
基于无人机传感器数据与词袋模型的点云自动化分类
2017-10-16 09:05:54汪从敏何玉涛黎天祥
地理信息世界 2017年4期
江 炯,汪从敏,何玉涛,黎天祥,徐 杰
(国网浙江省电力公司宁波供电公司,浙江 宁波 315010)
0 引 言
LiDAR作为一种快速、全天候、精确获取地面三维数据的技术,在现阶段LiDAR技术随着软硬件的发展也取得了全面的发展并受到了极大的重视。LiDAR(Light Detection And Ranging)集中体现了激光技术、计算机技术、全球定位系统(GPS)和惯性导航系统(INS)三种技术的结合。LiDAR以其快速、全天候、精确、直接获取地面二维数据信息的特点,在城市三维建模中扮演着越来越重要的角色[1]。
由于现实场景的复杂性以及LiDAR点云数据存在噪声点等原因,导致目前点云后处理中识别和分类的效率较低。多年来诸多学者致力于点云场景的分类和识别,提出了多种高效地用于描述点云场景的特征并应用于场景的解译中,如基于特征向量的特征[2-16]可以用来描述一个点周围小范围内的几何形状特征,广泛应用于激光雷达点云分类中。文献提出的旋转图像(spin image)[17]特征在记录当前点特征的同时也记录了其周围点的一些特征以此来提高特征算子的鲁棒性,在点云分类和识别中也有着广泛的应用。此外,高度[3,9,-,11,18,-,26]、点表面曲率、法向量[18]、点强度信息[2-3,9-10,18]、点特征直方图[21](Point Feature Histogram, PFH)、快速点特征直方图[22](Fast Point Feature Histogram, FPFH)等特征。
对于点云分类而言,目前主流的分类单元包括基于单点[23]、基于分割对象[24]和基于体素[25]。Niemeyer[26]通过构建两层的条件随机场,第一层是以单点为图模型的节点,第二层是以分割对象为图模型的节点。然后两层之间实现类别信息的传递来改善分类质量。Dittrich[27]对在点云分类识别中常用的3D结构张量的特征值特征做了定性和定量的分析。赵刚[28]基于GradientBoosting方法对车载点云数据进行自动化识别。其中基于单点的方法容易受到噪点的影响,而且尽管目前存在多种点云分割算法,但是考虑到计算效率问题,本文采用体素化点云的方式分割点云数据。Lim[29]对点云实验场景构建超体素,基于超体素利用条件随机场进行点云场景的分类。Ramiya[30]首先根据点云的几何和光谱相似性生成超体素,进而基于超体素聚类成不同大小的分割对象,然后不同的分类器分类得到点云分割对象。