
端对端的基于移动嵌入式端的车辆动态实时细粒度分类方法
2017-12-07 07:44林皞张琳
现代计算机 2017年30期
林皞,张琳
(上海海事大学信息工程学院,上海201306)
端对端的基于移动嵌入式端的车辆动态实时细粒度分类方法
林皞,张琳
(上海海事大学信息工程学院,上海201306)
卷积神经网络算法在物体分类与目标识别方面的具有非常好的鲁棒性。提出一种端到端的新型的轻量级卷积神经网络结构,针对目前神经网络进行了结构压缩;一种级联形式多模型联合检测方法,完成小范围的追踪满足实时检测准确度;采用中心对齐的思想来对特征进行一致性统一,大大降低噪声提高检测的准确度。
卷积神经网络;轻量级;级联形式;特征一致性
0 引言
基于图像处理的车辆类型识别技术是智能交通系统(IntelligentTransportSystem,简称ITS)中的一项非常重要的技术,同样在计算机视觉应用领域中占有重要地位。本文提出一种基于手机等移动嵌入式终端的车辆品牌细粒度分类方法;采用基于实时视频流的信息获取方式,实现了自动的进行车辆品牌的识别、包括车型(小轿车,SUV,小货车、客车和货车)生产厂家(宝马,奔驰,大众…)具体型号(宝马 x3,x5,5系,7系,大众 cc,宝来,捷达...)。
现有的车辆类型识别技术中,主要集中于对车辆类型进行分步识别,例如首先对车辆款式进行分类,比如分类为大型、中型及小型三类,或者轿车、货车、客车三类;然后依据车辆品牌类别及年款进行分类,例如大众、宝马、奥迪,依据这些识别结果得出车辆的整体类型信息,例如大众帕萨特2007款,这种车辆类型识别方法操作复杂,计算量大,耗时较长,耗资较高。另外,目前车辆款式的识别方法需要保证车辆整体轮廓的清晰度以便检测车辆的实际尺寸大小,因此该方法较难实现。另外对于现有的车辆类型识别技术,其中多数应用到了传统的特征提取方法,例如梯度方向直方图、局部二值模式纹理,在分析判别时大多采用了支持向量机(SupportVector Machine,简称SVM)方法。这些方法的使用具有局限性,例如在清晰场景下这些方法都有较高的识别率,但是在模糊场景下,例如因天气变化、光线变化所引起的图像模糊、夜间场景等场景下往往识别率较低;另外一般选取车辆的正面图像(车头、车尾)进行品牌识别,由于车辆外观表观形式复杂,因此对所检测的车辆与摄像机的拍摄距离、拍摄角度有着严格的要求。
对于车型识别算法,常用的方法种类比较多,例如基于模板匹配、统计模式等。例如名称为[1]“基于静态图片的自动套牌车检测方法(申请号:201310397152.5)”的中国发明专利申请公开的技术方案”中,提取静态图片中车辆前部图片,确定车头灯、散热器、品牌和保险杠区域;提取车辆图片的特征,并采用随机子空间分类器集成方法合并图片特征;根据车头灯、散热器、品牌和保险杠信息确定车辆品牌。名称为[2]“基于图像的车辆品牌识别方法和系统(申请号:201310416016.6)”的中国发明专利申请公开的技术方案”中,通过检测车牌在输入图像中的位置;根据车牌位置计算多个车辆部件位置;从该多个车辆部件位置的每一个抽取特征向量;以及对所抽取的特征向量进行分类并输出车辆的品牌信息,该特征向量包括外形特征和形状特征。上述车辆品牌型号的识别方法,通过提取车辆的特征进行识别,检测率低误报较多,同时速度慢,无法满足实时要求。
本文主要的研究内容和贡献如下:
(1)针对车脸以及车尾设计出一种新型的轻量级卷积神经网络结构,该模型以完整与部分的车脸与车尾图像作为输入,得到车脸以及车尾的整体特征;在移动手机端以及嵌入式端,在正常光照下,不受复杂的环境的干扰,可对292种常见车型进行端对端实时的细粒度检测与识别;
(2)针对车辆车型识别提出一种级联形式多模型联合检测方法:在一个车辆二分类模型的基础上将二分类模型特征输出结果分别作为车脸模型的输入进行结果的联合判断给出最终结果。
