
基于属性相似度的恶意代码检测方法*
2017-11-14 08:20:15张福勇东莞理工学院计算机与网络安全学院广东东莞523808
沈阳工业大学学报 2017年6期
张福勇, 秦 勇(东莞理工学院 计算机与网络安全学院, 广东 东莞 523808)
基于属性相似度的恶意代码检测方法*
张福勇, 秦 勇
(东莞理工学院 计算机与网络安全学院, 广东 东莞 523808)
针对未知恶意代码数量急剧增长,现有的检测方法不能有效检测的问题,提出一种基于属性相似度的恶意代码检测方法.该方法将样本文件转换成十六进制格式,提取样本文件的所有n-gram,计算每个n-gram的信息增益,并选择具有最大信息增益的N个n-gram作为特征属性,分别计算恶意代码和正常文件每一维属性的平均值,通过比较待测样本属性与恶意代码和正常文件两类别属性均值的相似度来判断待测样本类别.结果表明,该方法对未知恶意代码的检测性能优于基于n-gram的恶意代码检测方法.
恶意代码检测; 属性相似度; 网络与信息安全; 入侵检测; 数据挖掘; 机器学习; 未知恶意代码; 静态分析
据Symantec 2016年6月公布的数据称:2015年新增恶意代码数量为4.3亿,较2014年的3.17亿增加了36%,恶意代码总数目前已超过21亿,并且其正朝着顽固化、隐匿化的方向发展,攻击更加精准隐蔽,造成的损失也更加严重[1].2015年发现并报告的9次大型数据泄露事故中,总计4.29亿条身份信息遭遇曝光,规模最大的一项事故已经造成1.91亿条记录外泄[1].
恶意代码的数量继续呈高速增长的态势,其危害已渗透到社会生活的很多方面,给经济生活造成了诸多不便及巨大的损失.但目前的商业化安全防护软件仍是以特征码检测为主,这种方法仅能识别已知恶意代码,而且随着恶意代码数量的急剧增长,特征码库日趋臃肿,检测效率越来越低.虽然一些商业化安全防护软件开始加入了基于代码行为分析的检测方法,但这些方法仅通过对系统中文件、注册表等行为的监控来发现未知恶意代码,对未知恶意代码的检测率较低(仅为50%~80%).
目前,机器学习技术已经被广泛应用在恶意代码检测领域[2-3].很多研究人员通过分析恶意代码与正常文件的静态特征差异来检测恶意代码.如Ding等人[4]通过对恶意代码二进制文件样本进行反汇编,从汇编代码中得到API调用序列,并采用基于目标导向的关联挖掘算法对API调用序列建模,从而实现恶意代码的检测;Sheen等人[5]提出一种基于和声搜索的恶意代码检测方法,该方法采用静态API特征和PE文件特征来检测恶意代码;Shamsul等人[6]提出一种支持向量机包装和过滤相结合的恶意代码检测框架,该框架通过统计分析API调用实现恶意代码检测;Cesare等人[7]通过恶意代码中包含的一系列控制流图来描述恶意代码特征,并提出基于字符串特征向量间距的距离度量方法,采用特征向量的最小匹配距离来识别恶意代码;Zhao等人[8]提出采用静态操作码特征来检测恶意代码;另外,还有提取样本文件的n-gram字节特征检测方法[9-11],通过挖掘PE文件静态格式信息实现恶意代码检测的方法[12]及多特征结合的检测方法等[13-14].
本文提出一种基于属性相似度的恶意代码检测方法(MDMAS),该方法首先提取训练数据的特征属性,生成特征向量,并分别计算两个类别各维度属性的平均值,然后根据属性的平均值计算测试样本与训练数据的属性相似度,最后根据属性相似度的大小判断其所属类别.实验结果表明,该方法可有效检测未知恶意代码,检测性能优于Jeremy等人[9]提出的基于n-gram字节的恶意代码检测方法.
1 基于属性相似度的检测方法
本文提出的基于属性相似度的恶意代码检测方法假设如下:恶意代码和正常文件存在某些差异特征,且可以提取这些差异特征,并通过判断待测样本与这两个类别特征属性的相似度来识别恶意代码.识别过程需要两个主要步骤:特征提取和属性相似度计算.
1.1 特征提取
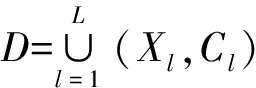
本文采用Jeremy等人[9]提出的基于n-gram字节的特征提取方法,该方法计算训练数据每个n-gram字节的信息增益,并选择信息增益最大的N个n-gram作为分类特征.
