
利用Bandit算法解决推荐系统E&E问题
2017-11-13 04:23高海宾
韶关学院学报 2017年9期
高海宾
(淮南联合大学计算机系,安徽淮南232001)
利用Bandit算法解决推荐系统E&E问题
高海宾
(淮南联合大学计算机系,安徽淮南232001)
当前推荐系统开发应用过程中普遍存在着E&E问题,笔者指出了推荐系统中E&E问题的产生和分类,提出用Bandit算法解决这一问题的思路,重点探讨Bandit算法的数学模型和用UCB策略建立的Bandit算法模型,用MATLAB编写了核心仿真程序,并指出了这种算法模型存在的优点和不足.
Bandit算法;推荐系统;E&E问题
在当前在大数据时代,信息爆炸式的增长给用户带来了大量的信息,满足了用户在信息时代对信息的需求,但网上信息量的大幅增长,使得用户在面对大量信息时无法从中获得对自己真正有用的那部分信息,对信息的使用效率反而降低了,这就是所谓的信息超载(Information Overload)问题[1].针对信息超载解决的办法之一是搜索引擎,具有代表性信息检索系统有谷歌和百度等,它们在帮助用户获取网络信息方面发挥着极其重要作用[2].但使用搜索引擎的用户在使用同一个关键字搜索信息的时候,得到的结果是相同的.一方面信息及其传播是多样化的,另一方面用户对信息的需求是多元化和个性化的,通过以搜索引擎为代表的信息检索系统获得的单一结果无法满足用户的个性化需求,无法很好的解决信息超载的问题.为了解决这个难题,推荐系统技术的相关研究就应运而生了.与搜索引擎相比,推荐系统通过研究用户的兴趣偏好,进行个性化计算,由系统发现用户的兴趣点,引导用户发现自己的信息需求,根据用户的信息需求,将用户需求的信息、产品等主动的推荐给用户,提高用户得到信息的有用率[3].
一个好的推荐系统不仅能为用户提供个性化的服务,还能和用户之间建立密切关系,让用户对推荐系统产生依赖.推荐系统算法的好坏能直接决定推荐系统的运行效率和质量,它是推荐系统技术中的核心部分.优秀合理的推荐算法模型能够从海量的用户行为数据中,快速挖掘出用户的兴趣意向,对用户实现更为精准的产品或信息的推荐,激发用户和系统之间的交互行为,最终能够实现推荐系统的利益最大化.由于推荐系统中普通存在着E&E问题,采用哪种更合理的算法解决是近年来讨论的热点.
1 推荐系统中的E&E问题
1.1 E&E问题的产生
推荐系统的成功与否最直接的衡量标准就是给用户推荐最想得到的内容,获得用户对展示内容的最大点击收益.每个用户对不同分类的内容感兴趣程度是不同的,那么推荐系统初次见到这个用户时,怎么快速地知道他对每个分类内容的感兴趣程度,从而获得最大的点击收益?对于老用户,推荐系统资源池有若干分类内容,怎么知道该给用户展示哪个分类,从而获得最大的点击收益?显而易见是展示其点击效果最好的那个分类.而对于老用户推荐系统把老的分类内容将不断重复展示,而新的分类内容将缺少展示机会,也有可能永远不会在用户面前展现.假设系统有了新的推荐策略,有没有比更快的方法知道它和旧的策略相比,哪个推荐效果更好?是通过推荐已知收益最高的分类来保证获得当前较高的收益,还是探索未知的分类内容,以一定的概率获得更加优秀的推荐分类内容,寻求获得更高收益的可能性.这些都是在推荐系统最常见的E&E问题(Exploit&Explore).一部分是探索未知内容(Explore),另一部分是利用已知内容(Exploit).推荐系统在不断利用已知分类内容展示给用户的同时还需要不断探索新的分类内容推荐给用户.换句话说,成功优秀的推荐系统应该能利用已知用户的兴趣,探索用户未知的兴趣,推荐资源池中用户更感兴趣的分类内容,获得最大点击收益.当前公认的解决这个问题的思路是推荐系统要花一部分精力做探索未知,花一部分精力做利用已知.至于这两个部分所投入精力的比例是多少,才能获得收益最大化,目前有多种算法可以解决,效果不尽相同.
