
基于Dais—CMX模型机的斐波那契数列指令集设计
2017-07-31 11:11高俊杰
计算机教育 2017年7期
高俊杰
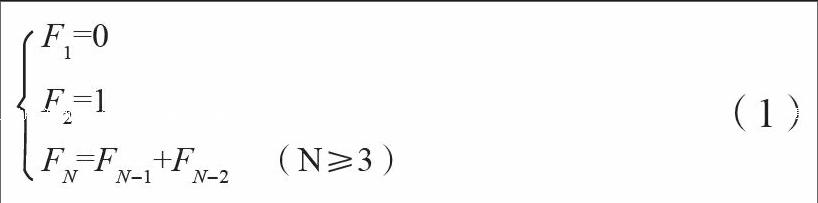

摘 要:在现代计算机系统中,利用高级语言可设计出多种计算斐波那契数列的算法,但需要众多指令的支持。为了简化斐波那契数列的计算过程,提高计算速度,文章提出在Dais-CMX模型机上,基于硬件底层微程序设计,利用寄存器寻址、寄存器间接寻址和指令跳转等硬件技术,设计7条指令即可完成斐波那契数列运算的方法。
关键词:指令集;微程序;斐波那契数列;寻址技术
文章编号:1672-5913(2017)07-0065-04
中图分类号:G642
0 引 言
13世纪,意大利数学家斐波那契在《算盘书》的修订版中加入了一道著名的兔子繁殖问题:假设一对兔子要一个月才能到成熟期,而一对成熟的兔子每月会生一对兔子,那么由一对初生兔子开始,12个月会有多少对兔子呢?从第一个月到第十二个月兔子的对数分别是:2,3,5,8,13,21,34,55,89,144……,这个数列被称为斐波那契数列[1]。
斐波那契数列在数学、物理、化学、生物、计算机科学中都发挥着极为重要的作用。为此,美国数学会从1960年代起出版了《斐波纳契数列》季刊,专门刊载这方面的研究成果。科学家发现,一些植物的花瓣、萼片、果实的数目以及排列方式也与斐波那契数列有着惊人的相似。1992年,两位法国科学家通过对花瓣形成过程的计算机仿真实验,证实了在系统保持最低能量的状态下,花朵会以斐波那契数列长出花瓣[2]。在计算机科学中,斐波那契堆(Fibonacci heap)是最小堆有序树的集合,它和二项式堆有类似的性质,可用于实现合并优先队列。近年来在计算机领域,基于斐波那契数列的研究层出不穷,如基于斐波那契数列的指纹增强方向滤波模板[3]、基于斐波那契数列采样的BP神经网络金融时间序列短期趋势预测[4]等都运用了斐波那契数列的运算。
在现代计算机系统中,利用高级语言可以设计出多种计算斐波那契数列的算法,如递推算法[5]、特征方程求解法[5]、矩阵幂运算加速算法[6]等,但这些基于高级语言的算法,在实现时需要调用众多指令,需要较为庞大的指令系统支持。为了简化斐波那契数列的计算过程,提高运算速度,笔者基于Dais-CMX模型机硬件底层微程序,设计出一个经过简化的计算斐波那契数列的指令集,利用寄存器寻址、寄存器间接寻址、指令的跳转[7]等硬件功能相互组合,融合软件技术中的指针概念,最终实现本设计。斐波那契数列指令集适用于Dais-CMX模型机系统,通过7条指令完成数列的计算,相比于大多数软件算法,在性能上有较大提高。
1 问题描述
斐波那契数列的计算可以通过软件方法或硬件方法进行设计。
1.1 软件设计方法及性能分析
斐波那契数列可以用软件设计方法中的递推法实现。递推法是迭代算法的一种,其基本思想是用若干步可重复的简单运算描述复杂的数学问题,以便于计算机处理。这种方法的求解过程与递推关系的思想完全一致,由边界条件开始往后逐个推算[5]。
斐波那契数列的递推关系:
从递推关系公式(1)可以看出,斐波那契数列第一项为0,第二项为1,其后各项为前两项之和。根据这一条件,可以归纳出该算法的时间复杂度为O(n)。
斐波那契数列伪代码如下:
FUNCTION_FIBONACCI(Fibonacci,n)
step1:Fibonacci[0] = 0
step2:Fibonacci[1] = 1
step3:For i=2 to n
step4: Fibonacci[i]=Fibonacci[i-1]+Fibonacci[i-2]
step5: return
斐波那契数列用C语言编制程序,其代码如下:
#include
int main(){
int Fibonacci[20]={0,1};
int i;
printf("%d %d ",Fibonacci[0],Fibonacci[1]);
for (i=2;i<20;i++){
Fibonacci[i] = Fibonacci[i-1]+Fibonacci[i-2];
printf("%d ",Fibonacci[i]);
}
}
高级语言有着较强的可读性和算法描述能力,与此同时隐藏了许多硬件的实现细节,通过汇编语言可以体现出程序的硬件实现过程。递推法汇编语言部分代码如下:
mov esi,OFFSET array
mov ecx,lengthof array