Babahajiani[31]通过将体素化的点云转换为超体素,通过训练增强型决策树完成场景的分类。Huang[32]构建了一种3D卷积神经网络框架用于分类点云数据,文中首先将原始点云体素化,体素应用三维的卷积操作,然后用体素的类别标记体素内的点,完成点云场景的分类。为了能有效地描述体素的特征,将词袋模型[33]引入点云分类中。词袋模型能有效地综合体素中每个点的特征,从含有不同点数的体素中提炼出相同长度的特征向量,这样便于特征向量作为分类器的输入以及对体素进行分类。
考虑到点云数据只具有精确的平面位置信息和高度信息,然而却不能获取地表物体的纹理信息,而高分辨率的遥感卫星图像却能获取物体的光谱、纹理、几何形状等信息,本文结合这两种数据的特征,提出了融合影像信息的城区机载LiDAR点云数据的自动化分类方法,具体流程如图1所示。首先将原始点云数据体素化,并基于单点计算点云的几何特征和对应的影像特征,然后基于k-means算法计算训练数据特征向量的 k个聚类中心,视为视觉单词词典。接着基于视觉单词词典统计每个体素内视觉单词的词频,构建视觉单词词频直方图即为词袋模型。最后基于词袋模型训练随机森林分类器,识别未知类别的体素,以此完成点云的分类。
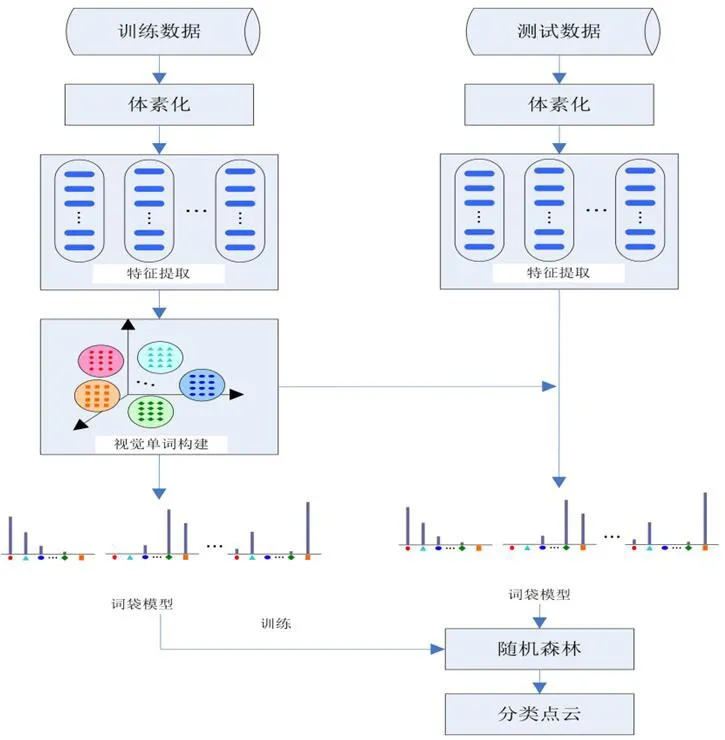
图1 基于词袋模型的点云分类流程图Fig.1 Flow chart of classification of point cloud based on bag of words
1 研究方法
1.1 点云体素化
考虑到点云在空间中的散乱分布,将点云所在的三维空间的外包围盒验三个空间坐标轴方向以一定步长划分为一系列可以索引的立方体栅格,这个过程称为点云的体素化。点云体素化的建立依赖于体素的各边长的设置,体素的形状和大小由长、宽和高来确定。根据体素的三条边长l,w,h和公式(1)将点云范围沿X、Y、Z坐标分别划分为m、n、g份。
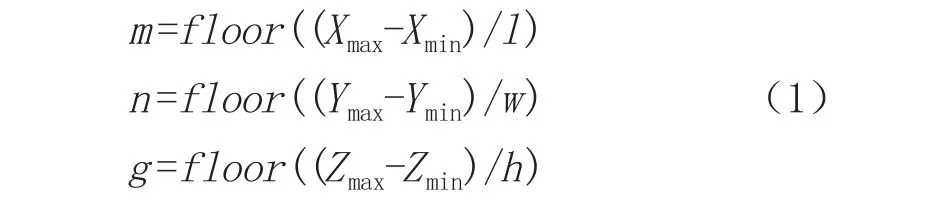
根据点云的坐标最小值Xmin、Ymin、Zmin和体素的三条边长l、w、h通过公式(2)计算点云中任一点(X、Y、Z)所在体素的索引号(i、g、k)。
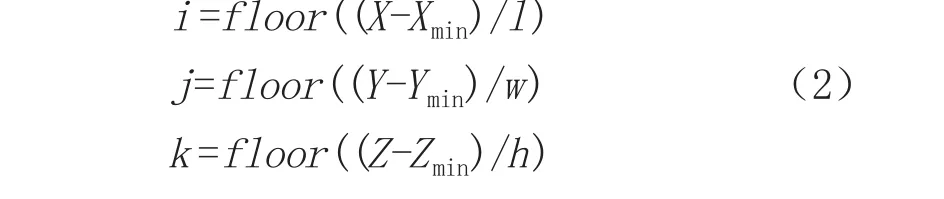
图2是将实验数据进行体素化之后,同一体素内的点被赋为相同的颜色,不同体素被随机赋色得到的点云渲染图。

图2 体素化结果Fig.2 Voxelization
1.2 基于单点的特征提取
