
基于逻辑回归算法的微博水军识别*
2017-09-04 00:31:10谢忠红
网络安全与数据管理 2017年16期
谢忠红,张 颖,张 琳
(南京农业大学 信息科学技术学院,江苏 南京 210095)
基于逻辑回归算法的微博水军识别*
谢忠红,张 颖,张 琳
(南京农业大学 信息科学技术学院,江苏 南京 210095)
受潜在的商业利益的驱动,微博水军横行于话题与评论之间,对人们了解真实的结果产生不良影响,成为正常用户了解事实真相的障碍。分析了正常用户和水军的关系图,以此为切入点,分析了水军的特点,从用户属性中抽取了8个特征数据(粉丝数、关注数、好友粉丝比、注册时间、活跃度、关注速率、双向关注比和互粉数)基于学习数据集R训练逻辑回归分类模型,得到可靠的回归系数后,使用识别样本集R进行识别,水军识别率高达98.770%。为验证抽取的8个特征是否能有效识别水军,使用Scikit-Learn机器学习库中4种分类方法对同一识别样本集进行水军识别,水军识别准确率均在98.688%以上。研究结果表明,选取的8个特征能有效地进行水军判别,逻辑回归分类模型在进行水军识别研究中具有高准确性和可靠性。
微博;水军;逻辑回归
0 引言
互联网时代的到来以及社会生活的高度信息化,使网络承载了蕴含着价值的大数据,如新浪微博、大众点评网、豆瓣等拥有海量用户的社会化网络媒体,已经被组织和个人广泛地用来进行辅助决策。巨大的用户群体蕴含着潜在的商机。为了人为控制事件的走向,使虚假意见和垃圾信息被广泛地制造和传播,该类危害的源头即俗称的网络水军。
1 国内外研究状况
1.1 国外研究状况
2009年10月Twitter推出了用户举报功能。在Twitter上,国外学者从Twitter虚假用户入手对如何判别水军用户有较深入的研究。水军既属于不可信用户也属于虚假用户。利用用户特征通过机器学习算法来识别Twitter中的虚假用户,衡量了所使用特征的好坏。学者们提出了一种在Facebook平台上通过分析照片墙帖子中包含的常见URL和相似文本来识别水军用户。McCord等人通过传统的机器学习分类器检测Twitter上的水军用户,比较了几种分类器的检测性能[1]。Lee等人利用Twitter中7个月的数据,自动发现Twitter中的微博机器人用户[1]。
1.2 国内研究状况
国内的研究大多数基于内容与关系特征进行研究,随后,统计学也相继应用于此。2012年5月国内的新浪微博成立了微博社区委员会负责审核用户举报信息,微博平台提出了一些利用明显水军特征进行模式匹配的识别技术。国内一些学者针对微博播环境中水军事件进行分析。莫倩等人总结了目前的特征关系,分析了基于内容特征、基于环境特征、基于用户特征、基于综合特征的网络水军识别研究[2]。程晓涛等人利用用户关系图获得了聚类系数、节点核数等特征,通过朴素贝叶斯算法来识别,识别率达82.8%[3]。
2 水军简介
2.1 水军定义
网络水军是指那些由商业利益驱动,为达到影响网络民意、扰乱网络环境等不正当目的,通过操纵软件机器人或水军账号,在互联网中制造、传播虚假意见和垃圾信息等网络垃圾意见的用户的总称。水军可以使某些话题迅速登上热门话题,引起广泛关注,甚至会影响舆论导向。
2.2 水军用户关系图绘制
NetworkX是一个用Python语言开发的图论与复杂网络建模工具。在采集的用户集合之中,随机抽取了一个正常用户“Yvonne_zzyyy”与一个水军用户“Areyding”来绘制用户关系图[4]。首先,分别获取了正常用户“Yvonne_zzyyy”和水军用户“Areyding”的好友id,从而绘制出了一个正常用户好友关系图(如图1所示)和一个水军用户好友关系图(如图2所示)。