mov edx,offset prompt
call writestring
mov edx,offset prompt1
mov edi,0
mov [esi],edi
mov eax,[esi]
call writeint
call writestring
mov edi,1
mov [esi + 4],edi
mov eax,[esi + 4]
call writeint
call writestring
sub ecx,2
由匯编语言代码可知,一个采用递推算法的程序在实际运行时至少调用了20次关键指令,因此,斐波那契数列的计算需要进行20多次关键指令的操作才能完成。
1.2 硬件设计分析
基于硬件设计,其可靠性、计算速度都远胜于软件算法。在硬件底层实现斐波那契数列的计算,可以简化计算过程,提高计算速度。为便于设计,我们将寄存器间接寻址作为软件技术中的指针使用。表1对斐波那契数列硬件实现过程进行了描述:①在Step1中,R1和R2理解为两个指针单元;②在Step4中R3送入B,是由于试验机限制,每条指令只能选择一个寄存器,在下一步中完成R2自增,不能再选择R3,所以在这里将计算结果暂存为B。
2 指令集和微指令设计
根据表1中硬件实现过程的描述,设计的指令集见表2,根据每条指令设计出相应的微操作,并写成微指令,再利用微指令组成微程序,最终设计出多条指令与各个微程序相连接,即可完成指令集的设计。
在微程序控制的系统中,CPU设计了一个控制存储器,用于存放各种机器指令对应的微程序段。当CPU执行机器指令时,会在控制存储器里寻找与该机器指令对应的微程序,取出相应的微指令来控制执行各个微操作,从而完成该程序语句的功能[8]。按照Dais-CMX模型机系统建议的微指令格式,参照微指令设计,将每条微指令代码化,译成二进制代码表,并将二进制代码表转换成十六进制格式文件。
1)指令IN1、指令IN2、指令ADD1的微指令设计。
图1描述了IN1、IN2和ADD1指令运行的示意图,表3—表5描述3条指令对应的微指令信息。
2)指令OUT的微指令设计。
在OUT指令中,通过R2寄存器间接寻址,将@R2送入ALU中的A寄存器。
3)指令ADD2的微指令设计。
图2描述了ADD2指令的运行示意图,表7描述ADD2指令对应的微指令信息。
4)指令STA、指令JMP的微指令设计。
图3描述了STA指令的运行示意图,表8和表9描述STA指令和JMP指令对应的微指令信息。
3 实验结果及性能比较
3.1 实验结果
在Dais-CMX模型机上,完成指令和微指令集设计后,启动系统,运行结果如图4所示。从内存中观察到设计的指令集和底层的微指令集,能实现斐波那契数列的运算,并且运算结果完全正确。
3.2 软硬件实现斐波那契数列的性能比较
表10将斐波那契数列实现的两种方法进行了比较,可知硬件实现的性能提高了很多。
4 結 语
通过实验证实,斐波那契数列指令集设计是正确可行的。斐波那契数列指令集设计原理可以移植到嵌入式系统,如基于斐波那契数列的加密设备、指纹识别设备等,结合本硬件算法设计可以加快计算速度,减少内存占用,提高可靠性。
参考文献:
[1] 凌晓牧. 有趣的斐波那契数列[J]. 江苏第二师范学院学报: 自然科学版, 2011(5): 31-33.
[2] Douady S, Couder Y. Phyllotax is as a physical self-organized growth process.[J]. Physical Review Letters, 1992, 68(13): 2098-2101.
[3] 蔡秀梅, 范九伦, 高新波.基于斐波那契数列的指纹增强方向滤波模板[J]. 模式识别与人工智能, 2011, 24(3): 360-367.
[4] 邱紫华, 潘和平. 基于斐波那契数列采样的BP神经网络金融时间序列短期趋势预测[J].管理学家:学术版, 2010(5): 50-60.
[5] 赵秀梅, 赵宗昌. Fibonacci数列的应用研究[J]. 山东建筑大学学报, 2004, 19(2): 73-75.
[6] 陈宏建, 陈崚, 沈洁, 等. 一种改进的矩阵幂运算及其性能分析[J].计算机工程与应用, 2003, 39(33): 61-64.
[7] 唐朔飞. 计算机组成原理[M]. 北京: 高等教育出版社, 2008: 72-103.
[8] 齐学梅. 计算机硬件基础实验教程[M]. 芜湖: 安徽师范大学出版社, 2013: 25-40.
(编辑:孙怡铭)