1.2 推荐系统中E&E问题的分类
推荐系统常见的E&E问题主要分为几类:(1)推荐系统冷启动问题.假设一个用户对不同类别的内容感兴趣程度不同,那么推荐系统初次见到这个用户时,如何快速准确的确定他对所感兴趣的分类内容.如何给新注册用户或无历史信息的客户做个性化推荐,如何将新产品推荐给可能对其感兴趣的用户,如何在一个新开发的系统上设计个性化推荐,从而在系统刚发布时就让用户体验到个性化推荐服务或者只有产品还没用户的系统.(2)老用户推荐分类选择问题.假设资源池有若干分类内容,如何确定给用户展示哪些分类,才能获得用户的最大点击收益.(3)推荐策略选择问题.如何快速的检验出我们有了新的推荐策略,是否比之前推荐策略具有更有效的推荐效果[4].
1.3 E&E问题的解决思路
Exploit是基于已知最好的推荐策略,开发利用已知具有较高收益的分类.优点在于可以充分利用已知高收益分类内容,缺点在于仅限于局部最优,错过潜在的具有更高分类收益的机会,属于保守部分.Explore是不考虑曾经的经验,探索潜在可能产生高回报的分类内容.优点在于能发现更高收益的分类内容,缺点在于失去了对已有高收益分类内容利用机会,属于激进部分.E&E问题的解决思路在于要找到Exploit&Explore的平衡点,以达到累计收益最大化.面对多个分类的选择,我们选择所产生收益和期望的最佳选择所产生的收益之间的差值作为评估指标,定义为遗憾值R(regret),多次选择的遗憾值之和定义为累计遗憾,即根据累计遗憾值的多少来衡量解决E&E问题的优劣性.
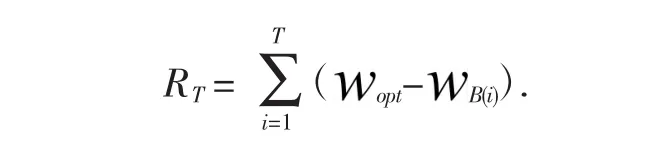
上式中,这里假设选择每个分类的收益为伯努利回报,RT为累计遗憾值opt是第i次试验时被选中分类的期望收益,opt是所有分类中的期望的最佳选择分类的收益.累计遗憾值为次选择的遗憾累计,每次选择的遗憾值T为最优选择收益与本次选择收益之差.可见定义的遗憾值R作为策略好坏的指标,通过最理想总收益与实际得到的总收益之间的差值,反应解决E&E问题的优劣.
2 Bandit算法介绍
Bandit算法来源于经典的N臂赌博机问题,有N个赌博机并排放在赌徒面前,每一轮赌徒通过拉动一台赌博机的臂来进行选择,同时记录这台赌博机带来的收益.假设各个赌博机得到收益均不是完全相同的,经过多轮操作后,可以得到出各个赌博机收益的部分统计信息,然后根据统计信息选择那个看起来收益最高的赌博机,拉动它的臂,最终使赌徒得到最大的收益.即是一个赌徒需要在一排赌博机前决定选择拉动哪一台赌博机的臂,并且决定每个臂需要被选择多少次的问题.假设每台赌博机提供的收益是与它自身的收益随机分布的函数相关的.赌徒的目标是最大限度地通过选择的序列,使得获得的收益最大化.机器学习里又把它称为做“多臂老虎机”(multi-armed bandit)问题.需要一种算法能精确地计算哪个赌博机应该多次选择,哪个应该少选择,并告诉赌徒下一把应该去选择哪一个.Bandit算法的框架包含两个部分,一是探索未知,拉动未知收益的臂,尝试寻找更大收益的臂(Explore),二是利用已知收益的统计信息,拉动收益最大的臂(Exploit).
