
信念网络在用户画像中的应用
2017-11-02 02:40王程子姜慧
中国信息化 2017年10期
文|王程子,姜慧
信念网络在用户画像中的应用
文|王程子,姜慧
用户画像又称人群画像,是根据用户人口统计学信息、社交关系、偏好习惯和消费行为等信息而抽象出来的标签化模型。“标签”是画像的代名词,即用户画像是各种标签的组合结果。标签的制作分为两个部分:一是根据用户的行为数据直接获取,二是通过算法或关联规则挖掘得到。直接获取的数据如用户在网站或软件注册时主动填写和上传的数据、用户的行动数据(GPS位置信息)、电子商务中用户的交易数据等,这些数据的准确性比较高。通过算法或关联规则挖掘的数据具有预测性,是扩大标签化、推测用户行为习惯和兴趣倾向的重要步骤。
针对用户画像的应用型研究,很多学者对移动互联网、大型社交平台的数据构建用户画像,描述群体性特征,为电子商务和精准营销提供技术支持。本文在参考现有文献的同时,将信念网络模型引入用户画像的构建中,运用多元回归分析用户的基础数据得到信念网络的初始数值,然后构建信念网络模型,以此勾勒画像。
一、用户画像
用户画像更多地应用在电子商务领域,企业能够更好地发觉用户的购买动机和兴趣,以客户需求为具体的任务做设计要远远优于为脑中虚构的东西做设计。
(一)用户数据
用户数据是挖掘用户特征的基础,用户数据大致可以分为两类:静态信息数据和动态信息数据。其中,静态信息数据比较简单,即用户的属性信息。静态信息即用户的真实信息,对此无须做过多的研究和预测,只需附着在用户或用户群体的模型里即可。因此本文需要研究的重点是用户的动态信息,即网络行为数据(页面浏览量、访问时长等)、服务内行为数据(浏览路径、访问深度等)、用户内容偏好数据(收藏、评论、品牌偏好等)、用户交易数据(贡献率、连带率等)这四类信息,这些数据也是需要被分析的用户核心数据。
(二)数据建模
用户画像的目标是通过分析用户行为,最终为每个用户打上标签和该标签的权重。标签表征了用户对某内容的兴趣、偏好和需求,而权重表征了需求度、可信度和概率等。用户画像的建模就是运用上一步的用户数据,通过机器学习等的数学算法构建模型,得到标签和权重的过程。
用户模型包含很多的事件模型,每个事件模型本质上都是一次随机的用户行为,具体说来,就是:Who(用户)+When(时间)+Where(地点)+What(做什么)。“Who”的关键在于对用户的标识,区分不同类型的对象和群体。“When”包括时间戳和时间长度两个部分,时间戳表明发生事情的具体时刻,时间长度是用户在某一页面的停留时间。“Where”包括网址和内容,网址即url连接,定位了一个互联网页面,内容则是该页面的主题,如某产品的信息等。“What”为用户行为,对于电子商务有浏览、添加购物车、搜索、评论、购买、点赞、收藏等行为,不同行为有不同的权重。一般意义上,“5W”的总和即为用户画像的建模思路。
(三)用户兴趣模型
由于静态信息数据、行为特征以及社交网络等数据都是可以通过直接或间接的方法获取,因而建模的主要工作其实是对用户兴趣标签的选取。在对众多用户的行为特征进行归纳和建模时,我们发现用户的行为具有关联性,且行为之间存在逻辑关系。用户也会受到社交网络的影响而改变本身的兴趣。基于这种前后关联的行为模式,我们引入了信念网络的概念,试图构建一种可以模拟用户兴趣的类机器学习式的动态模型。
二、信念网络
信念网络又称贝叶斯网络(Bayesian Networks),是机器学习中经常用到的分类概率算法,人工智能领域用来模拟人脑的推理过程,具有很高的实用价值。
(一)贝叶斯定理
贝叶斯定理是一个“后验概率”,即已知B发生的条件下A的概率P(A|B)如何求得P(B|A)。生活中我们经常遇到这样的情况:我们很容易可以得到P(A|B),但是得到P(B|A)却很困难,为了得到更有用的P(B|A),贝叶斯定理应运而生,通过公式其P(A)中,是先验概率,是通过训练数据估计的初值,而分子可以看做一个观测因子来调节初值的权重以接近实际的P(B|A)。
(二)信念网络的定义
在介绍信念网络之前首先要介绍朴素贝叶斯分类(Naive Bayesian Classification),假设实例之间相互独立,通过给定的实例概率求解在每个实例在给定实例的可能情况下的出现概率,将后验概率最大者判定为分类结果。然而在用户数据中,这种前后条件独立的情况鲜有发生,基于这个问题,我们引入信念网络来解决。
信念网络的拓扑结构是有向无环图(Directed Acyclic Graph,DAG),每个节点代表实例值;有向的边代表两个点的因果关系,每条边都有一个条件概率值。实例空间中包含很多相互联系的实例,信念网络把这些实例整合在DAG中,描述实例之间的条件依赖。
三、实验过程
(一)获取初始值
我们选择某高校所有学生的淘宝购买记录作为数据空间,首先抽取电子商务相关的实例特征作为标签集合,然后根据多元线性回归公式Y=β0+β1x1+β2x2+...+βnxn+ε计算每个用户的实时兴趣度。通过特征提取我们得到了服装、鞋类、护肤品、食品、配饰、家居、百货、数码、运动9类主题。
在实际操作中,我们可以构建回归方程计算用户对某个主题的初始兴趣度,如可以构建方程(1),其中Mi表示页面浏览次数;Ti表示页面停留时间;Si表示收藏页面;Gi表示添加购物车;Bi表示购买。

