
基于机器学习的中医治疗肝硬化组方规律研究*
2017-08-31 12:16裴卫吴辉坤李晓东解丹
世界科学技术-中医药现代化 2017年6期
裴卫,吴辉坤,李晓东,解丹**
基于机器学习的中医治疗肝硬化组方规律研究*
裴卫1,吴辉坤2,李晓东2,解丹1**
(1.湖北中医药大学信息工程学院武汉430065;2.湖北省中医院肝病研究所武汉430061)
目的:运用机器学习技术对中医治疗肝病处方中组方规律进行分析,为肝病临床用药以及新药研发提供参考依据。方法:针对某三甲中医院肝病科近2年肝病治疗处方数据,首先运用复杂网络找出药物之间的关联结构,再运用关联规则、聚类分析等无监督机器学习方法,对其进行比较分析,最终得出中医治肝硬化的组方规律。结果:对589首处方,共计257味中药,高频药物组合包括频繁二项集12项、三项集15项以及四项集14项;支持信≥10%、置信度≥90%的关联规则包括“陈皮,神曲→白术”,“猪苓,陈皮→白术”等34条;通过聚类分析,发现中药主要以5种特征进行归类。机器学习结果与构建的复杂网络结构完全一致。结论:运用机器学习方法进行中医处方数据分析,并与复杂网络方法相结合,以探究中医治疗肝硬化组方规律的方法确实可行,可为临床治疗肝硬化和找寻新方提供线索。
机器学习肝硬化中药处方组方规律
肝硬化是一种常见的由不同病因引起的、以肝组织弥漫性纤维化、假小叶和再生结节为组织学特征的慢性进行性肝病[1]。临床上起病隐匿,病程发展缓慢,早期无明显症状,后期因肝脏变形硬化,血液循环途径会有显著改变,常见并发症有上消化道出血、肝性脑病、继发感染等[2,3]。中医处方是中医临床治疗经验的有效载体,中医治疗处方用药规律研究是传承中医防治疾病方法的核心[4]。中医处方是中医治疗疾病的图谱,通过对处方中的组方规律进行分析,将对中医药学术继承与创新具有重要意义[5]。而当前对中医处方进行组方规律研究通常采用数据挖掘方法,从数据分析的角度来看,绝大多数数据挖掘技术都来自机器学习领域[6]。通过文献研究发现,目前在中医治疗肝硬化上处方规律研究中用到的算法多为频数统计、关联规则、因子分析、聚类以及复杂网络,其中关联规则、聚类属于机器学习中的无监督学习方法。