
一种高性能高可靠的混合客户端缓存系统
2017-12-08 05:59:18李楚冯丹王芳
计算机研究与发展 2017年11期
李 楚 冯 丹 王 芳
(武汉光电国家实验室(华中科技大学) 武汉 430074) (信息存储系统教育部重点实验室(华中科技大学) 武汉 430074)
(lichu@hust.edu.cn)
一种高性能高可靠的混合客户端缓存系统
李 楚 冯 丹 王 芳
(武汉光电国家实验室(华中科技大学) 武汉 430074) (信息存储系统教育部重点实验室(华中科技大学) 武汉 430074)
(lichu@hust.edu.cn)
现代数据中心普遍使用网络存储系统提供共享存储服务.存储服务端通常使用独立冗余磁盘阵列(RAID)技术保障数据可靠性,如可以容单双盘错的RAID56.相比于传统磁盘,固态盘具有更低的访问时延和更高的价格,因此将固态盘作为存储客户端缓存成为一种流行的方案.写回法可以充分发挥固态盘的优势加速存储读写性能,然而一旦固态盘发生故障,写回法无法保证数据的一致性和持久性.写直达法简化了一致性模型,但是无法减小写时延.设计并实现一种新的混合客户端缓存(hybrid host cache, HHC),HHC通过使用廉价的日志磁盘镜像存放固态盘上的脏数据来提高可靠性,并且利用写屏障语义保证数据的可靠性和一致性.分析表明,HHC的平均无故障时间远远高于后端存储系统.最后实现了一个原型系统并使用Filebench进行性能评估,结果表明在不同负载下,HHC性能与传统的写回法接近,远远超过写直达法.
固态盘;客户端缓存;缓存管理;可靠性;性能
现代数据中心普遍使用网络存储系统提供海量存储服务,如网络附加存储(network attached storage,NAS)和存储区域网络(storage area network, SAN)等. 存储应用程序,如邮件服务器、文件服务器等分布在计算节点对外提供服务,并通过网络访问后端共享存储服务器.存储服务器通常使用独立冗余磁盘阵列(redundant array of independent disks, RAID)[1]技术保障存储系统的可靠性.比如RIAD5/6分别可以容单盘和双盘故障,既满足高性能高可靠需求,又能提供较高的存储利用率,在存储服务器中得到广泛应用[2].
随着固态盘(solid-state drive, SSD)存储密度的提高以及价格的不断降低,数据中心节点中部署SSD已成为较为普遍的做法.相对于DRAM,SSD具有大容量、非易失等优势;相对于传统的磁盘(hard disk drive, HDD),SSD有着更高随机访问性能.计算节点上利用SSD作为缓存设备,不仅可以减少对后端存储的访问竞争,而且能够大大降低应用的访问时延.因此,近几年工业界纷纷使用基于SSD的存储客户端缓存来提高存储服务能力[3-5].写直达法(write through)和写回法(write back)是2种基本的缓存写策略.写直达法会将写请求写入后端存储然后写入缓存;写回法只将写请求的数据写入缓存就返回,缓存中的脏数据由缓存管理模块选择合适的时机刷回到后端存储.写直达法可以减小读请求的时延,但因写请求的同步写回,写性能无法得到改善.然而最近的研究表明:企业级工作负载含有大量写操作,且写/读比例有增加的趋势[6-8],在这种负载下,采用写回法能够得到比写直达法好得多的性能[9],这在我们后面的实验中也得到了证实.
尽管写回法能更好地发挥SSD缓存的读写优势,但同时也面临着严峻的挑战:现代SSD中大量使用的多层单元(multi-level cell, MLC)闪存芯片擦除次数只有10 000次,可靠性远低于后端的RAID5/6.我们通过对可靠性的定量分析发现,单块SSD设备与多块磁盘构成的RAID5/6相比,其平均无数据丢失时间(mean time to data loss, MTTDL)少了2个数量级以上.那么当SSD发生不可恢复的故障时,采用传统的写回法将带来2个问题:1)脏数据异步刷回机制破坏了原来的写入顺序,因此无法保证存储服务器端的数据一致性;2)缓存数据的丢失使得原本被认为持久化的数据并没有写入后端存储,这样就无法保证数据的持久性,尤其是目前的SSD容量不断提升,一旦SSD出现故障将造成大量数据不可恢复的丢失,这是很多存储应用以及用户无法容忍的.因此,如何克服这些问题成为近几年的研究热点.
为了解决写回法带来的问题,研究人员提出了各种方案,按照实施的层次可分为2类:1)提高SSD缓存层的可靠性,从而降低缓存层失效的概率.其方法主要是使用 RAID技术组织多个SSD,利用冗余数据保证缓存层的可靠性,如Oh等人[10]提出的SRC(SSD RAID cache)以RAID5方式管理多块SSD缓存数据,Arteaga等人[9]则使用RAID1来构建SSD缓存层.尽管这种方式确实可以大大提高SSD缓冲层的可靠性,但是同时也导致成本大幅增加,而且RAID带来的冗余数据增加了SSD的擦写次数,加速了SSD的磨损,更严重的是均匀的磨损分布增加了多个SSD同时失效的风险[11-12].2)通过提出基于写回法的新缓存策略来应对SSD失效问题.如Koller等人[13]提出了2种缓存策略:Ordered Write-back和Journaled Write-back,可以保证脏数据的刷回顺序与应用程序写入的顺序完全相同.虽然这种方式保证了SSD缓存设备失效时存储服务端的数据一致性,但是并不能保证数据的持久性.Qin等人[14]提出Write-back Flush策略,利用文件系统、数据库等存储应用提供的写屏障(write barrier)机制, 在SSD缓存层实现写屏障操作的语义来保证数据的一致性和持久性.写屏障会阻塞随后的写请求,直到缓存中所有脏数据被持久化存储,文件系统等存储应用通过该机制保证数据的写入顺序[15].在Write-back Flush策略中,写屏障操作会触发缓存管理程序将SSD中所有脏数据刷回到网络存储系统,这使得写屏障时延较长,因此对于写密集尤其是同步密集型(如fsync,该操作会触发写屏障)负载,频繁的数据刷回操作直接影响到存储应用的响应时间.