3 利用Bandit算法解决E&E问题
3.1 Bandit算法模型
有N个赌博机并排放在我们面前,我们首先给它们编号1,2,…,N.赌博机的多个臂的收益可以看做是一组真实的随机分布 B={R1,...,RK},K∈Z,Z代表赌博机集合,K代表臂杆.u1,...,uk代表每个臂的平均收益,赌徒每一轮拉下一个臂,并得到一次收益,i是试验的轮数.轮之后的后悔度为,可用如下公式表示[5]:
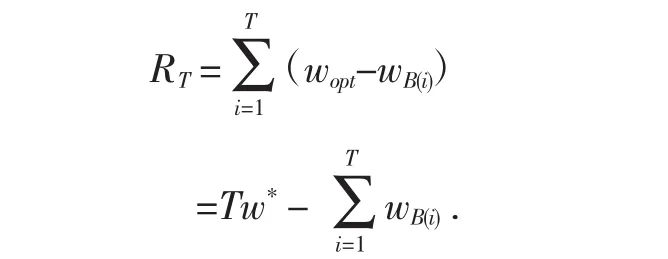
其中w*是前T轮最大收益的平均数,w*=max{ uk},wB(i)是第i次试验时被选中臂的期望收益.一个零后悔度的策略会使得RT在无限次选择臂杆后以概率1趋近与0,趋近于最优策略.在解决这个问题的时候,需要在探索新臂以获得更多关于当前已经选择臂的收益的信息,即探索和选择已有收益最高的臂来获取最大利益之中进行权衡.每次选择后,和本该最佳的选择差了多少,然后把每次差距累加起来就是总的遗憾.这个公式也可以用来对比使用不同策略的Bandit算法的效果.对同样的多臂问题,用不同的策略的算法试验相同次数,看看谁的regret增长得慢.
目前流行的几种Bandit算法,大多采用的是UCB策略,即估计置信区间的做法,然后按照置信区间的上界来进行推荐,因此一些学者把这类Bandit算法称之为UCB算法.
3.2 Bandit算法中的UCB策略
假设面对固定的N个分类内容,没有任何用户的历史行为和行为预测,每一个分类内容的收益情况完全不知道,每次试验要选择其中一个,如何在这个选择过程中最大化收益?论文讨论采用UCB策略即用置信区间解决这个问题.使用置信区间来度量估计的不确定性和置信性.置信区间可以简单地理解为不确定性的程度,区间越宽,越不确定,反之区间越窄,确定性越高.每个分类内容的回报均值都有个置信区间,随着试验次数增加,置信区间会逐渐变窄,也就确定了到底收益多还是少.UCB是一种乐观的策略,选择置信区间上界排序,如果是悲观保守的做法,是选择置信区间下界排序.这里采用分类收益的置信上限作为收益预估值,其基本思想是:每次选择前,都根据已经试验的结果重新估计每个分类的均值及置信区间.如果某些分类的置信区间很宽,说明它被选次数很少,不确定性高,那么它会倾向于被多次选择.选择置信区间上限最大的那个分类,置信区间较宽的那些分类倾向于被多次选择,这就是算法激进的部分(explore).对某些分类尝试的次数越多,对该分类收益估计的置信区间就会越窄.估计的不确定性降低,说明被选次数很多,比较容易确定其好坏了,那些均值更大的分类倾向于被多次选择,这是算法保守的部分(exploit).算法大致过程可以描述为,先对每一个臂都试一遍之后,每次选择分类期望Z值最大的那个臂,分类期望是这个臂到目前的收益均值和标准差之和,其计算分类期望的公式如下:
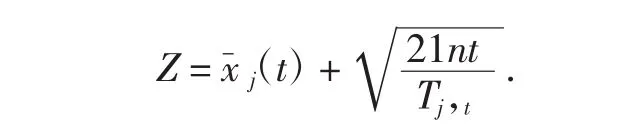
与Bandit算法中应用的其他策略相比,这种策略的好处在于:考虑了收益均值的不确定性,让新的分类更快得到尝试机会.将探索和开发融为一体的UCB策略不需要任何参数,因此不需要考虑如何验证参数的问题.UCB策略很好的解决了Exploit&Explore之间平衡的问题,不会顾此失彼,比较成功的融合在一起.
