
基于大数据智能的找矿模型构建与预测
2017-09-18 02:44吴永亮贾志杰陈建平朱月琴
中国矿业 2017年9期
吴永亮,贾志杰,陈建平,朱月琴
(1.中国地质大学(北京)地球科学与资源学院,北京 100083;2.北京市国土资源信息研究开发重点实验室,北京 100083;3.中国航天标准化与产品保证研究院,北京 100071;4.中国地质调查局发展研究中心,北京 100037;5.国土资源部地质信息技术重点实验室,北京 100037)
基于大数据智能的找矿模型构建与预测
吴永亮1,2,3,贾志杰1,2,陈建平1,2,朱月琴4,5
(1.中国地质大学(北京)地球科学与资源学院,北京 100083;2.北京市国土资源信息研究开发重点实验室,北京 100083;3.中国航天标准化与产品保证研究院,北京 100071;4.中国地质调查局发展研究中心,北京 100037;5.国土资源部地质信息技术重点实验室,北京 100037)
当前地质科学数据呈现出科学大数据的特点,依靠传统人工检索和处理地质大数据具有很大的局限性,难以满足当前地质科学高速发展的需求。针对找矿地质模型建立与预测需求,本文利用大数据发现方法实现了地质找矿专题数据的自动采集;利用机器学习方法对地质专题数据进行深层次的挖掘和提取,研究了基于大数据智能的找矿模型预测方法。在已有地质成矿理论的基础上,建立了统一的多数据源找矿地质模型库,使用朴素贝叶斯分类算法对找矿概念模型库中数据进行分类研究,通过计算模型中控矿要素的使用率和重要性来建立起全面客观的找矿地质模型,最终实现找矿模型预测。
地质大数据;人工智能;找矿模型
地质学属于数据密集型科学,随着地质信息时代的来临,地质数据已呈现出爆炸式增长态势,面临着数据量巨大、挖掘效率低等问题[1-3],仅依靠人工检索与处理地质大数据越来越难以满足当前地质科学高速发展的需求[4-5]。随着AlphaGo在围棋对弈取得了举世瞩目的成就,人工智能的发展应用也达到了高峰,这为地学研究提供了新的思路[6-7]。人工智能是利用计算机来模拟人脑从事的推理、学习、思考等活动,以人类智力开展图像识别、自然语言理解等复杂问题。人类习得语言、思维的过程,就是从大数据学习的过程。因此,大数据是实现人工智能的重要支撑,而大数据智能则是基于大数据驱动的人工智能[8-9]。地学领域既有大数据的基础,又有利用人工智能解决成矿预测、资源评价、环境保护等复杂问题的需求。
国务院印发的《新一代人工智能发展规划》(国发〔2017〕35号)提出了研究“数据驱动与知识引导相结合的人工智能方法”大数据智能理论的重要目标。如何利用人工智能手段有效的发现和获取地质大数据,挖掘出高价值信息与知识,解决地学问题并实现相应地质服务具有重大意义[5]。本文从地质大数据发现与挖掘入手,探索了地质大数据驱动与知识引导相结合的人工智能应用方法,建立了地质找矿数据模型,研究了基于大数据智能实现的找矿模型预测方法,开发了相应的软件系统并进行了应用实验。结果表明,本文给出基于大数据智能的找矿模型预测方法有效可行,为利用计算机发现、挖掘地质大数据,开展找矿地质模型预测工作探索出具有实用价值的技术方法。
1 地质大数据发现与挖掘
1.1研究方法