本文提出一种新的混合客户端缓存(hybrid host cache, HHC)架构.HHC由SSD和廉价的HDD组成,缓存管理模块选择性地将SSD缓存中的脏数据以日志方式顺序写入HDD,一方面保证了缓存层的可靠性,另一方面充分利用磁盘顺序写的带宽优势,尽可能减小冗余的写入操作对前台写请求的影响.另外,在写回法的基础上,HHC利用写屏障机制实现新的缓存策略,通过结合精心设计的日志管理策略保证数据的一致性和可靠性.最后我们实现原型系统并使用Filebench[16]对I/O吞吐率进行测试和分析.实验结果表明,在读密集型负载websearch下HHC与其他缓存策略表现相当,在写密集型负载fileserver下HHC相对于写直达可以提高75.4%~388.2%,相对于Write-back Flush提高了48.2%~173.4%;在同步密集的负载varmail下比写直达提高了3.7~8.2倍,相对于Write-back Flush提高了5.5~10.2倍.
1 混合客户端缓存HHC
1.1设计目标
在设计HHC时,我们致力于达到4个目标:
1) 持久性.当SSD设备发生故障时,将导致所有的缓存数据不可用.由于使用基于写回法的缓存策略,缓存中的数据块主要有2种:干净缓存块和脏缓存块.干净缓存块是当读不命中时从后端读入缓存的数据块,而脏缓存块是由应用程序写入缓存且未被刷回后端存储服务器的数据块.由于干净缓存块在后端有同样的副本,因此不需要额外的保护.而对于脏缓存块应当提供与后端RAID5/6相当级别的可靠性保障[9].HHC使用磁盘来镜像地存放SSD缓存中的脏数据,通过定量的可靠性分析发现:当使用1块磁盘时HHC可达到超过RAID5的可靠性级别;而当使用2块磁盘做镜像时,HHC的可靠性可以超过RAID6(见第2节,可靠性分析).因此,可以根据后端存储的RAID级别使用不同的HHC配置.
2) 一致性.存储应用通常会利用写屏障请求来实现原子操作和持久化操作(如fsync)等,从而确保数据的一致性[14].当存储应用发出写屏障请求时,存储设备会将其缓存中的所有脏数据持久化到设备之后才返回到应用,这样使得写屏障之前与之后的写操作的顺序性得到保证.需要注意的是,对于写屏障之后的写操作,存储系统并不保证其持久化到存储设备,即在2个写屏障之间的写操作并不需要强制保证其持久化到存储设备时的顺序.HHC在缓存层实现写屏障语义,当来自存储应用的写屏障请求到达时,HHC一方面将对SSD设备发送写屏障以确保缓存数据和缓存索引的持久化,另一方面确保SSD中的脏缓存块全部持久化到磁盘日志.因此即使SSD或HDD出现故障,仍然能保证写屏障时所有数据不会丢失,从而保证写屏障语义的正确实施.
3) 高性能.存储应用程序发送的写屏障操作要求将所有SSD中的脏数据持久化到磁盘日志,为了降低写屏障的时延, HHC在内存中维护多个内存缓冲区,对应到磁盘上的日志段,存储应用的写请求被写入内存缓冲区,并采用流水线的方式异步地写回到磁盘日志.这样既可以避免因脏数据累积过多而增加写屏障的开销,又可以充分利用磁盘顺序写的带宽优势.研究表明大量的负载都有着突发性特征,I/O空闲期广泛存在[17],因此为了保证充足的日志空间,HHC在系统空闲的时间进行日志回收操作,从而尽可能避免日志回收带来的开销.
4) 低成本.尽管SSD的价格逐步降低,然而其单位存储的价格仍然比磁盘高出10倍左右.因此使用额外的磁盘并不会带来成本的显著增加,而且由于数据中心的计算节点常常会有备用的磁盘处于空闲状态,HHC可以将这些磁盘作为日志盘使用,进一步降低存储系统的成本.
表1给出了5种不同缓存策略的对比,依次是写直达法(WT)、写回法(WB)、Ordered Write Back(WB-Ordered)、Write-back Flush(WB-Flush)以及我们的HHC.WB能够提供最好的性能,但是它既不能保证一致性也不能保证持久性;WB-Ordered在不同的负载下都有很好的性能,但是同样不能提供持久性;WT和WB-Flush能够保证一致性和持久性,但是对于写密集型和同步密集型(如邮件服务器等)的存储应用,并不能充分发挥SSD的读写优势;而HHC在不同负载下能够达到或接近WB的性能,同时能够保证数据的一致性和持久性.
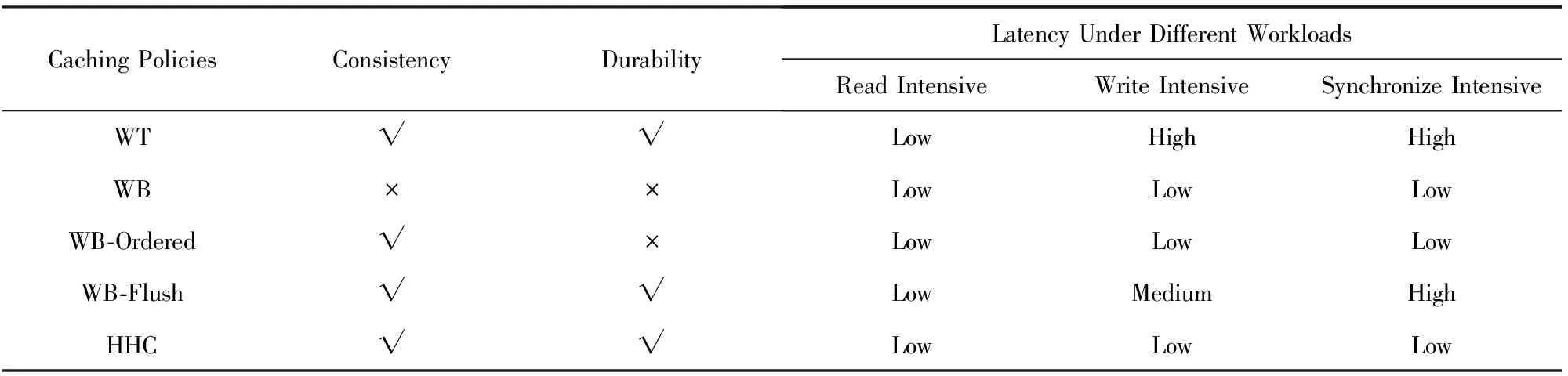
Table 1 Comparison of Different Policies表1 不同缓存策略的对比
Note:“√” means support; “×” means nonsupport.
