
基于随机KNN特征选择的高质量移动通信用户预测
2017-10-18 03:44:13崔伟夏汛孙瑜鲁
现代计算机 2017年26期
崔伟,夏汛,孙瑜鲁
(1.泸州职业技术学院,泸州 646000;2.四川大学电子信息学院,成都 610064)
基于随机KNN特征选择的高质量移动通信用户预测
崔伟1,夏汛1,孙瑜鲁2
(1.泸州职业技术学院,泸州 646000;2.四川大学电子信息学院,成都 610064)
高价值移动通信用户预测是电信企业客户管理的一项重要内容,针对用户数据维度较高,规模较大,类不平衡较严重等问题,提出一种基于随机KNN的特征选择的预测方法,首先对初始数据进行随机采样构建多个KNN分类器,随后计算特征的权重以评估其重要性,利用广义顺序后退法对特征进行选择获得最优的特征子集,最后在结合集成学习方法中加入加权投票机制,建立预测模型。实验结果表明,该预测模型能够有效降低样本特征维度并提升对高价值移动通信用户预测性能。
不平衡数据集;特征选择;k近邻;预测模型
0 引言
随着智能手机的普及以及4G网络通信的快速推广,移动客户消费增长迅速,市场竞争全面展开,如何挖掘并发展高价值用户是电信企业增加收入并提高市场竞争力的关键。目前对于高价值用户并无统一的定义,以往的学术研究多关注用户分类[1-2]及客户流失预测[3-4]等,对于高价值用户预测的研究较少,因此根据用户的消费记录等数据建立高价值移动用户预测模型具有重要的应用价值。然而由于这类数据规模较大,维数较高,其中可能包含的不相关或者冗余特征导致模型的学习时间增加,同时发生过拟合现象。进行特征选择的目的是为了尽可能减少数据集中的冗余特征,因此设计有效的特征选择方法是建立模型核心所在。
根据特征选择方法与后续学习算法间的关系,可将特征选择算法分为过滤式、嵌入式两类。在过滤式的特征选择算法中,依据特定的度量选择特征,特征选择的过程与具体的分类器无关,常用的方法有Relief[5]、CFS[6]等,这类方法较简单,速度快,然而其评估结果与后续学习算法的性能偏差较大,对于不同数据集的鲁棒性和适应性有待提高。封装式的特征选择方法在特征度量中考虑了分类的错误率,将特征选择方法作为学习算法的一个组成部分,直接使用分类性能评价所选择的特征子集。由于其评价限制于具体的分类器,所以封装式方法的分类精度得到了大幅度的提高,然而其泛化能力较差,时间复杂度较高。
文献[7]将随机森林用作特征选择,通过在每一颗决策树中随机排列特征,通过分类准确度进行特征选择,在迭代中,逐步剔除不能提高分类性能的特征,最终得到的结果是构成分类误差最小的特征集合。然而,由于随机森林方法其为层次的树形结构,其特征选择的结果并不稳定,若数据发生微小的改变,随机森林可能生成不同数量的特征,同时,在决策树中存在高方差的情况[8]。
因此,从集成学习的方法出发,结合高价值移动用户数据集维度较高,类不平衡较严重的特点,本文提出一种基于随机KNN的特征选择方法,将其用于高价值移动通信用户预测。
1 高价值移动通信用户判定及数据收集
电信企业将用户平均收益(Average Revenue Per User,ARPU)作为衡量用户价值的重要指标,它注重一个时间段内电信运营商从每个用户得到的收入。一般来说,移动用户连续N月的月均消费水平会随N值的提高而增长,同时,月均消费水平较高的用户流失率较低,因此,本文将高价值用户定义为:入网一年以上且近一年月均消费金额在200元以上的用户。
对于一个移动通信用户,其消费水平增长是一个较慢的过程,大幅度的增长较为少见。因此,本文的研究目标为连续一年月均ARPU值在100~200元之间的用户,正类样本为未来一年内会成长为高价值用户的群体,其余用户标为负类。本文从消费特征,终端特征,消费行为变化,App下载记录等4个方面抽取目标用户的基本特征构成特征集合和相关样本数据,最终的数据集包括12万条数据记录,98个用户特征,正类样本越占总样本的四分之一。其中10万条数据记录作为训练集及测试集,剩余2万条记录构成验证集以检验模型的预测效果。
