
改进耦合字典学习的脑部CT/MR图像融合方法
2017-09-03 10:23王丽芳秦品乐
计算机应用 2017年6期
董 侠,王丽芳,秦品乐,高 媛
(中北大学 计算机与控制工程学院,太原 030051)
改进耦合字典学习的脑部CT/MR图像融合方法
董 侠,王丽芳*,秦品乐,高 媛
(中北大学 计算机与控制工程学院,太原 030051)
(*通信作者电子邮箱wsm2004@nuc.edu.cn)
针对目前使用单字典表示脑部医学图像难以得到精确的稀疏表示进而导致图像融合效果欠佳,以及字典训练时间过长的问题,提出了一种改进耦合字典学习的脑部计算机断层成像(CT)/磁共振成像(MR)图像融合方法。该方法首先将CT和MR图像对作为训练集,使用改进的K奇异值分解(K-SVD)算法联合训练分别得到耦合的CT字典和MR字典,再将CT和MR字典中的原子作为训练图像的特征,并使用信息熵计算字典原子的特征指标;然后,将特征指标相差较小的原子看作公共特征,其余为各自特征,并分别使用“平均”和“选择最大”的规则融合CT和MR字典的公共特征和各自特征得到融合字典;其次,将配准的源图像编纂成列向量并去除均值,在融合字典的作用下由系数重用正交匹配追踪(CoefROMP)算法计算得到精确的稀疏表示系数,再分别使用“2范数最大”和“加权平均”的规则融合稀疏表示系数和均值向量;最后通过重建得到融合图像。实验结果表明,相对于3种基于多尺度变换的方法和3种基于稀疏表示的方法,所提方法融合后图像在亮度、清晰度和对比度上都更优,客观参数互信息、基于梯度、基于相位一致和基于通用图像质量指标在三组实验条件下的均值分别为:4.113 3、0.713 1、0.463 6和0.762 5,字典学习在10次实验条件下所消耗的平均时间为5.96min。该方法可以应用于临床诊断和辅助治疗。
医学图像融合;K奇异值分解;系数重用正交匹配追踪;稀疏表示;字典训练
0 引言
在医学领域,医生需要对同时具有高空间和高光谱信息的单幅图像进行研究和分析,以便对疾病进行准确诊断和治疗[1]。这种类型的信息仅从单模态图像中无法获取,例如:计算机断层成像(Computed Tomography, CT)能够捕捉人体的骨结构,具有较高的分辨率,而磁共振成像(Magnetic Resonance, MR)能够捕捉人体器官的软组织如肌肉、软骨、脂肪等细节信息。因此,将CT和MR图像的互补信息相融合以获取更全面丰富的图像信息,可为临床诊断和辅助治疗提供有效帮助[2]。
目前应用于脑部医学图像融合领域比较经典的方法是基于多尺度变换的方法:离散小波变换(Discrete Wavelet Transform, DWT)[3]、平稳小波变换(Stationary Wavelet Transform, SWT)[4]、双树复小波变换(Dual-Tree Complex Wavelet Transform, DTCWT)[5]、拉普拉斯金字塔(Laplacian Pyramid, LP)[6]、非下采样Contourlet变换(Non-Subsampled Contourlet Transform, NSCT)[7]。基于多尺度变换的方法能够很好地提取图像的显著特征,并且计算效率较高,但是多尺度分解水平不易确定,分解层数太少则不能提取足够多的细节信息,分解层数太多则融合过程对图像误配准更加敏感,分解层数需要在细节提取能力和对误配准鲁棒性之间做出折中。另外,传统的融合策略也会导致融合图像对比度丢失。随着压缩感知[8]的兴起,基于稀疏表示的方法[9-10]被广泛用于图像融合领域,并取得了极佳的融合效果。Yang等[11]使用冗余的离散余弦变换(Discrete Cosine Transform, DCT)字典稀疏表示源图像,并使用“选择最大”的规则融合稀疏系数。DCT字典是一种隐式字典,易于快速实现,但是其表示能力有限。Aharon等[12]提出K奇异值分解(K-means-based Singular Value Decomposition, K-SVD)算法用于从训练图像中学习字典。与DCT字典相比,学习的字典是一种自适应于源图像的显式字典,具有较强的表示能力。学习的字典中将仅从自然图像中采样训练得到的字典称为单字典,单字典可以表示任意一幅与训练样本类别相同的自然图像,但对于结构复杂的脑部医学图像,使用单字典既要表示CT图像又要表示MR图像,难以得到精确的稀疏表示系数。Ophir等[13]提出小波域上的多尺度字典学习方法,即在小波域上对所有子带分别使用K-SVD算法训练得到所有子带对应的子字典。多尺度字典有效地将解析字典和学习的字典的优势相结合,能够捕捉图像在不同尺度和不同方向上包含的不同特征。但是所有子带的子字典也是单字典,使用子字典对所有子带进行稀疏表示仍然难以得到精确的稀疏表示系数,并且分离的字典学习时间效率较低。Yu等[14]提出基于联合稀疏表示的图像融合方法兼具去噪功能。这种方法是对待融合的已配准源图像本身进行字典学习,根据联合稀疏模型的第一种模型(Joint Sparsity Model-1, JSM-1)提取待融合图像的公共特征和各自特征,再分别组合并重构得到融合图像。这种方法由于是对待融合源图像本身训练字典所以适用于脑部医学图像,可以得到精确的稀疏表示系数;但是对于每对待融合的源图像都需要训练字典,时间效率低,缺乏灵活性。
针对上述问题,本文提出一种适用于脑部CT/MR图像融合的方法。不同于单字典的样本采集方式,该方法首先将高质量的脑部CT/MR图像对作为训练集,使用改进的K-SVD算法联合训练分别得到耦合的CT字典和MR字典,再结合空间域的方法融合CT和MR字典得到融合字典。融合字典很好地保留了CT和MR训练图像的特征,使用这样一个融合字典就可以同时准确地表示CT和MR源图像并得到精确的稀疏表示系数。其次,在耦合的特征空间下使用改进的K-SVD算法联合训练字典较其他几种经典字典学习方法提高了字典学习的时间效率。最后,在融合阶段将源图像列向量的均值去掉,这样只保留了图像纹理信息而不是图像的强度值,再使用不同的融合规则组合重构各部分得到融合图像。实验结果表明本文提出的方法在主观视觉和客观参数上性能较优。
1 稀疏表示和字典学习
稀疏表示理论的基本假设是:任何给定的自然信号都可以表示为字典中原子的稀疏线性组合[15]。对给定的信号x∈Rn,信号x的稀疏表示可以描述为x=Dα,其中矩阵D=(d1,d2,…,dm)∈Rn×m是一个字典,每个列向量di∈Rn(i=1,2,…,m)是字典D的一个原子,向量α∈Rm是含有一些非零元素的稀疏系数。稀疏系数α的计算式如下:

(1)
式中:向量α的稀疏水平是由l0范数衡量的;‖α‖0表示向量α中非零元素的个数;ε表示允许偏差的精度。问题(1)的求解过程称为“稀疏编码”。
在稀疏表示中,字典D的选择是非常关键的。构造字典的两种主要方法是:解析方法和基于学习的方法。与解析方法相比,基于学习的方法可以提高字典的性能和灵活性,应用范围更广。

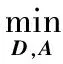
(2)
s.t. ∀i,‖αi‖0≤τ
式中:符号‖·‖F表示F范数;τ是稀疏矩阵A的稀疏度。MOD和K-SVD都是迭代算法,通过交替地执行稀疏编码和字典更新这两个步骤得到问题(2)的解。
2 改进的耦合字典学习和融合字典
精确的稀疏表示是图像融合成功的关键。经典的模型是从自然图像当中训练一个超完备字典来描述源图像。与自然图像相比,医学图像具有灰度不均匀、对比度低等特点,使用这样的超完备字典并不能精确地表示CT和MR图像。基于此,本文提出使用改进的K-SVD算法联合训练分别得到耦合的CT字典和MR字典,耦合的字典学习能够更高效完整地提取CT和MR图像的特征,然后再结合空间域的方法融合CT字典和MR字典得到融合字典。由于融合字典同时包含了CT和MR图像的特征,所以使用融合字典表示这两种源图像能够得到更精确的稀疏表示系数,从而提高脑部医学图像融合的质量。本文将提出的基于改进耦合字典学习的脑部CT/MR图像融合方法简记为ICDL(ImprovedCoupledDictionaryLearning)。图1为ICDL方法的流程。