发现地质大数据是实现人工智能处理大数据的前提条件,挖掘地质大数据是解决问题的重要手段。利用计算机从纷杂的数据海洋中发现需要的地质数据,然后对各类结构、半结构化、非结构化的数据进行信息抽取与挖掘,得到数据的潜在规律与有价值的信息,不断的循环迭代,最终解决成矿预测、地质规律研究、资源评价等地质科学问题,见图1。
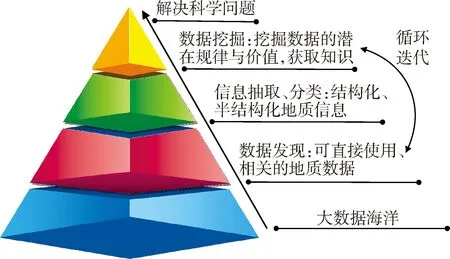
图1 地质大数据发现与挖掘
数据发现任务就是采集地质专题数据,根据需求从互联网中获取到关心的地质数据并存储到本地计算机或数据库服务器中,从而开展下一步的处理和分析。数据发现在注重地质专业数据采集方法实现的同时,也要注重数据采集的效率。不仅要采集到地质专题数据,还能实现半自动化甚至自动化的数据采集[10]。目前,对于互联网数据采集的主要分为两部分,即互联网数据爬取和信息提取。
数据挖掘又称数据库中的知识发现,将数据库技术、统计学、机器学习、信息检索技术、数据可视化和模式识别与人工智能等领域有机结合起来,从而能从数据中挖掘到其他传统方法不能发现的有用知识[11-12]。数据挖掘任务一般可以分两类:描述和预测。描述性挖掘任务是分析数据库中数据的一般特性,预测性挖掘任务在当前数据上进行推断。数据挖掘技术主要又分成“关联规则”,“时间序列”,“聚集”,“分类”等[13]。
本文针对地质找矿需求,在传统地质找矿数据应用的基础上,采取大数据发现方法采集找矿专题信息数据,利用大数据挖掘方法开展地质找矿模型预测,最终实现大数据智能在地质找矿领域的应用。
1.2技术方法及模块功能
针对地质大数据智能应用需求,利用C#开发语言和MySQL数据库,集成了Nherbinate框架工具,采用较成熟的C/S体系结构及目录服务器搜索模式,开发了地质大数据发现与挖掘系统实现上述工作,可以实现地质专题数据采集、地质找矿模型构建与预测等功能,技术方法见图2。系统主要模块功能以下包括几方面。
1)地质大数据发现模块主要功能是通过爬虫和正则表达式实现公域网数据的爬取和抽取,通过调用Everything.dll的方法实现局域网络内计算机本地数据的全盘搜索和获取,对采集到的数据按统一的清洗和存储规则进行处理,获得地质找矿专题大数据。
2)数据挖掘模块的主要功能是在获取的研究区地质专题数据的基础上,结合人工选择确认的方式整理数据,将传统地质找矿模型进行系统的归纳与总结,获得研究区的控矿要素,建立统一的找矿概念模型数据库。使用朴素贝叶斯分类算法对研究区数据进行模型分类、匹配、计算等工作,实现找矿模型预测。将经过验证后的找矿模型添加到原有数据库中,作为下次机器学习的训练样本,形成从数据-信息-知识-价值服务-再数据的大数据应用链。随着建立的找矿概念模型越多,系统的人工智能经验越来越丰富,最终预测的研究区找矿模型结果将越来越准备。
2 找矿地质模型
2.1找矿模型理论依据
