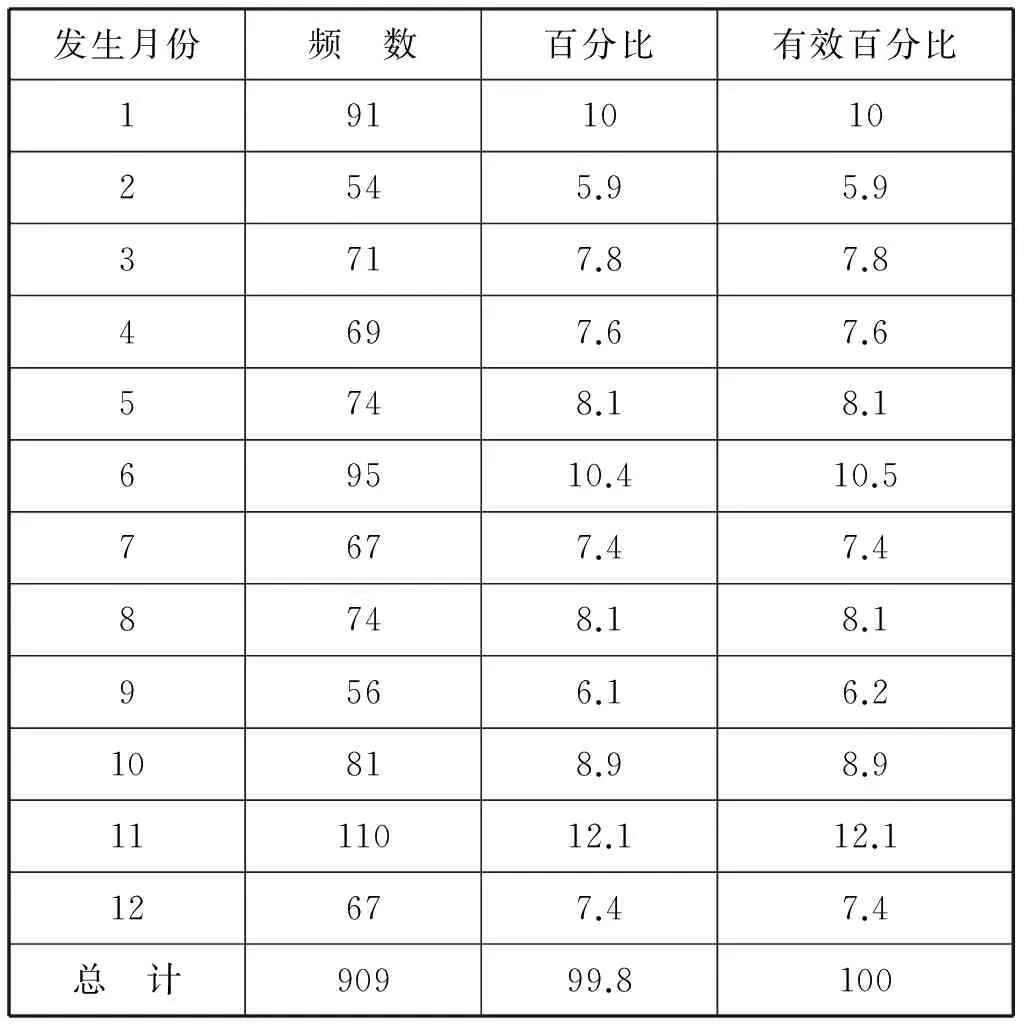
表2 群体性事件发生月份及频数统计
此外,根据矛盾冲突本文描述将冲突焦点类型进行了归类,主要划分为:政府类、社会类型冲突(涉及征地、拆迁、国企改制、司法、乱收费、环境、就业等方面矛盾和冲突)、企事业机构与利益诉求方的冲突(涉及业主与物业、医患、教育、环境等方面的冲突和纠纷)、及除上述几类冲突之外的其他类型冲突焦点。具体如表3所示:
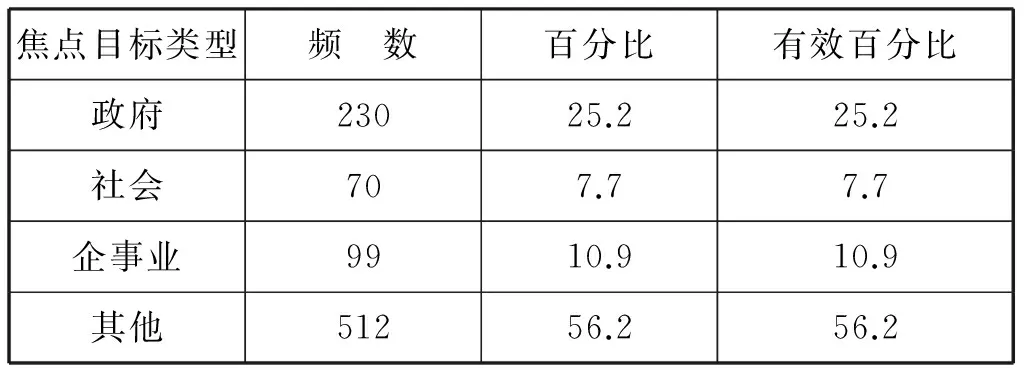
表3 焦点目标及频数统计
涉及的参与主体如表4所示:

表4 参与主体及频数统计
涉及群体性事件发生的诉求目的统计情况如表5所示:
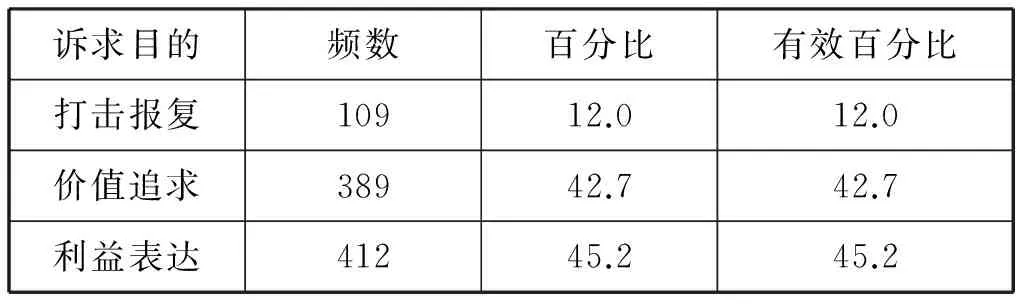
表5 诉求目的及频数统计
涉及群体性事件发生的事件规模根据参与人数进行划分,可分为4个等级,统计情况如表6所示:
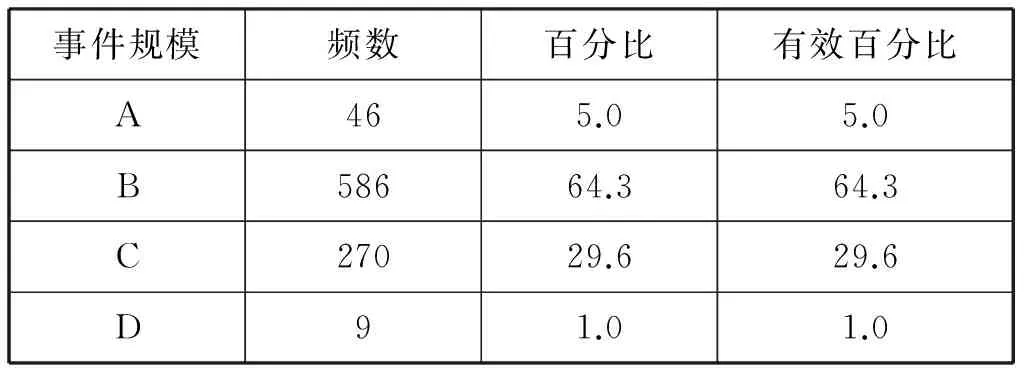
表6 事件规模及频数统计
根据发生群体事件的表现形式,可以将其划分为5类,具体统计情况如表7所示:
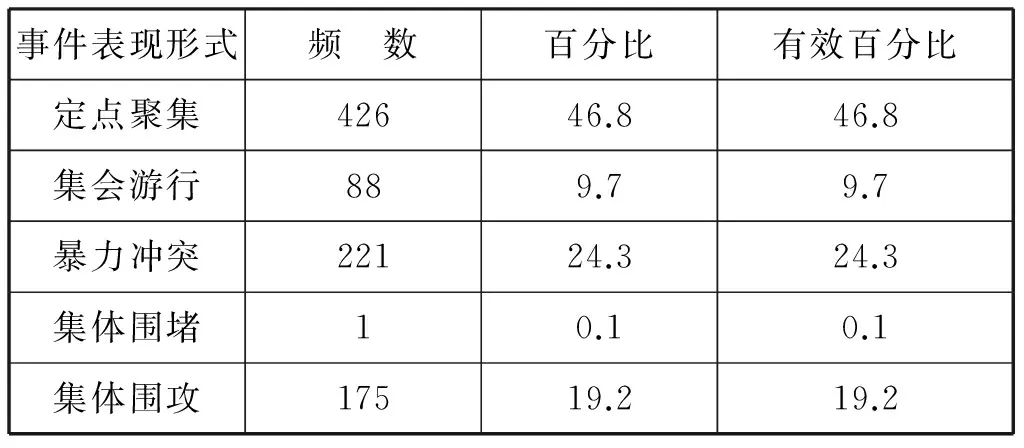
表7 事件表现形式及频数统计
笔者又根据关注的媒体级别对群体性事件数据中的媒体影响力进行了分级分类,分级划分情况如表8所示:
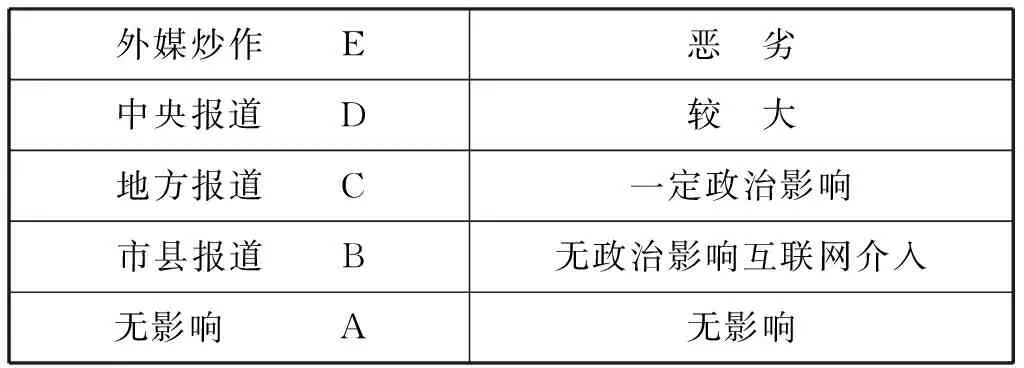
表8 关注媒体级别及影响
根据媒体影响力划分统计情况如表9所示:

表9 媒体影响力及频数统计
为了最终模型的标签类别划分,笔者根据中国国家标准《公共安全风险评估技术规范》[5]对数据中的安全等级和危害程度(伤亡人数、财产损失)进行划分,划分标准如表10所示:
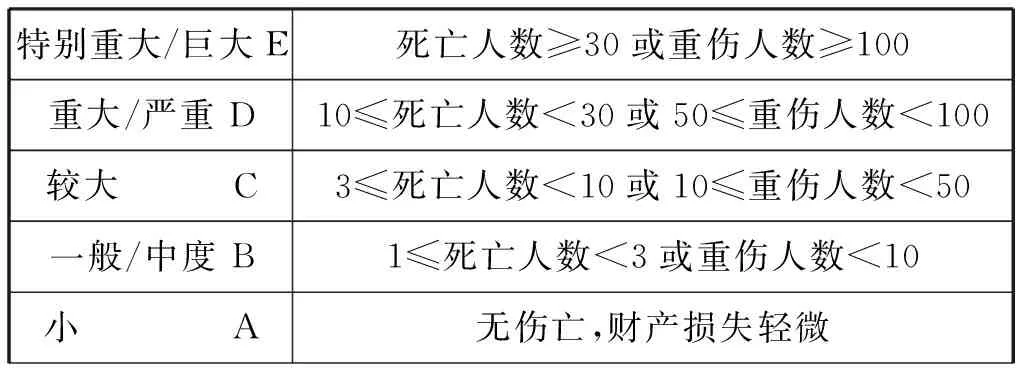
表10 公共安全等级和危害程度
根据上述划分标准得到具体统计和划分结果如表11所示:

表11 危害程度及频数统计
2.2 模型选择及实现
2.2.1 机器学习中常用的分类算法
在机器学习方法中,分类器有很多种,它们的优劣势不尽相同。而如何针对不同的场景选择不同的模型算法就需要深入把握各种分类模型的特点。
朴素贝叶斯在机器学习的分类器中相对比较简单,但这种方法需要满足各个特征尽量条件独立。如果条件独立性假设成立,相比于其他分类判别模型,它的收敛速度更快,所以这对与小型训练集效果比较优越。如果要得到简单快捷的执行效果,朴素贝叶斯方法比较适合。但朴素贝叶斯最大的不足之处在于如果特征之间不满足条件独立,甚至有很大的关联性的情况下,分类结果就很不理想,不能学习特征之间的相互作用。
