
入侵检测分类技术的比较研究
2017-09-03 09:17郝晓弘张晓峰
网络安全与数据管理 2017年15期
郝晓弘,张晓峰
(兰州理工大学 计算机与通信学院,甘肃 兰州 730050)
入侵检测分类技术的比较研究
郝晓弘,张晓峰
(兰州理工大学 计算机与通信学院,甘肃 兰州 730050)
入侵检测是网络安全研究的主要问题之一,有效的检测方法在开发入侵检测系统中发挥着至关重要的作用。通过对数据挖掘中的分类算法进行深入研究,选取四种常用的分类算法如决策树、贝叶斯、K最近邻法和神经网络来分别构建入侵检测系统,旨在找到最有效的分类算法。仿真实验在Weka环境下使用KDD CUP99数据集进行测试。实验表明,采用C4.5决策树构建的入侵检测系统具有良好的检测性能,是一种非常有效的网络入侵检测方法。
入侵检测;数据挖掘;Weka ;KDD CUP99
0 引言
随着计算机技术与互联网的快速发展,使得人们对网络的依赖愈加强烈。而随之而来的网络安全问题已成为当下社会关注的焦点,其中网络入侵是网络安全最主要的威胁[1]。尽管诸如访问控制、信息加密和入侵防御等安全技术可以用来保护网络系统,但仍然存在很多无法检测到的入侵[2],比如,防火墙不能够防御内部攻击。因此,在网络安全中入侵检测系统起着非常重要的作用。
入侵检测的概念开始于James P. Anderson[3]的信息安全技术研究报告,他提出了一种将计算机系统存在的威胁和风险进行分类的方法,将威胁分为3种类型:外部渗透、内部渗透和不法行为,还提出通过审计跟踪数据对攻击行为进行监视的思想。入侵检测技术可以定义为识别和处理计算机网络资源被恶意使用的系统,包括内部用户的未授权和外部系统入侵行为,它也是一种确保计算机系统安全性的技术,能够发现非授权和异常行为,用于检测威胁网络安全的情况[4]。入侵检测技术可以分为两类:误用检测和异常检测。误用检测是指通过攻击行为与特征库匹配来确认攻击事件,具有较低的漏报率。但是它不能发现未知的攻击。异常检测是指将用户正常行为的特征存储到数据库中,然后将用户的当前行为与数据库中的行为进行对比。如果分歧足够大,则认为该行为是异常。它最大的优点是能够检测到未知的攻击。但是,由于正常的行为特征库不能给出系统中所有用户行为的完整描述,而且每个用户的行为随时在变化,因此,它具有较高的误报率。
Wenke Lee首次提出了一种使用数据挖掘技术进行入侵检测的系统框架[5],通过将数据挖掘中的分类、关联规则和序列等算法应用于入侵检测,形成有效的检测模型。数据挖掘技术能够有效地提取用于误用检测的入侵模式,建立用于异常检测的正常网络行为库,并且构建分类器来检测攻击,尤其针对大量的审计数据[6]。其中基于分类的入侵检测系统将所有的流量数据分为正常或异常,它不仅节省时间,而且也能有效分析攻击数据。
在本文中,将数据挖掘的4种分类算法应用于入侵检测,采用KDD CUP99数据集[7]在Weka环境下测试不同的分类算法,通过分析各算法的准确度、灵敏度、特异性和计算时间等性能,从而找到在其性能度量方面表现最好的算法。
1 数据挖掘与分类算法描述