(3)本文采用中心对齐的思想:采用目标检测的方法对训练集中的车辆进行定位之后再裁剪进行训练,在检测端也采用先定位再识别的方法,这样就对输入与输出进行了中心对齐,比原始非对齐的车脸图像识别率高了35%;最终在移动端实时可对292种常见车辆达到89%的识别正确率。
1 一种新型的轻量级多姿态深度卷积神经网络
基于深度卷积神经网络的物体识别方法,因为其识别准确度远远超过传统的基于局部特征的方法,并且鲁棒性很强不受场景等噪声因素变换的影响,在物体识别的方向上慢慢的成为主流。但是神经网络算法的计算量常常需求很大,对硬件的计算能力要求很高;因为在嵌入式以及手机端的硬件与高性能主机相差很大所以网络结构需要适量的修改。
针对车脸以及车尾的图像也使用卷积神经网络来对其提取特征,并提出了一种新型的轻量级深度卷积神经网络结构;本节详细的介绍了这种网络结构的设计以及调参方法。
1.1 网络设计思想
模块的设计思想是将三种经典的网络设计思想进行融合。
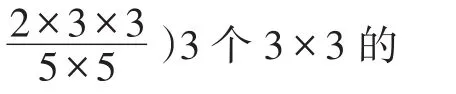
(2)GoogleNet[4]中的 inception Module结构;采用分支结构,通过多尺度的多样化的特征融合;增加了网络对不同尺度的适应性,类似于Multi-Scale的思想。在计算机视觉中,接触对灵长类神经视觉系统的研究,Serre使用不同尺寸的Gabor滤波器处理不同尺寸的图片;inception Module表达能力更强的同时也大大降低参数量以及过拟合的情况。
(3)ResNet[5]中的 ResidualUnit残差结构;
允许原始input信息直接传输到后面的层中;原因是因为在不断加深神经网络的深度时,会出现一个Degradation的问题,及准确率会上升之后然后到达饱和,再持续增加深度则会导致准确率下降;那么后面加上几个y=x的全等映射层,起码误差不会增加;假定神经网络某段结构的输入input为x,期望输出为H(x),如果我们直接把x传到输出作为初始结果,那么此时我们需要学习的目标就是 F(x)=H(x)-x,这就是一个残差学习单元(Residual Unit)及学习的目标改变了,不再是学习一个完整的H(x)而是output与input的差别H(x)-x及残差;传统的卷积层或全连接层在信息传递时,或多或少的存在信息丢失,残差结构保证了信息的完整性同时也简化了训练的难度。
1.2 卷积神经网络模型
网络结构中,主要包含了“input”,“conv”,“BN”,“relu”,“ELU”“pool”,“shortcut”,“linear”,“output”节点。其中“input”与“output”节点代表数据的输入与输出,每一层的开始的“input”代表把上一层的数据作为输入,第一层的输入为原始彩色3通道的车脸与车尾的图像,每一层的“input”节点代表该层数据的输出。“conv”节点代表卷积操作,在卷积操作中,每一个kernel也就是一个卷积核可以提取input的一种特征,多个卷积核可以提取多种特征呢。”BN”节点代表正则化操作,正则操作主要作用是防止“梯度弥散”,将权重分布归一到一个正态分布上,同时可以加快训练的速度,提高模型的精度。“relu”节点代表非线性映射操作,在alexnet诞生之前CNN采用的是sigmoid或tanh函数来做映射,但是relu可以增强稀疏性加速收敛(附图)如果卷积计算的output小于0则等于0,否则保持原来的值不变。“ELU”节点代表另一种非线性操作,但是相对“relu”更加的平滑,可以加速收敛并提高准确度。与“relu”不同的是,ELU拥有负值,允许他们以更低的计算复杂度将平均单位激活推向更加接近0的值;“pool”节点代表池化操作(降采样),主要目的是对卷积特征进行降采样,降低计算的复杂度的同时也降低过拟合的风险,“pool”主要分为两种,最大(max pooling)或平均值(average pooling)池化;“shortcut”节点代表 ResNet里面的残差结构;“linear”节点相当于权重的线性组合起到特征融合的作用与全连接层类似。
该CNN结构总共包含5层,由3个不同的模块组成(如下图所示)