逻辑回归是当前机器学习领域比较常用的分类方法,主要用于估计某种事物的可能性。就逻辑回归本质而言,它就是一种线性回归,其与线性回归的最大不同点就是它引入了一个sigmoid函数:

(1),
目的就是要将线性回归输出的很大范围的数,压缩到0和1之间。逻辑回归的有点就在于它是一种软分类,即得出的结果是一个概率值,用户可以根据概率阈值的调整控制分。这种分类方法可用于二值分类和多值分类,最常用的场景还是二值分类。相对效果也比较理想。
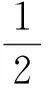
决策树是一个树结构,其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别[7]。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。决策树有它特殊的优势:一是它可以毫无压力地处理特征间非参数化的交互关系,无需再异常值或者数据是否线性可分得问题上做过多处理。二是处理速度快,缘于它的计算量相对较小,且容易转化成分类规则。一般只要沿着树根向下一直延伸到叶,沿途的分裂条件就能够唯一确定一条分类的谓词。 三是挖掘出的分类规则准确性高且便于理解,因为决策树可以清晰的显示哪些字段比较重要。
2.2.2 决策树分类方法的选择
本研究中,笔者根据群体性事件的数据情况,分析各类机器学习中常用的几种分类方法,出于数据集的数据类型普遍是非结构化、非参数化的形式,为了避免过多的数据处理和符号化,选择采用决策树方法进行危害性后果的等级评估。此外,本研究涉及的数据体量并不很大,选择决策树分类方法不会影响计算效率。再而决策树分类方法在不存在连续性的字段,也就不会出现预测不到结果的问题,而且该群体性事件的数据噪声较小(空值较少),更有利于决策树作用的发挥。
2.2.3 基于Python的ID3解决方案
为更好的划分数据集,笔者首先对危害程度进行信息熵计算,得到熵之后,就可以按照获取最大信息增益的方法开展分类。根据香农公式:
(2)
算得数据分类划分的信息熵H=1.3274812033811645。使用python通过利用决策树算法对群体性事件进行划分,部分程序代码如图1所示:
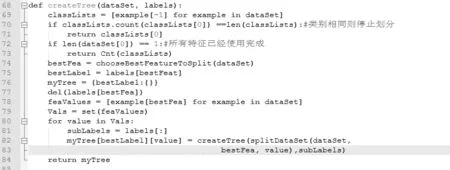
图1 基于ID3的代码实现(部分)
鉴于以上方式,可以始终保持基于最好的属性值对数据集进行划分,程序递归构建决策树,数据由上而下依次划分处理,直到满足决策树递归的终止条件,即遍历完所有划分数据集的属性,或者每个分支下的所有实例都具有相同的分类,则得到下一个叶子节点或者终止块。此时任何到达叶子节点的数据必然属于叶子节点的分类。