1.2HHC系统架构概述
如图1所示,根据后端存储服务可靠性的不同,HHC在传统的固态盘缓存层添加一个或多个磁盘,多个磁盘将以镜像的方式存储数据,从而保证可靠性需求.固态盘作为读写缓存使用,其缓存策略可以选择传统的LRU方式,也可以使用近年来提出的一些针对固态盘特性的选择性缓存策略等.固态盘缓存中的数据按照缓存状态可分为2类:1)干净缓存块,即缓存块中的数据在后端存储中有相同的副本;2)脏缓存块,即由应用程序写入的新数据,尚未写回到后端存储.为了充分发挥固态盘缓存带来的性能提升,以及充分利用磁盘优秀的顺序写性能,HHC采用异步的方式将固态盘中的脏缓存块写入附加的磁盘中,磁盘数据以日志的方式进行组织,即所有的写操作都是追加写,最大程度上减小磁盘的寻道时延和旋转时延.
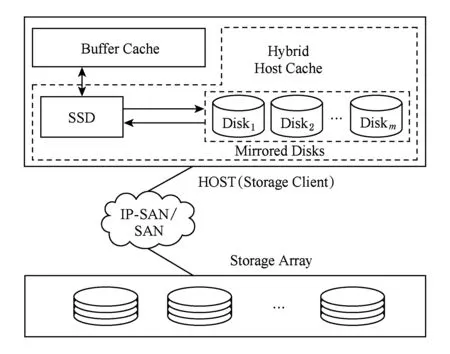
Fig. 1 Architecture of HHC图1 HHC架构图
HCC主要包含3个模块:固态盘缓存管理模块、磁盘日志管理模块和故障处理模块.固态盘缓存管理模块主要用来响应上层应用程序的读写请求、管理缓存空间、缓存块的状态以及与后端存储上的映射关系等;磁盘日志管理模块负责管理磁盘上的日志空间,其功能主要包括日志的写入、垃圾回收等;故障处理模块负责当发生故障时,根据故障类型执行相应的故障恢复工作,保证存储系统的数据一致性和持久性.
1.3固态盘缓存管理
固态盘缓存管理将固态盘分为2个区域,即元数据区和数据区.元数据区记录缓存块的状态以及逻辑地址映射信息等,容量较小,通常可全部放入DRAM中以加速缓存查找.数据区用来存放缓存数据,以固定大小划分,默认选用4 KB.该模块对上主要提供3种操作:读、写和写屏障操作.
对于读请求,首先以请求的逻辑块地址为关键字在缓存中查找是否命中,如命中则根据缓存元数据信息中的映射关系,从相应的缓存块读出完成读操作;如不命中,则从后端存储服务器读取数据块,并申请缓存块写入固态盘缓存,同时在内存中添加相应的元数据信息.对于写请求,与读请求类似,首先在缓存中查找,如果命中则写入缓存,否则申请新的缓存块将数据写入并修改元数据信息.元数据信息被同步刷回到固态盘,使得即使客户端重启,缓存中的数据块和其状态仍然能够正确恢复.事实上以上也是传统的写回法缓存处理流程.当申请缓存块的时候,如果缓存块已满则需要进行缓存替换操作,为了减小缓存替换时的延迟时间,HHC采用LRU的方式优先替换干净缓存块以避免写回操作.为了保证以上缓存替换过程的顺利进行,在后台执行脏数据块刷回操作,使得SSD缓存中脏数据块的数量不超过一定的阈值.刷回操作在后台执行,并且根据负载密集程度调整优先级.当负载较轻或空闲时,提高刷回优先级使得更多缓存块可用;当负载较重时,降低刷回优先级以减小对前台应用I/O的影响.当刷回操作完成时,同时会向磁盘日志管理模块发送相应的revoke通知,日志会记录相应的撤销块,这种机制有利于日志盘的空间利用以及降低日志操作开销.
另外,HHC对于写操作增加了异步提交日志的操作.当数据写入缓存的同时,并行地将其提交给磁盘日志管理模块,该模块负责将其异步地写入磁盘以提供可靠性保证.HHC提供的另一个特殊的操作为写屏障操作, 该操作将会触发日志写入操作,直到SSD缓存中的脏数据都被写到磁盘写屏障才会返回,这样可以保证写屏障操作的语义.即该操作完成后,保证所有数据持久化到存储设备.为了保证异步提交日志机制的正确执行,HHC在SSD缓存块元数据信息中加入了一个标记位Logged_Flag,表示该数据块是否已提交给磁盘日志管理模块.日志管理的具体流程将在1.4节给出.
需要注意的是,写屏障操作并不会改变SSD缓存块状态,原来的脏缓存块仍然保留脏块的标记,否则可能会导致数据丢失而破坏写屏障语义.例如,写屏障操作使得脏缓存块D被写入HDD日志中,然后将其标记为干净,随后缓存块D被替换出缓存,此时假如HDD出现故障,缓存块D的数据将无法恢复.
1.4磁盘日志管理
为方便进行日志管理,磁盘采用如下组织方式:磁盘开头存放日志超级块,剩余部分被分成固定长度的段(segment),每个段有一个头部(header)记录该段日志的元数据信息.当采用多个磁盘时,由于采用镜像方式,所以各个磁盘上的划分是一样的.磁盘日志管理主要包含2个方面:1)日志的写入;2)日志的回收.日志的管理我们采用类似文献[18]中Everest store的设计,但是根据新的应用场景进行了一些修改和优化.