2 算法描述
随机KNN(Random KNN,RKNN)的思想与随机森林相似,通过将多个基础分类器联合为一个强分类器进行学习。与随机森林不同的是,随机KNN中的基础分类器为KNN,而不是决策树,因此其没有层次结构。在每一个基础KNN分类器中,通过与测试样本最近的k个样本决定样本的分类。而最终得到的RKNN通过多个KNN投票进行决策。
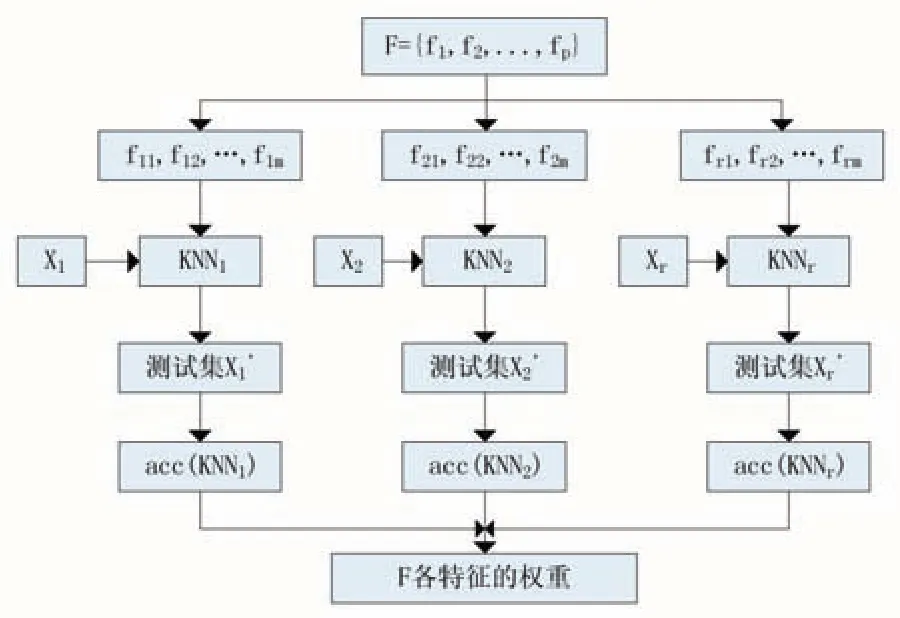
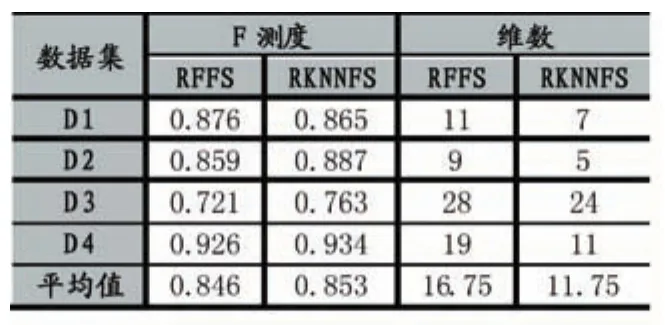
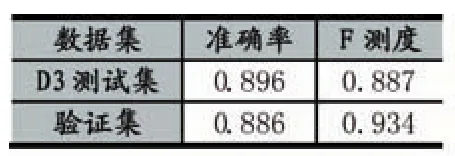
令F={f1,f2,...,fp}为输入的p个特征,X为包含n个数据的输入数据集合,则X为一个大小为n×p的矩阵,对于随机数m(m KNN算法的基本思想为:给定一个测试样本x,首先找出与该测试样本最接近的K个训练样本,通过统计测试样本与K个近邻中各类样本的相似度之和,作为测试样本与各类的相似度,最后将该样本判定为相似度最大的类,步骤如下: (1)计算测试样本与所有训练样本的距离,而测试样本x与训练样本y的距离计算如下式: (2)找出与测试样本x距离最小的K个最邻近训练样本。 (3)分别计算K个最近邻样本与测试样本x的相似度。距离越大,相似度越小,反之亦然,即: (4)统计测试样本与各类别的总相似度S(x,Ci): 为了选择有效的特征,其关键是计算特征的权重,为其重要性进行排序。本文将KNN的分类准确率作为特征的特征权重的计算依据。 首先,每一个KNN对测试集进行分类,通过与测试样本的实际类别进行比较,计算每一个KNN的分类准确率acc(KNN)。令C(f)表示特征f参与的所有的KNN分类器的集合,每一个KNN的分类结果对参与其中的特征计算权重,如图1所示。特征权重越高,则该特征越重要。特征f权重可计算为: (5)将测试样本判别为相似度最大的类: 图1 特征权值计算流程图 在得到特征权重以后,可以直接选择权重较高的特征作为特征选择的输出结果,但由于在基础KNN进行分类时,其样本集合的特征是随机选取的,这样的做法并不可靠。因此,考虑到算法速度和分类性能的平衡,本文将特征选择的过程分为两步,不断采用序列后向搜索方法进行迭代构造新的样本集选择特征。在第一步的迭代中,算法每次迭代,特征的数量减小为原来的q(0 对于预测模型,常用的评价指标包括:精确率(Pre⁃cision),召回率(Recall),F 测度(F-measure)评价跟踪算法的性能。其定义分别为: 精确率(Precision),表示“正确被检索到的条目(TP)”在“实际被检索的条目(TP+FP)”中所占的比例: 召回率(Recall),表示所有“正确被检索的条目(TP)”在“应该被检索到的条目(TP+FN)”中所占的比例: F测度(F-measure),表示召回率(R)和精确率(P)的加权调和平均数,其一般化的公式为: 当β=1,就是F1-measure: 为了验证本文方法在高价值移动通信用户预测研究中的有效性,本文选用特征子集的维度和F测度两个指标对模型性能进行评估,并与随机森林的特征选择方法进行对比试验,采用其提供的原始算法建立预测模型。本文选用了UCI数据库中3个不同数据集及本文研究在数据搜集阶段得到的某电信公司提取的初始数据集作为实验数据,如表1所示。 表1 不同数据集比较 不同方法对4个数据集的预测结果如表2所示。本文方法KNNFS的降维效果最好,相对于RFFS,在特征维数上减小了29.85%,其平均F测度提高了2.25%,这表明KNN相对于随机森林的树状结构更适合解决此类包含较多冗余特征的大规模不平衡而分类问题。