点云的法线能够很好地反映建筑物和植被的表面变化状况。求解表面上某点的法线的问题可以通过求取表面某点正切平面的法线来解决,那么可以转化为最小二乘平面估计问题。计算待定点及其邻域内点到拟合平面的距离,利用下式计算平面残差和,作为分类特征。
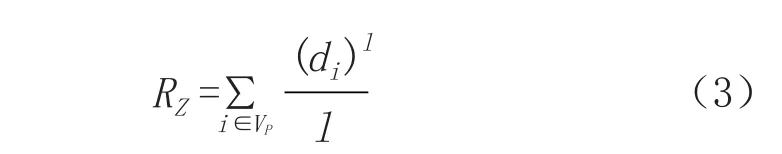
式中,di是指点i到平面的距离,l=1.2。
由于基于特征值的特征能良好地表征3D场景中物体的几何形态,近些年被诸多学者广泛地应用于三维场景中物体的分类和识别中,也从定量和定性的角度分析了基于特征值的特征的精度和稳健性。因此,本文在建立点邻域系统之后,通过定义当前的邻域协方差矩阵求解当前点的特征值特征。假设CP表示当前点P的邻域协方差矩阵,那么CP可以通过公式(4)进行计算:

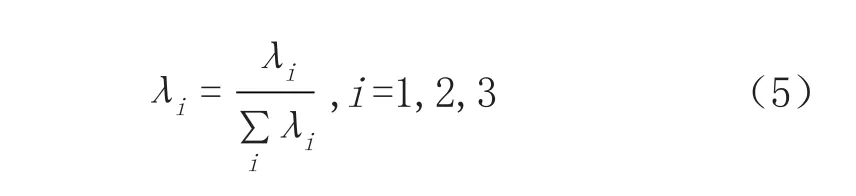
在求解特征值基础上,计算在特征值基础上的衍生特征用于区分平面、边缘以及线性结构,提取的这些特征在不同的几何结构上的取值不同,其中,λ3在平面区域值较低,非平面区域值较高,建筑物屋顶处λ3值较低,高植被处λ3值较高。各向异性:Aλ=(λ1-λ3)/λ1;平面性:Pλ=(λ2-λ3)/λ1;球面性:Sλ=λ3/λ1;线性:Lλ=(λ1-λ2)/λ1,这些特征可以辅助区分平面、边缘、角点和线等结构。
为了能有效地利用同机获取影像的光谱信息,在构建点特征向量时考虑了影像所包含的光谱信息,主要提取影像像素的RGB信息。
在综合分析点云数据及其对应影像数据基础上,实现影像和点云的配准,并构建如公式(6)所示的描述点的特征向量。

式中,RZ表示平面残差,λ1、λ2、λ3分别是邻域协方差矩阵的特征向量,Aλ表示各向异性,Pλ表示平面性,Sλ表示球面性,Lλ表示线性,R、G、B分别表示当前点的RGB信息。
1.3 构建词袋模型
最初的Bag of words,也叫做“词袋”,在信息检索中,Bag of words model假定对于一个文本,忽略其词序和语法,句法,将其仅仅看做是一个词集合,或者说是词的一个组合,文本中每个词的出现都是独立的,不依赖于其他词是否出现,或者说当这篇文章的作者在任意一个位置选择一个词汇都不受前面句子的影响而独立选择的。目前词袋模型在计算机视觉领域得到了广泛应用。文中将原始点云体素化后,基于词袋模型来描述和表示体素内容,基本原理是统计点云体素中重要内容出现的频次,如基于单点构建点的特征向量,将其类比为文档中的单词(文中称之为视觉单词),随后将体素内每个点的特征向量映射为(最近的)的视觉单词,从而将每个体素转换为多个视觉单词的组合形式。