1.4.1 关键数据结构
日志超级块用来记录日志的基本信息,如日志头和尾的位置、日志块大小、每个段的长度等.在HHC的设计中,日志超级块主要是用来在故障恢复时定位日志起始位置,从而减少扫描日志所需要的时间,超级块并不需要频繁地持久化到磁盘,而只在系统空闲时间或周期性地写入日志盘,因此并不会影响日志写入的性能.日志段是真正存放日志数据块的地方,分为段头部和数据区,段的头部主要包含6个字段:
1) SegmentID.当前的段号,编号从0开始.
2) SequenceID.表示该段的序列号,每当写入新的日志段时,该值加1.
3) Barrier_Flag.当该日志段是针对写屏障操作的最后一个日志段时,将该标记位置1.
4) Checksum.日志数据的校验和,主要用来保证日志段的完整性,在恢复时可以根据校验和判断该日志段是否写入成功.
5) Log_LBA_Table.记录该段中日志块对应的原来逻辑块地址.例如,假如第1个日志块对应的后端存储的LBA(logicalblockaddress)为8192,那么Log_LBA_Table的第1项就写入8192.

Fig. 2 In-memory structure for log blocks图2 内存中的日志块索引结构
HHC在内存中维护日志盘的当前状态,如当前日志的起始和结束位置、当前日志段的序列号等.Log Entry结构记录一个数据块在日志中的位置,即所在日志的段和在数据区中的块索引号.属于相同日志段的Log Entry结构被串联起来以方便日志回收.所有的Log Entry以Hash链表的方式组织起来,以加速日志块的查找,如图2所示.另外内存中维护一个缓冲池,用来缓冲新来的日志数据块.缓冲池中包含多个缓冲区,每个缓冲区跟日志磁盘上的一个段大小一样,缓冲区头部对应日志段头部,缓冲区数据区对应日志段中的数据块.日志段大小设置存在一个权衡的问题.如果设置太小,则无法充分发挥磁盘大块写的带宽优势,而且会增加日志元数据的存储开销;如果设置过大,则当写屏障请求到达时需要等待的时间可能会比较长,对于fsync操作密集的负载会增加访问时延.因此管理员需要根据实际的负载特征使用合理的设置.
1.4.2 日志写入
在进行日志写入时,HHC首先将日志块写入到内存中的缓冲区,更新日志Hash表中相应的Log Entry结构,并且将SSD缓存数据块元数据信息中的Logged_Flag标志位置1.当缓冲区写满或写屏障请求到达时,将该缓存区写入当前日志尾部对应的日志段,对于由写屏障触发的最后一个日志段需要将头部的Barrier_Flag标记位置1,代表本次写屏障操作完成,在日志恢复时需要用到该标记位.固态盘缓存脏数据的刷回操作会使得旧的日志块无效,此时如果对应的日志块尚处在内存缓冲区中,则只需要在内存中删除该日志块,否则将该日志块对应RAID中的逻辑块地址记录到缓冲区中的Revoke_Table,最后将该块对应的Log Entry从内存Hash表中删除.注意,对缓冲区中的日志块进行更改时可以在内存中进行原地更新,而为了避免产生随机I/O增加时延,一旦缓冲区被持久化到日志段,HHC将不会对日志段进行更新操作,而是通过维护内存中的日志Hash表来记录有效的日志块信息.
由于缓冲池中包含多个缓冲区,当一个缓冲区在刷回磁盘时,新来的日志数据可以写入另一个缓冲区,这样的并行处理可以最大程度提高日志盘的写入带宽.尽管目前的SSD写入带宽高于磁盘,通常情况下,缓冲池中的数据仍然可以及时刷回到日志盘而不会造成缓冲池紧缺,原因主要有2个方面:1)SSD缓存盘作为读写缓存设备,其负载包含了读和写,再加上SSD的读写干扰问题[19]使得其写带宽远达不到其饱和值;2)SSD的写入操作主要有2部分组成:1)读不命中时从后端存储载入数据;2)写入脏数据.而第1类写操作并不产生日志数据,因此这也降低了日志数据的产生频率.然而对于极端情况,比如当写操作非常密集时,仍然有可能会造成缓冲池不足的情况,这时对于新来的日志数据并不做处理,当有空缓冲区时,从SSD缓存元数据中遍历Logged_Flag=0的脏缓存块,将其读入日志缓冲区,随后的操作与前面描述的一致.
1.4.3 日志回收
由于日志总是顺序地追加到日志尾部,日志盘的可用空间会持续减小.而为了保证日志的顺利写入就需要在合适的时间进行日志回收操作.由于有效日志块以Log Entry及Hash表方式存储在内存,且相同日志段的日志块被串联在一起,HHC可以很方便地识别待回收的日志块,加速日志回收过程.考虑到HHC只缓存SSD缓存中的脏数据等特点,我们将日志回收分为主动回收和被动回收2种.
主动回收是指将日志头部的有效日志块迁移到日志尾部从而释放日志空间.与传统的日志回收不同的是,HHC并不需要从日志磁盘中读取数据,而是选择从SSD缓存中读取相应的数据块.这是由HHC的日志管理机制决定的,因为当SSD中缓存块变为干净状态时,会向日志管理模块发送revoke通知,使得日志中对应的日志块变无效,也就是说日志块中的有效块必然在SSD缓存中有相同的副本.这样就可以充分利用SSD的读优势,而且避免了传统日志回收对日志写入的负面影响.
被动回收是指利用缓存本身的特点进行自我回收.其原理是考虑到日志管理的特点和负载特征.在HHC的日志管理中,有2种情况下会将之前的日志块置无效,一种是SSD缓存块的覆盖写,一种是周期性的脏块刷回操作.最近写入的数据位于更靠近日志尾部的日志段,而很久未被修改的脏数据位于更靠近日志头部的段.这样日志段事实上就形成一种天然的LRU排序方式.考虑到负载的局部性特征,通常缓存的刷回操作也采用LRU的方式进行,随着将日志尾部所在日志段中的脏数据刷回后端缓存,日志头部索引向尾部靠近,从而释放日志空间.HHC充分利用缓存特点和日志管理模式,结合主动回收和被动回收2种方式,降低日志回收带来的开销.