图1 ICDL方法的流程
2.1 改进的耦合字典学习
本文使用的训练集是8个已经配准的CT和MR图像对,这些图像对来自哈佛大学医学院[17],如图2所示。从训练集中采样得到向量对{XC,XR},定义XC)∈Rd×n为n个采样的CT图像向量组成的矩阵,XR)∈Rd×n作为对应的n个采样的MR图像向量组成的矩阵。根据文献[18]和[19],本文的目标是在耦合的特征空间下训练两个字典DC,DR∈Rd×N,使得CT和MR训练图像在相应的字典作用下具有相同的稀疏表示系数A∈RN×n。图3为ICDL方法的字典学习过程。
传统的耦合字典学习问题可表示为:

(3)



图2 训练集

图3 ICDL方法的字典学习过程
本文的耦合字典训练使用改进的K-SVD算法[20],该算法是在字典学习代价函数式(3)中加入支撑完整的先验信息[21],交替地更新DC、DR和A,对应的训练优化问题如下:
(4)
s.t. ‖A‖0≤τ,A⊙M=0
式中:⊙代表点乘;掩膜矩阵M由元素0和1组成,定义为M={|A|=0},等价于如果A(i,j)=0则M(i,j)=1,否则为0。因此A⊙M=0能使A中所有零项保持完备。引入辅助变量:
(5)
(6)
则问题式(4)可以等价地转化为:

s.t. ‖A‖0≤τ,A⊙M=0
(7)
式(7)的求解过程分为稀疏编码和字典更新两个步骤。

s.t.A⊙M=0
(8)
分别对系数矩阵A中每一列的非零元素进行处理,而保持零元素完备,则式(8)可以转换为式(9):

(9)

其次,在字典更新阶段,式(7)的优化问题可以转化为式(10):

s.t.A⊙M=0
(10)
则式(10)的补偿项可以写为:

(11)

最后,循环执行稀疏编码和字典更新这两个阶段,直至达到预设的迭代次数为止,输出一对耦合的DC和DR字典。由于字典更新阶段同时更新字典和稀疏表示系数的非零元素,使得字典的表示误差更小且字典的收敛速度更快。在稀疏编码阶段,考虑到每次迭代时都忽略前一次迭代的表示,CoefROMP算法提出利用上次迭代的稀疏表示残差信息进行系数更新,从而更快地得到所要求问题的解[21]。
2.2 融合字典
为构造一个同时包含CT和MR两种图像特征的字典,使得这个字典能够同时精确地表示CT和MR源图像。考虑到2.1节中CT和MR训练图像在一对耦合字典的作用下具有相同的稀疏表示系数,因此将CT和MR字典中的原子作为训练图像的特征,再结合空间域的方法融合CT和MR字典得到融合字典。
具体地,令DC,DR∈Rd×N,LC(n)和LR(n)(n=1,2,…,N)分别代表CT字典和MR字典的第n个原子的特征指标。由于脑部CT和MR图像是对应于人体同一部位由不同成像设备获取的图像,因此两者之间一定存在着公共特征和各自特征。本文提出:将特征指标相差较大的原子看作各自特征,使用“选择最大”规则融合;特征指标相差较小的原子看作公共特征,使用“平均”的规则融合。融合字典的计算式表示如下:
DF(n)=
(12)
式中:设λ=0.25,DF∈Rd×N表示融合字典。根据医学图像的物理特性,使用信息熵[22]作为特征指标。这种方法将稀疏域和空间域的方法结合起来,考虑了医学图像的物理特性计算字典原子的特征指标,与稀疏域的方法相比,具有更加明确的物理意义。
3 脑部CT/MR图像融合过程
不失一般性,设已经配准的脑部CT/MR源图像IC,IR∈RMN。图4为脑部CT/MR图像融合流程,融合过程如下:


(13)

(14)



(15)


(16)
其中:DF是由2.2节提出的融合字典。

(17)

(18)


(19)