图1 正常用户和水军用户的好友关系图
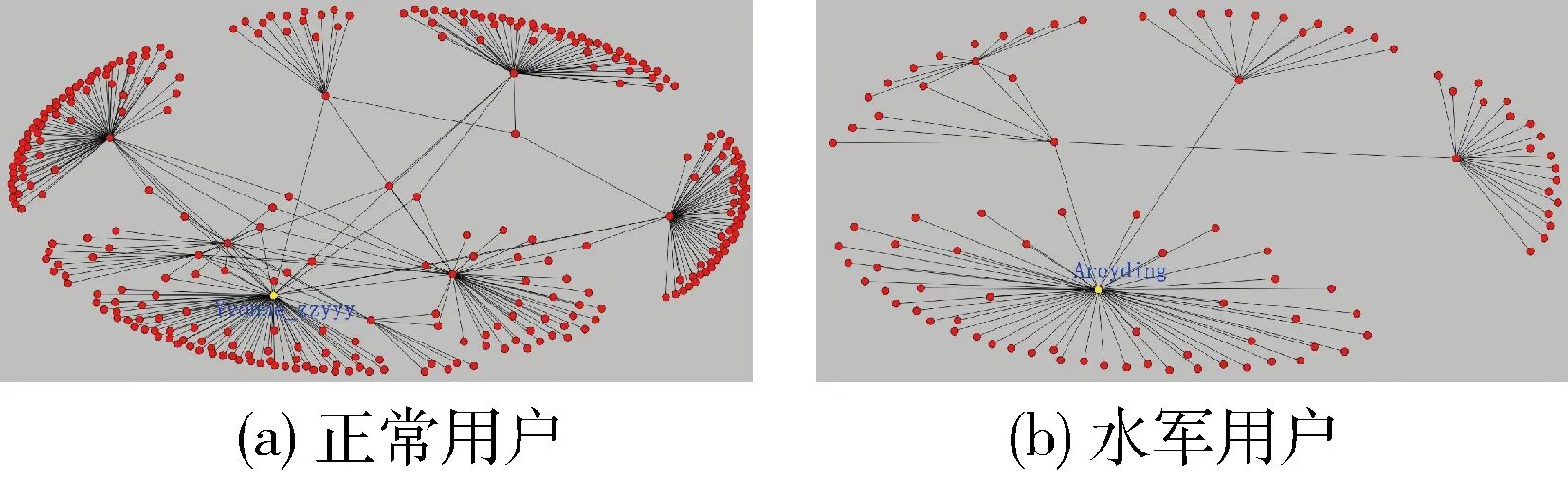
图2 水军用户的完整关系图
3 微博用户关系数据及分析
3.1 微博用户关系数据获取
新浪微博是中国排名第一的运营商,用户数占69.4%,因此本次研究选择使用新浪微博开放的API来获取新浪微博数据[3]。然而为了限制恶意利用API获取微博数据,新浪对微博平台API进行了升级,导致获取大量微博数据难度增加。本文通过分析大量微博发现,水军用户的存在形式集中于评论之中,例如产品的推广等。人工采集微博关系数据的方法是:人工进行评论的获取,采用测试账号对其进行关注,然后通过新浪开放平台提供的Java SDK获取测试账号所关注的用户信息,获得水军用户的全部基本信息。比较正常用户与水军用户之间差异,删除对本次研究没有帮助的字段后保留了8个字段如下:用户UID(Id)、粉丝数(followers_count)、关注数(friends_count)、互粉数(bi_followers_count)、微博数(statuses_count)、收藏数(favourites_count)、用户创建时间(created_at)、互粉数(bi_followers)。
3.2 特征选择
为了能够有效识别出伪装成正常用户的水军,本文除了选择已有的简单特征(粉丝数、关注数、互粉数、发博数、注册时间等)外,还通过计算得到了一些其他特征,例如:关注速率、用户活跃度、双向关注比等[5-8]。已用特征的定义如下:
(1)粉丝数Nfollowers
粉丝数反映用户的受欢迎程度,反面说明其他用户对该用户所发内容等的一种喜好程度。正常用户拥有一定比例的粉丝数,而水军用户一般大量关注大V用户而得不到对方的关注,水军拥有的粉丝数很少。
(2)关注数Nfriends
关注数反映用户的喜好范围。正常用户只会对自己认识或者感兴趣的博主进行关注,进而关注数处于一个合理的范围,而水军用户为了达到营销等效果,会大批量关注各种博主,因此水军用户与正常用户相比,拥有高关注数。
(3)互粉数Nbf
互粉数反映用户的社会交际水平。正常用户存在朋友圈因此拥有高相互关注数,而水军大部分是关注大V,而没有真实的朋友圈形成,因此相互关注数处于一个很低的状态。
(4)注册时间Tcreate
注册时间反映用户的存在周期,对于水军用户该信息尤其重要,一部分水军产生于某事件发生的时间,相对于正常用户,存在周期较短,因此这个特征能够衡量用户是否为水军。
(5)关注速率Rf

(1)
其中,Nfriends是关注数,Tcreate是注册时间。关注速率从侧面反映出注册时间的作用,水军用户会在一个较短的时间差内关注大批量的用户,关注速率比较高。
(6)用户活跃度Ralive

