
基于随机平衡采样的不平衡数据集分类算法研究
2017-10-16 08:15:51季梦遥
海南大学学报(自然科学版) 2017年3期
袁 磊,季梦遥
(1.武汉大学人民医院 信息中心,湖北 武汉 430000;2.武汉大学人民医院 消化内科,湖北 武汉 430000)
基于随机平衡采样的不平衡数据集分类算法研究
袁 磊1,季梦遥2
(1.武汉大学人民医院 信息中心,湖北 武汉 430000;2.武汉大学人民医院 消化内科,湖北 武汉 430000)
提出了随机平衡数据采样算法,以此为基础对AdaBoost算法进行修改并构建了随机平衡集成分类算法,采用6组UCI数据集对随机平衡集成分类算法进行实验,并与SMOTEBoost算法、RUSBoost算法、AdaBoost算法进行比较.实验结果表明,随机平衡数据集成算法具有更好的分类性能,在处理不平衡数据集方面有一定的优势,具有较强的多元性和鲁棒性.
不平衡数据集; 采样; 分类; 集成
传统的机器学习算法大都基于样本数据分布是平衡的[1-3],但是这种假设与实际中许多应用存在着冲突,例如在机器故障的诊断中,故障运行的比例远远低于正常运行的比例,此情况还广泛存在于网络入侵[4]、临床诊断[5-6]、信用卡欺骗[7]等.在现实世界中,样本的分布通常不均匀,此数据集称之为不平衡数据集.在不平衡数据集中,某些类的样本数目比其他类的样本数目大得多,其中样本较多的类称之为多数类,样本较少的类称之为少数类.目前,不平衡数据集的研究受到越来越多的学者重视,ICML[8],SIGKDD[9-10]等数据挖掘顶级会议都对不平衡数据集的挖掘进行讨论.许多学者也在研究不平衡数据集的分类问题,这些算法大致可以分为:1)算法层面的研究,如Hellinger Distance Decision Tree,HDDT[13]等;2)数据预处理方面的研究,如随机欠采样算法(RUS)[14]、随机过采样算法[15]、SMOTE算法[16]等;3)代价敏感学习方面的研究[17];4)集成学习方面的研究,如SMOTEBoost算法[18]、RUSBoost算法[19]等.文献[18-19]基本思想是在分类算法的每次迭代中引入SMOTE过采样技术,通过加入合成正例样本使每个基分类器更加关注正类样例.但是,新合成的样例只分布在原始样例的概率曲线上,不能很好地反映数据的实际分布,容易造成过拟合和加长训练时间的问题.
目前许多分类算法都是基于多数类学习得到的分类器,分类器对整体的预测准确率很高,但对少数有用信息的预测准确率却十分低,如决策树[11]、神经网络[12]等.对不平衡数据集的分类研究:1)可以增加分类器的性能,增加少数类信息的关注度;2)可以使分类器更加注重现实世界,增强分类器的实用性.因此,笔者提出了全新的随机平衡数据采样算法(Random Balance Sampling,RBS),将RBS算法与Boost算法相结合,提出了随机平衡集成分类算法—RBEBoost算法,RBEBoost算法是AdaBoost算法的一种改进算法. RBEBoost算法通过随机改变不平衡数据集的不平衡率,改变不平衡数据集的数据分布,对生成的数据集进行分类学习.实验结果证明随机平衡集成分类算器具有更强的多元性和鲁棒性.
1 随机平衡集成分类算法
1.1随机平衡取样算法随机平衡取样算法是一种通过调整依靠随机率(Random Ratio,RR)使不平衡数据集达到再平衡的一种数据再平衡技术,通过随机设定随机率使得集成分类器具有更强的适应性和多样性.
随机平衡采样算法的具体步骤可分为3个步骤:1)随机设定少数类和多数类的个数;2)用SMOTE算法分别增加相应类的样本数目来满足事先设定的期望值;3)重新生成数据集.随机平衡取样算法如图1所示.

图1 随机平衡取样算法
从图1可以看出,随机平衡采样算法克服了数据预处理方面的部分缺陷: 1)在不改变数据集大小的基础上,反复地以改变随机率改变数据集的数据分布,可以克服欠采样丢失有用信息的缺陷; 2)克服了SMOTE算法由于增加数据集的大小,导致学习时间增加的缺陷.
