
基于隐式时间查询的文档排名方法
2017-09-09 01:38王晶晶
软件导刊 2017年8期
王晶晶


摘 要:时态信息检索是近年来的研究热点,很多解决方案是在检索模型中考虑时间相关性。提出一种支持隐式时间查询的文档排名方法,使用考虑内容相关性排名结果的前k个文档分析查询的时间意图,然后使用排名模型计算各个文档时间相关性得分。实验结果表明,在排名模型中引入时间因素有利于提升检索性能。
关键词:隐式时间查询;时态信息检索;排名模型
DOIDOI:10.11907/rjdk.171275
中图分类号:TP301
文献标识码:A 文章编号文章编号:1672-7800(2017)008-0012-03
0 引言
搜索引擎是目前最受欢迎的获取信息方式之一,用户可以通过搜索引擎在海量信息中方便地检索到自己感兴趣的主题,研究人员发现大约1.5%的查询包含明确的时间约束[1],超过7%的查询包含隐式时间意图[2]。因此,在检索模型中考虑时间因素,理解用户查询的潜在时间意图,有利于提升搜索引擎的检索性能。
1 相关工作
时态信息检索 (Temporal Information Retrieval)[3]是信息检索的一个重要分支。查询某一个特定时间区间的文档称为时间敏感查询(time-sensitive query)。显式时间敏感查询定义明确的时间约束,Berberich等[4]针对这类查询提出一个考虑时间因素的检索模型,把从文档中提取的时间词汇添加到语言模型中计算概率。Diaz和Jones[5]提出使用文档的时间戳衡量检索结果文档在时间域上的分布,并创建一个查询时间配置文件。隐式时间敏感查询虽然没有提供明确的时间标准,但与查询相关的文档大都发生在特定时间区间。解决此问题的方法之一是基于元数据,利用文档发表日期等确定查询的时间意图。Kanhabua等[6]提出3种分析隐式时间查询意图的方法:①仅通过关键词分析时间意图;②使用仅考虑内容相关性排名结果的前k个文档分析时间意图;③通过前k个文档的时间戳分析查询的时间意图。Dakka 等[7]在语言模型中加入时间因素,给每个时间段一个相关性评估分数,而有的文档可能没有可信的创建日期,且当文档时间意图和文档创建时间相差很远时,这种通过文档创建日期分析查询时间意图的方法就不准确,可能降低检索质量。Lin等[8]建立了一个时态信息的检索模型TASE(Time-Aware Search Engine),此模型可以提取显式和隐式表示时间的词汇,计算网页与每个时间表达式之间的相关评分,基于网页和查询之间的时间相关性和文本相关性对检索结果重新排序。还有一种方法是基于用户的查询日志,如Metzler等[2]提出通过挖掘用户日志以及分析不同时间的查询频率来识别与时间关联较强的查询。张晓娟等[9]的研究也是基于查询日志,通过Sogou实验室提供的查询日志数据和新闻数据分析潜在时间意图及其相关时间属性,构建潜在时间意图查询检索模型。
2 方法
包含时间意图的查询主要有两种类型:①查询中明确指定了時间约束,称为显式时间查询;②用户没有提供明确的时间标准,但与查询相关的结果都倾向于发生在某个特定的时间区间,称为隐式时间查询[6]。本文中,定义文档集C是所有文档的集合,C={d1,d2,d3,...,dn}。文档di是一系列单词的集合,di={w1,w2,w3,...,wm,t1,t2,t3,...,tn},其中wm 是文档中没有时间含义的词汇,这些词汇的集合记作dword; tn是文档中表达时间的词汇,这些词汇的集合记作dtime,di={dword,dtime}。支持隐式时间查询排名算法过程如下:①提交查询到已建立索引的文档集,得到仅考虑内容相关性的初始排名结果;②使用初始排名结果的前k个文档,分析查询的时间意图;③在考虑查询时间意图的基础上利用排名模型计算文档的时间相关性得分;④结合内容相关性得分和时间相关性得分对结果重排,最后把新的排名结果返回给用户。从以上工作流程可见,此算法主要有分析查询的时间意图和考虑时间因素的检索模型这两个主要模块,下面对这两个模块进行详细描述。
2.1 查询时间意图确定
本文提出一种分析隐式查询时间意图的方法。如果查询的内容是关于著名人物或历史上某个重大事件,通过前k个文档内容时间确定查询时间意图,主要步骤如下:首先仅考虑内容相关性,在文档集中检索得到排名前k个文档,这些文档和查询内容、时间相关的概率较大,所以前k个文档的内容中某个时间点出现频率越高,这个时间点属于查询时间意图的可能性就越大。规定前k个结果中出现超过m(m≥0)次的时间点为用户感兴趣的一个时间点,这些时间点组成的集合为查询q的时间意图。过程如下:
INPUT:查询qword,选取结果中前m个时间区间,文档中时间点组成的集合DN OUTPUT: 符合查询时间意图的时间区间A A← HashMap map(key,value) //key:排名前k个结果中出现的时间点,value:时间点出现的频率 DTopK ←retrieveTopKDoc (qword ,k) //仅考虑内容相关性检索得到排名前k个文档 for each {di∈DTopK} do for each {tj∈di} do if{tjkey} map.put(tj,1) else map.put(tj,value+1) end if end for end for A←map.selectTopMIntervals (m) //根据频率选取前m个时间点 return A
2.2 检索模型
隐式时间查询q 由qword和时间意图qtime组成,根据线性结合内容得分和时间相关性得分得到文档d的最终得分S(q,d),公式如下:S(q,d)=α·S'(qword,dword)+(1-α)·S"(qtime,dtime)(1)endprint
α是调节内容相关性得分S'(qword,dword)和时间相关性得分S"(qtime,dtime)的参数。
由分析隐式时间意图方法得到查询的时间意图qtime,qtime={t1',t2',t3',...,tn'},且t1'∩t2'∩t3'...∩tn'=。时间相关性得分S"(qtime,dtime)定义如下:S"(qtime,dtime)=P(qtime|dtime)=P(t1',t2',t3',...,tn'|dtime)(2)
qtime由一系列不重复的时间点组成,假设每个时间点彼此之间是相互独立的,没有依赖关系,则P(t1',t2',t3',...,tn'|dtime)=∏Q∈qtimeP(Q|dtime)(3)
相似地,文档内容中也存在多个时间词汇,dtime={t1,t2,...,tn},且t1∩t2∩...∩tn=。为了防止结果概率为0,使用Jelinek-Mercer 平滑方法。P(Q|dtime)计算公式如下: P(Q|dtime)=(1-λ)1|Dtime|∑T∈DtimeP(Q|T)+ λ1|dtime|∑T∈dtimeP(Q|T)(4)
λ∈[0,1],把整个文档集当作一个文档,|Dtime|是这个文档中时间表达的个数,本文中所有的λ取值为0.85。时间点Q与时间点T表现形式不同,但可能指向同一个时间段,所以在计算P(Q|T)时需要考虑时间的不确定性。比较Q与T相差的时间天数,如果Q与T相差的时间在m天内(m≥0),P(Q|T)则为1,否则为0。P(Q|T)=1 (|Q-T|≤m),m≥00 否则 (5)
3 实验
3.1 实验设置
本文中使用的实验数据是NTCIR-11 会议Temporal Information Access (Temporalia)任务中使用的文档集,涵盖了2011年5月到2013年3月约1 500个不同博客和新闻收集到的3.8M文档[10]。使用Indri系统对文档集构建索引,得到仅考虑内容相关性的排名结果。实验使用方法定义如下:LMU-DIF方法利用公式(5)计算P(Q|T),并在此基础上计算时间相关性得分,然后使用公式(6)对Indri系统的文档原始得分0-1规范化,规范后的结果作为内容相关性得分。
Scorenorm=score-scoreminscoremax-scoremin(6)LMU-DIF-rankAdd和LMU-DIF计算时間相关性得分的方法相同,区别在于LMU-DIF-rankAdd方法使用公式(7)把Indri系统初始排名转换为分数,然后把公式(6)规范后的结果作为内容相关性得分。
S"(qtime,dtime)=1rank+60(7)
3.2 实验结果
本文使用平均查准率均值(MAP),前m个文档的准确率(P@m)、前m个文档的nDCG(nDCG@m)和前m个文档的err(err@m)值来评价检索结果质量。
前面提出的一种分析时间意图的方法是使用前k个文档分析查询时间意图,k值的不同会影响检索结果。表1列出不同k值对实验结果的影响,可见1 000个文档中取前200个文档分析查询时间意图时检索性能最好,所以本文实验中值取200。