从表2中可以看出,本文方法对于低维数据,本文方法除能降低特征集合的维度外,在提升模型预测性能方面并无特别优势。但从D3可以看出,对于高维、正负样本不平衡度较大的数据集,RKNNFS的降维效果及对模型性能的提升作用得以体现,验证了本文方法的有效性。 表2 不同算法的性能比较 经过一系列特征选择及算法参数调优,得出RKNNFS和High-value mobile user数据集的最优特征子集为:套餐金额,在网天数,近半年月均活动基站数,近3月月均通话时长,漫游通话次数,增值业务费用,近三月月均流量,月均长途通话时长,终端销售价格,近3月月均通话时长,用户ARPU增长速度。 表3 预测模型在不同数据集上的结果比较 预测模型在高质量移动用户验证集和D2测试集上的预测结果如表3所示,可以看出,算法相对于在D1上的结果,预测模型在验证集中准确率仅略微下降了1.1%,然而F测度提高了5.2%,体现本文预测模型的泛化能力较强。 因此,基于RKNN的特征选择方法建立的高价值移动用户预测模型具有一定的实用性,能够处理大规模高维不平衡数据集上的二分类问题,能够较好地为企业决策提供参考。 针对移动高价值移动通信用户,本文提出随机KNN方法进行特征选择并建立预测模型,通过在随机森林的框架下利用KNN作为基础分类器,避免了随机森林的缺陷,可以有效处理高维度不平衡数据集上的特征选择问题,通过与传统方法的实验结果进行对比,验证了该方法的有效性和实用性,未来计划将该方法用于其他应用,并提高模型的预测精度。 [1]梁霄波.电信客户细分中基于聚类算法的数据挖掘技术研究[J].现代电子技术,2016(15):95-98. [2]张焕国,吕莎,李玮.C均值算法的电信客户细分研究[J].计算机仿真,2011(06):185-188. [3]张慧,徐勇.数据挖掘中SVM模型与贝叶斯模型的比较分析——基于电信客户的流失分析[J].平顶山学院学报,2016,(02):68-73. [4]梁路,王彪,王剑辉,刘冬宁.基于细精度关联规则挖掘的电信客户流失分析[J].智能系统学报,2015(03):407-413. [5]Dash M,Ong Y.RELIEF-C:Efficient Feature Selection for Clustering over Noisy Data[C].International Conference on Tools with Artificial Intelligence,2011:869-872. [6]Liu L,Zhang J,Li P,et al.A Label Correlation Based Weighting Feature Selection Approach for Multi-label Data[C].Web Age Information Management,2016:369-379. [7]姚登举,杨静,詹晓娟.基于随机森林的特征选择算法[J].吉林大学学报(工学版),2014(01):137-141. [8]Mcinerney D O,Nieuwenhuis M.A Comparative Analysis of kNN and Decision Tree Methods for the Irish National Forest Inventory[J].International Journal of Remote Sensing,2009,30(19):4937-4955. Abstract:The prediction for high value mobile communication user plays an important role in the telecom enterprise customer management.Aiming at the problems such as