找矿模型以地质成矿理论为依据,相关地质成矿规律与成矿预测理论包括:朱裕生等的矿床成矿模式理论[14]、翟裕生等的成矿系统理论[15]、程裕淇等的矿床成矿系列理论[16]、涂光炽等关于大型、超大型矿床的成矿和找矿理论[17]等。找矿模型以不同控矿要素为基础,在区域地质背景、成矿规律与成矿模式的基础上构建的区域找矿模型,形成找矿模型预测方法指导找矿。例如:大多已知成矿区带的大地构造背景决定着预测区的选择,大多已知矿床的形成时代决定着成矿期的确定,大多已知矿床的成矿条件、控矿要素和找矿标志决定着找矿模型等。找矿模型可突出主要的控矿因素、抓住找矿的关键信息、提出获得关键信息的有效方法组合、总结主要找矿标志组合、简化找矿实际过程,是进行成矿预测的主要依据[18]。
2.2找矿模型构建
找矿模型构建是在地质大数据的基础上,建立找矿模型和找矿模型数据库,为机器学习提供重要的数据基础。根据已有文献等数据,分析研究区区域成矿地质背景及典型矿床控矿条件,总结区域成矿规律,建立区域找矿概念模型,分析主要矿床类型、控矿因素和找矿标志[19]。找矿模型构建主要包含两部分工作:第一,进行数据整理,将各种矿床模型名称以及控矿要素进行统一;第二,建立起结构统一、易于理解的找矿模型数据库,为建立找矿概念模型提供训练数据。
2.2.1 数据整理
模型的数据整理主要包括两个方面。一是模型名称的整理。模型名称一般分为两类,一类是典型矿床式命名,例如山东焦家金矿;一类是抽象总结式命名,例如岩浆岩型稀土矿。这两种模型名称在数据整理过程中无法统一,因此将模型中的关键词进行统一。二是控矿要素的整理。随着模型数量的增多,而同一控矿要素会重复出现。在不同的地质数据资料中,控矿要素文本数据并不严格一致。为了使计算机能够准确识别控矿要素,必须保证同一个控矿要素文本数据具有唯一性。
2.2.2 建立找矿模型数据库
在地质大数据机器学习中,需要建立统一的,适用所有的矿床成矿模式或矿床式(代表在成矿作用发生、发展、演化过程的某个时期,在相似地质条件下形成的典型矿床)的找矿概念模型数据结构。由于资料来源不同及资料的成矿地质条件和矿产勘查程度存在差异,造成了建立找矿模型时,对其理解和具体操作出现不统一的结果,同一名称属不同概念,不同名称又属同一内涵的现象在不同资料中普遍存在。因此依据地质大数据建立起每一个找矿模型与控矿要素的对应关系。
找矿模型数据来源主要有北京市国土资源信息研究开发重点实验室已有找矿模型以及相关文献中整理的找矿模型等,目前已经建立了全国矿产资源潜力评价预测模型88个、全国典型矿床成矿模型257个。
3 找矿模型预测方法
找矿模型预测的本质是找矿模型文本数据的分类,它的核心是提取分类数据特征,然后选择找矿模型最优匹配,从而进行分类。
3.1模型分类
模型分类是通过朴素贝叶斯文本分类方法将找矿概念模型库中现有数据作为训练样本,以研究区的控矿要素作为待处理数据,对研究区资料进行分类,计算对研究区控矿要素的条件概率,判断其属于模型库中每个模型的概率。
假设有m个找矿地质概念模型y1,y2,…,ym,记为Y,见式(1),每个模型所对应的控矿要素分别为F1,F2,…,Fm。
Y={y1,y2,…,ym}
(1)
研究区内收集到n个控矿要素,将这些属性作为一个向量,记为X。{y1,y2,…,ym}中的概率值为{p1,p2,…,pm},其中Pi为X属于yi的概率。假设第i个找矿地质模型有ki个控矿要素,记为Fi,见式(2)。
Fi={f1,f2,…,fki}
(2)