基于体素的词袋模型构建主要包括以下部分:①将原始点云体素化;②基于单点计算点的特征向量;③基于k-means聚类算法求得特征向量的聚类中心,生成视觉单词表;④将体素内的所有点的特征向量映射为最相似的视觉单词,统计每个体素内各个视觉单词出现的频次,构建该体素的词袋模型表示,即各个视觉单词的直方图表示。
1.4 随机森林分类器
随机森林(Random Trees)是一种由多棵决策树组合而成的联合预测模型,自然可以作为快速且有效的多类分类模型。当输入待分类样本时,随机森林输出的分类结果由每个决策树的分类结果简单投票决定。通过分类器联合,总体上得到比单一分类器分类结果更稳定、鲁棒性更好的分类性能,发掘了各个分类器的优点,并避开了分类效果不好的分类器。
根据Breiman的随机森林理论,在一个随机森林分类器中,要建立多棵决策树,这些树的建立方式相同,但是由于构建每个决策树时,随机抽取训练样本集和属性子集的过程都是独立的,这一点决定了每棵树的分类结果都是不一样的。以同样的方式训练得到 个决策树将其组合起来,就可以得到一个随机森林。当输入待分类的样本时,随机森林输出的分类结果由每个决策树的输出结果进行简单投票(即取众数)决定。随机森林中第 个决策树的训练过程如图3所示。
一旦随机森林建立起来,所有的树Tree1,...,Treem都会对预测样本有一个预测标签。通过随机森林中的M棵树,得到了M个对样本的分类标签Li(1≤i≤M),然后从这M个标签中选择所得投票数多的那个标签作为随机森林分类器的预测结果,预测结果由下式给出:
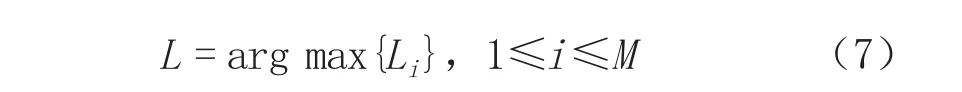
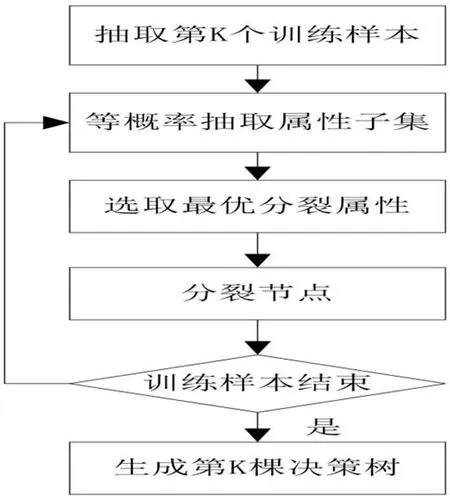
图3 随机森林中单个决策树训练过程Fig.3 A single decision tree training process in random forest
2 实验与分析
2.1 实验数据
为了验证本文提出方法的有效性,文中选取了两个实验区来验证。场景I为Terrasolid官网提供的数据,数据范围是Jyväskylä市的点云数据,实验数据中点云密度为15.4点/m2,该场景的影像分辨率为0.4 m。场景II的实验数据的覆盖区域为赫尔辛基工业大学校区,实验数据中点云密度为4点/m2,该场景的影像分辨率为0.4 m。相关场景的部分区域影像如图4a和图4b所示,对应点云数据的人工分类结果如图4b和图4d所示,图中红色点表示建筑物点,浅绿色点表示低植被点,深绿色点表示高植被点,橘黄色点表示地面点,以此作为点云自动分类结果评定的标准。同时统计了相关实验数据信息,统计结果见表1。

