
基于十字链表与三元组表的稀疏矩阵压缩存储实例研究
2017-12-02 17:12周张兰
软件导刊 2017年11期
周张兰


摘要:十字链表和带行链接信息的三元组表是稀疏矩阵的两种压缩存储方法。十字链表为链式存储结构,带行链接信息的三元组表为顺序存储结构。在MovieLens数据集上设计了分别采用十字链表和带行链接信息的三元组表对以用户为行、项目为列、用户评分为矩阵元的稀疏矩阵进行压缩存储,并在这两种存储结构上实现用户相似度计算算法。通过测试分析和比较了两种不同的压缩存储方法在创建及相似度计算上的执行效率,并探讨了各自的特点及适用条件。
关键词关键词:稀疏矩阵;十字链表;三元组表;压缩存储
DOIDOI:10.11907/rjdk.171845
中图分类号:TP302
文献标识码:A文章编号文章编号:16727800(2017)011002204
0引言
矩阵是科学与工程计算问题中研究的数学对象。在高阶矩阵中,可能存在很多相同值或零值的矩阵元,对这些矩阵元的存储造成存储空间的浪费。因此,可以对矩阵进行压缩存储,以节省存储空间,达到提高存储利用率的目的。在算法实现中,选择的存储结构不同,执行效率也将不同。对不同矩阵存储方法的特点进行分析和比较,有助于根据不同的实际应用,有针对性地选择更为合适的存储结构,以此提高矩阵运算及其它相关操作的运行效率。
1稀疏矩阵及存储
若一个m行n列矩阵中的零元素有t个,零元素个数t与矩阵元总数m×n的比值称为稀疏因子,一般认为若稀疏因子不大于0.05,则此矩阵为稀疏矩阵。设矩阵有10行10列,即总共100个元素,若其中零元素有95个,而非零元素仅有5个,则此矩阵为稀疏矩阵。在存储稀疏矩阵时,可以采用非压缩存储和压缩存储两种方式。非压缩存储使用二维数组,比如,设10行10列的稀疏矩阵M的矩阵元均为整数,则可以使用二维数组存储该矩阵M,数组的定义用C语言[1]描述如下:
int a[10][10];
其中,a[0][0]代表稀疏矩阵M第1行第1列元素,a[i][j]代表第i+1行第j+1列元素。由于数组是从下标0开始,因此使用二维数组时下标与逻辑上的行号和列号相差1。为了操作方便,也可以从a[1][1]开始存储第1行第1列元素,即定义为:
int a[11][11];
这种定义方式可以使逻辑上的行、列号与二维数组的下标保持一致,采用这种方式存储矩阵时所需存储空间要求更大。
从操作上看,二维数组的非压缩存储方式按行和列存取数据元素非常方便。然而,在稀疏矩阵中,大量零元素的存储不仅会浪费存储空间,而且与零元素相关的运算也会在一定程度上降低计算总体效率。因此,在实际应用中,对稀疏矩阵进行压缩存储很有必要。压缩存储只存储非零矩阵元,有顺序存储和非顺序存储两种。其中,顺序存储可使用带行链接信息的三元组表,而非顺序存储可采用十字链表。
2压缩存储
2.1三元组及表示
压缩存储只存储矩阵中的非零元。在矩阵中,除了存储非零元素的值,还要存储该元素所在的行号和列号。三元组表示法以(行号,列号,值)形式存储矩阵中的一个非零元素,比如,(1,1,5)表示第1行第1列元素值为5。设矩阵元素值的类型为ElemType,则存储一个非零元三元组的结构体类型定义用C语言描述如下:
struct Triple{
int i,j;
ElemType e;
};
三元组可存储稀疏矩阵中所有非零元的值及其行、列号。但是,从三元组中不能得到整个稀疏矩阵行数、列数及非零元个数等信息。因此,还要对存储整个稀疏矩阵的三元组表进行定义。带行链接信息的三元组表又称为行逻辑链接顺序表[2],其结构体类型定义用C语言描述如下:
struct TripleMatrix{
struct Triple *data;
int *rops;
int m,n,t;
};
其中,以三元組形式表示的非零元存储在数组data[]中,每行的第1个非零元在三元组表中的起始位置存放在数组rops[]中,两个数组的存储空间在初始化时分配。m、n、t分别代表稀疏矩阵的行数、列数和非零元个数。
2.2十字链表及表示
