
基于卷积神经网络的图像识别教学实验
2017-09-08 02:00:32祝世平周富强魏新国温思寒
电气电子教学学报 2017年4期
祝世平, 周富强, 魏新国, 温思寒
(北京航空航天大学 仪器科学与光电工程学院, 北京 100191)
基于卷积神经网络的图像识别教学实验
祝世平, 周富强, 魏新国, 温思寒
(北京航空航天大学 仪器科学与光电工程学院, 北京 100191)
图像识别是“图像处理”教学中的重要内容。本文在Linux环境下使用iTorch notebook可视化界面利用卷积神经网络实现mnist手写数字体的准确识别,并详细介绍卷积神经网络的原理,给出直观的实验结果。教学实践表明,通过具有应用性和趣味性的实验可以提高学生的积极性,加深对课程理论的认知,培养其分析问题和解决问题的能力。
图像识别;卷积神经网络;iTorch
0 引言
图像识别是“数字图像处理”课程的重要内容,随着图像处理技术的迅速发展,图像识别技术的应用领域越来越广泛[1]。其中,好的识别技术是关键所在,怎么样提高识别率和识别的速度意义重大,直接关系到图像识别的实用性和安全性。目前,图像识别方法大多采用人工方式提取特征,不仅费时费力,而且提取困难;而深度学习是一种非监督学习,学习过程中可以不知道样本的标签值,整个过程无需人工参与也能提取到好的特征。作为实现深度学习的一项重要技术,卷积神经网络(CNN)成功训练了首个深层神经网络结构,已在图像识别、语音识别等领域取得卓越成绩[2]。另外,在Google公司的alphGo运用深度学习的方法战胜围棋高手李世石后,人们对深度学习的好奇掀起了高潮,故为了更好地满足学生的求知欲,激发学生的积极性,本课程设计了基于卷积神经网络的图像识别实验,并在iTorch notebook可视化界面下训练MNIST手写数据集,测试其识别准确度。通过直观的实验结果,使学生在实验中达到以下锻炼:
(1)熟悉Linux开发环境,并掌握对Torch,iTorch的安装及使用;
(2)了解深度学习,并理解卷积神经网络的概念,掌握其实现流程;
(3)更加深刻的理解图像识别的原理,并对卷积神经网络技术在图像识别上的应用有所掌握。
另外,实验提供的可视化平台,使学生可以更直观地对程序进行调试及运行,提高了其动手实践和分析与解决问题的能力。
1 实验环境配置
本实验使用的 iTorch notebook 是一个通过Web界面实现交互的shell,其中iTorch 是 Torch 的 iPython 内核。
首先,我们需要一台配置好Python和Torch7的Linux系统,再针对iTorch notebook配置iTorch,iTorch是Torch里面的一个包,它能很轻松地显示图片、视频和音频等等,但是需要和ipython搭配使用,故需要安装iPython。
打开终端,输入:
wget http://ipython.scipy.org/dist/ipython-0.8.4.tar.gz
下载完毕后,输入解压缩命令:tar zxvf ipython-0.8.4.tar.gz
切换到解压缩的目录:cd ipython-0.8.4
输入命令安装:python setup.py install
但此时还是无法使用,需要我们再安装ipython-notebook,安装命令如下:sudo apt-get install ipython-notebook
然后,在终端输入:itorch notebook,在浏览器中便会弹出iTorch notebook的Web界面,如图1所示。

图1 iTorch notebook的Web界面
点击右上角的new notebook建立一个新的笔记本,界面如图2所示。

图2 建立新笔记本
并在In[]:命令行输入命令测试,便输出如下图3的界面。
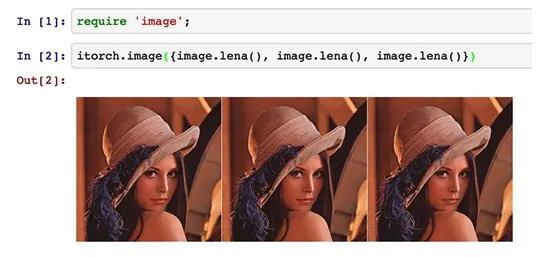
图3 命令测试结果
由图3可看出,该界面能够直观显示出我们的输入,并能分层次输入,便于学生对程序更好的调试及理解。
另外,由于本次实验需要对图像进行显示,故需要安装image库,在运行itorch notebook 前在终端键入:luarocks install image进行安装。
最后,本文是针对MNIST数据库中的数字进行训练及识别,故需要对其进行安装,在运行itorch notebook前在终端键入:luarocks install mnist完成安装。
MNIST是一个手写数字数据库,它有60000个训练样本集和10000个测试样本集。它是NIST数据库的一个子集。数据库存储并不是标准的图像格式,这些图像数据都保存在二进制文件中,所有的图片都经过了尺寸标准化和中心化,图片的大小固定为28×28。
2 实验设计
为了加强学生对卷积神经网络在图像识别的理解和应用,提高学生运用卷积神经网络等深度学习方法来解决实际生活中图像识别的能力,本实验要求学生自行搭建程序运行所需环境,熟悉对Linux系统的使用,并给出已经训练好的训练集,让学生自己对测试集中的数据进行测试,给出其准确度,并随机显示图片验证其正确性。
同时,为了让学生更快速的进入实验状态,发挥自己的动手实践能力,我们给出卷积神经网络的结构,并给出该识别过程中最主要的模型建立流程。