数据挖掘也称为数据库中的知识发现,是指从大量数据中提取或挖掘知识。基于数据挖掘的入侵检测系统仅需要标记流量数据来指示入侵而不用手动编码规则。其中,分类是最常用的有监督的数据挖掘技术之一。分类的任务是从分类对象构建分类器,以便对先前未知的对象尽可能准确地进行分类。根据类别上可用的信息和分类类型,分类器的输出可以用不同的形式呈现。
1.1 决策树算法
决策树是数据挖掘中使用最广泛并且非常有效的分类算法。它以自上而下、分类治之的方式进行操作,通过一组无序、无规则的事例推理出决策树的分类规则,是基于实例的归纳学习方法,能够完成对位置数据的预处理、分类以及预测[8]。决策树是通过信息理论的原则采用分析与归纳的方法来构建。
决策树算法将样本属性值与构建的决策树进行类比,从而实现对未知的样本进行准确分类。Quinlan推广了决策树的使用方法,并且提出了C4.5决策树,成为新的监督学习算法的性能比较基准[9]。决策树算法最主要的问题就是找到最佳的将数据划分为其相应类的属性。C4.5采用信息熵的概念通过训练数据集来构建决策树。也就是说,它是基于每个属性的最高增益。信息增益定义为原来信息需求与新的需求之间的差值,增益公式如下:
Gain(A)=Info(D)-InfoA(D)
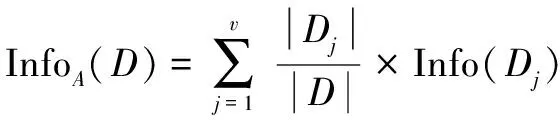
这里,熵计算公式如下:
其中,pi是D中任意元组属于Ci的概率。由于信息使用的是二进制编码,因此,使用以2为底的对数函数。Info(D)是识别D中元组的类标号所需的平均信息量。
在通过最大化增益创建树之后,C4.5模型分解数据空间,使得某些分解区域变得均匀。由于在决策树建立时,数据中存在噪声和离群点,很多分枝反映出了训练数据中的异常,通过C4.5执行修剪步骤来处理数据过分拟合的问题,使决策树变得更为普遍。
1.2 朴素贝叶斯算法
目前,存在很多变化的贝叶斯模型,这些都是基于贝叶斯定理构造的。本文描述一种典型的朴素贝叶斯模型。朴素贝叶斯分类法又称为简单贝叶斯分类法[10],它的过程如下:
(1)令D是元组及其相关联的类标签的训练集合。每个元组由n维属性向量X=(x1,x2,…,xn)表示,描述分别从n个属性A1,A2,…,An对该元组进行的n个测量。
(2)假设有m个类C1,C2,…,Cm,给定一个元组x,分类器将能够预测出x属于具有最高后验概率的类,它是以x为条件来预测的。换句话说,朴素贝叶斯分类器预测元组x属于类Ci,如果仅当
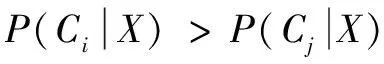
因此,需要最大化P(Ci|X)。 将P(Ci|X)最大化的类Ci称作最大后验假设。 按照贝叶斯定理方程,有:
(3)由于P(X)对于所有情况都是常数,因此,只要使P(X|Ci)P(Ci)最大化即可。假如类先验概率不为已知的,则通常假设这些类具有相同的概率,即P(C1)=P(C2)=…=P(Cm),因此只要使P(X|Ci)最大化。反之,需要最大化P(X|Ci)P(Ci)。
(4)当给定的数据集具有许多属性时,计算P(X|Ci)将是非常复杂的。为了在评估P(X|Ci)时减少计算,进行类条件独立的假设。给定各元组的类标签,假定属性的值有条件地互相独立,从而有:
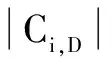
②如果Ak是连续属性值,则需要做更多的工作,但计算是非常简单的。连续属性值通常假定为具有平均值和标准偏差的Guassian分布,定义为:
1.3 人工神经网络算法
人工神经网络是一种能够进行信息处理的数学模型,人工神经网络是基于模拟生物神经系统来处理信息[11]。神经网络是通过互相连接的节点和有向的边组合而成,每一个神经元代表一个信息处理单元,其中包括一组与其他神经元相互连接的突触权值(又称权重w)、一个用来将所有的输入信号迭加到加法器的求和装置、用于控制神经元输出的激活函数f(·)以及一个用来减小对激活函数累计输入的阈值θ。神经网络输出的结果会随连接方式、权重值以及激励函数的变化而变化,因此,可以把网络本身看作是对某一种算法的实现[12]。神经元数学模型如图1所示。

图1 神经元数学模型
其中,x1,x2,…,xn代表神经元的输入,即来自前一级的n个神经元的轴突信息,w1j,w2j,…,wnj分别表示j神经元对x1,x2,…,xn的权重系数,即为突触的传递效率,f(·)是激发函数,它决定了j神经元受输入x1,x2,…,xn的共同刺激所达到的阈值使用哪种方式输出。
神经元的激发函数f(·)是非线性函数,它有很多表示形式,典型的有阈值函数、阶跃函数以及Sigmoid型函数(简称S型函数)。目前,S型函数使用最广泛,它的输出是非线性的,因此,称这种神经元为非线性连续模型。其表达式为:
假设Ij代表一个神经元,它的数学表达式如下:
其中,wij是由上一层的单元i到单元j的连接权重,oi是上一层的单元i的输出,而θj是单元j的偏倚,用来充当阈值,改变单元的活性。
1.4 K最近邻算法
K最近邻是一种简单有效的技术,该算法是基于类比的学习分类法,它将给定的目标元组和与它相似的训练元组进行类比来分类。用n个属性来描述训练元组,其中,每个元组表示n维空间中的一个点,这样就将所有训练元组存放于N维的模式空间中。在给定某个未知的元组时,k最近邻分类方法搜寻整个模式空间,找到与未知元组最接近的K个训练元组,那么这K个训练元组就是该未知元组的K个近邻。
考虑一组观察值和目标值(x1,y1),…,(xn,yn),其中观测值xi∈Rd,目标值yi∈{0,1},则对于给定的i,k近邻对训练样本中的测试序列的邻居进行速率估计,并使用最近邻的类别标签来预测测试向量类。因此,k最近邻取新点,并根据对训练数据中的K个最近点获得的大部分投票将它们分类。在k最近邻中,欧几里得距离通常用作距离度量,以测量两个向量[13]:
其中,(xi,xj)∈Rd,xi=(xi1,xi2,…,xid)。
2 实验与结果分析
在Weka环境中使用KDD CUP99数据集进行实验。KDD CUP99是入侵检测方法中最常用的数据集,包含测试数据中约200万条记录和训练数据集中约490万条记录,每个记录包含41个特征和一个决策属性[14]。由于原始数据集数量庞大,因此,本文从KDD CUP99 10%数据集中随机抽取数据样本来进行仿真实验,并采用十折交叉验证来测试和评估四种分类算法[15]。在十折交叉验证过程中,数据集被分为10个子集。在每一次测试时,10个子集中的一个被用作测试数据集,剩余的子集构成训练集。本文基于准确度、灵敏度、特异性和时间来比较各分类器的性能,测试结果如表1、图2、图3所示。