图4 实验数据Fig.4 Experimental data
表中分别统计了两个实验场景中不同地物的LiDAR点个数以及场景点云的总个数。
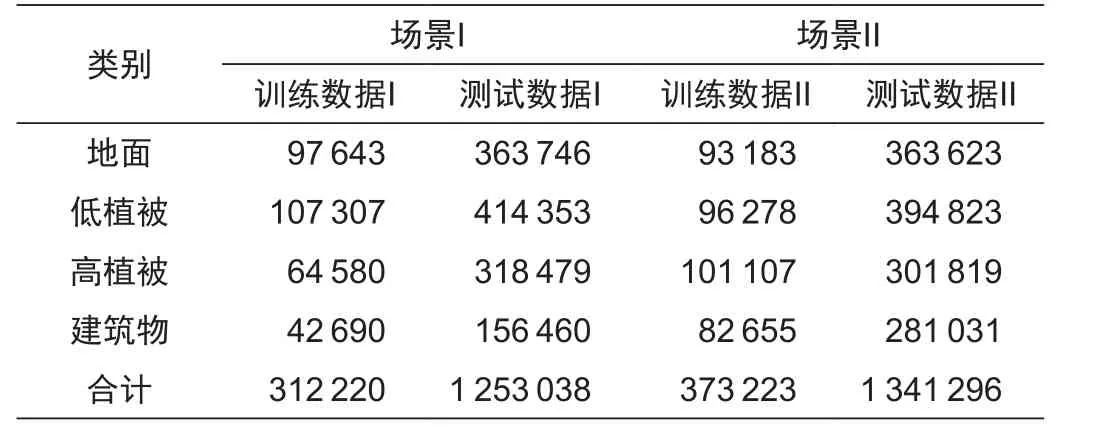
表1 训练数据和测试数据统计结果Tab.1 Training and test data
本文采用召回率(Recall)、精确率(Precision)、准确率(OverallAccuracy)对于分类器的性能进行评价。假设原始样本中有两类,其中有P个类别为1的样本,且假设类别1为正例,有N个类别为0的样本,且假设类别0为负例,则

式中,TP个类别为1的样本被系统正确判定为类别1,FN个类别为1的样本被系统误判定为类别0,FP个类别为0的样本被系统误判断定为类别1,TN个类别为0的样本被系统正确判为类别0。
2.2 实验分析
2.2.1 影像光谱信息对分类结果的影响
文中为了改善点云分类质量,将同机获取的影像用于点云分类过程中以期望改善分类效率。为了验证这个策略的有效性,文中以场景I和场景II为研究对象进行了对比实验,实验中分别统计了在添加影像光谱信息和没有添加光谱信息情况下点云的分类质量,统计分类结果见表2,可以得出影像光谱信息的融入,使分类总正确率提高了4%以上。同时文中列举了点云中道路点的分类质量,如图5所示,图中橘黄色的点为道路点。由图中可以得出通过加入影像光谱信息,能改善分类过程中可能存在的“椒盐”现象,同时对于识别植被等地物具有重要意义。
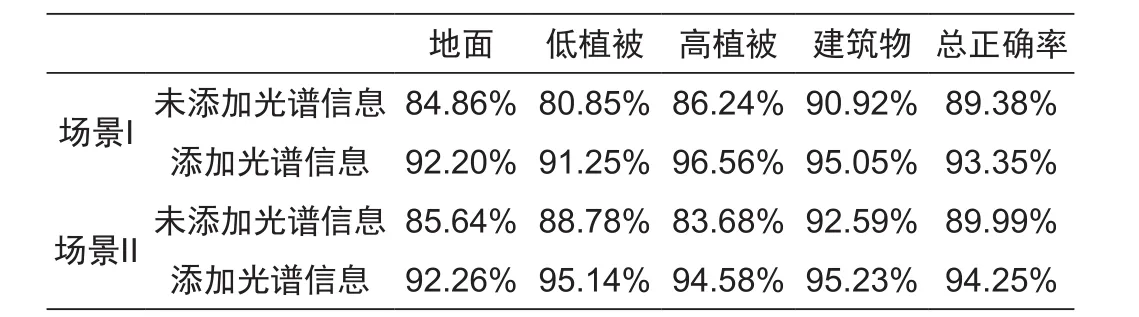
表2 影像光谱信息对分类结果的影响Tab.2 Influence of the spectral information on classification result
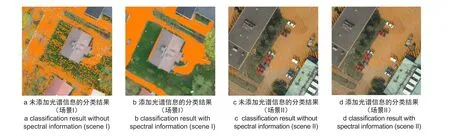
图5 影像光谱信息对分类结果的影响对比图Fig.5 Comparison with and without spectral information
2.2.2 体素的大小对分类结果的影响
本文中是以体素为单位分类点云的,为了探求体素的大小对分类精度的影响。文中以场景I的实验做了参数敏感性分析。文中对该实验区进行分类,通过改变体素的边长来探求实验精度受体素大小的影响,并统计实验结果如图6所示,图中柱状图描述的是不同地物的分类精确率受体素大小变化的影响,折线图表述的是分类总正确率受体素大小变化的影响。实验结果表明,随着体素大小的不同,不同地物的分类结果也不相同,其中建筑物的分类结果随体素大小变化波动最大,精确率取值波动范围大于8%。
