
Caffe并行实现算法研究
2017-10-09 08:36
福建质量管理 2017年16期
(沈阳理工大学信息科学与工程学院 辽宁 沈阳 110159)
Caffe并行实现算法研究
孟思彤辜阳
(沈阳理工大学信息科学与工程学院 辽宁 沈阳 110159)
本文首先分析了单机版本Caffe的缺点和实现分布式的原因,再分别介绍了Caffe的基于同步式SGD、异步式SGD和改进的异步SGD三种不同的并行实现方式,最后通过分析了三种方式的优缺点,得出改进的异步式SGD效果最好结论。
Caffe;同步式SGD;异步并行;改进异步式SGD
一、引 言
随着对深度学习领域研究的深入,有证据表明增大模型参数规模和训练数据集,能有效的提高模型准确率。152层残差网络(ResNet)结构[1]的提出和大数据时代超过TB的训练数据,带来了精度上的提升,同时也带来了巨大的训练时间成本,仅仅使用目前的单机版本深度学习工具加GPU计算的方式,已经不能满足其要求的计算能力和存储空间。当前热门的深度学习工具,如TensorFlow、MXNet、Torch、CNTK等都在设计初期,基于参数服务器结构实现了自己的分布式版本,支持并行训练。
Caffe作为一个高效、实用的老牌开源深度学习框架[2],已经在计算机视觉,文本处理,自然语言识别等领域取得卓越成就,得到了学术界和工业界广泛的认可。然而Caffe在设计初期声称的高速运算,只是简单的采用GPU加速计算,并没有实现并行训练的方式,这显然与当前深度学习的发展趋势不符。
分布式深度学习框架包含模型并行和数据并行两种,由于数据并行化在实现难度、容错率和集群利用率方面都优于模型并行化,所以现有的分布式深度学习框架大多采用数据并行方式,本文所讨论的SGD并行算法也是基于数据并行。
二、同步式SGD
前不久,雅虎开源了基于Spark平台的Caffe并行版本CaffeOnSpark,与其他专门搭建的深度学习集群不同,支持直接在Spark集群上进行深度学习,避免了训练数据的传输,同时支持yarn的管理调度,能同时进行多个训练任务。CaffeOnSpark在参数同步时采用的是同步式SGD结构,标准的同步SGD算法,每次迭代都分为三个步骤,首先,从参数服务器(Parameter Server,PS)中把模型参数w拉取(pull)到本地,接着用新的模型参数w计算本地mini-batch的梯度Δw,最后将计算出的梯度Δw推送(push)到PS。PS需要收集所有worker的梯度,再统一进行平均处理更新模型参数,同步式算法如图1所示。
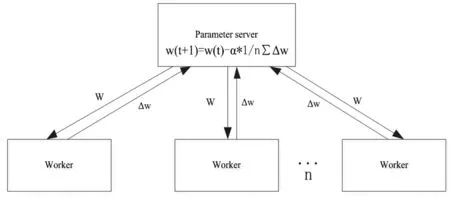
图1 同步式SGD算法图
当集群中各个机器之间性能有差异时(即计算一个mini-batch花费时间不同),将会导致所有的worker都要等待计算最慢的一个执行完,产生等待时间开销,我们称为木桶效应问题。当忽略机器之间的性能差异,所有worker同时完成一个mini-batch计算,则会一起向参数服务器发送梯度值,而没有抢占到资源的worker会被放入等待队列排队,参数服务器向worker发送更新后的参数时,同样是依次发送,worker需要排队等待,浪费计算时间,我们称为通信冲突。
三、异步式SGD
当前热门的分布式深度学习框架大多采用异步随机梯度下降算法(ASGD),参数服务器只要接收到worker的梯度值就进行更新,把更多的时间用于计算,而不是等待参数服务器的平均操作,消除了木桶效应问题,并且利用梯度的延迟更新,减少了网络通信量,降低网络通讯造成的时间开销,获得明显加速。文献[3]证明算法是收敛的,但是通信冲突问题仍然存在,而且还会导致梯度值过时问题,计算梯度需要消耗时间,当某个节点算完了梯度值并且将其与参数服务器的全局参数合并时,全局参数可能已经被更新了多次,梯度值过时会降低算法的收敛速率,同时导致模型准确率下降。
四、改进的异步式SGD
在上述问题的研究基础上,我们发现机器性能差异越大,即完成一个或多个mini-batch的时间差越大,通信等待时间越小。文献[4]提出一种改进的异步式随机梯度算法,采用随机数据分片方式,进一步加大完成时间差,使其尽可能小,达到进一步减少训练时间目的。针对ASGD算法的梯度值过时问题,改进的异步式算法使用了一种弱同步策略,在系统性能跟算法收敛速率之间进行权衡,引入参数s来控制模型更新,只有在接收到n个Caffe进程的s次梯度更新,模型参数才进行更新。
五、结束语
同步式SGD算法实现了Caffe的并行,ASGD算法实现了Caffe的异步并行,改进的异步算法通过分析ASGD算法的通信冲突,发现可以通过加大各个worker完成mini-batch的时间差,能缓解通信冲突,并采用一种弱同步策略,减弱梯度过时的影响。通过实验验证,改进的ASGD算法确实能带来训练速率和模型准确率的提升,但同时也带来了一些额外的超参数,如npush和npull间隔的轮数,参数服务器进行更新的次数s,比起同步式SGD调参更为困难。
[1]Kaiming He,Xiangyu Zhang,Shaoqing Ren,et al. Deep Residual Learning for Image Recognition[J]. In CVPR,2016.
[2]Yangqing Jia. Caffe: A fast open framework for deep learning [EB/OL]. http://caffe.berkeleyvision.org.
[3]Zinkevich M,Langford J,Smola A. Slow learners are fast [C]. Advances in Neural Information Processing Systems 22 (NIPS 2009),2009:2331-2339.
[4]Dean J, Corrado GS, Monga R, et al. Large scale distributed de-ep networks [C]. International Conference on Neural Information Processing Systems. Curran Associates Inc. 2012:1223-1231.
孟思彤(1993-),女,汉族,辽宁本溪人,硕士,研究方向网络管理与系统监控,深度学习;辜阳(1993-),男,汉族,湖北汉川人,硕士,研究方向图像处理与分析技术,深度学习。
猜你喜欢
数学物理学报(2021年6期)2021-12-21
应用数学(2020年2期)2020-06-24
军事运筹与系统工程(2019年4期)2019-09-11
数学年刊A辑(中文版)(2018年2期)2019-01-08
电子制作(2018年11期)2018-08-04
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
雷达与对抗(2015年3期)2015-12-09