因此,m个找矿地质概念模型中共有H个控矿要素,见式(3)。
(3)
每个找矿地质概念模型所对应的先验概率P(yi),见式(4)。
(4)
记研究区中第j(1≤j≤n)个控矿要素在第i(1≤i≤m)个找矿地质概念模型Yi概率为p(xj|yi),由于各个控矿要素是条件独立的,则根据贝叶斯定理可得研究区属于m个找矿地质概念模型的概率P(yi|X),见式(5)。
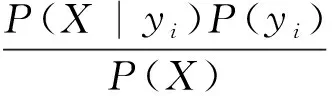
(5)
因为分母对与所有类别为常数,因此只要将分子最大化皆可,又因为各个控矿要素是条件独立的,所以有式(6)。
P(X|yi)p(yi)=P(x1|yi)P(x2|yi)…

(6)
分类结果P见式(7)。
P={p1,p2,…,pm}
(7)
其中,Pj是研究区控矿要素属于模型Yj的概率。
3.2模型匹配
找矿模型匹配分为两步:第一步为关键词匹配,关键词由中文分词结果中选取及手动添加得到,多个关键词与模型名称进行匹配;第二步为研究区控矿要素与找矿模型中的控矿要素匹配,筛选出m个找矿模型M1,M2,…Mm,每个模型有n个不等的控矿要素F1,F2,…Fn。
3.3模型计算
3.3.1计算控矿要素重要性
根据筛选出的m个找矿概念模型M1,M2,…Mm,每个模型所对应的控矿要素分别为F1,F2,…Fm。对于第i个模型,在控矿要素数据清洗过程中按控矿地质条件类别不同分为ci类,将所有控矿要素按照控矿地质条件类别统计,每类所对应的控矿要素个数分别为Numi1,Numi2,...Numici(1≤i≤m),则在第i个模型的第j类中,每个控矿要素的重要性pij见式(8)。
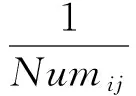
(8)
其中,i取值范围为[1,m],j取值范围为[0,ci]。
由于一个控矿要素可能出现在多个模型中,所以对于研究区中任意一个控矿要素将在其每个模型中的重要性pij加起来得到这个控矿要素的最终重要性指标。重要性P的计算公式为式(9)。
P=∑pij
(9)
其中,pij为每个模型中控矿要素的重要性。
3.3.2 计算控矿要素的使用率
根据筛选出的m个找矿地质概念模型M1,M2,…Mm,每个模型所对应的控矿要素个数分别为N1,N2,…Nm,共计有H(N1+N2+…+Nm=H)个(不删除重复的控矿要素),则可得第i个控矿要素的使用率计算公式为式(10)。

(10)
其中i的取值范围为[1,H]。
3.4模型验证
为了验证模型计算的正确性,通过在找矿概念模型数据库选择一个模型,删除其中多个控矿要素,如果模型匹配结果中有删除的控矿要素,即该计算结果可靠。例如,选择数据库中热液型硫铁矿进行验证。选择研究区控矿要素,删除成矿时代和含矿岩系。验证结果显示包含成矿时代和含矿岩系,因此计算方法通过现有模型验证。
4 应用实验
4.1数据发现
以焦家金成矿带作为实例应用进行验证,主要流程包括数据发现、控矿要素选取、机器学习、模型计算,找矿概念模型输出。工作区位于焦家近况成矿带上,行政区划隶属于莱州市、招远市,面积约180 km2。资料收集是通过数据发现系统对北京市国土资源信息研究开发重点实验室局域网以及知网等网站进行自动检索与采集,经人工确认后获取了研究区地调网页信息35份,勘查成果报告204份,区域地质资料17份,科研专著8份、论文193篇,为建立初步找矿概念模型提供了数据基础。