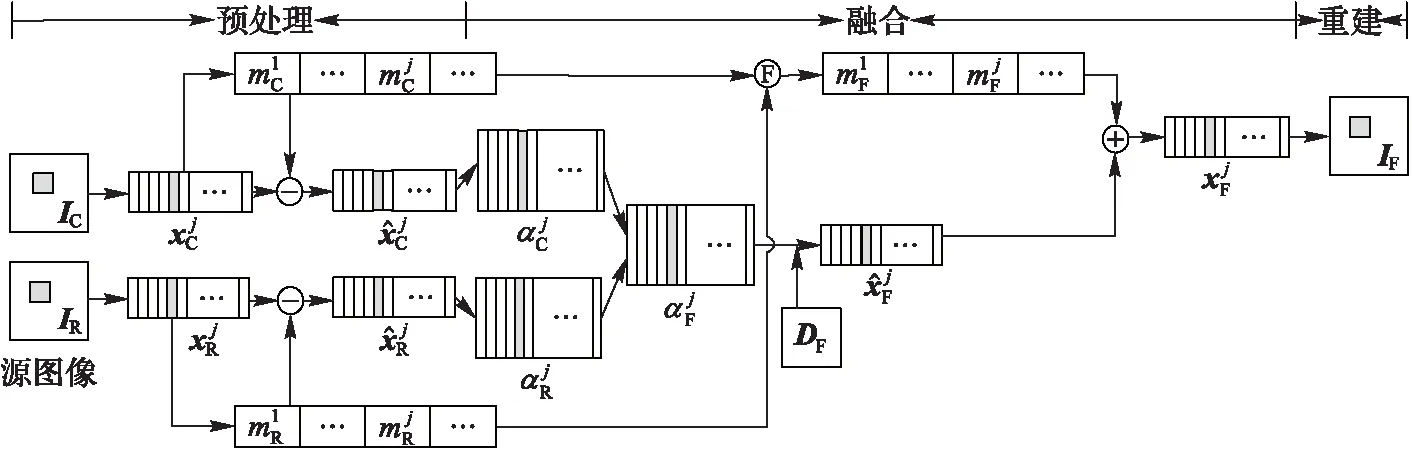
图4 脑部CT/MR图像融合
4 实验结果与分析
本文的实验环境为:32位Windows7操作系统、MatlabR2013a、Inteli3- 2350 2.3GHz处理器、4GB运行内存。为验证本文方法的有效性,选取三组已经配准的脑部CT/MR图像进行融合,分别为正常脑部CT/MR(图5(a)、(b))、脑萎缩CT/MR(图6(a)、(b))、脑肿瘤CT/MR(图7(a)、(b)),图片大小均为256×256。选取的对比算法有:离散小波变换(DWT)[3]、平稳小波变换(SWT)[4]、非下采样Contourlet变换(NSCT)[7]、传统基于选择最大的稀疏表示方法(SparseRepresentation“choose-Max”-based,SRM)[11]、基于K-SVD的稀疏表示方法(SparseRepresentationbasedonK-SVD,SRK)[12]、基于多尺度字典学习的方法(Multi-scaleDictionaryLearning,MDL)[13]。
基于多尺度变换的方法中,对于DWT和SWT方法,分解水平都设为3,小波基分别设为“db6”和“bior1.1”。NSCT方法使用“9—7”金字塔滤波器和“c—d”方向滤波器,分解水平设为{22,22,23,24}。基于稀疏表示的方法中滑动步长为1,图像块大小均为8×8,字典大小均为64×256,误差ε=0.01,稀疏度τ=6。ICDL方法使用改进的K-SVD算法,执行6个字典更新周期(DictionaryUpdateCycles,DUC)和30次迭代。
由图5~7可以看出,DWT方法的融合图像边缘纹理模糊,图像信息失真且存在块效应;与DWT方法相比,SWT和NSCT方法的融合质量相对较好,图像的亮度、对比度、清晰度有了很大的提升,但仍存在边缘亮度失真,软组织和病灶区域存在伪影的问题;SRM和SRK方法较基于多尺度变换的方法,图像的骨组织和软组织更加清晰,伪影也有所减少,能很好地识别病灶区域;MDL方法与SRM和SRK方法相比,能保留更多的细节信息,图像质量取得进一步的改善,但仍有部分伪影存在;本文提出的ICDL方法在图像的亮度、对比度、清晰度和细节的保持度上都优于其他方法,融合图像没有伪影,骨组织、软组织和病灶区域显示清晰,有助于医生诊断。