图1
图2 模块1
模块1的设计采用简化版的两种不同的inception modual级联形式;
模块1的input为原图片:3×224×224,进入第一个分支:
左分支:卷积层包含13个kernel,每个kernel为3×3,stride为 2,padding为 1,output:13×112×112;
右分支:一个 2×2的最大池化,output:3×112×112;
Join:进行通道数的合并输出:16×112×112;
进过BN正则化以及relu非线性变换之后进入第二个分支:
左分支:第一个卷积层包含32个kernel,每个kernel为 3×3,stride为 2,padding为 1,output:32×56×56;进过BN正则化以及relu非线性变换之后,直连第二个卷积层包含 32个 kernel,每个 kernel为 3×3,stride为 1,padding为 1,output:32×56×56(使得特征的学习能力更强)。
右分支:卷积层包含32个kernel,每个kernel为1×1,stride为 2,output:32×56×56;
add:维度上进行累加;之后进行relu变换output:32×56×56。

图3 模块2
模块2的设计采用ResNet中的Residual Unit残差单元:
Input为模块 1的 output:32×56×56;
第一个卷积层包含32个kernel,每个kernel为3×3,stride为 1,padding为 1,output:32×56×56
第一个卷积层包含32个kernel,每个kernel为3×3,stride为 1,padding为 1,output:32×56×56;残差模块为 32×56×56;output:32×56×56。下面是 6个模块 2的直连最终的 output:32×56×56。

图4 模块3
模块3的设计采用Inception Modual与Residual Unit相结合的级联模式:
第一个分支:(Inception Modual)
Input为第二层的 output:32×56×56;
左分支:第一个卷积层包含64个kernel,每个kernel为 3*3,stride为 2,padding为 1,output:64×28×28
第二个卷积层包含64个kernel,每个kernel为3×3,stride为 1,padding为 1,output:64×28×28。
这里使用了ELU代替relu作为激活函数。
右分支:卷积层包含64个kernel,每个kernel为1×1,stride为2(这里使用不同的卷积核提取特征之后加以融合,丰富特征的多样性)output:64×28×28。
第二个分支:(ResidualUnit)
Input:64×28×28
第一个卷积层包含64个kernel,每个kernel为3×3,stride为 1,padding为 1,output:64×28×28
第二个卷积层包含64个kernel,每个kernel为3×3,stride为 1,padding为 1,output:64×28×28,残差模块:64×28×28,output:64×28×28,下面直连 5个模块 2,最终 output:64×28×28。

图5 模块4
模块4的设计在模块2与模块3的基础上加上了最终的输出处理:
第一个部分结构为模块3,第二部分为模块2,区别在于将relu激活函数替换成了ELU激活函数。Input为第三层的 output:64×28×28。
进入模块3 Inception结构:左分支:第一个卷积层包含 128个 kernel,每个 kernel为 3×3,stride为 2,pad-ding为 1,output:128×14×14第二个卷积层包含 128个kernel,每个 kernel为 3×3,stride为 1,padding为 1,output:128×14×14。右分支:卷积层包含 128个 kernel,每个 kernel为 1×1,stride为 2,output:128×14×14;
进入模块 3 Residual Unit结构:input:128×14×14,第一个卷积层包含128个kernel,每个kernel为3×3,stride为 2,padding为 1,output:128×7×7;
进入模块 2结构:input:128×7×7;第一个卷积层包含 128个 kernel,每个 kernel为 3×3,stride为 1,padding为 1,output:128×7×7;avgpool层 stride为 7×7,output:128×1×1;linear层 output:128×1×1,最终经过 softmax输出长度为292的向量。
此网络结构经过层层的多样化的特征提取以及特征融合,最终将车脸图片从224×224变为7×7的大小,相当于原始图像的1/32;训练集拥有13w张292类不同角度的车脸图像,验证集为4w张292类不同角度的车脸图像,准确度Top5_accuracy为97%,Top_1_accuracy为91%;模型大小为6.8MB。
结构中的参数都是基于大量的实验得出的,其中最重要的是每一层中卷积核的个数,在调试参数的过程,具体参数可通过可视化模型来调整。可视化是指将不直观的层与层变换后的结果参数转化为直观的数字图像。
数据流是指图像数据在CNN结构中的流动状态,在本网络中数据主要经过卷积和池化以及Inception Modual的concat,Residual Unit残差融合四种操作。观察数据流可视化的结果可调整模型中feature map的数量,如果发现数据流可视化结果中有大量相似或者无意义的图像,说明feature map数量太多,这时候应当减少filter的个数,如果发现数据流可视化结果中的图像都各不相同,这时候可适当的増加feature map的个数,直到选出满足的参数。
Feature maps代表对图像提取特征,一个filter代表对图像提取一种特征,多个Feature maps代表对图像提取多个特征。低层的Feature maps代表边缘,纹理,颜色等基础局部特征,高层的Feature maps代表抽象之后的全局特征,在Feature maps可视化的结果中,有些核会表示成特别有意义的图案,例如横线、竖线、曲线,边缘轮廓,线面组合等,如果在可视化卷积的结果中没有发现含有明显图案的图像,说明CNN结构设计不够完善,可适当调整CNN结构组成例如添加Inception结构增加特征提取的多样化从而增强模型的表述能力。
1.3 数据可视化
由于网络相对复杂只提取一部分进行说明:

图6 CNN模型输入

图7 模块1的第一个卷积层的结果
将图1作为CNN模型的输入。该CNN结构第一层卷积有13个filters,所以原始输入图片对应13个feature maps,并且13个feature maps都各不相同,说明CNN训练得到的13个核提取的特征都各不相同,有些核提取的横的边缘,有些filter提取边缘,有些filter分割背景。

图8 为第一层模块1第二个分支中第一个卷积结果
该卷积层具有32个filters,32个feature maps各不相同,相比于第一个分支中的结果更加的抽象且有代表性
2 级联形式多模型联合检测方法
本文提出一种级联形式的多模型联合检测方法:通过目标检测模型(本文使用tiny-yolo)对目标进行定位并将定位之后裁剪的图像送入上文中分类网络进行识别。
图10
训练集使用tiny-yolo[6]进行预处理;对于视频动态实时检测与静态图片检测最大的区别在于镜头捕捉远近以及采集器抖动的情况,这对于分类模型的影响是巨大的;在检测时使用tiny-yolo进行目标定位是为了统一与训练集的特征标准做到图像的中心对齐,这样可与将抖动以及镜头远近的情况通过定位的方式解决;同时也使得待检测目标填充整张图片,大大地降低背景以及干扰物的噪声。

图5 为未经裁剪的图像

图6 为tiny-yolo裁剪过后的图像
3 统一特征标准级联模型有效性实验
使用tiny-yolo统一训练集与测试集的标准之后,分别对20000帧实时车脸街拍视频进行了测试准确度有接近38%的提升。
3.1 实验目的
证明图像对齐操作能提高最后分类正确率。正确分类是指目标图像中的车脸识别为正确的车型,错误分类是指目惊图像中的车脸识别为其他车型。
3.2 实验方案
同时对各种经典卷积神经网络算法进行了对比,测试框架为tensorflow1.0,测试硬件平台为iPhone6。对齐方式采用tiny-yolo进行裁剪对齐,EasyNet为本文介绍的轻型CNN模型;
实验1:将非对齐数据和对齐数据输入inceptionV1模型比较分类正确率Top5_error与Top5_error1以及单帧时间
实验2:将非对齐数据和对齐数据输入vgg16模型比较分类正确率Top5_error与Top5_error1以及单帧时间
实验3:将非对齐数据和对齐数据输入EasyNet模型比较分类正确率Top5_error与Top5_error1以及单帧时间
3.4 实验结果
从表1中可以看出,对于实时街拍车脸视频,对齐后的数据比不对齐的数据分类器得到的准确率至少高将近35%。证明车脸对齐操作对分类正确率有着至关重要的作用。
实时性以及模型大小也是本文考虑因素之一。
Tiny_yolo+EasyNet的级联网络联合识别在20000帧实时车脸街拍视频上的表现,Top5_error为94%,Top_1_erro为89%,单帧时间为0.69s;
在50000张静态各个角度的292类车脸测试图片上的表现 Top5_accuracy为 96%,Top_1_accuracy为90%;
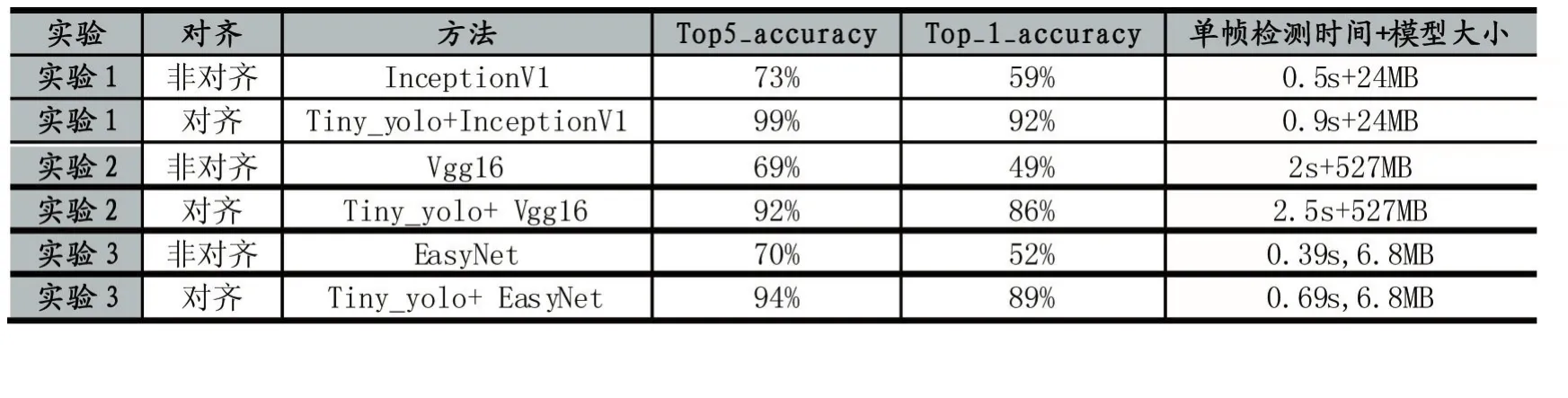
表1
模型大小为6.8MB满足手机等嵌入式存储环境。
4 结语
本文主要介绍了实时动态基于轻量级多姿态的卷积神经网络的车脸识别方法;动态视频识别检测的难点在于采集器采集图像的远近以及抖动情况会对卷积神经网络的识别产生较大的影响,本位采用定位加识别的方法对动态视频图像进行统一化处理,将其与训练集进行对齐大大的改善了动态识别的精度;同时也提出一种轻量级多姿态的卷积神经网络EasyNet满足实时性、准确性以及嵌入式硬件需求。