以往研究人员多使用一种或多种算法进行研究,尚没有从某一方法入手,再通过机器学习从而提升获取隐含知识率的探索。本文尝试从复杂网络入手,首先得到药物之间的关联结构图,再使用无监督的机器学习方法进一步分析,包括关联规则以及聚类,通过调节权重值进行反复实验,将学习结果与复杂网络结构进行互证。通过机器学习,可以更加确切的反映药物之间的联系,挖掘出处方之间的内在联系,本文方法可为中医治疗肝硬化和开发新方提供数据支撑和理论参考。
1 相关研究
从20世纪90年代至今,中医治疗肝硬化组方规律研究已有一定基础。程远[7]将某“三甲”医院肝硬化药物治疗的数据,按照药物效果分类,通过频数统计、聚类分析的方法找到高频药物汇总,利用Apriori算法进行分析,发现数据分析矩阵和Apriori算法建模所得结果一致。严明[8]收集周仲瑛教授诊治肝硬化病例数据,采用频数统计法和因子分析法,对证候信息辨识、病机证素特征和选方用药经验三个方面进行挖掘,提炼周教授对肝硬化的治疗经验、思路和方法。孙继佳[9]对肝硬化临床患者的相关信息,采用粗糙集方法建立证候决策信息表,提取与肝硬化各证型有密切关联的重要症状、体征,利用这些提取的症状组合作为支持向量机的输入,从支持向量机分类结果得到相应的证候,认为基于粗糙集与支持向量机的中医辨证具有比较高的可靠性。陈明[10]通过对患者进行关联分析,找出符合最小支持度和最小置信度的中医证候,认为关联规则是广泛运用的数据挖掘工具之一。孙洁[11]搜集整理名老中医治疗肝硬化腹水的医案,运用频数分析法、关联规则分析法及聚类分析法,对证候分布、病机证素特征、用药规律三大方面的内容进行挖掘,归纳总结名老中医对本病的治疗用药经验及学术思想。吴辉坤[12]对肝硬化门诊患者临床资料进行处理,利用数据分类、关联、聚类等大数据分析方法对数据进行分析。阎小燕[13]收集尹常健教授治疗肝硬化门诊处方,使用中医传承辅助系统,发现利用文本挖掘、关联规则等数据挖掘方法较好的体现了尹常健教授治疗肝硬化的用药规律。刘嘉辉[14]研究国医大师治疗肝硬化的用药规律,将搜集到的63个医案中的方药信息提取,对药物的功效、性、味、归经进行描述性统计和对高频药物进行聚类分析和关联分析。
