
基于DAE-RBM-PLDA的说话人确认信道补偿技术*
2017-09-03 09:17尹主峰徐志京
网络安全与数据管理 2017年15期
尹主峰,徐志京
(上海海事大学 信息工程学院,上海 201306)
基于DAE-RBM-PLDA的说话人确认信道补偿技术*
尹主峰,徐志京
(上海海事大学 信息工程学院,上海 201306)
在说话人识别系统中,一种结合深度神经网路(DNN)、身份认证矢量(i-vector)和概率线性鉴别分析(PLDA)的模型被证明十分有效。为进一步提升PLDA模型信道补偿的性能,将降噪自动编码器(DAE)和受限玻尔兹曼机(RBM)以及它们的组合(DAE-RBM)分别应用到信道补偿PLDA模型端,降低说话人i-vector空间信道信息的影响。实验表明相比标准PLDA系统,基于DAE-PLDA和RBM-PLDA的识别系统的等错误率(EER)和检测代价函数(DCF)都显著降低,结合两者优势的DAE-RBM-PLDA使系统识别性能得到了进一步提升。
说话人识别;i-vector;降噪自动编码器;受限玻尔兹曼机
0 引言
说话人识别属于生物特征识别技术的一种,是一项从说话人语音中提取有效特征信息进行说话人识别的技术。比较流行的说话人识别模型是建立在以混合高斯模型-通用背景模型(GMM-UBM)[1]的基础上。随后Patrick等人提出联合因子分析(JFA)[2],Najim 等提出全局差异空间因子( i-vector)[3]等建模方法。当前i-vector已成为文本无关的说话人识别最有效的技术,这个框架可以被分为3个步骤:(1)利用GMM-UBM把语音声学特征序列表示成充分统计量;(2)转换成低维的特征向量i-vector,提取i-vector;(3)使用PLDA模型进行信道补偿并通过比较不同语音段的i-vector产生验证分数得出判决结果。
近年来,深度神经网路DNN被成功应用于语音识别领域[4]。在说话人识别领域,Lei等[5]利用DNN对语音特征根据音素分类到不同音素空间中,然后在每个空间中对特征降维提取出不同发音的声学特征,提出基于DNN的i-vector。该模型把UBM中计算各类后验概率的方法利用DNN输出层Softmax的输出来表示,为说话人确认带来显著的性能提升。
降噪自动编码器(DAE)可通过训练从损坏的数据重构出原始数据。把说话人的特征表示i-vector受说话人信道信息的影响看成是受损的数据。因此通过DAE重构的方法进行信道补偿可以获得更加鲁棒的效果,产生抗噪能力,从而降低说话人的信道差异性。在文献[6]中,基于RBM-PLDA的信道补偿技术被证明性能优于传统PLDA。RBM通过分离出说话人信息和信道信息重构i-vector,然后把包含说话人信息的因子应用于PLDA端进行比较。本文结合DAE和RBM各自的优点提出基于DAE-RBM-PLDA的信道补偿方法,从而进一步降低说话人信道多样性的影响。
1 基于i-vector的说话人识别系统
1.1 GMM i-vector技术
i-vector因子分析模型将说话人差异空间与信道差异空间作为一个整体进行建模。模型建立在GMM-UBM所表示的均值超矢量之上。说话人的一段语音相对应的均值超矢量可以分解为下式:
M=m+Tω
(1)
其中,m为UBM的均值超矢量,T为低秩的全局差异空间矩阵,ω为全局差异空间因子,它的后验均值即为i-vector矢量。
在i-vector的提取过程中需要使用EM算法估计全局差异空间矩阵T,提取Baum—Welch统计量,说话人s的语音段h在第j个GMM混合成分的零阶统计量和一阶统计量分别为:
(2)
(3)
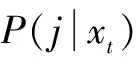
(4)
然后进行如下计算即可得到对应的i-vector:
ωh=E[Wh]=I-1TT∑-1Fh
(5)
1.2 DNN i-vector技术
GMM具有强大的拟合能力,但它不能有效地对非线性或近似非线性的数据进行建模是它的不足之处。因此DNN被应用于声学建模中,DNN的多层非线性结构使其具有强大的表征能力,它使用无监督生成式算法进行预训练,然后使用反向传播算法进行参数微调。
DNN由输入层、多隐藏层和Softmax输出层构成。Softmax层给出的是绑定三因素状态类在语音帧上的后验概率P(j|xt) ,它被用作对应高斯上的占有率,代入式(2)和式(3)可以估计出DNN i-vector的零阶统计量和一阶统计量,然后根据式(5)提取i-vcetor。基于DNN的i-vector提取过程及判别过程如图1所示。