1.2理论分析随机平衡采样算法产生的新数据集由原始样本和人工合成的样本2个部分组成,但是新数据集包含少数类样本与多数类样本的概率不同.假设数据集大小为m,正类样本个数为p≥2,负类的样本个数为n,则可得如下定理.
定理1
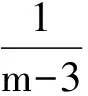
(1)
定理2
(2)

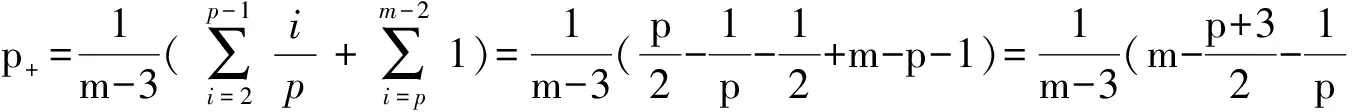
(3)
定理2的推导同定理1,此处不再介绍.
图2表示当m=1 000时,新数据集包含少数类样本与多数类样本的概率.图2表示新生成的数据集(m=1 000)包含多数类和少数类的概率,从图2中可以看出当数据集趋于平衡状态时,少数类入选新数据集的概率也呈下降趋势.当p≤n时,p+≥p-,p+≥0.75,p-≥0.5.对于一个平衡度较好的数据集(正类样本数和负类样本数相当)而言,包含少数类的概率略大于0.75.而同时丢失多数类信息的缺陷也会得到改善,这是由于对于每个基分类器而言,多数的样本个数略大于50%.由于当少数类较少时,少数类入选生成新数据集的概率远大于多数类入选的概率.同时,当数据集趋于平衡时,少数类与多数类入选的概率相当,这从根本上保证了生成的数据集可更好反映正类样本的分布,从而从理论上保证了新生成的数据集真实可靠.
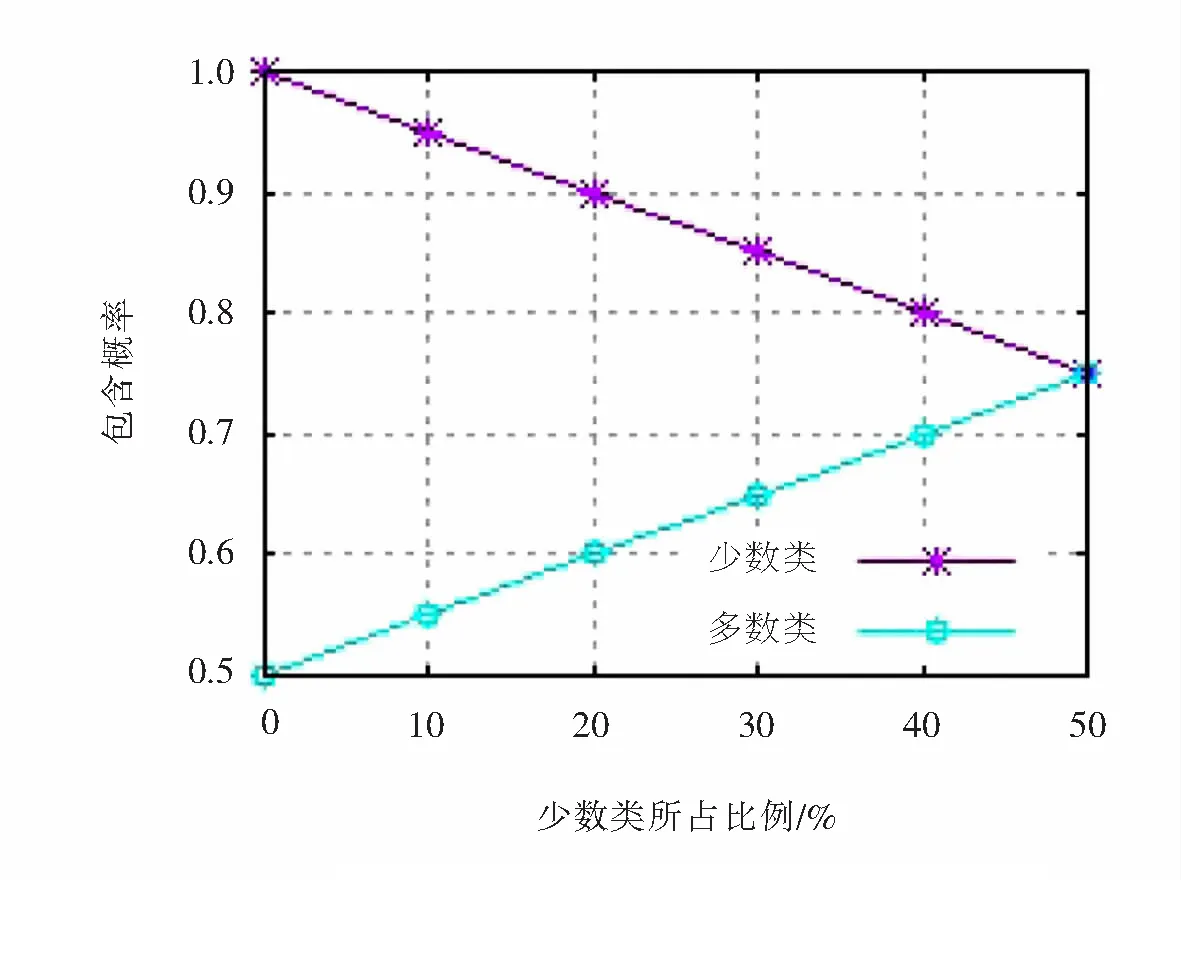
图2 数据集包含少数类与多数类概率图