4.2控矿要素分析与模型构建
通过研究分析焦家金成矿带上的大中型典型矿床地质特征及控矿要素,确定研究区的地质找矿信息的控矿要素如下。
1)成矿时代。现有矿床主要赋存在中生代岩体边缘或者两种岩体的接触带上。
2)成矿环境。俯冲背景下的伸展拉张环境下,压扭性构造控矿。
3)控矿构造。主要的控矿构造是北东-北北东向断裂构造,其中焦家主干断裂、河西支断裂和望儿山支断裂是主要的赋矿断裂构造,同时灵北断裂及其他次级断裂构造对金矿床亦有明显的控制作用。
4)围岩蚀变。硅化与金矿形成关系较为密切,它是热液中的二氧化硅在外部作用下形成的硅化石英,它与斜长石或钾长石的交代作用使得其呈现残留体特征。绢云母化及黄铁矿化是和矿化关系最密切的蚀变特征,胶西北金矿中广泛存在的围岩蚀变就是黄铁绢英岩化作用;碳酸岩化是岩石受到热液蚀变后产生的,共生的有绿泥石化,它是破碎蚀变带的一种重要蚀变作用,通过作为研究热液活动结束的标志,在金矿化中碳酸盐化标志着矿化的结束。
5)含矿岩系。主要矿体一般赋存于主裂面下盘0~40 m范围内的黄铁绢英岩化碎裂岩带和黄铁绢英岩化花岗质碎裂岩带,其构造活动强烈,破碎程度高、裂隙发育、孔隙度大,有利于矿液的渗滤、扩散和交代,矿化富集程度高。
依据研究区分析结果,在找矿模型数据库中选取对应的控矿要素,添加新增控矿要素,建立研究区初始找矿模型作为待处理输入数据,通过软件系统进行预测计算。
4.3找矿模型预测计算
找矿概念模型库中数据作为训练集,依据朴素贝叶斯算法对研究区进行分类;分类结果是每一个找矿模型的概率,并按概率大小排序;依据关键词从分类结果名称中检索与研究区关键词相关的模型,完成模型匹配;对匹配成功的多个模型,分析模型中的控矿要素,计算每个控矿要素出现的次数,统计在同一个模型中此控矿要素对应的控矿要素类别的个数,依据此结果计算每个控矿要素在模型中的重要性,最终将所有模型中同一控矿要素的重要性之和累加。
对控矿要素依据使用率和重要性进行排序,结合专家知识,选取排序靠前且研究区初始找矿模型中缺失的控矿要素作为补充。经过人机交互,本次计算结果为缺失地球化学和地球物理两项。从相关参考文献及数据资料中将相应控矿要素变量特征补充到研究区找矿模型中,见表1。
4.3.1 地球物理找矿模型
矿体中,因硅化影响而呈较弱的高阻异常,第四系覆盖的不均匀对视电阻率有较大影响。矿体在平面上投影与视极化率异常对应较好。从已知的金矿床看,其中大部分矿床所在区域是平缓的弱磁场和负磁场区,磁场为低缓变场。布格重力异常显示为中部重力低,西部和东部重力相对高的两高一低异常,区内北东向、近东西向异常错动带。
4.3.2 地球化学找矿模型
研究区金矿床的指示元素为An、Hs、As、Bi、Ni、As、Pb、Cu、Zn和S,其异常的规模、强度与金矿化的规模有明显的相关关系,各元素的分带趋势是:矿体头部指示元素为:Hg、Ag、Sb、Pb,近矿指示元素是As、Au、Zn,矿尾指示元素是Bi、Cu等,它们是找矿的直接标志。
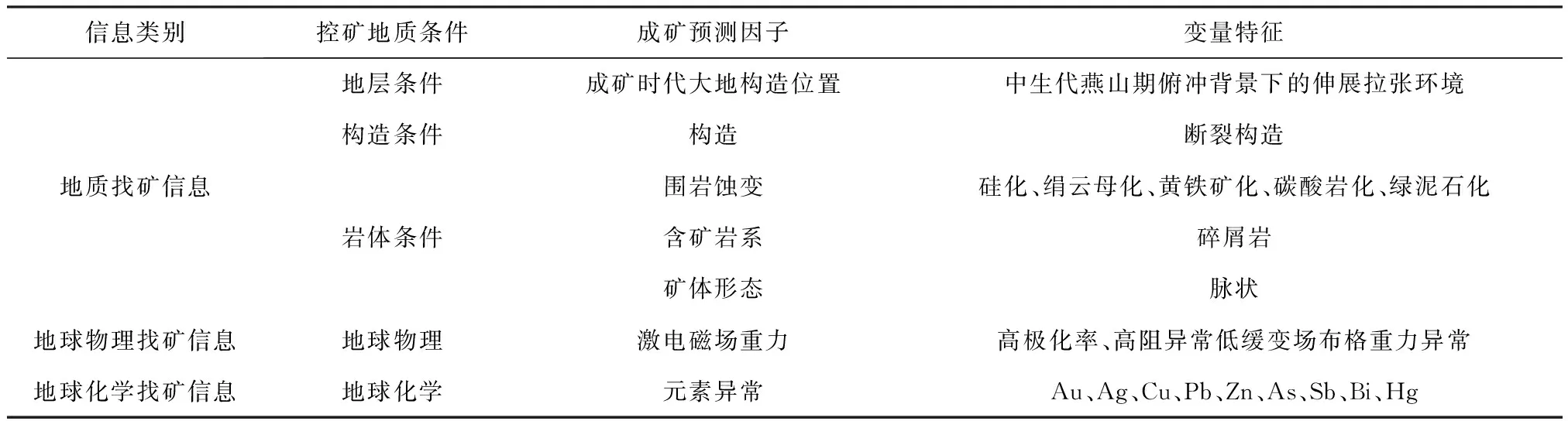