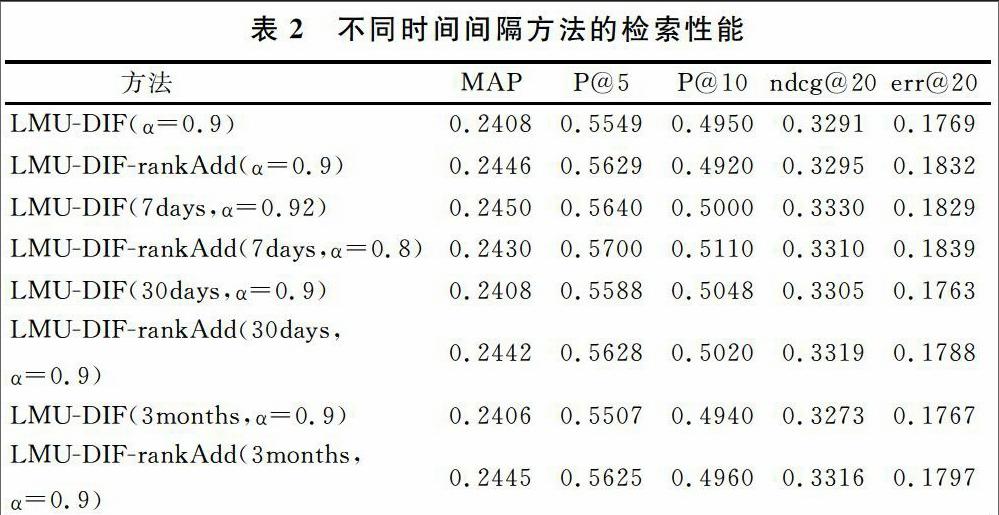
语言模型中计算值需要考虑时间不确定性,不同的时间间隔可能会影响排名结果。表2列出不同时间间隔(0天、7天、30天、3个月)下LMU-DIF和LMU-DIF-rankAdd方法的指标值。从表2可见,时间间隔取太大或太小都会降低结果性能,间隔7天时性能最好。
综合上面的分析,表3列出了每个方法在参数配置最优情况下各指标的值,Baseline是仅考虑内容相关性的一个基准。总体上看,各种方法性能都有所提升,LMU-DIF-rankAdd方法比LMU-DIF更优,但都优于Baseline,表明本文提出的方法在改善搜索引擎性能方面有一定效果,排名模型需要考虑时间因素的影响。
4 结语
本文提出一种支持隐式时间查询的文档排名方法,该方法首先分析隐式查询的时间意图,在此基础上线性计算时间相关性得分,结合时间相关性得分和内容相关性得分,把重排结果返回给用户。实验结果表明本方法具有一定的实用价值。
参考文献:
[1] NUNES S, RGIO, RIBEIRO C, et al. Use of temporal expressions in web search, proceedings of the Ir research[C].European Conference on Advances in Information Retrieval,2008.
[2] METZLER D, JONES R, PENG F, et al. Improving search relevance for implicitly temporal queries [J]. Proceedings of Sigir, 2009(1):700-701.
[3] ALONSO O, STROTGEN J, BAEZA YATES R, et al. Temporal information retrieval:challenges and opportunities[J].Temporal Web Analytics Workshop at Www, 2011(1):8-9.
[4] BERBERICH K, BEDATHUR S, ALONSO O, et al. A language modeling approach for temporal information needs [M]. ECIR, 2010.
[5] JONES R, DIAZ F. Temporal profiles of queries [J]. Acm Transactions on Information Systems, 2007, 25(3): 14-16.
[6] KANHABUA N, NORVAG K. Determining time of queries for re-ranking search results[M].ECDL 2010.
[7] DAKKA W, GRAVANO L, IPEIROTIS P G. Answering general time-sensitive queries[J].Knowledge & Data Engineering IEEE Transactions on, 2012, 24(2): 220-350.
[8] LIN S, JIN P, ZHAO X, et al. Exploiting temporal information in Web search [J]. Expert Systems with Applications, 2014, 41(2): 331-411.
[9] 张晓娟, 陆伟, 周红霞. 用户查询中潜在时间意图分析及其检索建模 [J]. 现代图书情报技术, 2011(11): 38-43.
[10] JOHO H, JATOWT A, BLANCO R. NTCIR temporalia: a test collection for temporal information access research [M]. Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea,ACM,2014.endprint