对于一个n-gram特征属性T,其信息增益IG(T)的计算公式为
IG(T)=H(C)-H(C|T)
(1)
式中:H(C)为类别C的熵;H(C|T)为属性为T时类别C的条件熵.假设类别C有n个不同取值C1,C2,…,Cn,则H(C)的计算公式为
(2)
式中,P(Ci)为Ci出现的概率.H(C|T)的计算公式为
(3)
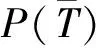
特征向量的生成步骤如下:
1) 提取所有训练样本的n-gram,这里n-gram指的是将样本文件转换成十六进制后的连续n个字节.假设n=3,一个样本文件转换成十六进制后的字节序列为:25 50 44 46 2D 31,则该文件的3-gram为:255044,504446,44462D,462D31.
2) 计算每个n-gram的信息增益,并将其按信息增益由大到小排序.
3) 选择排序后的前N个n-gram作为分类特征,比较样本文件是否存在这N个n-gram,如果存在,则对应属性值为1,否则为0,最终得到一个N维特征向量.例如,取N=10,最终得到的N维向量的形式为(1,0,1,1,1,0,0,0,1,1).
1.2 属性相似度计算
属性相似度计算分为3个步骤,具体过程如下:
1) 分别对两个类别训练数据的每一维属性取平均值.恶意代码类别得到平均值M={m1,m2,…,mN},正常代码类别得到平均值B={b1,b2,…,bN}.假设恶意代码类别有3个训练样本,特征向量分别为:(0,0,0,0,0,0,0,0,1,1),(0,0,0,0,0,0,0,0,0,1)和(0,0,0,0,0,0,0,0,1,0);正常代码类别也有三个训练样本,特性向量分别为:(1,1,1,1,1,1,1,1,0,0),(1,1,1,1,1,1,1,1,1,0)和(1,1,1,1,1,1,1,1,0,1),则恶意代码类别的平均值向量为:(0,0,0,0,0,0,0,0,0.67,0.67),正常代码类别的平均值向量为:(1,1,1,1,1,1,1,1,0.33,0.33).
2) 计算待测样本与这两个类别平均值向量的属性相似度.设待测样本的特征向量为(u1,u2,…,uN),属性相似度计算方法为:
如果|ui-mi|<|ui-bi|(其中,ui为待测样本的第i个属性值;mi为恶意代码类别平均值第i个属性值;bi为正常代码类别平均值第i个属性值),则待测样本的第i个属性与M相似.
如果|ui-mi|=|ui-bi|,则待测样本的第i个属性不与任何类别相似.
如果|ui-mi|>|ui-bi|,则待测样本的第i个属性与B相似.
3) 比较待测样本与两个类别相似属性的个数,待测样本的类别与相似属性多的类别一致.若与两个类别的相似属性个数相同,则采用决策树方法判断其类别.
2 实验数据及结果分析
2.1 实验数据集
为了更好地验证所提方法的有效性,本文采用两组实验数据.第1组数据中的恶意代码为2014年间收集的样本,用作训练数据;第2组数据中的恶意代码为2015年间收集的样本,作为测试数据,用于检验方法对未知恶意代码的检测性能,并评估相关参数对检测结果的影响.所有的正常文件样本均来自Windows XP系统文件,且两组实验数据均没有重复.第1组数据的信息如表1所示,第2种数据的信息如表2所示,所有数据均为Win32 PE格式.
综合考虑样本训练过程中的计算复杂度及检测性能,本文选取n=3,即提取样本文件的3-gram计算信息增益.采用第1组数据作为训练数据,共提取互不相同的3-gram数量为376 942.