1.3随机平衡集成分类算法RBEBoost算法每个循环的基本步骤:1)根据随机平衡采样算法产生新的数据集,对训练集中的每个样本赋予权重,若样本属于原数据集,则保持原权重,若属于新合成的数据而赋予新的统一权重;2)用弱分类器对训练集进行训练,并计算其分类性能;3)根据预测的性能更新样本的权值,对分错的样本赋予较高的权值.重复以上3个过程,最终生成集成分类器,其算法过程如图3所示.

图3 随机平衡集成分类算法
2 实验与分析
主要是设计实验对随机平衡集成分类算法进行性能分析,实验通过对6组不平衡数据集进行测试,并与当前处理不平衡数据集的经典集成算法分别进行对比,同时对4种方法的ROC曲线[21-22]、AUC和F-Measure进行分析,最后对集成分类器大小进行设定,通过实验研究集成分类器大小对集成分类器的性能的影响.
2.1实验数据本实验所用到的所有数据均来自于UCI数据集合,为了更好的验证该算法,对UCI数据进行了修改,其不平衡率从1.93~39.14,如表1所示.
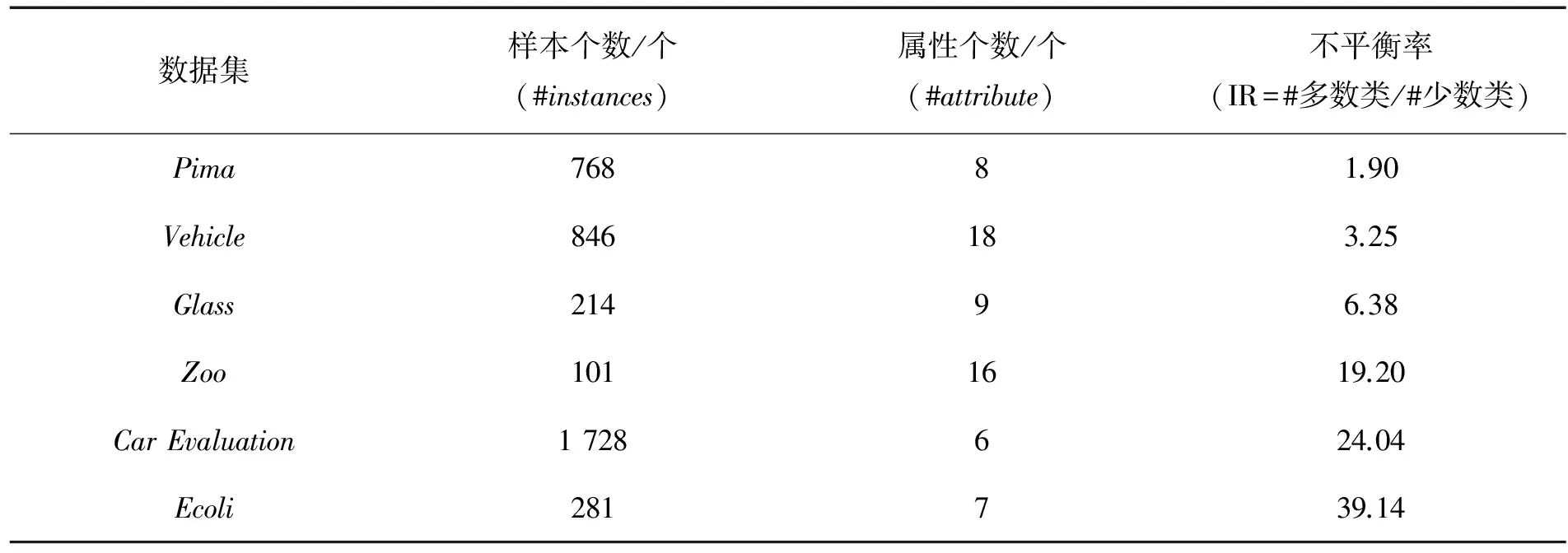
表1 实验数据
2.2结果分析对集成分类器的性能进行验证,基分类器为J48,集成分类器的大小为100,分别用4种集成分类算法对表1所示的6组不平衡数据集进行分类比较.6组不平衡数据的分类性能对比实验结果表2、图4所示,其中图4a、4b和4c分别为6组不平衡数据集的ROC曲线对比图.