2.1 卷积神经网络的网络结构
卷积神经网络CNN(Convolutional Neural Networks)是一种为了处理二维输入数据而特殊设计的多层人工神经网络,网络中的每层都由多个二维平面组成,而每个平面由多个独立的神经元组成[3-5]。
如图4示,这是一个简单的卷积神经网络 CNN。
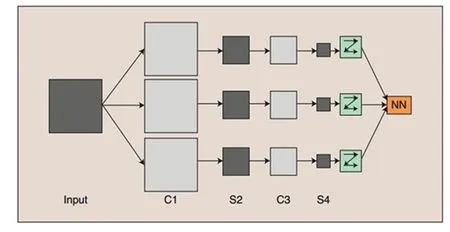
图4 简单的CNN
输入图像通过和三个可训练的滤波器和可加偏置进行卷积,卷积后在C1层产生三个特征映射图。然后特征映射图中每组的四个像素再进行求最大值,加权值,加偏置,通过一个ReLu函数得到三个S2层的特征映射图。这些映射图再经过滤波得到C3层。这个层级结构再和S2一样产生S4。最终,这些像素值被光栅化,并连接成一个向量输入到传统的神经网络,得到输出。
一般地,C层为特征提取层,每个神经元的输入与前一层的局部感受野相连,并提取该局部的特征,一旦该局部特征被提取后,它与其他特征间的位置关系也随之确定下来;S层是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射为一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。
此外,由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数,降低了网络参数选择的复杂度。卷积神经网络中的每一个特征提取层(C-层)都紧跟着一个用来求局部平均与二次提取的计算层(S-层),这种特有的两次特征提取结构使网络在识别时对输入样本有较高的畸变容忍能力。
2.2 模型建立流程
基于深度学习的图像识别模型流程主要是:把图像输入到神经网络中,利用深度学习的前向传播和反向传播误差等算法来最小化损失函数,更新权值后,得到一个较优的识别模型,然后利用此模型对新的图像来进行识别。
在该基于卷积神经网络的图像识别实验中,最核心的部分就是此模型的建立。
首先,我们需要首先建立一个容器用来存放各种模块:
model = nn.Sequential()
然后,放入一个reshape模块。因为mnist库的原始图片是储存为1列728个像素的。我们需要把它们变成1通道28×28的一个方形图片。
model:add(nn.Reshape(1, 28, 28))
接下来要把图片的每个像素除以256再乘以3.2,也就是把像素的取值归一化到0至3.2之间。
model:add(nn.MulConstant(1/256.0×3.2))
然后是第一个卷积层,它的参数按顺序分别代表:输入图像是1通道,卷积核数量20,卷积核大小5×5,卷积步长1×1,图像留边0×0。
model:add(nn.SpatialConvolutionMM(1, 20, 5, 5, 1, 1, 0, 0))
一个池化层,它的参数按顺序分别代表:池化大小2×2,步长2×2,图像留边0×0。
model:add(nn.SpatialMaxPooling(2, 2 , 2, 2, 0, 0))
再接一个卷积层和一个池化层,由于上一个卷积层的核的数量是20,所以这时输入图像的通道个数为20。
model:add(nn.SpatialConvolutionMM(20, 50, 5, 5, 1, 1, 0, 0))
model:add(nn.SpatialMaxPooling(2, 2 , 2, 2, 0, 0))
在接入全连接层之前,我们需要把数据重新排成一列,所以有需要一个reshape模块。
model:add(nn.Reshape(4×4×50))
这个参数为什么是4×4×50,即800呢?原因是:我们的输入是1通道28×28的图像,经过第一个卷积层之后变成了20通道24×24的图像。又经过池化层,图像尺寸缩小一半,变为20通道12×12。通过第二个卷积层,变为50通道8×8的图像,又经过池化层缩小一半,变为50通道4×4的图像。所以这其中的像素一共有4×4×50=800个。
接下来是第一个全连接层。输入为4×4×50=800,输出为500。
model:add(nn.Linear(4×4×50, 500))
两个全连接层之间有一个ReLU激活层。
model:add(nn.ReLU())
然后是第二个全连接层,输入是500,输出是10,也就代表了10个数字的输出结果,哪个节点的响应高,结果就定为对应的数字。
model:add(nn.Linear(500, 10))
最后是一个LogSoftMax层,用来把上一层的响应归一化到0至1之间。
model:add(nn.LogSoftMax())
至此,模型的建立就完成了。我们还需要一个判定标准。由于我们这一次是要解决分类问题,一般使用nn.ClassNLLCriterion这种类型的标准(Negative Log Likelihood)。
criterion = nn.ClassNLLCriterion()
到这里,网络模型的部分就都已经完成了,其具体流程图如下图5。
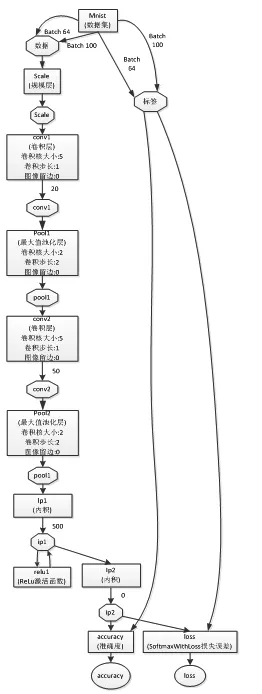
图5 网络模型流程图
3 实验结果