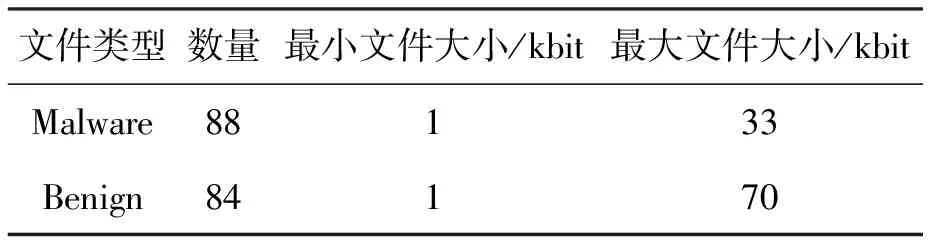
表1 第1组实验数据Tab.1 First set of experimental data
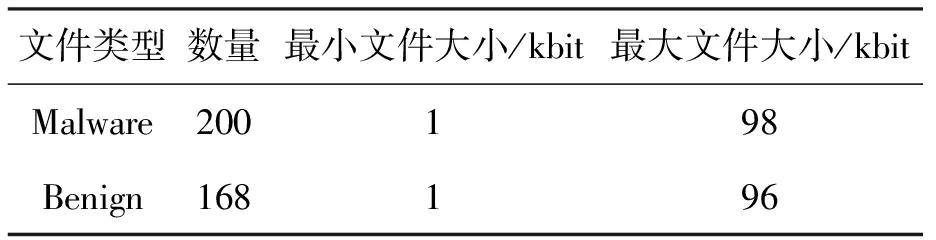
表2 第2组实验数据Tab.2 Second set of experimental data
2.2 参数N的敏感性分析
本节采用第2组数据作为测试数据,验证所提方法的有效性,并评估算法中仅剩的可变参数N对检测性能的影响.图1显示了N取值范围为100~1 000时的分类准确率情况.从图1可以看出,N取不同值时,分类准确率有一定的波动,但波动不大,分类准确率范围在91.3%~93.48%之间,而且N取值在100~500时的分类准确率要高于N取值在600~1 000的范围,这说明对MDMAS方法而言,分类准确率不会随着N取值的增加而提高.由图1中结果可以看出,N的最佳取值范围应该在100~500之间.
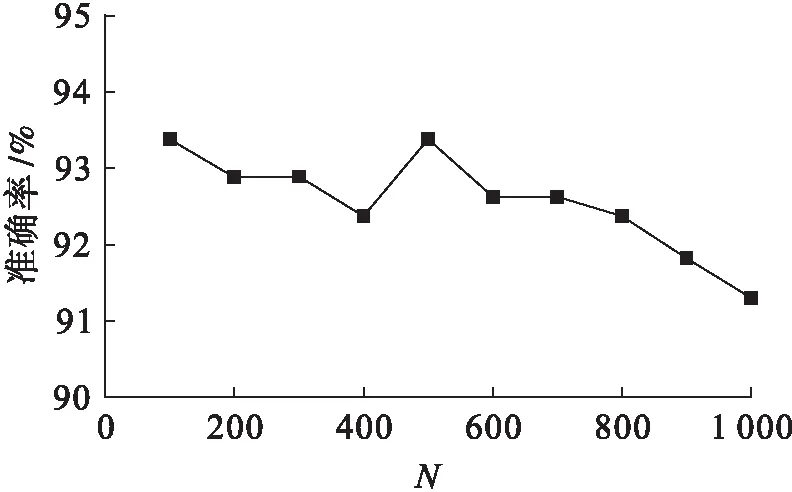
图1 N对分类准确率的影响Fig.1 Effect of N on classification accuracy
图2给出了N取值范围为100~1 000时的检测率情况.由图2可以看出,N取值对检测率的影响要大于对分类准确率的影响,检测率的波动范围为92%~97.5%,尤其是当N取值大于600时,检测率呈明显下降趋势.另外,与N对分类准确率的影响情况类似,N取值范围为100~500时的检测率要明显高于取值范围为600~1 000的情况.N取值范围为100~500时,检测率的波动范围为96.5%~97.5%,分类准确率的波动范围为92.39%~93.48%,浮动范围均约为1%,相对比较平稳.从分析结果可知,N的最佳取值范围为100~500,而且在这个取值范围内对检测性能的影响不大.
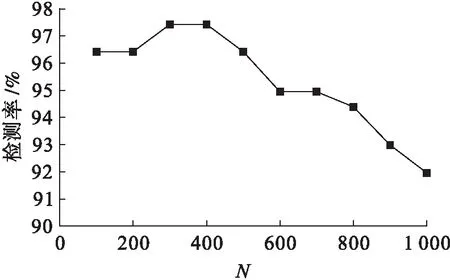
图2 N对检测率的影响Fig.2 Effect of N on detection rate
2.3 不同算法实验结果比较与分析
为验证所提方法的检测性能,将MDMAS算法与基于Jeremy的n-gram字节恶意代码检测方法[7]进行比较.其中Jeremy方法中包括朴素贝叶斯(naïve bayes,NB)、贝叶斯网络(bayesian networks,BN)、支持向量机(support vector machine,SVM)和C4.5决策树(C4.5 decision tree,DT)4种分类算法.实验中这4种方法分别采用WEKA平台[15]的Naïve Bayes、BayesNet、SMO和J48实现,并且都采用WEKA平台的默认参数.