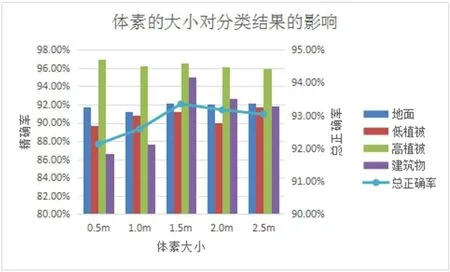
图6 体素的大小对分类结果的影响Fig.6 Influence of the size of voxel on the classification result
2.2.3 视觉单词个数对分类结果的影响
在描述和表达体素的特征时,文中将词袋模型引入到体素的分类过程中。实验中所用的视觉单词表中单词实际上是由k-means聚类算法得到的聚类中心。为了探求实验中视觉单词表中单词数目对实验结果的影响,文中以实验场景I为研究对象,分别选取不同的视觉单词个数也即设置不同的特征向量的聚类中心的个数,以此来探求视觉单词对分类结果的影响,并将实验结果统计如图7所示,图中柱状图描述的是不同地物的分类精确率受视觉单词个数变化的影响,折线图表述的是分类总正确率受视觉单词个数变化的影响。实验结果表明,视觉单词的个数对分类结果产生较大影响,随着单词个数的变化,分类总正确率波动大于3%。在单词个数变化的过程中,建筑物受其影响最为显著,建筑物的分类精确率波动超过6%。
2.2.4 基于单点与基于体素的分类结果对比
考虑到点云数据存在大量噪点,同时抑制分类过程中可能存在的“椒盐”现象,文中以体素的形式组织原始点云。为了验证这种策略的有效性,文中以场景I和场景II的实验数据作为研究对象,与基于单点的策略进行分类结果对比,统计结果如下图8所示,图中橘黄色点表示地面点。实验结果表明,基于体素方式分割原始点云,并基于体素进行对象化的分类,对于改善点云分类的质量和效率效果显著。表3中列举了基于单点的方法与基于体素的方法的分类结果对比,从对比结果中可以得出,基于体素分割原始点云可以有效地抑制噪点在分类过程中的影响,分类结果提高了7%。

图7 视觉单词个数对分类结果的影响Fig.7 Influence of the number of visual words on the classification result

图8 基于单点与基于体素的分类结果对比图Fig.8 Comparison of point-based and voxel-based classification result
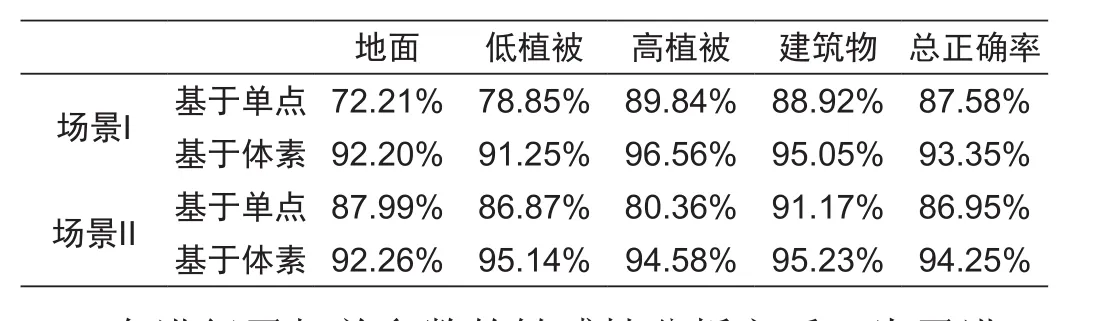