综上,目前大部分肝硬化方面的组方规律研究多从关联规则、分类、聚类三类数据挖掘方法入手,探寻证候信息、病机证素以及选方用药经验。尚没有从机器学习角度,将复杂网络与机器学习相结合,通过不断调整参数,进一步探寻组方药物间关联度的研究,因此本文工作具有一定理论创新性。
2 数据准备
2.1 数据来源
以某三甲中医院2015年7月至2016年8月间,参照2011年8月中国中西医结合学会消化系统疾病专业委员会制定的《肝硬化中西医结合诊疗共识》明确诊断为乙肝肝硬化的700例门诊记录[15]。本文用到的字段包括患者诊疗记录中的患者基本信息(门诊号、西医诊断、性别、年龄)、检验(首次检查总胆红素、首次检查凝血酶原时间、首次检查白蛋白、末次检查总胆红素、末次检查凝血酶原时间、末次检查白蛋白等)以及医嘱(即处方)信息。
2.2 纳入标准
依据肝功能Child-Pugh分级标准,计算患者的首次来院检验的得分与经过一段时间诊疗后最近一次来院检验的得分,筛选诊疗前后评分下降的案例作为本文的有效数据[16]。肝硬化对Child-Pugh分值变化敏感度低,出现评分下降的情况可认为该案例在一定概率下是治疗有效的。
2.3 排除标准
文献数据的排除标准包括:①患者门诊号缺失;②中药处方信息缺失;③缺少Child-Pugh分级标准所需信息:肝性脑病、腹水、血清胆红素、血清白蛋白和凝血酶原时间。
2.4 纳入情况
依据纳入标准和排除标准,筛选所有治疗有效案例,从700例原始案例中最终获得620份有效案例纳入后续分析。
3 数据预处理和方法
3.1 数据预处理
本文数据预处理工作主要包括检验数据修正与有效记录的筛选、多处方识别与处方长文本分割以及药物名称的规范化。所有工作均在中医肝病临床医生指导下,采用python编程方式完成,具体工作如下:
3.1.1 检验数据修正与有效记录的筛选
对原始数据中的检验数据进行修正,主要包括缺失检验数据的填补以及极端值形成原因的判定与修正。在完成原始数据检验值的修正后,再依据肝功能Child-Pugh分级标准进行计算。
3.1.2 多处方识别与处方长文本分割
对多处方现象进行归并,通过识别数值与逗号对原始处方进行分割,最终获得589首处方数据。如:白茅根30 g,泽泻15 g,车前草15 g,朱云苓15 g,识别后为白茅根,30;泽泻,15;车前草,15;朱云苓,15。