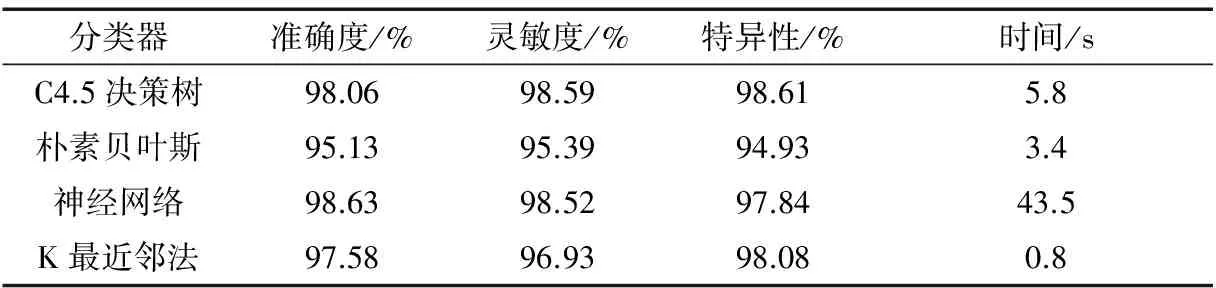
表1 分类器性能指标
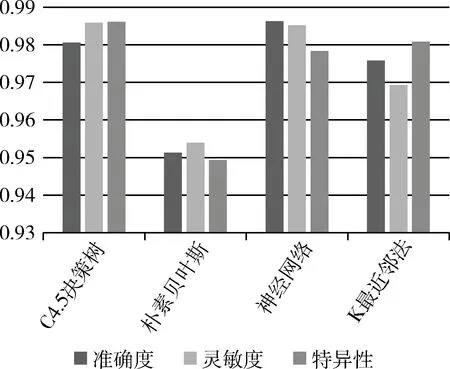
图2 四种分类器的性能
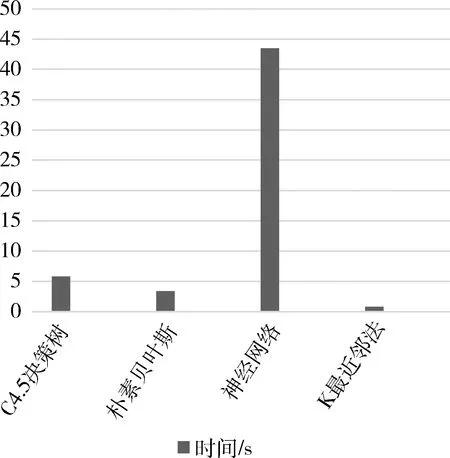
图3 四种分类器建模时间
由图2可以看出,在对入侵行为进行检测时,由决策树构成的分类器具有很好的分类效果。其次是神经网络,它具有很高的准确率,达到98.63%,但是该算法计算复杂度比较高,因此,需要消耗更多的时间来建模。从图3可以看出,由于K最近邻法是一种惰性学习,再加上更快的训练阶段,所以,需要最短的时间约0.8 s,相比于其他三种算法在训练阶段具有较低的耗时。通过综合分析四种分类器的准确度、灵敏度、特异性以及建模时间等性能指标不难看出,由C4.5决策树算法构建的分类器具有很好的分类能力,能够有效地检测入侵行为,是一种非常有效的网络入侵检测方法。
3 结论
本文的研究目的是通过仿真实验来找出应用于网络入侵检测系统的最佳可用分类技术。通过使用KDD CUP99数据集在Weka平台进行测试,并观察各个分类算法的性能。实验表明,C4.5决策树分类算法具有良好的分类性能。其中由神经网络构建的分类器在准确度、灵敏度和特异性等方面的表现优于K最近邻算法,而K最近邻算法与其他分类方法相比具有最少的消耗时间。在将来的研究工作中,可以通过混合应用不同的数据挖掘算法和数据缩减技术来提高检测的准确率,实现对入侵行为的检测。
[1] 楼文高,姜丽,孟祥辉. 计算机网络安全综合评价的神经网络模型[J]. 计算机工程与应用,2007,43(32):128-131.
[2] ZHU D, PREMKUMAR G, ZHANG X, et al. Data mining for network intrusion detection: a comparison of alternative methods[J]. Decision Sciences, 2001, 32(4): 635-660.
[3] ANDERSON J P. Computer security threat monitoring and surveillance[R]. James P. Anderson Company, Fort Washington, Pennsylvania, 1980.
[4] MOHAMMAD M N, SULAIMAN N, MUHSIN O A. A novel intrusion detection system by using intelligent data mining in weka environment[J]. Procedia Computer Science, 2011, 3(1): 1237-1242.