表1 找矿地质模型输出
经过预测计算并补充控矿要素后,建立起完整的焦家金矿找矿模型,将模型添加到已有数据库中。这些找矿模型不仅是基于地质大数据下的矿床形成条件和特征概况,也反映成矿地质理论的表达形式。随着数据库中的找矿模型不断丰富,预测结果越来越可靠,能有效的指导找矿勘查。
5 结 论
1)提出了基于大数据智能的找矿概念模型构建与预测方法,实现了地质找矿专题数据的自动采集,对地质数据进行挖掘和提取,是信息时代背景下大数据的理念、技术和方法在地质领域的应用与实践。
2)研究了基于地质成矿理论的找矿地质模型构建方法,将机器学习算法引入到找矿概念模型预测中并开发了相应的软件系统,以焦家金成矿带研究区为例对系统所提出研究区找矿概念模型进行示范研究,实验表明本方法可科学匹配、推送数据库中最佳的找矿模型。
3)提出了模型分类结果中控矿要素评价算法,该算法能通过分类计算得出研究区属于每个模型的概率以及控矿要素重要性,帮助地质工作者更好评价每个模型中的控矿要素。
4)现有找矿模型知识库数据量不足,目前已完成《全国矿产资源潜力评价预测模型》及《全国典型矿床成矿模式》共345个找矿模型的建立,需要进一步从相关地质数据中搜集并整理找矿模型。此外,仅依据使用率和重要性评判模型控矿要素,不能满足最优找矿模型评价需求。下一步工作重点是补充找矿模型数据以及完善控矿要素评价算法。
[1] Gölzer P,Simon L,Cato P,et al.Designing Global Manufacturing Networks Using Big Data[J].Procedia Cirp,2014,33:191-196.
[2] Guo H,Wang L,Chen F,et al.Scientific big data and Digital Earth[J].Chinese Science Bulletin,2014,59(35):5066-5073.
[3] Lee J G,Kang M.Geospatial Big Data:Challenges and Opportunities[J].Big Data Research,2015,2(2):74-81.
[4] 陈建平,李婧,崔宁,等.大数据背景下地质云的构建与应用[J].地质通报,2015,34(7):1260-1265.
[5] 赵鹏大.数字地质与矿产资源评价[J].地质学刊,2012,36(3):225-228.
[6] 刘知远,崔安颀,等.大数据智能[M].北京:电子工业出版社,2016.
[7] Ranina R,Madhavan A,Ng A Y.Large-scale deep unsupervised learning using graphics processors[J].International Conference on Machine Learning,2009:873-880.
[8] Manegold S,Kersten M.Big Data[J].ERCIM News,2012,89:33-36.
[9] 赵国栋,易欢欢,糜万军,等.大数据时代的历史机遇[M].北京:清华大学出版社,2013.