3.1.3 药物名称的规范化
本文处方数据共包含407种中药名称,规范化的中药名称219种、不规范的中药名称188种,不规范中药名称中包含中药别名97种、中药简称3种以及炮制中药88种。对未规范中药的名称进行规范化预处理,并参照《中药编码规则集编码》(中华人民共和国国家标准[GB/T 31774-2015])与《中国药典》(2015年版)对预处理后的药物进行严格规范化,最终获得257种标准中药名称。
3.2 分析方法
通过数据预处理之后,进行数据分析。本文采用的分析方法主要有二大类,首先是复杂网络,其次是无监督的机器学习方法:关联规则和聚类。由于本文的数据规模较小,因此不用过多考虑算法的时间损耗,重点关注学习过程(即参数设置)以及产生结果的合理性解释。本文构建复杂网络的思路是将每味中药作为一个节点,两味中药之间有连线是他们同时出现在某一处方中,提取出药物之间的相互关系,并绘制药物关联结构图。机器学习方法中关联规则采用的是经典Apriori算法,根据数据分布情况进行最小支持度和最小置信度的设置,选择最优参数。聚类分析采用的是经典k-means算法,将给定数据集分为K个簇,簇数K由用户设定,每一个簇通过簇中所有点的中心来描述。根据设置不同的簇数和随机种子数以获得最优簇数k,然后得到每一簇的中药组合。在二类方法完成之后,结果可以进行互证。
4 结果
4.1 复杂网络分析结果
复杂网络主要用于体现药物之间的相互关系。为了展现药物之间的关联,将两味中药同时出现的次数除以中药总味数(257味)作为权重。利用Gephi软件,把药物之间的相互关系以图形化的方式展现出来(图1)。
在图1中,每一个实心圆圈就是一个节点,代表一味中药。圆圈的面积越大,说明该节点的度越高,它反映了该节点在网络图中的直接影响力。边的粗细,表示权重大小,它反映了两个节点之间的关系密切程度。图1中A表示权重值>30的药物结构,而B是所有药物之间的关联。从图1-A中可以发现白术、茯苓、甘草、茵陈蒿、丹参和泽泻等6味中药的影响力最高,其次是陈皮、猪苓、神曲、半夏、鸡内金、大腹皮、郁金和枳壳等。