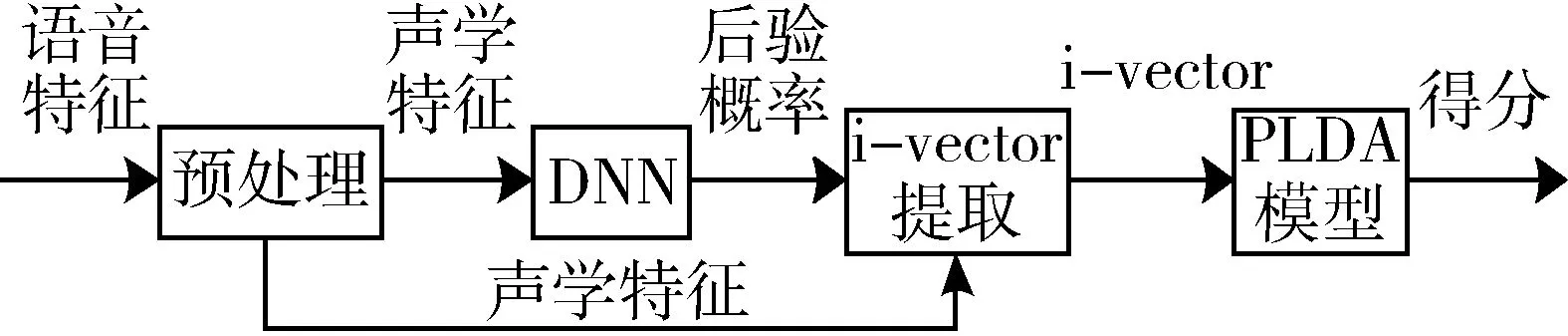
图1 基于DNN的说话人识别系统流程图
2 后端PLDA技术分析
2.1 PLDA模型
PLDA是一种基于i-vector的信道补偿算法,i-vector特征包含说话人信息和信道信息。要提取说话人信息,所以需要进行信道补偿,去除信道的干扰。经过简化的PLDA被证明是信道补偿的有效方法[7]。简化的PLDA模型如下式所示:
ωsh=μ+Vys+zsh
(6)
其中,ωsh表示第s个人第h段语音的i-vector,μ为所有训练数据的均值,矩阵V描述说话人的子空间,表征说话人类间差异,ys为隐藏说话人因子,zsh为残差噪声。以上参数满足如下分布:
ys~N(0,1)
(7)
zsh~N(0,D)
(8)
PLDA训练阶段的目的是根据一定样本的说话人语音数据集用EM算法估计出模型需要的参数θ={μ,V,D}。模型训练好之后进行识别打分,给定相同说话人注册和测试的i-vector分别为ωe和ωs,采用下式计算似然比分数:
(9)
其中H0表示ωe和ωs来自同一说话人,H1表示来自不同说话人。计算两个高斯函数的似然比作为得分进行最终判决。
2.2 基于DAE和RBM的PLDA
降噪自编码器(DAE)是一种通过特殊训练得到的自编码器。在输入中接受受损数据作为输入,并训练来预测原始未损坏数据作为输出的自动编码器,使其产生抗噪能力,从而得到更加鲁棒的数据重构效果。DAE的训练过程如图2所示。引入一个损坏过程C(y|x),这个条件代表给定数据x产生损坏样本y的概率。自动编码器假设x是原始输入,降噪自动编码器利用C(y|x)引入损坏样本y。然后把y当作带噪声的损坏输入,把x当作输出,对自编码进行学习训练。把DAE应用到说话人识别系统后端模型最早在文献[8]中被提出,本文将在此基础上继续探讨进一步提升系统性能。在本系统中把说话人的i-vector受说话人信道信息的影响看成受损的数据,其训练可简化为如下过程。

图2 DAE结构原理图
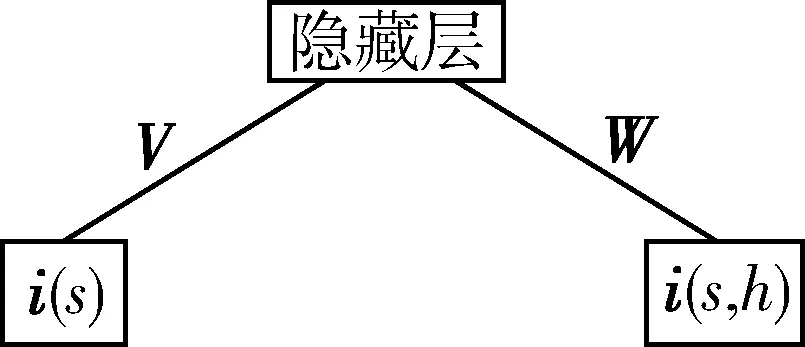
图3 RBM预训练
实验中DAE的训练过程是先按图3进行RBM预训练。隐含层神经元取二进制值并服从伯努利分布,可见层神经元连接两个服从高斯分布的实数值向量i(s)和i(s,h)作为输入。其中向量i(s)表示说话人s的所有语音段的平均i-vector,向量i(s,h)表示从说话人s的第h段语音提取的i-vector。RBM的训练用CD算法[9],权重矩阵参数V、W用来初始化DAE模型。
预训练之后把模型展开成如图4所示,此模型可以看作标准DAE模型来重建i-vector。输出端采用说话人平均i-vector降低说话人信道信息的差异性。之后采用反向传播算法对网络参数进行调优。DAE的输出经白化和长度规整处理后可直接作为标准PLDA模型的输入(DAE-PLDA)进行得分验证并根据事先设定的阈值进行判决。
RBM是一种由随机性的一层可见层神经元和一层隐藏神经元所构成的无向图模型。它可以作用于PLDA信道补偿端,隐藏层被分解为说话人信息因子和信道信息因子,如图5所示。采用文献[6]类似的算法进行训练,不同之处是为保持与前文DAE预训练时隐藏层数值类型一致,这里隐藏层采用二进制数值并服从高斯伯努利分布。进入识别阶段,可见层输入说话人的i-vector,输出端包含说话人信息的说话人因子作为PLDA模型(RBM-PLDA)的输入来进行得分比较。

图4 DAE
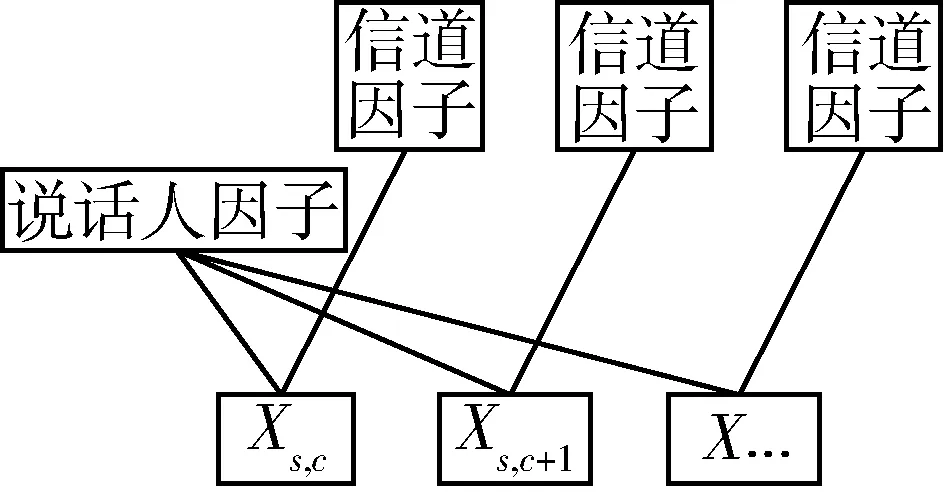
图5 RBM-PLDA
由以上分析可知,基于DAE是无损转换和RBM的有效特征提取原理。考虑使用DAE和RBM混合的方法,第一层为DAE,经白化和长度规整技术处理后输出作为RBM的输入,RBM与标准PLDA结合后组成判别模型,记为DAE-RBM-PLDA。系统框图如图6所示。
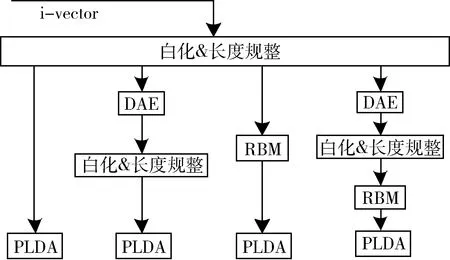
图6 PLDA、DAE-PLDA、RBM-PLDA、DAE-RBM-PLDA流程
3 实验与结果
本文采用TIMIT语料库作为实验语音数据库,采用等错误率(EER)和检测代价函数(DCF)作为性能评价指标。