本次实验最终确定神经网络的迭代次数(iteration)为30,其正确率如图6所示,可达到98%以上,相比较其他算法,错误率大大减少,且由观察可知,只需迭代30次,准确率便可稳定,缩短了训练时间,提高了运行速度。

图6 6次迭代图像识别正确率
针对训练好的模型,我们从测试集中随机选取图片进行验证,其结果示于图7和8,无论什么形式的手写体,该算法都能够对其正确的识别。

图7图像识别算例1测试结果 图8 图像识别算例2测试结果
4 结语
本文详细讨论了基于卷积神经网络的图像识别实验的原理和流程,并以iTorch noteboook的可视化界面直观的显示出其准确性。而且,通过让学生自行搭建程序运行所需环境,自行编程对测试集中的数据进行测试,并随机显示图片验证其正确性,大大提高了学生的编程能力,加深了学生对深度学习的了解,让学生更加全面的理解卷积神经网络在图像识别中的应用。
[1] 邓柳, 汪子杰. 基于深度卷积神经网络的车牌识别研究[J]. 成都:计算机应用研究, 2016, 33(3): 930-932.
[2] 徐彩云. 图像识别技术研究综述[J]. 菏泽:电脑知识与技术, 2013, 9(10): 2446-2447.
[3] 卢宏涛, 张秦川. 深度卷积神经网络在计算机视觉中的应用研究综述[J]. 南京:数据采集与处理, 2016, 31(1): 1-17.
[4] 张文达, 许悦雷, 倪嘉成, 马时平, 史鹤欢. 基于多尺度分块卷积神经网络的图像目标识别算法[J]. 成都:计算机应用, 2016, 36(4): 1033-1038.
[5] 范哲意, 曾亚军, 蒋姣, 翁澍沁, 刘志文. 视频人脸识别实验平台的设计与实现[J]. 北京:实验技术与管理, 2016, 33(3): 159-161, 165.
Image Recognition Teaching Experiment Based on Convolutional Neural Network
ZHU Shi-ping, ZHOU Fu-qiang, WEI Xin-guo, WEN Si-han
(SchoolofInstrumentationScienceandOptoelectronicsEngineering,BeihangUniversity,Beijing100191,China)
Image recognition is the important content of Image Processing course. In this paper, under the environment of Linux, we realize the accurate handwritten digit recognition from the data of mnist by using a visual interface called itorch notebook, introduce the principle of the convolutional neural network in detail, and give an intuitive experimental results. The teaching experience shows that such kind of experiment which embodies interestingness and practical application has the advantage of increasing the students′ interest in the course, deepen the cognition of curriculum theory and cultivate their ability to analyze and solve problems.
image recognition; convolutional neural network; iTorch
2016-07-05;
2016-11- 11
北京航空航天大学仪器科学与光电工程学院教改项目
祝世平(1970-),男,副教授,主要从事图像处理教学和视频压缩、计算机视觉、机器视觉在精密测量中的应用等方面的研究,E-mail:spzhu@163.com
G426
A
1008-0686(2017)04-0124-04
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
当代陕西(2020年13期)2020-08-24 08:22:02
电子制作(2019年16期)2019-09-27 09:34:50
中国交通信息化(2019年4期)2019-07-13 05:51:34
电子制作(2019年11期)2019-07-04 00:34:38
电子制作(2018年19期)2018-11-14 02:37:04
电子制作(2018年14期)2018-08-21 01:38:16
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
制造技术与机床(2017年5期)2018-01-19 02:49:17
潍坊学院学报(2016年2期)2016-12-01 13:00:11