high user data dimension,large scale and serious unbalanced class,proposes a method of feature selection based on random KNN.Firstly,the initial data is randomly sampled to construct multiple KNN classifiers,and then the weights of the features are computed to measure its importance,and the generalized sequential backward selection method is used to select the optimal features sub⁃set.Finally,the weighted voting mechanism is added in the ensemble learning method to establish a predictive model.The experimental re⁃sults show that the model can effectively reduce the dimensions of the sample features and improve the prediction performance of the high value mobile communication users. Keywords:Imbalanced Dataset;Feature Selection;K-NN;Prediction Model Prediction for High-Value Mobile Users Based on Random KNN Feature Selection CUI Wei1,XIA Xun1,SUN Yu-lu2 (1.Luzhou Vocational and Technical College,Luzhou 646000;2.College of Electronic&Information Engineering,Sichuan University,Chengdu 610064) 川大-泸州战略合作科技项目(No.2015CDLZ-S12) 1007-1423(2017)26-0009-04 10.3969/j.issn.1007-1423.2017.26.002 崔伟(1983-),男,四川自贡人,硕士,讲师,网络工程师,研究方向为企业信息化和新一代互联网应用 夏汛(1984-),男,四川泸州人,硕士,讲师,研究方向为大数据应用、企业信息化 孙瑜鲁(1991-),女,山东泰安人,在读硕士研究生,研究方向为图像处理,模式识别,Email:sunylcn@163.com 2017-06-27 2017-09-10

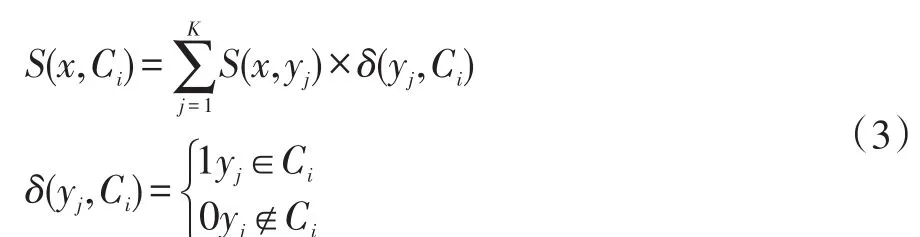


3 实验结果与分析





4 结语
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06电子测试(2018年1期)2018-04-18 11:52:35初中生世界·七年级(2017年9期)2017-10-13 22:27:46电子制作(2017年23期)2017-02-02 07:17:06光学精密工程(2016年4期)2016-11-07 09:05:00光学精密工程(2016年3期)2016-11-07 09:03:33西北工业大学学报(2015年4期)2016-01-19 03:31:47电测与仪表(2014年15期)2014-04-04 12:05:20