除此之外,本文还尝试使用单处方剂量平均加权方式以及多处方综合剂量加权方式,但得到的结果给临床医生审核后发现没有实际意义,可见在中药处方中仅靠剂量方式加权意义不大,还需结合中药的四性五味特点来分析,但目前电子病历中普遍缺少中药的君臣佐使信息,无法进行大规模分析。
4.2 无监督机器学习
由于本文数据均为已经确诊为肝硬化的患者,不具有诊断分类价值,因此采用无监督机器学习方法,从现有数据中找寻组方规律,主要对处方中的中药进行分类统计,包括单味中药、药物组合、药物分类等,分别采用了频次统计、关联规则以及聚类方法。
首先利用Excel对纳入的589首处方,257种中药进行单味中药的频次统计,得到治疗肝硬化处方中,中药使用频次在40次以上共计50味中药列表(表1)。
由表1可知,出现次数大于200的高频中药有:白术、茯苓、甘草、茵陈蒿、丹参、泽泻、猪苓和陈皮。由于频次统计与复杂网络的原理相同,因此与复杂网络结果完全一致。
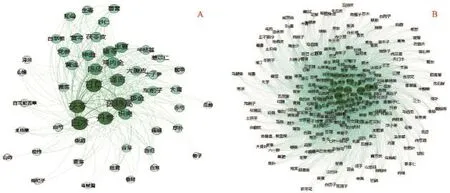
图1 中医治疗肝硬化处方的药物复杂网络结构图
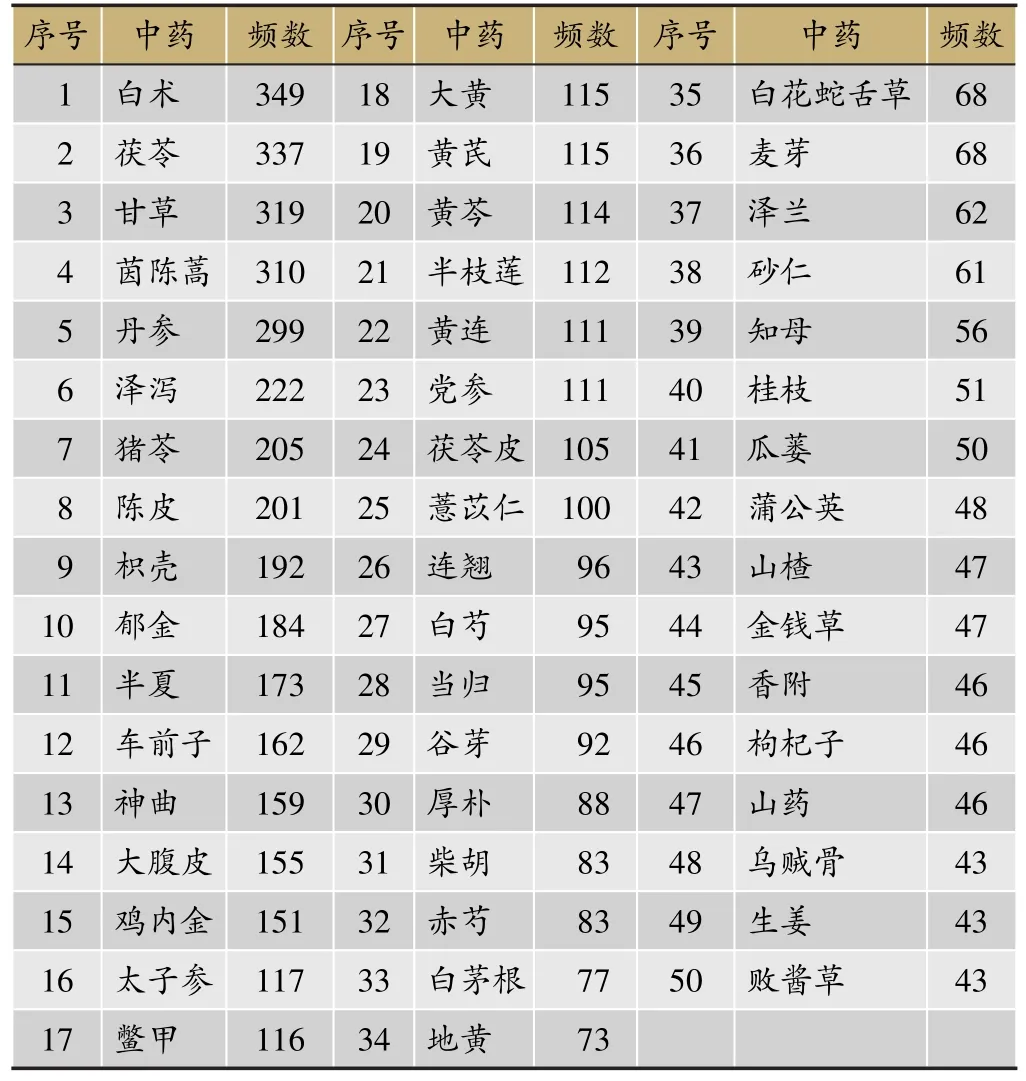
表1 治疗肝硬化处方中用药频次>40的中药
4.2.1 关联分析结果
用Weka中内嵌的Apriori算法,对肝硬化处方中药数据进行关联分析。将所有257味中药进行关联规则分析。在设置最小支持度和最小置信度参数时,分别从10%-30%和75%-95%,每隔5%进行一次尝试。最后发现在设置最小支持度为10%、最小置信度为90%时获得的频繁项集结果最为合理(表2)。
表2中共得到频繁二项集12项,频繁三项集15项以及频繁四项集14项。在设置最小支持度为10%、最小置信度为90%时,得到的关联规则结果见表3。以第一行为例,“陈皮,神曲->白术”是一条药物组合规则,“陈皮,神曲,白术”同时出现的概率为10%,当出现“陈皮和神曲”时100%会出现“白术”,这是一条强规则。
表3反映了多味药物之间的组合关系,为了更形象地反映出任意两味中药的关联程度大小,对其进行可视化。用每个节点表示一味中药,节点大小表示该中药出现的次数,连接两个节点的弧线粗细程度表示关联次数的多少。利用Gephi工具绘制关联规则结果(图1)。