3 实验结果分析
本文对实验结果通过精确率(precision)、召回率(recall)及F1—score进行模型效果评价。所谓精确率(precision)是指分类器分类正确的正样本的个数占该分类器所有分类为正样本个数的比例。召回率(recall)是指分类器分类正确的正样本个数占所有的正样本个数的比例。F1-score为精确率与召回率的调和平均值,它的值更接近于Precision与Recall中较小的值。即:

(3)
具体实验结果如表12所示:
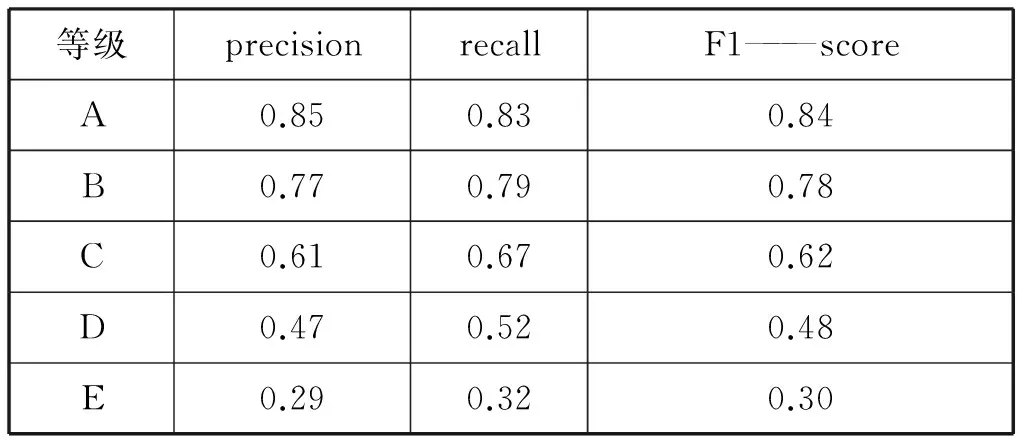
表12 原始数据实验结果
从上述表格实验结果可以看出,基于决策树分析法的群体性事件风险评估模型效果并不理想,针对风险等级A、B的预测效果比较好,无论从准确率还是召回率及F1评分来说效果都比较理想。但是针对C、D、E分级结果的预测效果明显较差,尤其是D和E分级的预测结果十分不理想,准确率过低,分本无法达到预期效果,满足预警目的。究其原因主要是因为D、E隶属于两级的数据量较少,尤其对比A级的样本数据量相差悬殊。故而导致了针对A级分类样本的拟合效果好,而针对D、E两级分类结果的拟合效果很差。下文笔者将根据这一问题对数据进行处理,以达到正负样本尽量均衡,预测效果尽量提升的目的。
4 基于SMOTE算法的样本失衡改进路径探究
4.1 SMOTE算法的引入
一般而言,为改善样本不均衡带来的预测效果不理想困境,可以从两个方面着手解决。一是从算法的角度出发,考虑不同误分类情况代价的差异性对算法进行优化,使得算法在不平衡数据下也能有较好的效果。二是主要从数据的角度出发,通过某种抽样策略使得样本数量尽量均衡。本研究中笔者主要采取第二种方案对数据进行抽样处理后实现预测效果的改善。
SMOTE全称是Synthetic Minority Oversampling Technique,即合成少数类过采样技术,它是Chalwa[8]在2002年提出的一种是基于随机过采样算法的一种改进方案,相对于随机过采样普遍采取简单重复构造数据样本的策略来增加少数类样本,极易产生模型过拟合的问题,使得训练模型学习到的信息过于集中而不够泛化。
SMOTE算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中,具体算法流程如下:
1.对于样本数量少的那一类中每一个样本,以欧氏距离为标准计算它到该本集中所有样本的距离,算得它的k近邻。
2.取过采样根据样倍数为n,再在上一步取到的k个近邻样本中选取n个样本。