[5] LEE W, STOLFO S J. Data mining approaches for intrusion detection[C].Usenix security, 1998.
[6] CHAUHAN H, KUMAR V, PUNDIR S, et al. A comparative study of classification techniques for intrusion detection[C]. 2013 International Symposium on Computational and Business Intelligence (ISCBI), IEEE, 2013: 40-43.
[7] BHAVSAR Y B, WAGHMARE K C. Intrusion detection system using data mining technique: support vector machine[J]. International Journal of Emerging Technology and Advanced Engineering, 2013, 3(3): 581-586.
[8] SINDHU S S S, GEETHA S, KANNAN A. Decision tree based light weight intrusion detection using a wrapper approach[J]. Expert Systems with Spplications, 2012, 39(1): 129-141.
[9] KOSHAL J, BAG M. Cascading of C4.5 decision tree and support vector machine for rule based intrusion detection system[J]. International Journal of Computer Network and Information Security, 2012, 8(8): 394-400.
[10] 李玲俐. 数据挖掘中分类算法综述[J]. 重庆师范大学学报(自然科学版),2011,28(4):44-47.
[11] LI J, ZHANG G Y, GU G C. The research and implementation of intelligent intrusion detection system based on artificial neural network[C]. Proceedings of 2004 International Conference on Machine Learning and Cybernetics, IEEE, 2004: 3178-3182.
[12] 谈恒贵,王文杰,李游华. 数据挖掘分类算法综述[J]. 微型机与应用,2005,24(2):4-6,9.
[13] ABUROMMAN A A, REAZ M B I. A novel SVM-kNN-PSO ensemble method for intrusion detection system[J]. Applied Soft Computing, 2016(38): 360-372.
[14] 张新有,曾华燊,贾磊.入侵检测数据集KDD CUP99研究[J]. 计算机工程与设计,2010,31(22):4809-4812,4816.
[15] BAMAKAN S M H, WANG H D, TIAN Y J, et al. An effective intrusion detection framework based on MCLP/SVM optimized by time-varying chaos particle swarm optimization[J]. Neurocomputing, 2016(199): 90-102.
A comparative study of intrusion detection classification technology
Hao Xiaohong, Zhang Xiaofeng
(School of Computer and Communication, Lanzhou University of Technology, Lanzhou 730050, China)
Intrusion detection is one of the main problems in network security research. Effective detection method plays an important role in the development of intrusion detection system.In this paper, through the in-depth study of classification algorithms of data mining, four kinds of commonly used classification algorithms, such as decision tree, Bayesian, K nearest neighbor method and neural network, are selected to construct the intrusion detection system respectively, and the most effective classification algorithm is found.Simulation experiments are performed using the KDD CUP99 data set in the Weka environment. The results show that the intrusion detection system constructed by C4.5 decision tree has a good detection performance and is a very effective method of network intrusion detection.
intrusion detection; data mining; Weka; KDD CUP99
TP31
A
10.19358/j.issn.1674- 7720.2017.15.003
郝晓弘,张晓峰.入侵检测分类技术的比较研究[J].微型机与应用,2017,36(15):8-11,15.
2017-04-12)
郝晓弘(1960-),男,硕士,教授,主要研究方向:智能信息处理、电子信息系统、控制网络与分布式系统、嵌入式系统。
张晓峰(1991-),男,硕士研究生,主要研究方向:智能信息处理、数据挖掘、网络安全。
猜你喜欢
电脑报(2021年14期)2021-06-28
法律方法(2021年4期)2021-03-16
广西科学(2020年3期)2020-08-02
成都信息工程大学学报(2019年3期)2019-09-25
计算机与生活(2019年5期)2019-07-18
电子制作(2018年16期)2018-09-26
吉林大学学报(理学版)(2018年2期)2018-03-29
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
铁道通信信号(2016年6期)2016-06-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