图5 正常脑部的CT/MR融合结果

图6 脑萎缩的CT/MR融合结果

图7 脑肿瘤的CT/MR融合结果
为进一步验证本文方法的有效性,使用互信息(MutualInformation,MI)[23]、基于梯度QAB/F[24]、基于相位一致Qp[25]和基于通用图像质量指标Qw[26]来对融合图像进行客观评价。MI反映融合图像从源图像提取的信息量的多少,提取的信息量越多则融合图像的质量越好;QAB/F反映融合图像对源图像边缘特性的保留情况,取值范围在[0,1],越接近1表示融合图像的边缘越清晰;Qp反映融合图像多种类型的显著特征,如边缘和角点等;Qw反映融合图像在系数相关性、光照和对比度方面与源图像的关联,符合人类视觉系统的特点。
表1~3为三组实验条件下不同融合方法的客观评价指标。

表1 正常脑部CT/MR融合结果性能比较

表2 脑萎缩CT/MR融合结果性能比较

表3 脑肿瘤CT/MR融合结果性能比较
从表1~3可以看出,DWT方法在MI、QAB/F、Qp和Qw四项指标上均不理想,主要是因为离散小波变换具有平移变化性、走样和缺乏方向性等缺陷;SWT和NSCT方法在上述四项指标上均明显优于DWT方法是由于它们具有平移不变性;SRM、SRK和MDL方法在MI指标上优于三层分解水平的多尺度变换的方法,而在其他三项指标上存在一些低于多尺度变换方法的情况,这可能是由于字典的表示能力不足以提取足够的细节信息和l1范数取极大的融合规则导致的图像的灰度不连续效应;经计算,本文提出的ICDL方法的MI、QAB/F、Qp和Qw四项指标在上述三组实验条件下的均值分别为4.113 3、0.713 1、0.463 6和0.762 5。与其他几种方法相比:本文提出的ICDL方法在MI指标上的值最大,表明该方法的融合图像从源图像提取的信息最丰富;同时在QAB/F、Qp和Qw三项指标上对应的值也最大,表明ICDL方法对图像误配准处理得较好,图像融合质量较高,其主客观评价一致。