表3中一共涉及到的中药有14味,分别是:陈皮,猪苓,泽泻,甘草,神曲,茯苓,白术,茯苓皮,党参,车前子,鸡内金,半夏,丹参和郁金。根据表3绘制的关联图2中显示“白术、陈皮、泽泻、甘草”的出现次数最高,而“白术,陈皮”、“白术,泽泻”、“白术,甘草”,“猪苓,泽泻”的关联度最高。此结果不仅体现了前面复杂网络与频次统计的结果,更进一步说明了药物之间的组合规律。
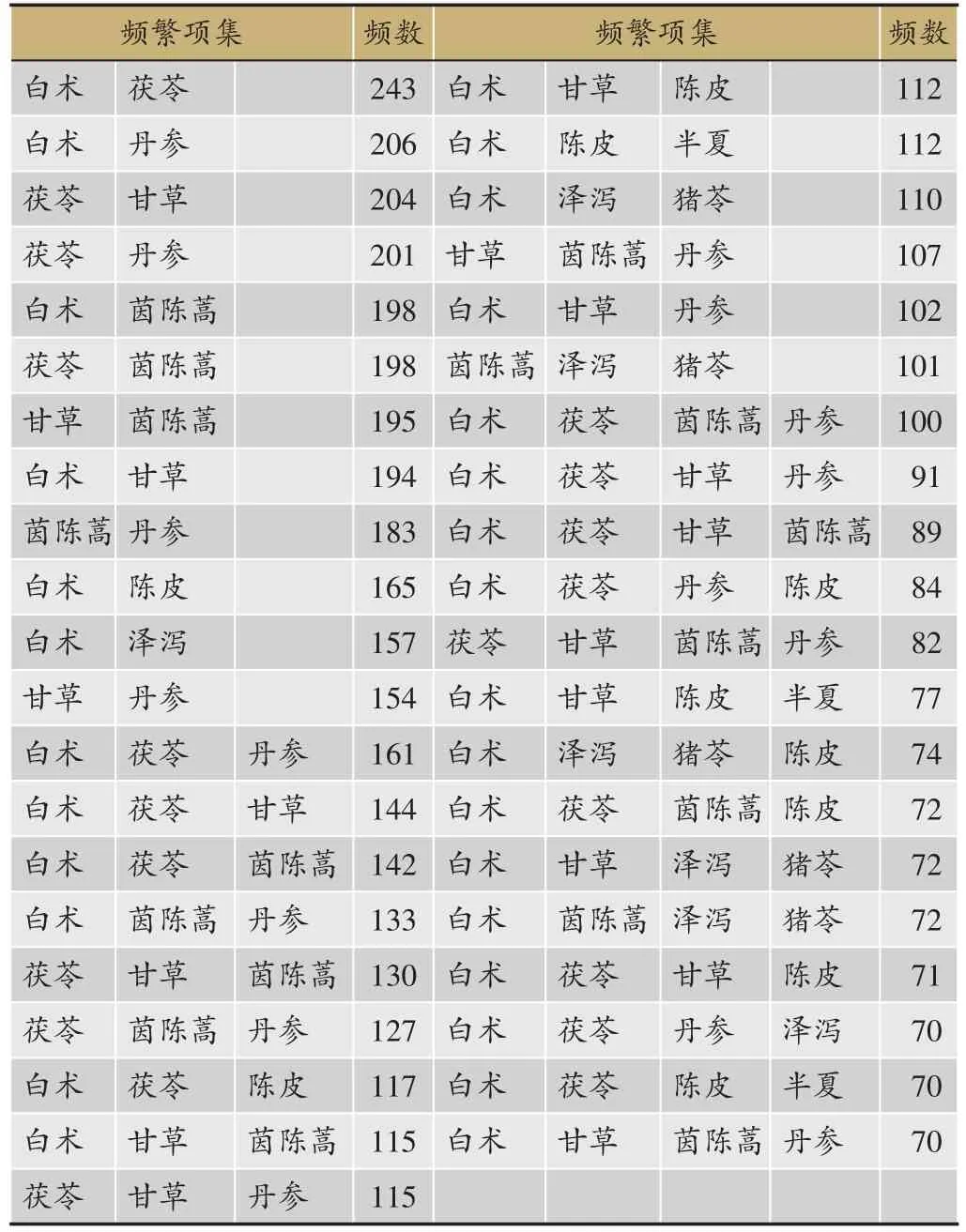
表2 频繁项集(最小支持度=10%,最小置信度=90%)
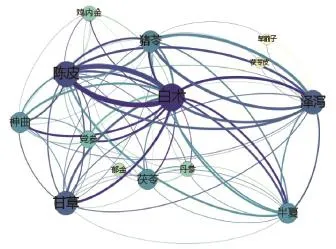
图2 药物关联结果图
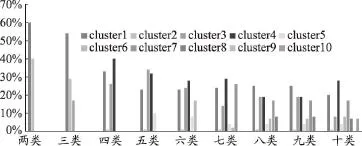
图3 聚类类别对照图
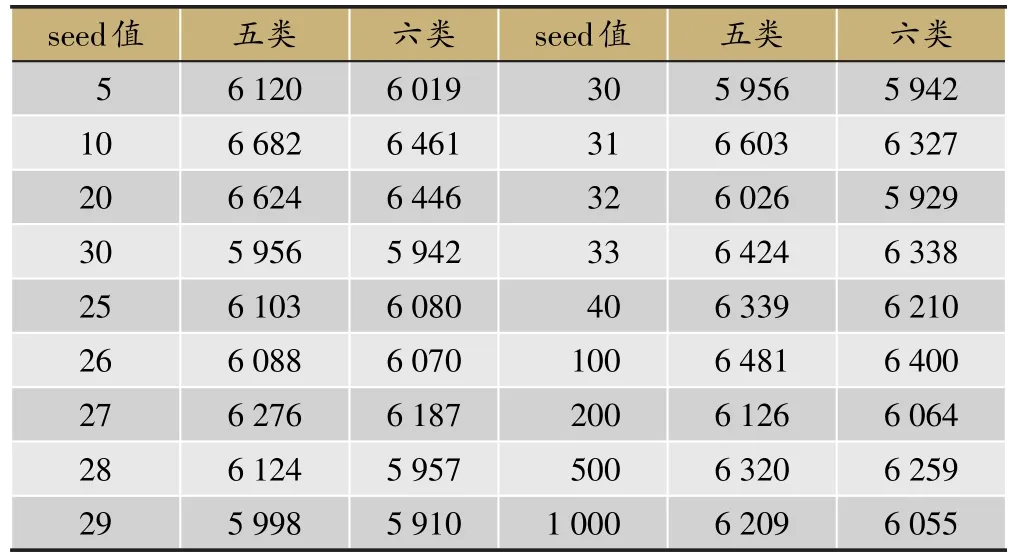
表4 随机种子值选择对照表
4.2.2 聚类分析结果
聚类分析试图将相似对象归于同一簇,将不相似的对象归到不同簇,这里所谓的相似取决于所选择的相似度计算方法。本文认为同时出现次数越多,其相似度越高。运用Weka软件,尝试使用了多种算法,包括k-means、熵聚类以及层次聚类,最后发现k-means算法的结果最符合临床医生的经验,因此选择kmeans算法进行聚类簇数k的设定(图3)。
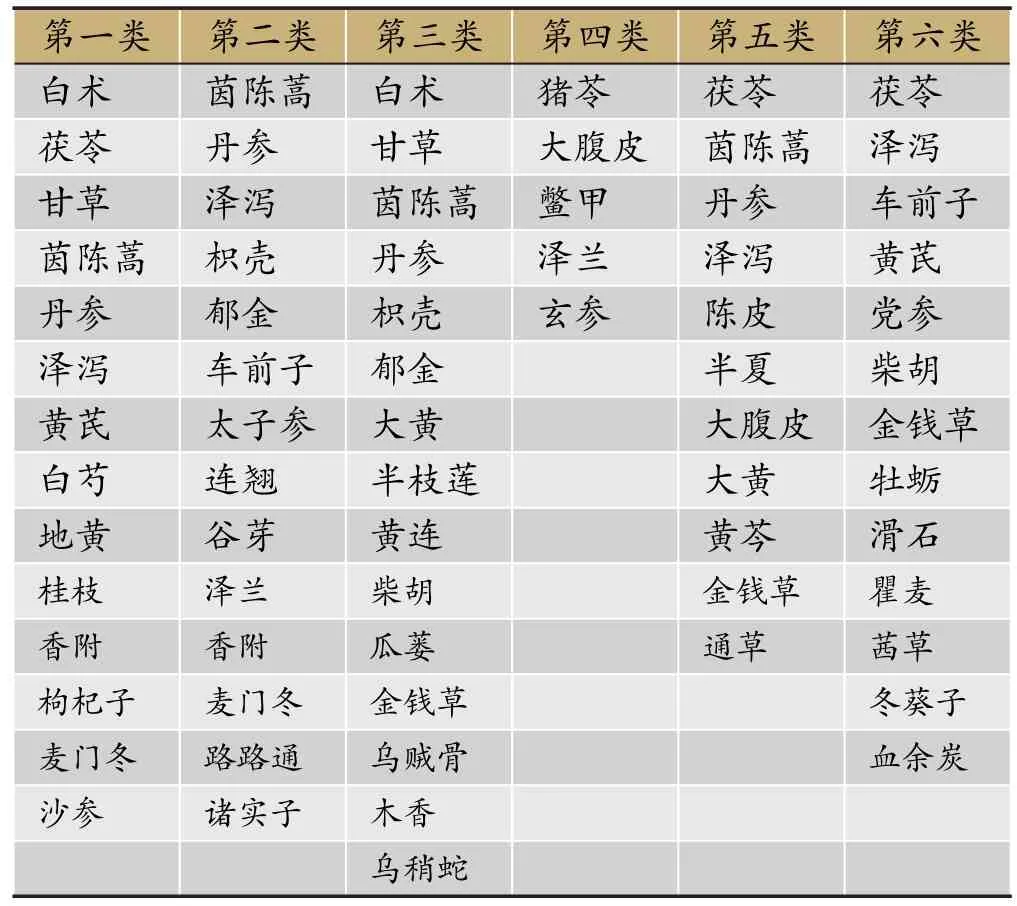
表5 聚类分析结果
从图2中可以发现,当k=5或者k=6时分类效果较好,各类区别度较高。因此对于聚类簇数K分别设置为5和6时,进行随机种子值的确定(表4)。
衡量聚类好坏的参数为“分类的平方误差和”,此参数越小,表明聚类效果越好。由表4可知,当聚类簇数k=6,随机种子值seed=29时效果较好。以该参数进行聚类分析,得到治疗肝硬化处方中药的聚类分析结果(表5)。
表5中有6个分类,但其中第四类的药物较少,主要体现了5类特征。在临床医生指导下,这一结果基本符合临床用药规律,特别是每一类的前几味中药,均为高频药物,与复杂网络结果相吻合。
5 总结