3.对于每一个随机选出的近邻样本,再分别与原样本按照如下公式
xnew=xi+rand(0,1)×(xi-xij)
(4)
,其中(j=1,2,3...,n)
构建新的样本。xnew上式中,表示新构造的样本,xi表示原有样本,rand(0,1)表示区间(0,1)之间的一个随机数,而xij(j=1,2,3……n)则表示取到的k近邻中的n个样本。将这些新生成的样本添加到原来样本集中数据较少的那一类中就产生了新的均衡化的训练集。该方法中新生成样本数量可有控制合成倍数来完成。SMOTE方法通过过采样的方式有效避免了非均衡训练集中的过拟合及样本失衡问题,大大提高了分类器的泛化能力。
4.2 引入SMOTE算法的实验数据改进
本研究中为克服样本失衡现象,主要对C、D、E三类危害等级样本进行合成泛化,即主要针对上述两类数据进行SMOTE新数据合成后再进行基于决策树模型的分类模拟,最终的实验效果如表13所示:

表13 引入SMOTE合成数据后的实验结果
通过引入SMOTE样本均衡算法针对失衡样本集效果改善较为明显,但预测分类效果依然有继续完善的空间,也就表明SMOTE在本研究关于群体性预警模型改进效果较为显著。
5 结论
本文针对群体性事件的预警模型进行探讨,旨在通过机器学习方法实现对群体性事件危害性后果的预估评判。主要思路就是将事件危害等级作为分类标签,将包括发生地点、发生时间、媒体关注程度、涉及利益诉求等9类属性作为自变量输入,利用决策树的ID3算法通过熵值最大化原则划分数据类别,确定最终分类结果的思维过程。但通过ID3方法作完分类的预测效果并不理想,尤其是针对样本数量较少的C、D、E等级数据预测效果很差,无法满足模型预期效果。笔者就在数据失衡的问题下尝试引入SMOTE算法,实现针对数量较少类别的样本进行新样本合成,尽可能实现样本均衡。实验结果表明引入SMOTE算法对样本改善效果较为明显,预测效果有所提升,但仍没有达到理想状态,还需进一步对模型进行改进。
下一步在模型的优化上可以换种切入角度,数据失衡导致模型的效果不理想问题不但可以通过引入过采样算法进行改进,还可以尝试通过改进模型算法进行优化,如可引入CART算法或C4.5算法做进一步尝试验证模型预测效果。
[1]余光辉,陈天然,周佩纯. 我国环境群体性事件预警指标体系及预警模型研究[J]. 情报杂志,2013,(7):13-18.
[2]吴竹. 群体性事件预警机制研究[D]. 长沙:中南大学,2006.
[3]胡诗妍,隋晋光,王靖亚. 群体性事件风险定量预测预警[J].西安: 西北大学学报(自然科学版),2012,42(4):548-552.