5 结语
针对目前基于字典学习的多模态脑部医学图像融合中,使用单字典难以得到精确的稀疏表示进而影响脑部医学图像融合的质量,以及字典训练时间过长的问题,提出了一种改进耦合字典学习的脑部CT/MR图像融合方法。该方法分别对正常脑部、脑萎缩和脑肿瘤三组脑部医学图像进行了多次实验,结果表明本文提出的ICDL方法与基于多尺度变换的方法、传统基于选择最大的稀疏表示方法、基于K-SVD的稀疏表示方法以及多尺度字典学习的方法相比,不仅提高了脑部医学图像融合的质量,而且有效降低了字典训练的时间,能为临床医疗诊断提供有效帮助。但仍存在以下需要进一步研究的问题:
1)本文提出的融合方法在空间域中使用滑窗技术易使源图像的细节被模糊。因此,进一步研究适用于稀疏表示方法的新的图像融合规则是下一步的工作重点。
2)本文是在已配准的脑部医学图像的基础上进行的融合研究,对未精确配准的脑部医学图像进行有针对性的图像融合的方法也需要进一步的研究。
3)本文主要实现了脑部CT和MR医学图像的高质量融合,但如何对脑部解剖图像和功能图像如MR与正电子发射断层成像(PositronEmissionTomography,PET)、MR与单光子发射计算机断层成像(SinglePhotonEmissionComputedTomography,SPECT)等进行高质量融合,也将是下一步继续研究的内容。
)
[1]BHAVANAV.Multi-modalitymedicalimagefusion—asurvey[C]//Proceedingsofthe2015InternationalJournalofEngineeringResearchandTechnology.Bangalore,India:EsrsaPublication, 2015: 778-781.
[2] 李超,李光耀,谭云兰,等.基于非下采样Contourlet变换和区域特征的医学图像融合[J].计算机应用,2013,33(6):1727-1731.(LIC,LIGY,TANYL,etal.Medicalimagefusionofnonsubsampledcontourlettransformandregionalfeature[J].JournalofComputerApplications, 2013, 33(6): 1727-1731.)
[3]PAJARESG,DELACRUZJM.Awavelet-basedimagefusiontutorial[J].PatternRecognition, 2004, 37(9): 1855-1872.
[4]LIST,KWOKJT,WANGYN.UsingthediscretewaveletframetransformtomergeLandsatTMandSPOTpanchromaticimages[J].InformationFusion, 2002, 3(1): 17-23.
[5]LEWISJJ,O’CALLAGHANRJ,NIKOLOVSG,etal.Pixel-andregion-basedimagefusionwithcomplexwavelets[J].InformationFusion, 2007, 8(2): 119-130.
[6]BURTPJ,ADELSONEH.TheLaplacianpyramidasacompactimagecode[J].IEEETransactionsonCommunications, 1983, 31(4): 532-540.
[7]ZHANGQ,GUOBL.Multifocusimagefusionusingthenonsubsampledcontourlettransform[J].SignalProcessing, 2009, 89(7): 1334-1346.
[8]DONOHODL.Compressedsensing[J].IEEETransactionsonInformationTheory, 2006, 52(4): 1289-1306.
[9]YANGB,LIST.Pixel-levelimagefusionwithsimultaneousorthogonalmatchingpursuit[J].InformationFusion, 2012, 13(1): 10-19.
[10]LIUY,WANGZF.Simultaneousimagefusionanddenoisingwithadaptivesparserepresentation[J].IETImageProcessing, 2015, 9(5): 347-357.
[11]YANGB,LIST.Multifocusimagefusionandrestorationwithsparserepresentation[J].IEEETransactionsonInstrumentation&Measurement, 2010, 59(4): 884-892.
[12]AHARONM,ELADM,BRUCKSTEINA.K-SVD:analgorithmfordesigningovercompletedictionariesforsparserepresentation[J].IEEETransactionsonSignalProcessing, 2006, 54(11): 4311-4322.
[13]OPHIRB,LUSTIGM,ELADM.Multi-scaledictionarylearningusingwavelets[J].IEEEJournalofSelectedTopicsinSignalProcessing, 2011, 5(5): 1014-1024.
[14]YUNN,QIUTS,BIF,etal.Imagefeaturesextractionandfusionbasedonjointsparserepresentation[J].IEEEJournalofSelectedTopicsinSignalProcessing, 2011, 5(5): 1074-1082.
[15] 赵井坤,周颖玥,林茂松.基于稀疏表示与非局部相似的图像去噪算法[J].计算机应用,2016,36(2):551-555.(ZHAOJK,ZHOUYY,LINMS.Imagedenoisingalgorithmbasedonsparserepresentationandnonlocalsimilarity[J].JournalofComputerApplications, 2016, 36(2): 551-555.)
[16]ENGANK,AASESO,HAKONHJ.Methodofoptimaldirectionsforframedesign[C]//Proceedingsofthe1999IEEEInternationalConferenceonAcoustics,Speech,andSignalProcessing.Piscataway,NJ:IEEE, 1999: 2443-2446.
[17]JOHNSONKA,BECKERJA.Thewholebrainatlas[EB/OL]. [2016- 10- 09].http://www.med.harvard.edu/aanlib/home.html.
[18]YANGJC,WRIGHTJ,HUANGTS,etal.Imagesuper-resolutionviasparserepresentation[J].IEEETransactionsonImageProcessing, 2010, 19(11): 2861-2873.
[19] YANG J C, WANG Z, LIN Z, et al. Coupled dictionary training for image super-resolution [J]. IEEE Transactions on Image Processing, 2012, 21(8): 3467-3478.
[20] SMITH L N, ELAD M. Improving dictionary learning: multiple dictionary updates and coefficient reuse [J]. IEEE Signal Processing Letters, 2013, 20(1): 79-82.
[21] 练秋生,石保顺,陈书贞.字典学习模型、算法及其应用研究进展[J].自动化学报,2015,41(2):240-260.(LIAN Q S, SHI B S, CHEN S Z. Research advances on dictionary learning models, algorithms and applications [J]. Acta Automatica Sinica, 2015, 41(2): 240- 260.)
[22] CVEJIC N, CANAGARAJAH C N, BULL D R. Image fusion metric based on mutual information and Tsallis entropy [J]. Electronics Letters, 2006, 42(11): 626-627.
[23] QU G H, ZHANG D L, YAN P F. Information measure for performance of image fusion [J]. Electronics Letters, 2002, 38(7): 313-315.
[24] XYDEAS C S, PETROVIC V. Objective image fusion performance measure [J]. Military Technical Courier, 2000, 36(4): 308-309.