(二)构建信念模型
对这9类主题构建信念网络,每个主题都由一个节点代替,节点间的有向线段表示用户的兴趣映射,权重为初始兴趣度。初始兴趣的信念网络如图1所示。
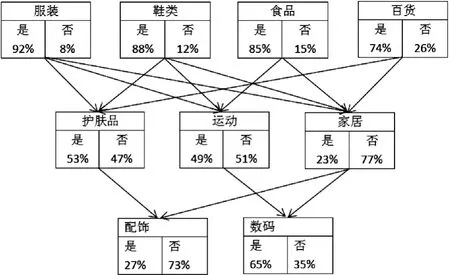
图1 初始兴趣的信念网络
(三)动态调整概率值
信念网络是一个重要的机器学习算法,其优势就是可以根据先验概率的变化调整参数以求得最真实的后验概率。淘宝网上的数据是实时更新的,尤其在网络通讯录大的时段,因此根据即时信息推断和预测用户最可能的兴趣是尤为重要的。
若某用户短期内对耐克运动鞋和宝洁产品的浏览量增加,则用户的鞋类、护肤品和运动的主题的概率会提升,信念网络会实时跟进记录用户的兴趣倾向。若用户对护肤品或运动的兴趣程度即概率值大于预设的阈值δ时,模型会预测该客户会进而对配饰或数码主题产生兴趣,进而推荐一些此类的网页,如图2所示。

表1 用户的后验概率

图2 信念模型预测用户兴趣变化
(四)基于信念模型的画像展示
信念模型在一段测试时间内会对用户的行为数据作整体判断,计算出该时间段内此用户的兴趣集合。上述实验过程中我们把兴趣阈值 设为0.618,实验得到的三个用户的后验概率如表1所示,A用户的兴趣集合为{服装,鞋类,护肤品},B用户的兴趣集合为{鞋类,运动,数码},C用户的兴趣集合为{食品,百货,家居}。由此商户可以根据用户喜好推荐链接,尽最大可能挖掘信息资源,精准营销。
四、结束语
本文阐述了用户画像的意义和主要的工作流程,阐明构建画像的重心在于根据动态信息数据挖掘用户的兴趣标签,并预测用户的兴趣转变趋势。借鉴机器学习中预测学习结果和计算后验概率的思路,引入信念模型的概念,通过实时追踪用户行为数据,运用行为间的逻辑关系来关联分析并挖掘用户的兴趣,最后设立阈值,准确勾勒用户的画像。信念网络能够动态评估和预测用户的兴趣,可以大幅度提升用户画像的准确性。
作者单位:国际关系学院
猜你喜欢
小哥白尼(神奇星球)(2022年3期)2022-06-06
金桥(2021年11期)2021-11-20
黄河之声(2021年9期)2021-07-21
非公有制企业党建(2020年10期)2020-10-27
雪豆月读·低年级(2020年7期)2020-09-10
学苑创造·A版(2017年11期)2018-01-23
瞭望东方周刊(2017年7期)2017-03-01
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
延河(下半月)(2014年1期)2014-02-28
