
决策树分类算法在大学生就业指导中的应用研究
2017-09-07 16:43段润英黄欣荣
数字技术与应用 2017年5期
段润英+黄欣荣


摘要:为深入挖掘剖析影响应加大学生求职择业的关键因素及其潜在的相互作用,笔者针对南京信息职业技术学院近年来的毕业生选择推荐就业、自主择业、自主创业或升学、待业等各种情况的决策因素进行了广泛的统计,以数据挖掘分类技术为支撑设计了C4.5算法对各种潜在的影响毕业生就业选择的因素进行了系统化的剖析,从而得出影响应届毕业生就业率的决策模型。本研究的主要意义在于学生可以算法模型在大学在读期间努力完善自己的知识结构,不断增强自身的综合素质及社会竞争力。从而适应日益严峻的就业形势和经济社会发展的需要,提高入职签约成功率。应届毕业生也可以参照算法模型对比自身的素质素养有针对性的选择目标单位进行择业。高等院校则可以根据该算法模型统计各界毕业生的就业指数进行纵向及横向的对比分析,进有针对性的改良教学计划,使院校培养出的毕业生更加符合当代社会的需求,刺激就业率快速增长。
关键词:数据挖掘;分类;决策树;C4.5算法;大学生求职
中图分类号:TP311.13 文献标识码:A 文章编号:1007-9416(2017)05-0151-03
1 C4.5算法
C4.5 算法是对ID3算法的优化改良。与ID3算法不同的是,C4.5算法是以数据增益率为标准来选择决策树的每个节点的节点属性。算法默认选择当前分支节点下数据增益率最高的属性作为当前节点的测试属性。C4.5算法具有的这一特性使得对数据挖掘结果中的样本分类所需的数据量大大减少,而且能够准确的反映出划分的最小随机性或“不纯性”。这种理论方法使得对一个对象分类所需的期望测试数目达到最小,从而设计一棵最为简单的决策树。为了研究的方便,下面对算法中的相关术语给出定义。
定义1:设数据集S为包含S个数据样本的集合,且类别属性可以取m个不同的值,对应于m个不同的类别Ci (i=1,2,…,m)。假设Si为类别Ci中样本的个数;对一个给定数据对象进行分类所需要的信息量,称为S划分前的熵,即:
其中Pi是任意一个数据对象属于类别Ci的概率:。Pi=Si/S。
定义 2:设一个属性A取v个不同的离散属性值{a1,a2,…av}。利用属性A可以将集合S划分为v个子集{S1,S2,…Sv},其中Sj包含了S 集合中属性A取aj值的数据样本。若属性A被选为测试属性,即用属性A 对当前样本集进行划分。设Sij為子集Sj中属于Ci类别的样本数。那么利用属性A划分当前样
2 挖掘对象及目标确定
本文以南京信息职业技术学院六百名2016届毕业生的就业情况作为研究对象,通过建立C4.5算法比对分析六百位2016届毕业生的学习成绩及个人素质等相关信息得出可能影响学生择业就业的潜在因素,为在校学生有针对性的提高自身素养提供了参考方向,同时也给学校学生工作委员会就业指导中心的专兼任教师调整学校课程安排和就业指导工作的中心提供了理论支撑。
3 数据采集
利用C4.5算法进行数据挖掘分析需要确立具体、可查的研究对象,所以建立算法分析模板前应对可预见的可能影响学生择业就业的潜在因素进行系统化、精细化的搜集整理。数据采集样本的准确程度直接影响了算法分析结果的参考价值。