在UBM i-vector系统中使用MFCC加一维能量及其一、二阶差分共39维MFCC特征。语音帧长25 ms,帧移10 ms。DNN i-vector系统中DNN说话人特征为40维Filter Bank特征以及一、二阶差分共120维。DNN共5个隐藏层,每层2 048个结点。首先比较了标准PLDA模型在UBM i-vector和DNN i-vector系统下的性能,实验证明DNN系统的识别性能比GMM-UBM系统显著提高。之后以DNN i-vector的PLDA为基线系统,性能对比如图7和表1所示。
由表1实验结果可以看到,相对于标准PLDA模型系统,应用深度学习模型的DAE-PLDA和RBM-PLDA后端信道补偿模型等错误率和检测代价函数都显著降低。将两者结合后的DAE-RBM-PLDA模型,性能提升更加明显,相对于基线系统性能提升了14.5%,体现了该信道补偿方法的有效性。
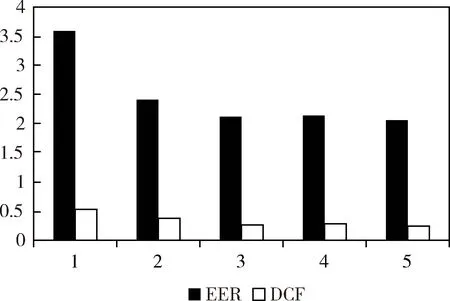
图7 模型性能柱状图

表1 PLDA、DAE-PLDA、RBM-PLDA、DAE-RBM-PLDA性能比较
4 结论
本文结合DAE和RBM的优点提出了基于DAE-RBM-PLDA的说话人确认信道补偿方法。该方法先把经过白化和长度规整技术处理的i-vector进行RBM预训练并初始化DAE模型,DAE的输出为说话人所有语音段的平均i-vector,从而降低了说话人信道信息的影响。然后与RBM相结合,把DAE的输出i-vector作为RBM的输入,隐含层重构分离出说话人信息和说话人信道信息,选择实验需要的说话人信息进行后端PLDA最终的似然比分数,进一步降低了说话人的信道差异性。在TIMIT数据集上的说话人确认实验表明结合了DAE和RBM两者优势的DAE-RBM-PLDA模型,可有效提高识别率。
[1] REYNOLDS D A, QUATIERI T F, DUNN R B. Speaker verification using adapted Gaussian mixture models[J]. Digital Signal Processing, 2000, 10(1-3): 19-41.
[2] KENNY P,OUELLET P,DEHAK N,et al. A study of interspeakervariability in speaker verification[J]. IEEE Transaction on Audio,Speech, and Language Processing, 2008,16(5): 980-988.
[3] DEHAK N,KENNY P,DEHAK R,et al. Front-end factor analysis for speaker verification[J]. IEEE Transactions on Audio,Speech,and Language Processing,2011,19(4): 788-798.
[4] HINTON G, DENG L, YU D, et al. Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups[J]. IEEE Signal Processing Magazine, 2012, 29(6): 82-97.
[5] VARIANI E, LEI X, MCDERMOTT E, et al. Deep neural networks for small footprint text-dependent speaker verification[C]. 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2014: 4052-4056.
[6] STAFYLAKIS T, KENNY P, SENOUSSAOUI M, et al. PLDA using gaussian restricted boltzmann machines with application to speaker verification[C].Interspeech, 2012: 1692-1695.
[7] GARCIA-ROMERO D, ESPY-WILSON C Y. Analysis of i-vector length normalization in speaker recognition systems[C].Interspeech, 2011: 249-252.