本文从复杂网络出发,通过机器学习方法,一方面可以用于互证二种方法的结果,另外复杂网络结果有助于进行机器学习算法的参数调整,让计算机可以通过不断学习来找到接近目标函数的假设值(即参数)。本文的分析结果表明,机器学习方法与复杂网络结果完全吻合。今后可以使用机器学习与复杂网络等其它方法相结合的方式进行组方规律研究,对临床有较强实用价值。虽然,基于机器学习的中医处方规律研究正在兴起,但还存在许多问题需要继续探索:
5.1 提高处方数据量
本文涉及中医处方均来自于某中医院乙肝肝硬化中医门诊案例,中药种类有限,在未来研究中应纳入更多临床处方。伴随着中医临床处方的动态增长性,需结合新增处方对模型进行定期训练与评价。
5.2 提高数据质量
本文在数据预处理中发现普遍存在检验数据不全或缺失、中药使用不规范现象,对电子病历的数据质量提了较高要求。原始数据采集时需进一步加强数据质控管理,避免数据缺失、中药名称不规范等现象发生。
5.3 改进机器学习算法
现阶段中医处方研究多从不同角度使用不同的机器学习算法进行建模分析,算法之间并不存在交叉,而结合多种算法构建复合算法,有利于从多种角度探索处方数据中药物的配伍规律,实现结果多元化。例如:使用时间序列算法,结合同一患者不同时段的检验数据对患者阶段性医嘱进行区分加权;使用聚类算法,结合诊疗记录中患者的症状对患者分类,根据不同类别患者病情的严重程度对患者的诊疗记录进行区分加权;使用神经网络算法训练药物名称的词向量,从而计算两个处方的相似度等。建立多种算法集成的机器学习模型有助于从多角度探索中医处方数据,提高模型对真实世界的拟合度。
1汪敬富.活血利湿补益肝肾法治疗肝硬化的临床及实验研究.南京:南京中医药大学博士学位论文,2009.
2王思颖.肝炎肝硬化脉象、脉图的特征及其与症状、实验室指标的相关性研究.北京:北京中医药大学硕士学位论文,2013.
3边静.细述肝硬化患者的早期症状与临床治疗.中国继续医学教育, 2015,7(14):54-55.
4唐仕欢,杨洪军.中医组方用药规律研究进展述评.中国实验方剂学杂志,2013,19(5):359-363.
5孙敬昌,王燕平.基于中医传承辅助系统的治疗水肿方剂用药规律分析.中国实验方剂学杂志,2012,18(10):11-16.
6周志华.机器学习与数据挖掘.南京大学计算机软件新技术国家重点实验室.