1.5故障处理
HHC的特点之一就是混合缓存层的高可靠性.对于非设备故障如断电重启,由于固态盘缓存的元数据信息已经被持久化,因此不会影响数据的一致性.对于设备故障,如果是日志盘故障,同样不影响数据的一致性,因为所有缓存数据仍然在SSD缓存中.
当固态盘失效时,需要从日志盘中恢复出最近一次写屏障操作之前的所有脏数据,写回到后端存储.其恢复过程主要分3个步骤:
步骤1. 读取日志盘的超级块找到需要恢复的日志起始和结束位置.日志结束位置是指最近一次成功执行写屏障操作的日志段,这是通过从日志头顺序扫描日志段头部直到下一个SequenceID小于当前段,然后反向查找离该段最近的一个Barrier_Flag被置位的段并通过校验和确保该段写入完整,否则继续往前查找.
步骤2. 根据读上来的日志元数据信息,顺序地从日志盘读取相应的数据块写入后端存储.
步骤3. 重新初始化将日志盘完成数据恢复工作.
如果SSD和所有HDD都失效,那么不可避免地会导致缓存数据的丢失.不过通过我们对HHC的可靠性分析可以发现,HHC的可靠性甚至高于后端存储通常采用的RAID5/6,因此全部失效的概率是极低的.具体分析在第2节给出.
2 HHC可靠性分析
为了保证缓存数据不丢失,就需要使得缓存层尽可能地满足高可靠性.HHC的一个设计原则就是保证混合缓存层的可靠性不低于后端存储的可靠性.RAID5/6作为底层存储广泛应用于数据中心以及云存储环境下,因此这里只对HHC和RAID5/6的可靠性进行定量分析和比较.
平均无数据丢失时间(MTTDL)作为一个重要的可靠性指标,被广泛用来衡量存储系统的可靠性.假设磁盘故障、固态盘故障以及修复过程是独立的,且服从参数分别为λ,φ,μ的指数分布,通过构造Markov链可以方便地计算存储系统的MTTDL.
设N为阵列中的磁盘数,RAID5的MTTDL计算为
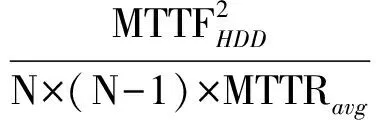
RAID6的MTTDL计算为
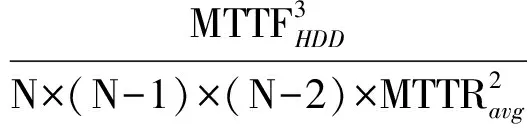

Fig. 3 State-transition probability diagram for HHC (M=1)图3 HHC状态迁移概率图 (M=1)
为了计算HHC的MTTDL,首先假设磁盘数M=1,使用Markov模型构造状态迁移概率图,如图3所示.状态0表示磁盘和固态盘都正常工作;当磁盘失效时进入状态1,若此时在恢复完成前固态盘失效则会导致缓存数据丢失;类似地处于状态0时,当固态盘发生故障则进入状态2,若在故障恢复前磁盘失效也会造成数据丢失.为描述该过程可通过构造Kolmogorov微分方程系统来实现[20]:
其中pi(t)代表HHC处于状态i的概率,其初始条件为
对式(3)进行拉普拉斯变换得到:
由式(3)(4)最终得到HHC的MTTDL为
式(6)得到当磁盘数M=1时的MTTDL计算方法.当Mgt;1时,由于修复前平均时间(mean time to failure, MTTF)远远超过平均修复时间(mean time to repair, MTTR),可以用下面的方法近似计算出HHC的MTTDL.首先计算出M个磁盘作为整体的MTTDLMirror-M,那么该整体的故障率将服从参数为λ′的指数分布,将λ′代入式(6)即可得到新的MTTDL.这里仅以M=2为例给出计算过程,λ′的计算公式如下:
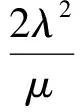
将式(6)中的λ替换为式(7)中得到的λ′即可得到MTTDLHHC-2,鉴于结果过于冗长,这里不给出推导后的公式,而是用图来给出更为直观的对比结果.参考目前主流设备的数据表(datasheet),实验中使用的参数取值如表2所示.
图4(a)中给出了使用一个磁盘时HHC与RAID5的MTTDL对比图,为方便比较,图4也给出了SSD设备的MTTF.图4中x坐标轴表示后端RAID5阵列使用的磁盘数;y坐标轴表示故障修复平均需要的时间;z坐标轴代表最终计算出的MTTDL,该值越大代表可靠性越高.从图4中可以看出,SSD的可靠性最低,远低于后端存储,这也再次证实了提高缓存可靠性的必要性;RAID5的可靠性随磁盘数的增加而下降;随着平均修复时间的增加,HHC和RAID5的可靠性都有所下降,但是可以清晰地看到,HHD的可靠性始终远高于RAID5(注意图4中的z轴使用的是对数坐标).图4(b)给出了使用2块磁盘做镜像时HHC与RAID6的MTTDL对比图.可以看到与图4(a)类似地趋势,HHC-2的可靠性远远超过了RAID6,而随着后端磁盘数的增加,优势会更加明显.