[8] NOVOSELOV S, PEKHOVSKY T, KUDASHEV O, et al. Non-linear PLDA for i-vector speaker verification[C].Interspeech, 2015: 214-218.
[9] HINTON G E. A practical guide to training restricted boltzmann machines[M].Neural Networks: Tricks of the Trade. Springer Berlin Heidelberg, 2012: 599-619.
Technology of speaker verification channel compensation based on DAE-RBM-PLDA
Yin Zhufeng, Xu Zhijing
(College of Information Engineering, Shanghai Maritime University, Shanghai 201306, China)
A hybrid model combining the deep neural network (DNN), i-vector and probabilistic linear discriminant analysis (PLDA) has been shown effective in the system of speaker recognition. In order to improve the performance of PLDA recognition model, the denoising autoencoder (DAE) and restricted boltzmann machine(RBM) and the combination of them(DAE-RBM) are used to channel compensation on PLDA model to minimize the effect of the speaker i-vector space channel information. The experiment showed that the recognition system based on DAE-PLDA and RBM-PLDA is significantly decreased than the standard PLDA for the equal error rate(EER) and detection function(DCF). The DAE-RBM-PLDA which combined with the advantages of them makes the performance of the recognition system has been further improved.
speaker recognition; i-vector; denoising autoencoders; restricted boltzmann machine
国家自然科学基金项目(61404083)
TP391
A
10.19358/j.issn.1674- 7720.2017.15.018
尹主峰,徐志京.基于DAE-RBM-PLDA的说话人确认信道补偿技术[J].微型机与应用,2017,36(15):62-64,72.
2017-03-02)
尹主峰(1986-),男,硕士研究生,主要研究方向:智能信息处理。
徐志京(1972-),男,工学博士,副教授,主要研究方向:无线通信和导航技术、人工智能、深度学习。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
制造技术与机床(2017年7期)2018-01-19
西安工程大学学报(2016年6期)2017-01-15
系统工程与电子技术(2016年7期)2016-08-21
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
探测与控制学报(2015年4期)2015-12-15