[10] 徐春凤,王艳春,翟宏宇.全自动网页信息采集系统[J].长春理工大学学报:自然科学版:,2015(2)2:151-154.
[11] 王树良,丁刚毅,钟铭.大数据下的空间数据挖掘思考[J].中国电子科学院学报,2013,8(1):10-16.
[12] Fu T C.A review on time series data mining[J].Engineering Applications of Artificial Intelligence,2011,24(1):164-181.
[13] 刘大有,陈慧灵,齐红,等.时空数据挖掘研究进展[J].计算机研究与发展,2013,50(2):225-239.
[14] 朱裕生,梅燕雄.成矿模式研究的几个问题[J].地球学报,1995,16(2):182-189.
[15] 翟裕生,邓军,李晓波.区域成矿学[M].北京:地质出版社,1999.
[16] 程裕淇,陈毓川,毛景文,等.初论矿床的成矿系列问题[J].中国地质科学院院报,1979(1):1-7.
[17] 涂光炽.超大型矿床的找寻和理论研究[J].矿产与地质,1989(1):1-8.
[18] 邵拥军,彭省临,吴淦国.大型矿山接替资源定位预测的途径及其研究意义[J].矿产与地质,2005,19(1):16-18.
[19] 于萍萍,陈建平,柴福山,等.基于地质大数据理念的模型驱动矿产资源定量预测[J].地质通报,2015,34(7):1333-1343.
Constructionandpredictionofprospectingmodelbasedonbigdataintelligence
WU Yonglinag1,2,3,JIA Zhijie1,2,CHEN Jianping1,2,ZHU Yueqin4,5
(1.School of Earth Sciences and Resources,China University of Geosciences(Beijing),Beijing100083,China;2.Beijing Key Laboratory of Development and Research for Land Resources Information,Beijing100083,China;3.China Academy of Aerospace Standardization and Product Assurance,Beijing100071,China;4.Development and Research Center,China Geological Survey,Beijing100037,China;5.Key Laboratory of Geological Information Technology of Ministry of Land and Resources,Beijing100037,China)
Geological science data present the characteristic of big data.Traditional manual retrieval and processing geological data has great limitations.It is difficult to meet the high-speed development requirement of the current geological science.Aiming at the establishment and prediction of prospecting geological model,this paper makes use of the big data discovery method to realize the automatic collection of geological prospecting thematic data.By using the machine learning method,the geological thematic data is mining deeply,and the prediction method of prospecting model based on big data intelligence is researched.On the basis of the existing geological metallogenic theory,a unified geological prospecting model library of multi-source data is established.Naive bayesian classification algorithm is used for prospecting concept model library classify data.By calculating model control utilization rate of mineral elements and importance,the comprehensive and objective prospecting geological model is establish to realize the prediction of prospecting model.
geological big data;artificial intelligence;prospecting model
2017-06-17责任编辑:赵奎涛
国土资源部公益性行业科研专项项目资助(编号:201511079)
吴永亮(1987-),男,博士研究生,从事地球探测与信息技术、航天标准化技术研究,E-mail:andyloveti@163.com。
陈建平(1959-),男,教授,博士生导师,从事矿产资源定量预测评价和"3S"技术集成应用的教学与研究,E-mail:3s@cugb.edu.cn。
P628
:A
:1004-4051(2017)09-0079-06
猜你喜欢
纺织科技进展(2021年5期)2021-07-22
矿产勘查(2021年3期)2021-07-20
矿产勘查(2021年3期)2021-07-20
矿产勘查(2021年3期)2021-07-20
矿产勘查(2020年2期)2020-12-28
矿产勘查(2020年6期)2020-12-25
矿产勘查(2020年6期)2020-12-25
矿产勘查(2020年5期)2020-12-19
军事运筹与系统工程(2018年3期)2018-03-26
商业经济研究(2016年24期)2017-01-10