Table 2 Main Parameters for Reliability Analysis表2 可靠性分析中的主要参数表
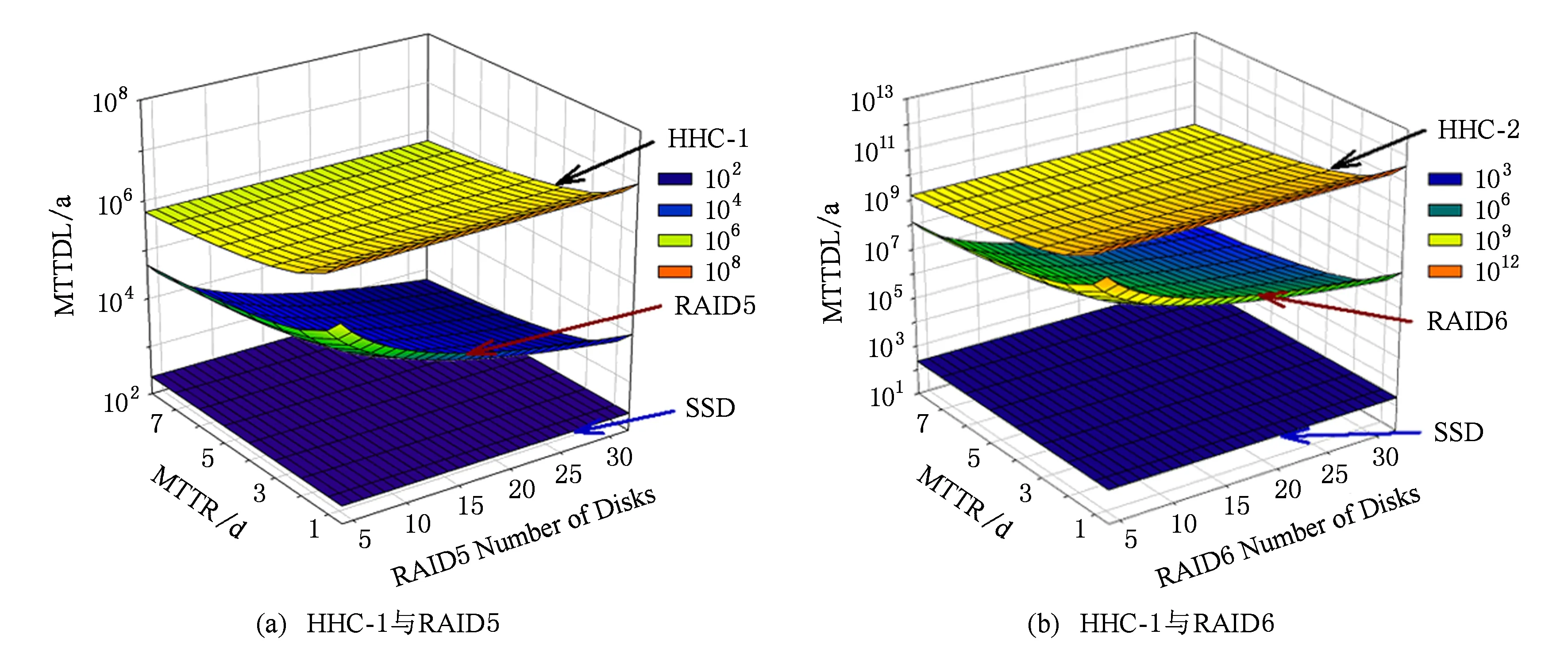
Fig. 4 MTTDL Comparison of HHC and RAID5/6图4 HHC与RAID5/6的MTTDL对比
3 实验结果与分析
我们在Linux系统中实现了HHC缓存架构内核模块,使用LRU替换算法,支持基本的写直达法(WT)、写回法(WB)以及本文提出的缓存策略(WB-HHC).同时实现了最近提出的Write-back Flush(WB-Flush)缓存策略.使用通用测试工具对比测试在不同负载环境下各种缓存策略所能提供的性能.为了展示缓存在网络存储环境中带来的优势,实验也给出不使用SSD缓存Raw时的性能作为对比.由于HHC中磁盘是以镜像方式组织的,日志采用完全并行的方式写入,使用两块盘的时候仅对可靠性带来提升,对性能并没有太大影响,因此在本节实验部分只对单磁盘架构下的HHC进行性能测试.
3.1实验环境及测试方法
测试平台主要由2部分构成,即存储客户端(host)和存储服务端(server),通过1 GB以太网连接.Host配备2个2.4 GHz的Intel Xeon E5620 CPU,1块120 GB的SATA接口SSD作为缓存,2块1 TB SATA2接口的HDD,其中1块安装CentOS release 5.4系统,另外1块HDD与SSD一起构成混合缓存.存储客户端使用3.12.9内核版本.为了减少Host端操作系统的页高速缓存带来的影响,我们将其内存设置为512 MB或1 GB.存储服务端配备2个2.13 GHz的Inter Xeon E5606 CPU,16 GB内存.5块1TB的HDD使用Linux的MD模块构成软RAID5通过iSCSI为存储客户端提供存储服务.为了体现阵列的真实性能,存储服务端禁用缓存.
存储客户端使用iSCSI发起程序将target端连接到本地,并格式化成Ext4文件系统,使用ordered日志模式.为了测试在不同负载下的性能,我们使用Filebench生成不同类型的负载.主要使用3种测试负载:websearch, fileserver, varmail,分别代表读负载密集型、写负载密集型以及同步操作密集型(fsync操作).websearch代表Web服务器的负载,读写比例设置为10∶1,文件平均大小为16 KB,文件数为100 000工作集大约为1.6 GB.本实验中该负载使用40个线程并发进行I/O操作,包括随机读取整个文件,追加写入日志文件,追加块平均大小也为16 KB.fileserver模拟多用户的文件服务器负载,每个用户对应到一个测试线程,独立地访问属于该用户的目录,主要操作包括创建、删除、读、写等.其读写比例为1∶2,本实验采用的负载大小约为2.2 GB.varmail模拟电子邮件服务器的负载,与Postmark类似,但Filebench使用多线程的方式进行一系列操作,主要包括读整个文件、追加写以及频繁的fsync操作,本实验中其工作集大小设置约为1.6 GB.以下每次测试时间为15 min,每项测试都执行3次取平均,测试指标为吞吐率(IOPS).如果参数有所改变,会在相应地方给出说明.
3.2不同负载下的性能及分析
我们在SSD上划分4 GB空间作为缓存,图5显示使用3种负载以及使用不同缓存策略的性能.其中Raw代表不使用缓存,WB表示写回法,WT表示写直达法,这3种缓存策略作为基准.WB-HHC是本文提出的缓存策略,WB-Flush作为最近提出的一种提供可靠性保证的缓存策略,是我们主要的对比对象.