3.3 Bandit算法的程序设计
利用Matlab软件进行算法仿真程序设计,由于篇幅原因,仅选取部分核心代码如下:


4 结语
E&E这个问题的本质就是寻找最优的分类和获得最大收益之间的平衡问题,所以它出现的领域就是这种寻找最优和获得最大收益矛盾的地方.这一对矛盾在推荐系统中一直客观存在,解决Explore肯定要放弃一部分既得收益,而要走向未知,寻找更优.这显然就存在一定的冒险性,会伤害用户体验的,甚至会损失一部分用户,在已经知道用户喜欢某个分类的前提下,仍然以小概率给用户推荐另一个分类.本文讨论的使用UCB策略实现的Bandit算法能较好的解决这对矛盾,但也存在一定的缺点.比如它需要首先尝试一遍所有分类,因此当分类资源数量很大时耗时耗力,另外初始阶段各个分类选择次数都比较少,导致得到的收益波动较大,以至于经常选中实际比较差的分类等,还需要在Bandit算法解决E&E问题上进行更多的实验和改进.
[1]杨娟.多通路主题模型和双矩阵分解推荐算法[D].苏州:苏州大学,2013.
[2]孙才奇.基于信任网络的情境感知推荐算法的研究[D].沈阳:东北大学,2015.
[3]王国霞.个性化推荐系统隐私保护策略研究进展[J].计算机应用研究,2012,29(6):2003.
[4]佚名.推荐系统的 EE 问题及 Bandit算法[EB/OL].(2016-12-15)[2017-02-11].http://x-algo.cn/index.php/2016/12/15/ee-problem-and-bandit-algorithm-for-recommender-systems/.
[5]Vermorel J,Mohri M.Multi-armed Bandit Algorithms and Empirical Evaluation[C].European Conference on Machine Learning,2005,3720:437-448.
[6]刑无刀.专治疗选择困难症——bandit算法[EB/OL].[2017-02-05].https://zhuanlan.zhihu.com/p/21388070?refer=resyschina.
Bandit Algorithm Solves the Recommended System E&E Problem
GAO Hai-bin
(Department of Computer Science,Huainan Union University,Huainan 232001,Anhui,China)
At present,the E&E problem is prevalent in the development and application of the current recommendation system.Firstly,the generation and classification of E&E problem in the recommendation system are introduced.Then,the idea of using Bandit algorithm to solve this problem is put forward.This paper introduces the mathematic model of Bandit algorithm and the Bandit algorithm model established by UCB strategy,and prepares the program with MATLAB.Finally,the merits and shortcomings of this algorithm model are pointed out.
Bandit algorithm;recommended system;E&E
TP391.1
A
1007-5348(2017)09-0022-05
2017-05-26
安徽省高等学校省级自然科学研究项目(KJ2017A585).
高海宾(1979-),男 ,安徽淮北人,淮南联合大学计算机系讲师,硕士;研究方向:软件技术.
(责任编辑:欧 恺)
猜你喜欢
内江师范学院学报(2022年4期)2022-04-27
湖北师范大学学报(自然科学版)(2021年3期)2021-09-08
数学小灵通(1-2年级)(2021年4期)2021-06-09
数学物理学报(2021年1期)2021-03-29
今日农业(2020年20期)2020-12-15
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
铁道通信信号(2018年9期)2018-11-10
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
海峡姐妹(2017年6期)2017-06-24