[1]张百灵,周逸凡,管文杰.基于静态图片的自动套牌车检测方法:,CN 103679191 A[P].2014.
[2]朱珑,林晨曦,陈远浩,等.基于图像的车辆品牌识别方法和系统:,CN 103488973 A[P].2014.
[3]Simonyan K,Zisserman A.Very Deep ConvolutionalNetworks for Large-Scale Image Recognition[J].Computer Science,2014.
[4]Szegedy C,Liu W,Jia Y,etal.Going deeper with convolutions[J].2014:1-9.
[5]He K,Zhang X,Ren S,etal.Deep ResidualLearning for Image Recognition[C].Computer Vision and Pattern Recognition.IEEE,2016:770-778.
[6]Redmon J,FarhadiA.YOLO9000:Better,Faster,Stronger[J],2016.
End to End Vehicle Real-Time Fine-Grained Identification Method Based on Mobile and Embedded System
LIN Hao,ZHANG Lin
(College of Information Engineering,Shanghai Maritime University,Shanghai 201306)
Convolution neural network algorithm has very good robustness in classification and object detection.Presents a new lightweight end to end convolutional neural network structure that compress the structure;A cascade multiple joint detection method,uses small scales tracking to improve real-time detection accuracy;uses the center alignment to uniform feature,greatly reduces the noise and improve the detection accuracy.
Convolution NeuralNetwork;Lightweight;Cascade;Uniform Feature
1007-1423(2017)30-0012-07
10.3969/j.issn.1007-1423.2017.30.003
2017-05-02
2017-09-10
猜你喜欢
现代电力(2022年2期)2022-05-23
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机系统应用(2021年10期)2022-01-06
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年19期)2019-11-23
学生天地(2019年28期)2019-08-25
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
北京航空航天大学学报(2018年1期)2018-04-20