比较实验采用第1组数据作为训练数据,第2组数据作为测试数据,用于测试几种方法对未知恶意代码的检测性能.图3给出了N取值范围为100~1 000时5种方法的分类准确率情况.可以看出MDMAS算法的分类准确率都优于其他方法,而且对其他4种方法而言,N取值在100~500之间的结果也优于N取值在500~1 000之间的结果,这个结论与之前对MDMAS算法分析得出的结论是一致的.
图4给出了N取值范围为100~1 000时5种方法的检测率情况,跟分类准确率相比,MDMAS算法在检测率上的优势更加明显.同样N取值在100~500之间的结果整体上也较N取值在500~1 000之间的结果要好.表3所列实验结果为N取值分别为100、200、300、400和500时,不同算法检测率和准确率的平均值.从表3的结果也可以更直观地看出MDMAS算法相比其他4种方法的检测性能优势.总体而言,本文所提出的MDMAS算法可实现对未知恶意代码的有效检测,且检测结果优于其他方法.
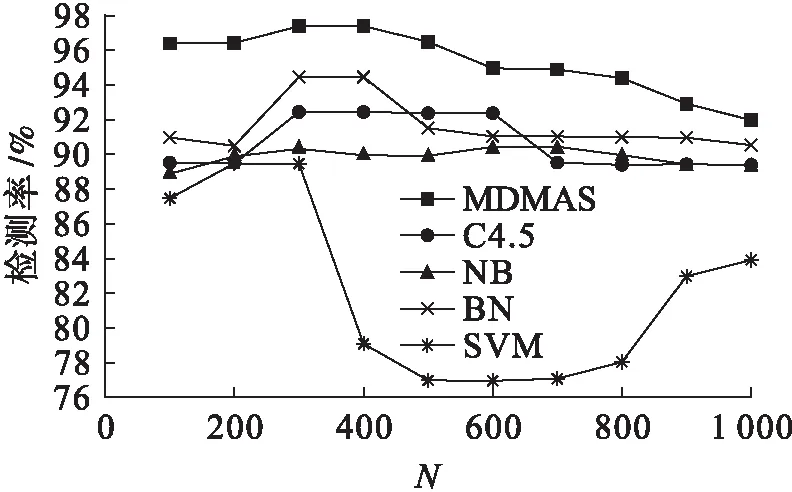
图4 检测率Fig.4 Detection rate
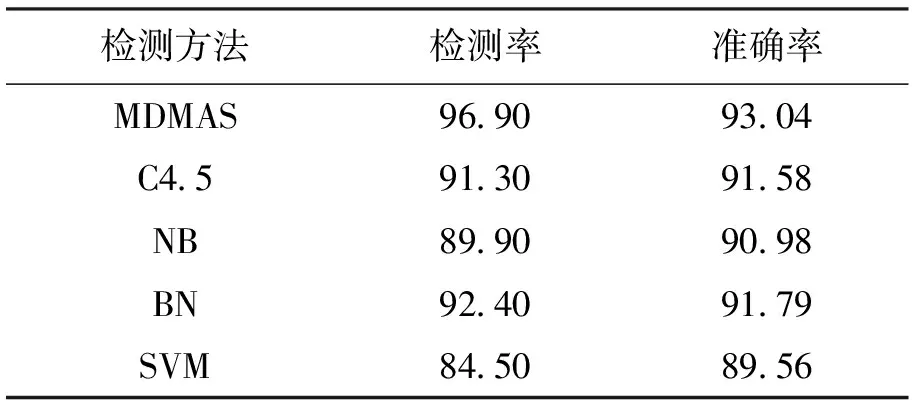
表3 实验结果Tab.3 Experimental results %
3 结 论
针对当前未知恶意代码数量急剧增长的现状,本文提出一种基于属性相似度的恶意代码检测方法.该方法首先提取并计算恶意代码和正常文件的属性均值,再通过比较待测样本的属性值与两类样本属性均值的相似度大小来判断待测样本类别.与Jeremy的恶意代码检测方法实验比较表明,该方法可实现未知恶意代码的有效检测,且检测性能具有一定优势.