表2 实验结果对比
图4a、4b和4c分别表示Vehicle数据集、Glass数据集和Ecoli数据集分别表示3个不平衡等级1~3、3~9和9以上.
从表2和图4可以看出: 1)RBEBoost算法在处理不平衡数据集方面比其他的集成分类算法在收敛性和分类性能上具有更好的效果; 2)RBEBoost算法在数据集不平衡率达到40时,仍具有较强的分类性能.
为了验证集成分类器大小对集成分类器性能(AUC和F-Measure)的影响,对集成分类器的大小进行了设定,其范围从5到100,集成分类器大小对分类器性能影响如图5所示.
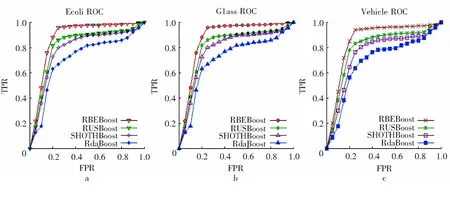
图4 ROC 曲线对比图

图5 集成分类大小对分类性能影响图
从图5可以看出,集成分类器性的性能随着分类器大小的增大而变佳,但是当分类器大小增加至一定数量时,集成分类器的性能并没有发生明显的变化.
3 结束语
提出了一种新的处理不平衡数据集的采样算法—随机平衡数据采样算法,并将这种算法与Boost算法相结合,提出了随机平衡集成分类算法—RBEBoost,并分析了随机平衡集成分类算法具有多元性和鲁棒性的理论依据.最后通过实验将RBEBoost算法、RUSBoost算法、AdaBoost算法和SMOTEBoost算法的分类性能进行比较,结果表明随机平衡集成分类算法在处理不平衡数据集具有更强的多元性和鲁棒性.不平衡数据集的分类是数据挖掘和机器学习中一个热门研究领域,RBEBoost算法主要是针对二分类问题,对多标签问题的研究是未来的一个研究方向.
[1]TütüncüGY,KayaalpN.AnaggregatedfuzzynaiveBayesdataclassifier[J].JournalofComputationalandAppliedMathematics,2015,286:17-27.
[2]SokHK,OoiPL,KuangYC,etal.Multivariatealternatingdecisiontrees[J].PatternRecognition,2016,50:195-209.
[3]LiH,ChungFL,WangS.ASVMbasedclassificationmethodforhomogeneousdata[J].AppliedSoftComputing,2015,36:228-235.
[4] 江颉,王卓芳,GongRS,等.不平衡数据分类方法及其在入侵检测中的应用研究[J].计算机科学,2013,40(4):131-135.
[5] 张金伟. 不平衡数据分类研究及在肿瘤识别中的应用[D].杭州:中国计量学院,2012.
[6] 郭维恒.脑卒中类型与复发的Logistic回归预测及SMOTE算法处理非平衡临床数据[D].石家庄:河北医科大学,2014.
[7]SahinY,BulkanS,DumanE.Acost-sensitivedecisiontreeapproachforfrauddetection[J].ExpertSystemswithApplications, 2013,40(15):5 916-5 923.
[8]WuG,ChangEY.Class-boundaryalignmentforimbalanceddatasetlearning:proceedingsoftheIcmlWorkshoponLearningfromImbalancedDataSets,WashingtonDC,August21, 2003[C].Brighton:EdwardoA.Garcia,2003.
[9]ChawlaNV,JapkowiczN,KotczA.Editorial:specialissueonlearningfromimbalanceddatasets[J].AcmSigkddExplorationsNewsletter, 2004,6 (1):1-6.