根据研究分析需要,本文主要从南京信息职业技术学院学生学籍管理系统中“基本信息服务”界面采集了学生“学生基本信息”,从“学习中心-成绩查询服务”界面导出了2016界毕业生的“学生成绩信息”。南京信息职业技术学院学生工作委员会下辖的就业指导中心的同事们向我们提供了2016界相关毕业生的“就业状况信息”。笔者使用随机抽样的方式从调取到的近五千条数据记录中截取了600条相关记录作为本次研究分析的对象。在截取的600条毕业生信息中安排400条数据组成训练数据集,剩余200条数据分配为测试数据集。
从南京信息职业技术学院学生学籍管理系统中“基本信息服务”界面采集了学生“学生基本信息”主要包括以下内容:院系、专业、班级、姓名、学号、性别、能力特长、政治面貌、健康情况、奖惩情况与培训工作经历、社会实践活动等。另外,该界面还显示了诸如民族、籍贯、身份证号等与毕业生就业选择无关或受反歧视、反地方保护政策限制对毕业生就业影响较小的因素,本文不作讨论。
从“学习中心-成绩查询服务”界面导出“学生成绩信息”,主要包括以下属性:学号、姓名、学年、学期、学分、课程性质、总评成绩等。该界面也提供了毕业生英语水平、计算机水平等被用人单位普遍重视的基础技能成绩的查询服务。
由南京信息职业技术学院学生工作委员会就业指导中心提供的毕业生“就业状况信息”主要包括以下属性:专业、班级、学号、姓名、就业单位、单位性质、单位通信地址、单位联系方式、单位效益等。
4 数据集成
本文研究的初始数据即从数据采集流程中“学生基本信息”、“学生成绩信息”及“就业状况信息”三个数据库选取。为了进一步提高数据挖掘质量,提高算法效能我们需要将采集到的数据进行集成处理,即将采集到的三个数据库中的相干信息统一整合到一个新的数据库中。
通过观察发现,三个数据库中均包含的数据属性有“姓名”、“学号”两个,由于以中文字符作为数据存储格式的“姓名”属性相较于以数字字符作为数据存储格式的“学号”属性难以在算法中录入、检索,故本文采用样本的“学号”属性作为主键将三个独立的数据库整合形成一个“南京信息职业技术学院2016届毕业生就业信息汇总表”。表内共包含以下样本个体的属性信息:专业、班级、姓名、学号、性别、政治面貌、奖惩情况、社会实践活动、学习成绩、英语水平、计算机水平、单位名称、单位性质、单位联系方式、单位地址、单位效益,共计16项。
经过认真的考校和从业内专业人士等渠道获取的相关信息我们发现表内的有些属性和算法实施的目的有关,一些与数据挖掘分析任务相干性较小或者不相干。因此,对表内的数据属性进行归约以得到最小的属性集从而保证数据挖掘结论的正确性和有效性是十分必要的。endprint
5 构造决策树
我们将“就业情况”中的“单位性质”作为类别标识属性,把“学生基本信息”中的“性别”、“专业”、“政治面貌”、“获奖情况”、“实践能力”、“学习成绩”、“英语水平”、“计算机水平”作为决策属性构建训练数据集。将学生就业的样本集设为S,其包含有400个元组。这400个元祖根据就业单位性质划分为A1、A2、A3、B1、B2、B3、C1、C2、C3九个类别,分别对应着较好的国企、一般的国企、差的国企、较好的外企、一般的外企、差的外企、较好的私企、一般的私企、差的私企九类就业单位。各个类别标识属性对应的样本数参照表1样本统计分析表所示。
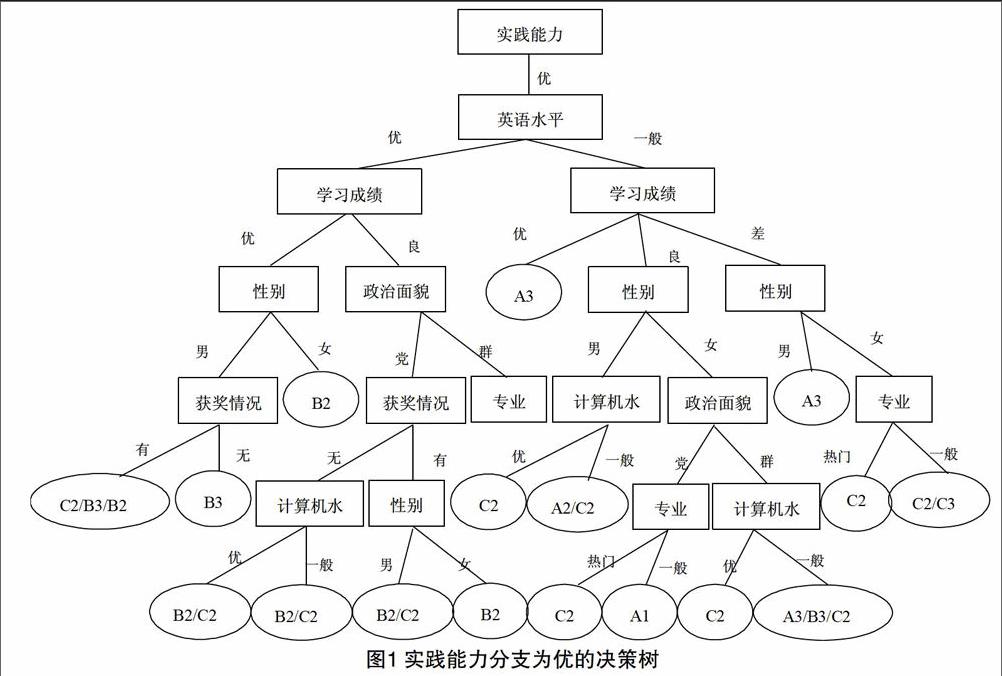