(2)
其中,Nblog是发博数,Tcreate是注册时间。通过在一个时间段内的发博数来反映一个用户的活跃程度。水军用户一般活跃于评论之中,自己发博数很少,正常用户的发博量肯定会比较多。
(7)双向关注比Rbf

(3)
其中,Nbf是相互关注数,Nfriends是关注数。双向关注比反映用户的一个交际情况,正常用户存在朋友关系一般会相互关注彼此,而水军可能的相互关注数会很低,通过观察,水军用户大多关注的大V较多,而大V用户一般对自己认识或者感兴趣的人才会相互关注。
(8)好友粉丝比Rff

(4)
其中,Nfriends是关注数,Nfollowers是粉丝数。出于营销等目的,水军会大批量关注别人,而获取对方关注的机会较低,因此呈现出高出度和低入度的状态特征。
4 基于逻辑回归的水军判断
4.1 逻辑回归算法

图3 逻辑回归流程图
逻辑回归算法是一种广义的线性回归分析模型,可用于二分类和多分类问题,常用于数据挖掘、疾病自动诊断、经济预测等领域。具体过程如图3所示:选取合适的预测函数,构造并求解Cost函数,基于梯度下降法求Cost函数的最小值以及递归下降过程的向量化。Cost函数表示预测的输出与训练数据类别之间的偏差[8-10]。
利用逻辑函数,即Sigmoid函数[11],该函数形式为:
hθ(x)=g(θTx)
(5)

(6)
计算最佳拟合参数θ的方法是最优化算法——求解的逻辑回归的代价函数是最大化似然函数,似然函数公式为:
(7)
所谓的梯度就是函数变化最快的方向。将参数θ设为全1,然后在算法迭代的每一步里计算梯度,沿着梯度的方向移动,以此来改变参数θ,直到θ的拟合效果达到要求值或迭代步数达到设定值。θ的更新公式为:

(8)
4.2 数据分析
研究中定义了测试集P和识别集R,P和R中均含325个用户关系,其中包含95个水军用户和230个正常用户。使用逻辑回归模型对R中的水军进行识别,结果如表1、表2所示。分析表1和表2可知在步长和迭代次数相同时,和普通梯度上升函数相比,采用随机梯度上升函数作为Cost函数时识别率高出了12.46%,且步长相同时,迭代次数越多识别率越高。