Fig. 5 IOPS under different caching policies图5 不同缓存策略的IOPS
从图5可以看出,由于SSD的速度优势,使用SSD缓存确实能带来明显的性能提升.对于websearch负载来说,由于其主要以读请求为主,因此5种缓存策略性能几乎没有差异.当使用fileserver负载时,WB-HHC的性能比WT和WB-Flush分别提高了388.2%和63.1%.这是由于fileserver负载中写操作比较多,使得缓存中累积大量的脏数据,EXT4周期性的commit会触发写屏障操作,从而使得WB-Flush从SSD中读出所有脏数据写回RAID5阵列.这部分开销使得其性能低于WB.WB-HHC异步地将脏数据顺序写入本地磁盘日志,大大缓解了WB-Flush中的写屏障开销,使得其性能基本上可以达到WB的水平.在varmail负载中,可以看到WB-Flush的性能甚至低于Raw和WT,分析发现这主要是因为varmail使用大量的线程并发操作,且使用了大量的fsync操作,这就使得写屏障操作非常密集.而对于写Raw和WT来说,脏数据会直接从内存写入到RAID5,而WB-Flush则需要先从SSD读出,然后写入后端阵列,由于频繁的fsync使得这部分开销无法被忽略.尽管WB-HHC也受到一些影响,但是相对于WT和WB-Flush分别提高了5.1倍和10.2倍.
3.3缓存大小对性能的影响
缓存策略与缓存大小有关,本节使用fileserver负载来深入理解不同缓存大小对性能带来的影响.考虑到实际环境下的DRAM/SSD容量比,本实验中客户端内存大小设置为512 MB,缓存大小为1~3 GB,负载为2.2 GB.从图6的测试结果可以看出,随着缓存的增加,IOPS逐渐增高,当缓存达到2 GB以上时性能趋于饱和;随着缓存的增加,WB-Flush相对WT有着越来越明显的性能优势,因为延迟的刷回操作减少了对前台写操作的影响;然而WB-HHC在不同缓存大小下的性能仍然能够接近WB策略,相对于WT性能提高了75.4%~355.6%,比WB-Flush提高了48.2%~173.4%.
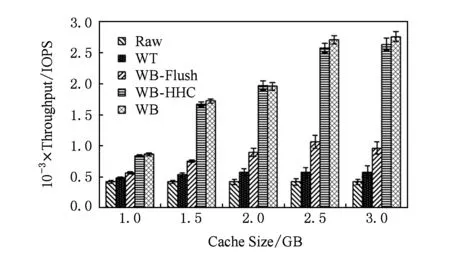
Fig. 6 Sensitivity to different cache sizes图6 不同缓存大小对性能的影响
3.4负载强度对性能的影响
本节讨论不同的负载强度对缓存策略带来的影响.为此我们使用同步密集型的varmail负载,通过调整负载的并发线程数来模拟不同强度的邮件访问场景.考虑到一般邮件服务器的工作集不会太大,实验中使用的负载大小约为1.6 GB,缓存大小设置为4 GB,客户端内存设置为512 MB.图7显示了负载线程数从2~32时不同缓存策略的测试结果.

Fig. 7 Sensitivity to different number of threads图7 不同线程数对性能的影响
从图7中可以看出,随着线程数的增加各种缓存策略的性能也有所增加,然而WB-Flush的增加幅度小于其他缓存策略,这使得在负载较重时(线程数不低于8),其性能甚至低于WT和Raw.其原因是大量的fsync操作导致密集的写屏障,WB-Flush需要频繁地从SSD读取脏数据写入RAID5,增加了fsync操作的延时,这种开销随着负载强度的增加会愈加明显.对于WB-HHC来讲,频繁的写屏障操作使得脏数据在内存中的聚集时间变短,降低了日志盘批量写回的优势,因此随着线程数的增加,WB-HHC与WB的差距会愈发明显.但是相比于WT和WB-Flush,WB-HHC的性能分别提高了3.7~8.2倍和5.5~9.1倍.
3.5HHC内存开销分析
HHC的内存开销主要来自于2个方面:固态盘缓存在内存中的元数据信息;用于日志管理的额外的内存开销.
1) 所有缓存策略所共有的、对于4 KB缓存块大小而言,每个缓存块在内存中的元数据信息主要包括其在固态盘及磁盘阵列中的逻辑块地址、缓存块状态以及用于索引结构的指针等,一共约20 B,因此其内存开销与固态盘容量的比例约为0.49%.
2) 内存开销主要来源于日志块索引(如图2所示),由于HHC只在内存中维护有效日志块信息,其数量等同于固态盘中脏缓存块的个数(通常被限制在一定阈值之内,如不超过缓存块总量的30%),而每个Log Entry的大小约为10 B,因此其内存开销约为固态盘缓存容量的0.07%.从以上分析可以看出,HHC的总内存开销约为固态盘缓存总容量的0.56%,尽管相比其他算法略有增加,但是在现代存储系统中仍然是可以接受的.
4 结束语
现代数据中心普遍使用固态盘作为缓存加速对网络存储系统的访问,写直达法可以严格保证数据的一致性,但对于写操作较多的负载,其性能远低于写回法.作为改进写回法的Write-back Flush策略将存储系统的写屏障语义引入SSD缓存层,来保证数据的一致性和持久性,然而实验发现对于同步操作密集型的负载,如邮件服务器,其性能甚至低于写直达法.本文使用SSD和廉价的HDD构成混合客户端缓存,避免了SRC带来的高成本,同时降低了写屏障操作的时延,实验结果证实了HHC的优越性.