[25] ZHAO J Y, LAGANIERE R, LIU Z. Performance assessment of combinative pixel-level image fusion based on an absolute feature measurement [J]. International Journal of Innovative Computing Information & Control Ijicic, 2006, 3(6): 1433-1447.
[26] PIELLA G, HEIJMANS H. A new quality metric for image fusion [C]// ICIP 2003: Proceedings of the 2003 International Conference on Image Processing. Washington, DC: IEEE Computer Society, 2003: 173-176.
This work is partially supported by the Natural Science Foundation of Shanxi Province (2015011045).
DONG Xia, born in 1992, M. S. candidate. Her research interests include medical image fusion, machine learning.
WANG Lifang, born in 1977, Ph. D., associate professor. Her research interests include machine vision, big data processing, medical image processing.
QIN Pinle, born in 1978, Ph. D., associate professor. His research interests include machine vision, big data processing, 3D reconstruction.
GAO Yuan, born in 1972, M. S., associate professor. Her research interests include big data processing, medical image processing,3D reconstruction.
CT/MR brain image fusion method via improved coupled dictionary learning
DONG Xia, WANG Lifang*, QIN Pinle, GAO Yuan
(SchoolofComputerScienceandControlEngineering,NorthUniversityofChina,TaiyuanShanxi030051,China)
The dictionary training process is time-consuming, and it is difficult to obtain accurate sparse representation by using a single dictionary to express brain medical images currently, which leads to the inefficiency of image fusion. In order to solve the problems, a Computed Tomography (CT)/ Magnetic Resonance (MR) brain image fusion method via improved coupled dictionary learning was proposed. Firstly, the CT and MR images were regarded as the training set, and the coupled CT and MR dictionary were obtained through joint dictionary training based on improved K-means-based Singular Value Decomposition (K-SVD) algorithm respectively. The atoms in CT and MR dictionary were regarded as the features of training images, and the feature indicators of the dictionary atoms were calculated by the information entropy. Then, the atoms with the smaller difference feature indicators were regarded as the common features, the rest of the atoms were considered as the innovative features. A fusion dictionary was obtained by using the rule of “mean” and “choose-max” to fuse the common features and innovative features of the CT and MR dictionary separately. Further more, the registered source images were compiled into column vectors and subtracted the mean value. The accurate sparse representation coefficients were computed by the Coefficient Reuse Orthogonal Matching Pursuit (CoefROMP) algorithm under the effect of the fusion dictionary, the sparse representation coefficients and mean vector were fused by the rule of “2-norm max” and “weighted average” separately. Finally, the fusion image was obtained via reconstruction. The experimental results show that, compared with three methods based on multi-scale transform and three methods based on sparse representation, the image visual quality fused by the proposed method outperforms on the brightness, sharpness and contrast, the mean value of the objective parameters such as mutual information, the gradient based, the phase congruency based and the universal image quality indexes under three groups of experimental conditions are 4.113 3, 0.713 1, 0.463 6 and 0.762 5 respectively, the average time in the dictionary learning phase under 10 experimental conditions is 5.96 min. The proposed method can be used for clinical diagnosis and assistant treatment.
medical image fusion; K-means-based Singular Value Decomposition (K-SVD); Coefficient Reuse Orthogonal Matching Pursuit (CoefROMP); sparse representation; dictionary training
2016- 11- 18;
2017- 02- 03。 基金项目:山西省自然科学基金资助项目(2015011045)。
董侠(1992—),女,山西临汾人,硕士研究生,主要研究方向:医学图像融合、机器学习; 王丽芳(1977—),女,山西长治人,副教授,博士,主要研究方向:机器视觉、大数据处理、医学图像处理; 秦品乐(1978—),男,山西长治人,副教授,博士,主要研究方向:机器视觉、大数据处理、三维重建; 高媛(1972—),女,山西太原人,副教授,硕士,主要研究方向:大数据处理、医学图像处理、三维重建。
1001- 9081(2017)06- 1722- 06
10.11772/j.issn.1001- 9081.2017.06.1722
TP
A
猜你喜欢
数学物理学报(2022年2期)2022-04-26
电子制作(2019年16期)2019-09-27
健康大视野(2019年14期)2019-07-19
小学阅读指南·低年级版(2019年11期)2019-07-01
小天使·一年级语数英综合(2017年11期)2017-12-05
家教世界·创新阅读(2017年7期)2017-08-09
奥秘(2016年6期)2016-07-30
读者(2016年14期)2016-06-29
分忧(2016年3期)2016-05-05
中国惯性技术学报(2015年1期)2015-12-19