表1 逻辑回归模型识别结果

表2 随机梯度上升在不同步长和迭代次数下识别结果
4.3 基于Scikit-learn机器学习库中分类算法的对比分析
Scikit-Learn是基于Python的机器学习模块,选择了Python机器学习库中多种不同的分类算法对提取的特征进行验证,对比提取的特征在不同算法作用下的正确率和特征的有效性[12-15]。
研究中设计了2个集合分别为含305个用户的训练集P和含305个用户的测试集T。P和T中均含有75个水军用户,230个正常用户。基于本文抽取的8个特征使用KNN最近邻、朴素贝叶斯、SVC和决策树4种方法进行水军识别,准确率分号为98.688%,99.016%,100%和100%。可见本文选取的8个特征在进行网络水军识别时是非常有效的,详细结果如表3所示[12-15]。
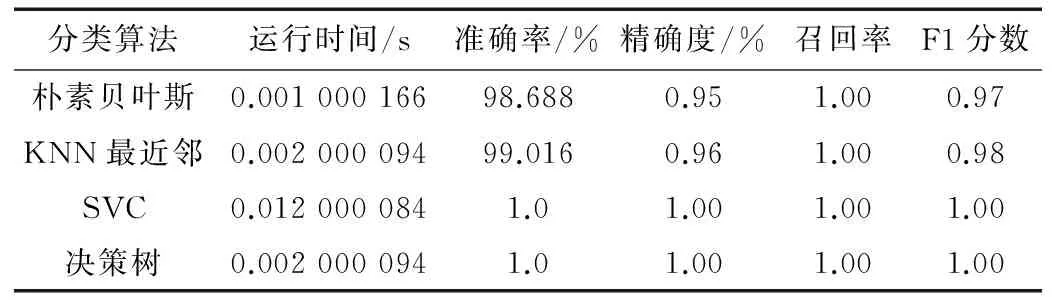
表3 Scikit-Learn机器学习库中各分类算法识别结果
5 结论
本文抽取了粉丝数、关注数、好友粉丝比、注册时间、活跃度、关注速率、双向关注比和互粉数共8个有效特征,使用逻辑回归方法实现水军用户的识别,识别率可达到98.77%,逻辑回归分类模型在水军识别研究中具有高准确性和可靠性。
[1] 陶永才,王晓慧,石磊,等.基于用户粉丝聚类现象的微博僵尸用户检测[J].小型微型计算机系统,2015,36(5):1007-1011.
[2] 莫倩,杨珂.网络水军识别研究[J].软件学报,2014,25(7):1505-1526.
[3] 程晓涛,刘彩霞,刘树新.基于关系图特征的微博水军发现方法[J]. 自动化学报,2015,41(9):1533-1541.
[4] HAGBERG A,SCHULT D,SWART P. Exploring network structure,dynamics,and function using NetworkX[C]. Scipy, 2008:11-15.
[5] 方洁, 龚立新, 魏疆. 基于利益相关者理论的微博舆情中的用户分类研究[J]. 情报科学, 2014,32(1):18-22.
[6] 韩忠明,许峰敏,段大高.面向微博的概率图水军识别模型[J]. 计算机研究与发展,2013,50(S2):180-186.
[7] 陈侃,陈亮,朱培栋,等.基于交互行为的在线社会网络水军检测方法[J].通信学报,2015,36(7):120-128.
[8] 王越,张剑金. 一种应用SAVBP神经网络的僵尸粉判别方法[J].重庆理工大学学报(自然科学),2014,28(4):72-76.
[9] 张良,朱湘,李爱平,等.一种基于逻辑回归算法的水军识别方法[J]. 信息安全与技术,2015(4):57-62.
[10] YU L L, ASUR S,HUBERMAN B A. Trend dynamics and attention in Chinese social media[J]. Ssrn Electronic Journal,2015,59(9).
[11] HARRINGTON P. Machine learning in action[M]. Manning Publications,2012.
[12] 何友奇,蒋新华,聂明星.基于模糊贝叶斯网络的叉装车制动系统故障诊断研究[J].微型机与应用,2016,35(11):70-73.
[13] 郭朝伟,张中炜.基于决策树学习的柱状二级管表面缺陷检测系统设计[J]. 微型机与应用,2015,34(6):39-41.
[14] 张线媚.数据挖掘在电信行业客户流失预测中的应用[J]. 微型机与应用,2015,34(15): 99-102.
[15] 杜翠红,李晓峰,简冲,等. SVC在无线信道传输中的非均衡差错保护[J]. 电子技术应用,2010,36(8):130-133,137.
The recognition of public opinion viruses of micro-blog based on logistic regression
Xie Zhonghong, Zhang Ying, Zhang Lin
(School of Information Science and Technology, Nanjing Agricultural University, Nanjing 210095, China)
Drived by the potential commercial benefits, micro-blog’s public opinion viruses rampant between topics and comments, and they not only have a bad influence on understanding the real result for people, but also have become an obstacle to normal users to explore the truth. This paper analyzed the normal users and public opinion viruses diagram, as the starting point for the study, after analysing the characteristics of the public opinion , 8 characters (number of fans, number of friends, the number of mutual concern, register time, activity, attention rate and the rate of fans and friends) were extracted. After obtaining reliable regression coefficients by classification training logistic regression model based on a learning data set, the public opinion viruses recognition rate was as high as 98.770% based on recognition sample setR. In order to verify that the 8 features could identify the public opinion viruses effectively, 4 kinds of classification methods in Scikit-Learn machine repository were used to recognize public opinion viruses in the same sample setR, and the recognition accuracy rate was above 98.688%.The results show that the logistic regression model has high accuracy and reliability in the recognition of classification public opinion viruses.
micro-blog; public opinion viruses; logistic regression
南京农业大学中央高校基本科研业务费人文社会科学研究基金项目(SK2015023);国家社会科学基金项目(13CTQ031)
TP393
A
10.19358/j.issn.1674- 7720.2017.16.019
谢忠红,张颖,张琳.基于逻辑回归算法的微博水军识别[J].微型机与应用,2017,36(16):67-69,72.
2017-02-23)
谢忠红(1977-),女,博士,副教授,主要研究方向:情报信息处理、图像处理、机器视觉技术。
张琳(1970-),女,学士,副教授,主要研究方向:情报信息处理。
猜你喜欢
《学习方法报》政治新教材高一(2023年8期)2023-04-29 00:44:03
法律方法(2022年2期)2022-10-20 06:44:24
中学生百科·大语文(2021年11期)2021-12-05 14:27:54
新世纪智能(数学备考)(2021年9期)2021-11-24 01:14:34
纺织科学研究(2021年7期)2021-08-14 01:42:34
中学生数理化·中考版(2021年3期)2021-07-22 07:41:30
新世纪智能(数学备考)(2020年9期)2021-01-04 00:25:12
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28 08:43:52
37°女人(2017年11期)2017-11-14 20:27:40
方圆(2017年12期)2017-07-17 17:50:26