表3 基于单点与基于体素的分类结果对比Tab.3 Comparison of point-based and voxel-based classification result
在进行了相关参数的敏感性分析之后,为了进一步验证本文提出模型的有效性和稳定性,将此模型应用于不同的实验场景,实验结果统计见表4和表5。表4和表5中分别列举了不同地物的分类结果。同时由于场景I和场景II获取的点云密度也是不一样的,也验证了本文模型对点云密度具有一定的抗干扰性。

表4 分类混淆矩阵(场景I,总正确率:93.35%)Tab.4 Confusion matrix of classification ( Scene I, overall accuracy:93.35%)
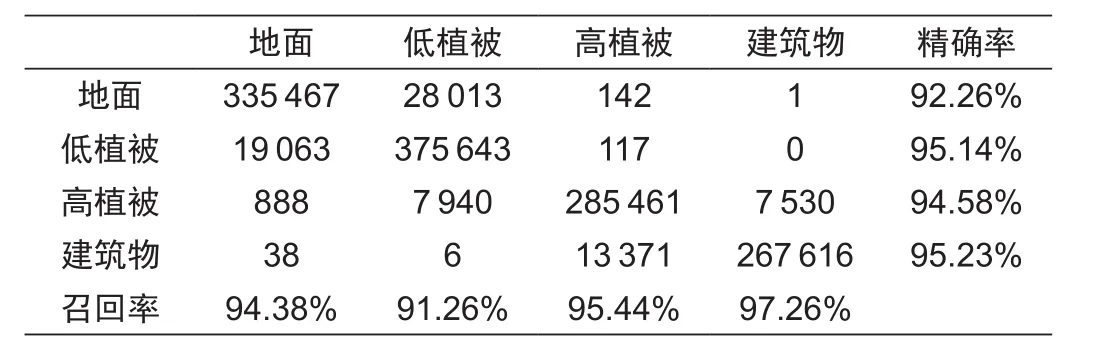
表5 分类混淆矩阵(场景II,总正确率:94.25%)Tab.5 Confusion matrix of classification ( Scene II, overall accuracy:94.25%)
3 结束语
对LiDAR数据进行分类、提取、建立三维城市模型具有重要的现实意义。为了提高从LiDAR点云数据中提取地物的效率与精确度,降低提取成本,本文在综合分析点云和影像数据特点的基础上,提出了融合影像信息的城区机载LiDAR点云自动化分类方法。考虑到点云数据存在大量的噪声点,因此,文中引入词袋模型用于描述和表达体素化的点云数据,这个过程能够有效地抑制点云中存在的噪声点,同时改善了分类过程中可能存在的“椒盐”现象。后期将继续基于词袋模型进一步挖掘点云体素的中层甚至是高层语义信息,提高点云分类的质量和效率。
猜你喜欢
计算机集成制造系统(2022年11期)2022-12-05 11:40:44
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
计算机集成制造系统(2020年4期)2020-05-08 02:41:16
阅读(快乐英语高年级)(2020年8期)2020-01-08 02:21:16
中国惯性技术学报(2019年1期)2019-05-21 00:58:46
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
智慧少年·故事叮当(2018年11期)2018-05-14 11:48:18
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
意林(绘英语)(2017年5期)2017-05-15 02:17:23