[1] Symantec.2016 internet security threat report [EB/OL].2016-04-21 [2016-06-22].https://www.symantec.com/security-center/threat-report.
[2] Philip O,Sakir S,Kieran M,et al.SVM training phase reduction using dataset feature filtering for malware detection [J].IEEE Transactions on Information Forensics and Security,2013,8(3):500-509.
[3] Shan Z Y,Wang X.Growing grapes in your computer to defend against malware [J].IEEE Transactions on Information Forensics and Security,2014,9(2):196-207.
[4] Ding Y X,Yuan X B,Ke T,et al.A fast malware detection algorithm based on objective-oriented association mining [J].Computers & Security,2013,39:315-324.
[5] Sheen S,Anitha R,Sirisha P.Malware detection by pruning of parallel ensembles using harmony search [J].Pattern Recognition Letters,2013,34(14):1679-1686.
[6] Shamsul H,Jemal A,Mamoun A,et al.Hybrids of support vector machine wrapper and filter based framework for malware detection [J].Future Generation Computer Systems,2016,55:376-390.
[7] Cesare S,Xiang Y,Zhou W L.Control flow-based malware variant detection [J].IEEE Transactions on Dependable and Secure Computing,2014,11(4):304-317.
[8] Zhao Z Q,Wang J F,Bai J R.Malware detection method based on the control-flow construct feature of software [J].IET Information Security,2014,8(1):18-24.
[9] Jeremy Z,Kolter M,Marcus A.Learning to detect and classify malicious executables in the wild [J].Journal of Machine Learning Research,2006,7:2721-2744.
[10]张福勇,赵铁柱.基于肯定选择分类算法的恶意代码检测方法 [J].沈阳工业大学学报,2016,38(2):206-210.
(ZHANG Fu-yong,ZHAO Tie-zhu.Malware detection method based on positive selection classification algorithm [J].Journal of Shenyang University of Technology,2016,38(2):206-210.)
[11]Nir N,Robert M,Lior R,et al.Novel active learning methods for enhanced PC malware detection in windows OS [J].Expert Systems with Applications,2014,41(13):5843-5857.
[12]Bai J R,Wang J F,Zou G Z.A malware detection scheme based on mining format information [J].The Scientific World Journal,2014(3):1-11.
[13]Rafiqul I,Ronghua T,Lynn M,et al.Classification of malware based on integrated static and dynamic features [J].Journal of Network and Computer Applications,2013,36(2):646-656.
[14]Thomas E D,Richard A R ,Michael R,et al.Malware target recognition of unknown threats [J].IEEE Systems Journal,2013,7(3):467-477.
[15]Weka.Weka-3-6-12jre.exe [EB/OL].2015-03-30[2016-06-22].http://www.cs.waikato.ac.nz/ml/weka/.
Malwaredetectionmethodbasedonattributesimilarity
ZHANG Fu-yong, QIN Yong
(School of Computer Science and Network Security, Dongguan University of Technology, Dongguan 523808, China)
Aiming at the problem that the number of unknown malware has dramatically increased and the existing detection methods can not effectively detect them, a malware detection method based on attribute similarity was proposed. In the proposed method, the sample files were converted into the hexadecimal format, and alln-grams of sample files were extracted. The information gain of eachn-gram was calculated, andNn-grams with the maximum information gains were selected as the feature attributes. In addition, the average value of each dimension attribute in malware and normal files was calculated, respectively. The categories of samples to be detected were determined through comparing the attribute similarity of samples to be detected as well as the similarity of avarage attribute values of both malware and normal files. The results reveal that the proposed method is superior to the malware detection method based onn-grams for unknown malware detection.
malware detection; attribute similarity; network and information security; intrusion detection; data mining; machine learning; unknown malware; static analysis
2016-06-22.
国家自然科学基金资助项目(61402106); 广东省普通高校国际暨港澳台合作创新平台及国际合作重大项目(2015KGJHZ027); 广东省教育科学规划资助项目(14JXN029).
张福勇(1982-),男,山东龙口人,讲师,博士,主要从事网络与信息安全等方面的研究.
* 本文已于2017-10-25 21∶12在中国知网优先数字出版. 网络出版地址: http:∥www.cnki.net/kcms/detail/21.1189.T.20171025.2112.008.html
10.7688/j.issn.1000-1646.2017.06.11
TP 309
A
1000-1646(2017)06-0659-05
(责任编辑:景 勇 英文审校:尹淑英)
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中国交通信息化(2018年5期)2018-08-21 03:37:40
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