[1]Chen P, Lee E, Gibson G, et al. RAID: High-performance, reliable secondary storage[J]. ACM Computing Surveys, 1994, 26(2): 145-185
[2]Zhang Guangyan, Zheng Weimin, Li Keqin. Rethinking RAID-5 data layout for better scalability[J]. IEEE Trans on Computers, 2012, 61(11): 2816-2828
[3]Hensbergen V, Zhao Ming. Dynamic policy disk caching for storage networking[R]. Austin, TX: IBM, 2006
[4]Byan S, Lentini J, Madan A, et al. Mercury: Host-side flash caching for the data center[C]Proc of IEEE MSST’12. Piscataway, NJ: IEEE, 2012: 37-48
[5]Saab P. Releasing flashcache: Facebook blog[OL]. 2010 [2016-07-09]. https:www.facebook.comnotesmysql-at-facebookreleasing-flashcache388112370932
[6]Leung A, Pasupathy S, Goodson G, et al. Measurement and analysis of large-scale network file system workloads[C]Proc of USENIX ATC’08. Berkeley, CA: USENIX Association, 2008: 213-226
[7]Koller R, Rangaswami R. IO deduplication: Utilizing content similarity to improve IO performance[C]Proc of USENIX FAST’10. Berkeley, CA: USENIX Association, 2010: 211-224
[8]Roselli D, Anderson T. A comparison of file system workloads[C]Proc of USENIX ATC’00. Berkeley, CA: USENIX Association, 2000: 41-54
[9]Arteaga D, Zhao Ming. Client-side flash caching for cloud systems[C]Proc of the 7th ACM SIGOPS Int Systems amp; Storage Conf. New York: ACM, 2014: 7:1-7:11
[10]Oh Y, Choi J, Lee D, et al. Improving performance and lifetime of the SSD RAID-based host cache through a log-structured approach[C]Proc of the 1st Workshop on Interactions of NVMFLASH with Operating Systems and Workloads. New York: ACM, 2013: 5:1-5:8
[11]Balakrishnan M, Kadav A, Prabhakaran V, et al. Differential RAID: Rethinking RAID for SSD reliability[C]Proc of the 5th European Conf on Computer System. New York: ACM, 2010: 15-26
[12]Jeremic N, Muhl G, Busse A,et al. The pitfalls of deploying solid-state drive RAIDs[C]Proc of the 4th Annual Int Conf on Systems and Storage. New York: ACM, 2011: 14:1-14:13
[13]Koller R, Marmol L, Rangaswami R, et al. Write policies for host-side flash caches[C]Proc of the 11th USENIX FAST’13. Berkeley, CA: USENIX Association, 2013: 45-58
[14]Qin Dai, Brown D, Goel A. Reliable writeback for client-side flash caches[C]Proc of USENIX ATC’14. Berkeley, CA: USENIX Association, 2014: 451-462
[15]Fedora Documentation. Write barriers[OL]. [2016-05-21]. http:docs.fedoraproject.orgen-US-Fedora14htmlStorage_Administration_ Guidewritebarr.html
[16]Amvrosiadis G. Filebench: A model based file system workload generator[CPOL]. 2011[2015-11-11]. https:github.comfilebenchfilebench
[17]Mao Bo, Jiang Hong, Wu Suzhen, et al. HPDA: A hybrid parity-based disk array for enhanced performance and reliability[J]. ACM Trans on Storage, 2012, 8(1): 1-20
[18]Narayanan D, Donnelly A, Rowstron A. Write off-loading: Practical power management for enterprise storage[C]Proc of USENIX FAST’08, Berkeley, CA: USENIX Association, 2008: 253-267
[19]Chen F, Koufaty D A, Zhang X. Understanding intrinsic characteristics and system implications of flash memory based solid state drives[C]Proc of ACM SIGMETRICS’09. New York: ACM, 2009: 181-192
[20]Paris J, Amer A, Long D. Using storage class memories to increase the reliability of two-dimensional RAID arrays[C]Proc of the 17th Annual Meeting of the IEEEACM Int Symp on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems. Piscataway, NJ: IEEE, 2009: 1-8

LiChu, born in 1989. PhD in computer architecture from Huazhong University of Science and Technology, China. His main research interests include RAID system and flash memory.

FengDan, born in 1970. PhD, professor, PhD supervisor. Senior member of CCF. Her main research interests include computer architecture, massive storage systems, and parallel file systems.

WangFang, born in 1972. PhD, professor. Member of CCF. Her main research interests include distribute file systems, parallel I/O storage systems and graph processing.
AHighPerformanceandReliableHybridHostCacheSystem
Li Chu, Feng Dan, and Wang Fang
(Wuhan National Laboratory for Optoelectronics (Huazhong University of Science and Technology), Wuhan 430074) (Key Laboratory of Information Storage System (Huazhong University of Science and Technology), Ministry of Education, Wuhan 430074)
Modern date centers widely use network storage systems as shared storage solutions. Storage server typically deploys the redundant array of independent disks (RAID) technique to provide high reliability, e.g., RAID56 can tolerate onetwo disk failures. Compared with traditional hard disk drives (HDDs), solid-state drives (SSDs) have lower access latency but higher price. As a result, client-side SSD-based caching has gained more and more popularity. Write-back policy can significantly accelerate the storage IO performance, however, it fails to ensure date consistency and durability under SSD failures. Write-though policy simplifies the consistence model, but fails to accelerate the write accesses. In this paper, we design and implement a new hybrid host cache (HHC). HHC selectively stores mirrored dirty cache blocks into HDDs in a log-structured manner, and utilizes the write barrier to guarantee the data consistency and durability. Through reliability analysis, we show that the HHC layer has much longer mean time to data loss (MTTDL) than the corresponding backend storage array. In addition, we implement a prototype of HHC and evaluate its performance in comparison with other competitors by using Filebench. The experimental results show that under various workloads, HHC achieves comparable performance compared with the write-back policy, and significantly outperforms the write-through policy.
solid-state drive (SSD); host cache; cache management; reliability; performance
2016-11-02;
2017-02-06
国家“八六三”高技术研究发展计划基金项目(2015AA015301);国家自然科学基金项目(61472153,61402189,61502191)
This work was supported by the National High Technology Research and Development Program of China (863 Program) (2015AA015301) and the National Natural Science Foundation of China (61472153, 61402189, 61502191).
冯丹(dfeng@hust.edu.cn)
TP334
猜你喜欢
北京工业职业技术学院学报(2024年1期)2024-01-14 06:35:14
上海理工大学学报(2021年3期)2021-07-20 08:04:04
陶瓷学报(2021年1期)2021-04-13 01:33:40
陶瓷学报(2021年1期)2021-04-13 01:32:54
电脑爱好者(2019年2期)2019-10-30 03:45:31
网络安全和信息化(2018年2期)2018-11-09 01:16:18
网络安全和信息化(2017年3期)2017-03-10 07:45:51
网络安全和信息化(2016年8期)2016-11-26 06:42:50
导航定位学报(2015年2期)2015-06-05 09:27:42
项目管理技术(2015年3期)2015-04-23 08:44:29