[4]辛越,于建. 基于灰色分析的群体性事件情报预警[J]. 河北公安警察职业学院学报,2009,9(1):20-24.
[5]GB/T,Technical Specification of Public Safety Risk Assessment[S].http://www.doc88.com/p-385770201522.htm[OB/OL].
[6]Joachims T.SVM light Support Vector Machine[E]. 2008,6.
[7]Nahler M.Decision Tree[M].Vienna: Springer,2009.
[8]Michael A Arbib,Jean-Marc Fellous.Emotions:from brain to robot[J].Trends in Cognitive Sciences,2004,8(12).
(责任编辑:王 谦)
EarlyWarningModelofSocialGroupEventBasedon
ID3-SMOTECombinationAlgorithm
SHI Tuo1,WEI Xin-lei1,SHAO Xu-fen2
(1. Information Engineering School,Communication University of China,Beijing 100024,China;2. Zhejiang Yueqing Middle School,Yueqing 325600,China)
At present,the mass incidents in China show the characteristics of organization,complexity,politics and violence,and seriously affect the social harmony and stability. To predict mass events through scientific means is an effective way to prevent its occurrence. The past group events warning methods were mainly through qualitative analysis or simple quantitative analysis to predict the occurrence of social group events,relatively lack of scientific and reliable data facts as a support. In this paper we obtain relevant group events data occurred in China during recent years through internal units,innovatively introduce machine learning into the field of mass incidents,and get the subversion of the traditional analysis method of group events. From the dual perspectives of social science and natural science,we use machine learning technology to predict mass events scientifically. It has important guiding significance for the government in the process of dealing with mass incidents,scientific decision-making,effective prevention and rapid response.
social group event;classification;decision tree;ID3;SMOTE
TP399
A
1673-4793(2017)06-0009-07
2017-09-22
石拓(1988-),女(汉族),北京市人,中国传媒大学博士研究生.E-mail:414496511@qq.com
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
今日农业(2019年12期)2019-08-13 00:50:02
电子制作(2018年16期)2018-09-26 03:27:06
现代园艺(2017年22期)2018-01-19 05:07:01
学习月刊(2016年19期)2016-07-11 01:59:44
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
火控雷达技术(2016年3期)2016-02-06 02:30:27
新闻传播(2015年21期)2015-07-18 11:14:21
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
小说月刊(2014年11期)2014-04-18 14:12:28