十字链表是稀疏矩阵的链式存储结构。十字链表对矩阵的每一行建立一个链表,行链表的头指针存放在其对应行的一维数组中。同样,为矩阵的每一列建立一个链表,列链表的头指针也存放在其对应列的一维数组中。为了实现十字链表,首先将需要存储的非零元素封装成一个结点。其中,结点包含5个域,除了行号、列号和值3个数据域外,还有两个指针域,分别指向该元素所在行及所在列的下一个非零元素。设稀疏矩阵的数据元素类型为ElemType,则十字链表中存储非零元素结点的结构体类型定义如下:
struct CrossLNode{
int i,j;
ElemType e;
struct CrossLNode *rownext, *colnext;
};
其中,rownext和colnext指针分别指向该元素所在行和所在列的下一个非零元素。对整个稀疏矩阵而言,除了存储非零元,还要记录整个矩阵的行数、列数和非零元个数以及两个分别存储所有行链表和列链表头指针的一维数组。因此,十字链表的结构体类型定义如下:
struct CrossLinkList{
struct CrossLNode *rowhead, *columnhead;
int m, n, t;
};
在十字链表定义中,m、n、t分别代表稀疏矩阵的行数、列数和非零元素个数。rowhead和columnhead指针分别指向存储所有行链表头指针和所有列链表头指针的一维数组的首地址。endprint
3实例测试
3.1数据集
协同过滤推荐[36]是一种广泛使用的推荐方法,传统的协同过滤推荐算法不依赖于推荐内容本身,而根据用户对项目的评分产生推荐。其中,用户对项目的评分可以看作是一个以用户为行、项目为列的矩阵,矩阵元aij表示用户i对项目j的评分。在实际应用中,用户有兴趣并且产生评分的项目相对于所有项目而言极其有限。因此,用户项目评分矩阵往往是一个稀疏矩阵。借助协同过滤推荐中常用的MovieLens[7]数据集作为数据对象,通过计算用户相似度,分析、对比分别采用带行链接信息的三元组表和十字链表对稀疏矩阵进行压缩存储时各自的执行效率。
本文使用的MovieLens数据集中,用户数943个、项目数1 682个。用户评分记录包括:用户号、项目号、评分和时间戳。其中,训练集有u1.base、u2.base、u3.base、u4.base和u5.base 5个数据文件,每个文件中评分记录为80 000条,每一条评分记录以(user_id,item_id,rating,timestamp)的形式存储。分析此数据可以得出,以用户对项目评分为矩阵元的矩阵稀疏因子为80 000/(943×1 682)≈0.05,即此矩阵可认为是一个稀疏矩阵。
3.2算法设计
在基于用户的协同过滤推荐中,首先利用评分矩阵计算用户与用户之间的相似度,从而产生目标用户的近邻,再利用这些用户近邻对目标用户未评分项目进行评分预测,最后根据预测评分的高低向目标用户推荐。用户相似度计算是基于用户的协同过滤推荐算法的重要步骤,本文采用余弦相似度计算用户之间的相似度值。为了比较带行链接信息的三元组表和十字链表压缩存储效率,分别在这两种存储结构上设计和实现用户相似度计算算法并进行了测试。
(1)带行链接信息的三元组表测试算法。采用带行链接信息的三元组表压缩存储评分矩阵并计算用户相似度的算法步骤如下:首先,初始化TripleMatrix类型的带行链接信息的三元组表M;然后,创建带行链接信息的三元组表M。读入评分记录文件u1.base,将其中每一条评分记录的行号、列号和值依次存储到M.data中;再计算用户之间的相似度,根据余弦相似度计算公式利用行链接信息M.rpos在三元组表中读取所需用户评分,并计算有共同评分的用户之间的相似度值;最后,重复以上步骤分别测试u2.base、u3.base、u4.base和u5.base 4个数据文件。