通过表1中的数据统计结果我们不难看出,400个训练数据元组中进入A1、B1、C1类单位就业的仅有十一个个体,相较于400个数据的总体所占比例过低,不具有代表性。这与本文通过研究既有应届毕业生就业数据分析得出潜在的可能影响就业的普适性因素以提高应届毕业生就业率的初衷背道而驰。因此,本文仅选择了进入二(A2&B2&C2)、三类(A3&B3&C3)单位工作的数据元祖使用决策树C4.5 算法进行挖掘分析,冀图得到更精确、更具有普适性的分析结果。C4.5决策树的具体的构建过程如图1所示。
400个元组,其中A2、A3、B2、B3、C2、C3对应的子集元组数分别为s1=32,s2=41,s3=35,s4=62,s5=61,s6=158,计算每个决策属性的信息增益率,按照公式(1)首先计算集合S的熵:I(s1,s2,s3,s4,s5,s6)=I(32,41,35,62,61,158)=2.320543,然后根据公式(2)、公式(3)和公式(4)计算每一个决策属性的信息增益率。
由上述结果可知,数据增益率最高的属性是“社会实践活动”,因此该属性应作为决策树的根结点。实践能力分出“优”、“良”和“差”三个分支,对应的元组个数依次为116、259和25。由上述结果可知,数据增益率最高的属性是“英语水平”,因此该属性是实践能力为“优”的分支结点。对实践能力为“良”和“差”的分支进行上述计算,结果为实践能力为“良”和“差”的分支结点均是属性“获奖情况”,同理确定其他的分支节点。
6 生成分类规则
從图1实践能力分支为优的决策树中从根结点到每个叶结点的流程我们可以归纳出如下分类原则(表2)。
通过上述分类原则可以看出,有社会实践经历丰富且具有较高的英语应用能力的毕业生占了较好企业就业样本中的绝大多数;而社会实践经历较为薄弱但获得过省市以上奖励荣誉的毕业生,基本上能够在差的国企、一般性外企和较好的私企就业;社会实践能力一般且没有获得过较高等级的奖励的毕业生只能混迹于较差企业等。
7 结语
根据潜在的可能影响到应届大学毕业生就业的数据属性所具有的离散性的特点,本文利用决策树C4.5算法对目标数据进行了挖掘分析,构建了大学生就业影响因素的分析模型,同时树立建立了分类规则,数据挖掘分析具有较高的参考价值和实践意义。通过C4.5算法模型分析出的应届毕业生就业影响因素分类规则对在校大学生针对性的提高自身综合素质具有导向作用,也可以为高校就业指导工作的转型提供思路。
参考文献
[1]杨断利,张锐,王文显.基于模糊决策树的高校就业数据挖掘研究[J].河北农业大学学报,2012,35(2):111-114.
[2]麦晓冬,贾萍,翁建荣,等.基于多尺度粗糙集模型的决策树在高校就业数据分析中的应用[J].华南师范大学学报(自然科学版),2014,46(4):31-36.
[3]李如平.数据挖掘中决策树分类算法的研究[J].华东理工大学学报,2015,33(2):192-196.endprint
猜你喜欢
疯狂英语·读写版(2023年5期)2023-06-01
成都信息工程大学学报(2019年3期)2019-09-25
意林·全彩Color(2019年7期)2019-08-13
电子制作(2018年16期)2018-09-26
电力与能源(2017年6期)2017-05-14
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
信息通信技术(2015年6期)2015-12-26
郑州大学学报(医学版)(2015年1期)2015-02-27
创业家(2015年4期)2015-02-27
电子设计工程(2014年18期)2014-02-27