7程远,曾照芳.关联规则挖掘在药物治疗肝硬化中的应用研究.激光杂志,2010,31(5):72-74.
8严明.基于病案数据挖掘分析的周仲瑛教授辨治肝硬化临床经验研究.南京:南京中医药大学硕士学位论文,2013.
9孙继佳,苏式兵,陆奕宇,等.基于粗糙集与支持向量机的中医辨证数据挖掘方法研究.数理医药学杂志,2010,23(3):261-265.
10陈明,杨慧芳,余蕾.基于关联规则的肝硬变辨证数据挖掘研究.河南中医,2009,29(3):258-260.
11孙洁.基于数据挖掘的名老中医治疗肝硬化腹水临床经验研究.南京:南京中医药大学硕士学位论文,2016.
12吴辉坤,李晓东,谢丹,等.基于数据挖掘从痰毒瘀虚治疗肝硬化的用药规律研究:第七次全国中西医结合传染病学术会议,中国山东青岛,2016.
13阎小燕,安勇,邵建珍.基于中医传承辅助平台的尹常健教授治疗肝硬化用药规律分析.中国实验方剂学杂志,2015,21(20):225-230.
14刘嘉辉,吕东勇,何洁茹,等.基于数据挖掘对国医大师治疗肝硬化用药规律研究.中华中医药杂志,2015,30(12):4328-4331.
15刘成海,危北海,姚树坤.肝硬化中西医结合诊疗共识.中国中西医结合消化杂志,2011,19(4):277-279.
16卫生部.原发性肝癌诊治指南(肝功能Child-Pugh分级标准),2011.
Study on Prescription Regularity of Traditional Chinese Medicine in Treating Cirrhosis Based on Machine Learning
Pei Wei1,Wu Huikun2,Li Xiaodong2,Xie Dan1
(1.College of Information Engineering,Hubei University of Chinese Medicine,Wuhan 430065,China; 2.Hepatology Institute,Hubei Province Chinese Medicine Hospital,Wuhan 430061,China)
This study was aimed to use machine learning techniques for the prescription regularity of traditional Chinese medicine(TCM)in the treatment of liver diseases in order to provide a reference basis for clinical treatment as well as research and development of new drugs.According to the prescription data of liver disease treatment of the last two years in the hepatology department of a triple-A TCM hospital,the related structure between drugs was firstly found by the complex structure of drugs.And then,association rule,cluster analysis and other unsupervised machine learning methodswere used.The prescription regularity of TCM in the treatment of cirrhosis was
through the comparison and analysis.The results showed that there were 589 prescriptions with 257 types of Chinese medicine herbs.The high frequency drug combination included 2 items of 12,3 items of 15,4 items of 14;support>10%,confidence>90%of the association rule include“dried tangerine peel,medicated leaven→largehead atractylodes rhizome,”“polyporus umbellatus,dried tangerine peel→largehead atractylodes rhizome”and other 34;through cluster analysis,it showed that Chinese medicine was mainly classified by 5 characteristics.The machine learning result was the same as the constructed complex network.It was concluded that the combination of complex network and machine learning methods in the exploration of prescription regularity of TCM in the treatment of cirrhosis were feasible.It provided clinical treatment of cirrhosis and clues for finding new prescription in the treatment of cirrhosis.
Machine learning,cirrhosis,traditional Chinese medicine prescription,prescription regularity
10.11842/wst.2017.06.010
R256.4
A
(责任编辑:马雅静,责任译审:王晶)
2017-03-20
修回日期:2017-05-20
*老年病中药新产品湖北省协同创新中心项目(201506):湖北省中医老年病数据资源管理平台构建研究,负责人:解丹;国家中医药管理局中医临床研究基地业余建设科研专项课题(JDZX2012051):中医治疗慢性乙型肝炎真实世界效果比较研究,负责人:李晓东。
**通讯作者:解丹,副教授,主要研究方向:医学数据挖掘。
猜你喜欢
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
新世纪智能(数学备考)(2021年9期)2021-11-24
大众投资指南(2021年35期)2021-02-16
当代陕西(2019年15期)2019-09-02
电影(2018年8期)2018-09-21
学苑创造·A版(2018年11期)2018-02-01
电力与能源(2017年6期)2017-05-14
读者(2017年5期)2017-02-15
信息通信技术(2015年6期)2015-12-26