(2)十字链表测试算法。采用十字链表存储评分矩阵并计算用户相似度的算法步骤与带行链接信息的三元组表类似,但由于该方法采用链式存储结构,因此在算法实现上主要是指针操作。首先,初始化并创建CrossLinkList类型的十字链表T;然后,读入评分记录文件u1.base,每读取一条记录,用malloc动态申请一个CrossLNode类型的节点,并存储相应的行、列和值,同时将该结点挂到其行所在的链表及其列所在的链表中;接着,计算用户之间的相似度,根据余弦相似度计算公式在创建的十字链表中读取所需节点的用户评分,并计算有共同评分的用户之间的相似度值;最后,重复以上步骤分别测试u2.base、u3.base、u4.base和u5.base 4个数据文件。
3.3运行测试
在配置为处理器Inter(R) Core(TM) i54210,内存4G,64位操作系统的电脑上使用visual C++6.0编程并运行测试。测试中,使用计时函数clock()计算运行时间。由于在不同时刻运行程序,计算的运行时间会有所偏差,为此将每个数据文件连续运行5次,取平均值作为最终执行时间。用训练数据集u1至u5分别测试两种存储结构。其中,创建十字链表和带行链接信息的三元组表所需时间如图1所示,计算用户相似度的运行时间如图2所示,创建并计算总执行时间如图3所示。
3.4结果分析
由图1可知,创建十字链表所用时间大于带行链接信息的三元组表用时。分析十字链表创建过程可知,每读入一条评分记录,动态申请一个结点的存储单元,不仅要将评分存储到结点中,还需要将该节点插入到其所在行和所在列的链表中。相对于直接加到表尾的三元组表存储的顺序存储而言所需时间要多。当然,由于在MovieLens数据集中,所有评分记录已按行和列从小到大顺序排序,因此當结点插入时只需要插入到所在行和列链表的表尾即可。但是若输入的评分记录没有按行和列排序,在创建十字链表时还需要从行或列的第一个结点开始查找合适的插入位置,再实现节点插入。这样所需运行时间更多,实际测试发现,其平均运行时间要多近3倍。若采用三元组表存储,在创建时需对记录进行按行和列排序,插入节点时还要为空出插入位置而移动元素,则所需创建时间会更多。
当非零元素分别以十字链表和三元组表存储,采用余弦相似度计算方法计算所有用户之间的相似度。其中,三元组表采用行逻辑连接的顺序表,可按行访问。从图2中得到,使用十字链表计算相似度所需时间小于采用三元组表存储用时。这说明,当十字链表和带行链接信息的三元组表创建后,在同等条件下计算用户相似度时,十字链表访问数据元素并实现计算的效率要比三元组表高。从总运行时间看,十字链表虽然在创建用时比三元组表要多,但由于计算相似度所用时间少,因此总执行时间要比三元组表少,两者总运行时间对比如图3所示。
将十字链表、带行链接信息的三元组表和非压缩的二维数组的创建和计算相似度的总运行时间进行比较,三者的总运行时间如表1所示。可以看出,无论是十字链表还是带行链接信息的三元组表,在压缩后由于去掉了大量零元素运算,因此所需运行时间均大幅减少,运行效率明显提高。
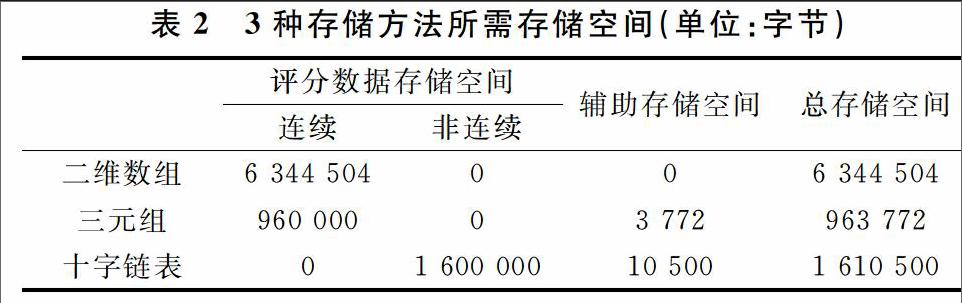
在存储空间方面,使用非压缩的二维数组、压缩的十字链表和带行链接信息的三元组表所需存储空间如表2所示。表中数据以943个用户、1 682个项目,形成943行1 682列的稀疏矩阵的数据集为例,其中,评分记录为80 000条。从表中结果可知,二维数组所需存储空间最多,总共需要943*1 682*4=6 344 504个字节,而且必须是连续的存储单元。十字链表所需存储空间其次,其中包含存储非零元的非连续存储空间80 000*20=1 600 000个字节,存储十字链表所有行链表头指针的连续存储空间943*4=3 772个字节和存储所有列链表头指针的连续存储空间1 682*4=6 728个字节,即十字链表总存储空间为1 610 500个字节。带行链接信息的三元组表所需存储空间最少,其中存储矩阵非零元的连续存储空间80 000*12=960 000个字节,存储每行在三元组表中起始位置的连续的存储空间943*4=3 772个字节,即总共需要963 772个字节的存储空间。另外,在三元组表和十字链表中还需要存储矩阵行数、列数和非零元个数等其它少量的辅助存储空间。endprint