[10]PhuaC,AlahakoonD,LeeV.Minorityreportinfrauddetection:classificationofskeweddata[J].AcmSigkddExplorationsNewsletter, 2004,6(1):50-59.
[11]WeinerWJ.Analgorithm(decisiontree)forthemanagementofParkinson’sdisease(2001):treatmentguidelines[J].Neurology, 2001,58(1):156-162.
[12]HansenLK,SalamonP.Neuralnetworkensembles[J].IEEETransactionsonPatternAnalysis&MachineIntelligence, 1990,12(10): 993-1 001.
[13]CieslakDA,ChawlaNV.Learningdecisiontreesforunbalanceddata:proceedingsoftheEuropeanConferenceonMachineLearning,Antwerp,Belgium,September15-19, 2008[C].BerlinHeidelberg:Springer-Verlag, 2008.
[14]LiuXuying,WuJianxin,ZhouZhihua.Exploratoryundersamplingforclass-imbalancelearning:proceedingsoftheInternationalConferenceonDataMining,LasVegas,July13-16,2009[C].Edmonton:WitoldPedrycz,2009.
[15]BaruaS,IslamMM,MuraseK.Anovelsyntheticminorityoversamplingtechniqueforimbalanceddatasetlearning[M].Heidelberg:Springer, 2011.
[16]ChawlaNV,BowyerKW,HallLO,etal.SMOTE:syntheticminorityover-samplingtechnique[J].JournalofArtificialIntelligenceResearch, 2011,16(1):321-357.
[17]CaoP,ZhaoD,ZaianeO.AnOptimizedCost-SensitiveSVMforImbalancedDataLearning[M].Heidelberg:Springer,2013.
[18]ChawlaNV,LazarevicA,HallLO,etal.SMOTEBoost:improvingpredictionoftheminorityclassinboosting[J].LectureNotesinComputerScience, 2003 (2838): 107-119.
[19]SeiffertC,KhoshgoftaarTM,VanHulseJ,etal.RUSBoost:ahybridapproachtoalleviatingclassimbalance[J].IEEETransactionsonSystemsManandCyberneticsPartASystemsandHumans, 2010,40(1) :185-197.
[20]WangS,YaoX.Diversityanalysisonimbalanceddatasetsbyusingensemblemodels:proceedingsofthe2009IEEESymposiumonComputationalIntelligenceandDataMining,Nashville,March30 -April2,2009[C].[S.l.]:IEEE, 2009.
[21]DavisJ,GoadrichM.TherelationshipbetweenPrecision-RecallandROCcurves:proceedingsofthe23rdInternationalConferenceonMachineLearning,Pittsburgh,June25-29, 2006[C].Pittsburgh:WilliamW.Cohen, 2006.
[22]FawcettT.AnintroductiontoROCanalysis[J].PatternRecognitionLetters, 2006,27(8): 861-874.
Abstract:In the report, a new algorithm (Random Balance Sampling Algorithm, RBS) was proposed, and on which AdaBoost algorithm was modified and RBE Boost (Random Balance Ensemble Boost Algorithm ) was constructed. 6 UCI data sets were used to test our proposed algorithm. The results showed that the robustness and diversity of our proposed method were better than that of SMOTEBoost, RUSBoost, and AdaBoost.
Keywords:imbalanced data set; sampling; classifier; ensemble
SortingAlgorithmBasedonRandomBalanceSamplingforImbalancedData
Yuan Lei1, Ji Mengyao2
(1.Deparment of Information Center,RenMin Hospital of Wuhan University, Wuhan 430000, China;2.Derparment of Gastroenterology,Renmin Hospital of Wuhan University,Wuhan 430000,Chin)
TP 391.9
A DOl:10.15886/j.cnki.hdxbzkb.2017.0037
2017-03-10
袁磊(1982-),男,湖北武汉人,硕士,研究方向:数据挖据与计算机应用,E-mail:yuanlei009@163.com
1004-1729(2017)03-0228-06
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05 06:49:10
中学生数理化·中考版(2021年6期)2021-11-22 07:52:30
新世纪智能(数学备考)(2021年4期)2021-08-06 09:04:50
新世纪智能(数学备考)(2021年4期)2021-08-06 09:04:50
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
电子测试(2018年1期)2018-04-18 11:52:35
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
光学精密工程(2016年4期)2016-11-07 09:05:00