測试发现,无论使用十字链表还是带行链接信息的三元组表对稀疏矩阵进行压缩存储,由于只需存储非零元素,因此对存储空间的压缩效果明显,尤其是带行链接信息的三元组表,所需存储空间较少。然而,由于三元组是顺序存储的,因此,存储空间必须是连续的存储单元。相对于带行链接信息的三元组表,十字链表所需存储空间更多,但所需连续存储空间少,因为存储非零元素的存储空间是动态申请的,因此不必是连续的存储单元。
从用户相似度的运行时间上看,相比非压缩的二维数组存储方法,利用十字链表和带行链接信息的三元组表压缩存储后计算所需运行时间较少。这是因为省略了对大量零元素的存储,同时也就免除了大量有关零元素的运算,而这些针对零元素的运算在余弦相似度计算中并无必要。因此,经过压缩存储后,对程序运行时间的提高也有很大帮助。在本例测试中,十字链表比带行链接信息的三元组表的创建所用时间多,但是在计算相似度时所用时间要少,而总运行时间优于三元组表存储方法。这是由于十字链表虽然采用链式存储结构,但可以按行和列访问矩阵元,而在行逻辑链接的三元组顺序表中,虽然每行的第一个非零元素的起始位置已存储,也可以实现按行访问,但在本例中所用时间还是比十字链表略多。
4结语
测试分析表明,十字链表和带行链接信息的三元组表都可以较好地实现对稀疏矩阵的压缩存储,并且在运行时间和存储空间上比非压缩存储效率均有明显提高。在运行时间方面,若输入数据已按行和列排序,在创建时只需在表尾插入,则三元组表的顺序存储结构所用创建时间比十字链表少。然而,创建时若输入数据没有经过排序处理,则十字链表的结点插入需要先找到插入位置。同样,带行链接信息的三元组表需为待插入元素空出位置而移动元素,两者在创建上的运行时间都将比非压缩的二维数组多。运算时间上,本例中十字链表按行访问并完成相似度计算的运行时间比带行链接信息的三元组表要少。由于十字链表顺序存储了行链表和列链表的头指针,相比仅按行访问的带行链接信息的三元组表,十字链表不仅可以按行访问,还可以根据需要按列访问,使用更加灵活。在存储空间方面,三元组表的顺序存储结构所需存储空间较少,但要求存储单元必须连续,而且容量固定,不易扩充。十字链表中非零元的存储单元是动态申请的,需要的连续存储空间较少,同时插入、删除操作灵活,可以很好地适应数据变化。
基于十字链表和三元组表的稀疏矩阵压缩存储特点及用户相似度计算效率的对比与分析表明,这两种对稀疏矩阵压缩存储的方法各有所长,在实际应用中可依据对数据的存储容量和操作特点选择更为合适的存储结构,从而实现计算效率最优化。
参考文献参考文献:
[1]谭浩强.C语言程序设计[M].第2版.北京:清华大学出版社,1999.
[2]严蔚敏,吴伟民.数据结构(C语言版)[M].北京:清华大学出版社,2007.
[3]GOLDBERG D,NICHOLS D,OKI B M,et al. Using collaborative filtering to weave an information tapestry[J]. Comm ACM,1992,35(12):6170.
[4]KONSTAN J A,MILLER B N,MALTZ D,et al.GroupLens: applying collaborative filtering to usenet news[J]. Comm ACM,1997,40(3):7787.
[5]LINDEN G,SMITH B,YORK J.Amazon.com recommendations: itemtoitem collaborative filtering[J]. IEEE Internet Computing,2003,7(l):7680.
[6]SCHAFER J,KONSTAN J,RIEDLL J.Recommender systems in Ecommerce[C].Proc ACM ECommerce,1999:158166.
[7]MovieLens[EB/OL].http://grouplens.org/datasets/.
责任编辑(责任编辑:孙娟)endprint
