
集总动力学模型结合神经网络预测催化裂化产物收率
2017-07-19 13:09:06欧阳福生刘永吉
石油化工 2017年1期
欧阳福生,刘永吉
(华东理工大学 石油加工研究所,上海 200237)
专题报道
集总动力学模型结合神经网络预测催化裂化产物收率
欧阳福生,刘永吉
(华东理工大学 石油加工研究所,上海 200237)
根据催化裂化反应机理和多产异构烷烃的重油催化裂化(MIP)工艺的特点,结合大量的工业数据,开展了MIP工艺过程集总动力学模型与BP神经网络模型相结合提高目标产物预测精度的研究,建立了饱和分、芳香分、胶质+沥青质、柴油、汽油、液化气、干气和焦炭8个集总反应网络,结合龙格库塔法与遗传算法求得该集总模型的47个动力学参数。实验结果表明,所求得的动力学参数能较好地体现催化裂化反应规律;模型对产物分布的模拟计算相对偏差均小于5%,采用14-7-5结构的BP神经网络与集总模型相结合,可进一步提高模型对产物分布的预测精度,为重油催化裂化的模拟优化提供了一个新的方向。
催化裂化;MIP工艺;集总模型;神经网络
催化裂化(FCC)是重质油加工的核心技术之一,是生产汽油、柴油和低碳烯烃的主要手段[1]。为满足汽油质量快速升级和适应重油资源高效利用的要求,国内开发了一系列降低汽油烯烃含量和多产丙烯的催化裂化新工艺,如多产异构烷烃的重油催化裂化(MIP )工艺[2]、两段提升管催化裂化(TSRFCC)工艺[3]、灵活多效催化裂化(FDFCC)工艺[4]等。进一步研究这些工艺过程的动力学模型对指导过程模拟优化具有非常重要的意义。集总方法是研究催化裂化这种复杂反应体系动力学的有效手段[5-6]。针对上述几种新工艺及相关反应机理,先后有学者建立了TSRFCC工艺的6集总模型[7]、FDFCC工艺重油提升管的10集总[8]和12集总模型[9]及MIP工艺的12集总模型[10]。但机理建模的建立过于理想化,不能完全模拟出实际工业过程中的不确定和干扰,降低了机理模型的精确度;此外,大多数的化工过程都难以用准确的机理来描述,这大大增加了建模难度和精确度。
人工神经网络能在过程机理不明或过于复杂的情况下寻找系统过程输入数据和输出数据之间的相关关系,从而建立过程数学模型[11]。神经网络具有强大的自适应、自组织、自学习和非线性拟合能力,因此,它在化工领域尤其是在一些复杂过程中得到了广泛的应用[12-14]。
本工作根据催化裂化反应机理和MIP工艺的特点,结合大量的工业数据,开展了MIP工艺过程的集总动力学模型与BP神经网络模型相结合预测目标产物精度的研究,以提高目标产物的预测精度。
1 模型集总反应网络和动力学方程的建立
许多研究将催化裂化原料油按烃类族组成进行集总划分,但目前大多数工厂通常采用饱和分、芳香分、胶质和沥青质4个组分来表示重质原料油的组成,同时考虑到胶质与沥青质反应特性相似,且二者含量,尤其是沥青质含量很低,将原料油分成饱和分、芳香分、胶质和沥青质3个集总,这样划分很大程度上简化了反应网络。本工作所采集的大量工业装置数据是根据实时数据整理得到的,无法获得相对应的柴油、汽油和气体的详细组成数据,因此,将产物分为柴油、汽油、液化气、干气和焦炭5个集总。
MIP工艺的提升管反应器见图1。反应器包含2个反应区[2],第一反应区以裂化反应为主,采用高温、短接触和大剂油比操作;第二反应区主要是通过采用较低的反应温度和较长的反应时间来强化氢转移和异构化反应,实现汽油中的烯烃含量的降低和异构烷烃含量的增加,同时抑制二次裂化。但是两个反应区发生的反应本质上是相同的,只是不同反应发生的比例有所变化,所以采用同一个反应网络进行描述。
MIP工艺8集总反应网络见图2。总反应网络共计包含22个反应。

图1 MIP工艺的提升管反应器Fig.1 Sketch of riser reactor in maximizing iso-paraffins(MIP) process.

图2 MIP工艺8集总反应网络Fig.2 8-Lump kinetic model for MIP process.HS:saturates of heavy oil;HA:aromatics of heavy oil;HR:asphaltenes and resins of heavy oil;D:diesel;G:gasoline;LPG:liquefied petroleum gas.
本工作对模型的基本假设参照文献[8],考虑催化剂的重芳烃失活与碱氮失活等其他因素的影响,忽略质点内扩散,因此,由连续性方程和反应速率方程可推导得出模型的基本方程,见式(1)。

2 动力学参数的求取和分析
模型中的动力学参数通过MATLAB编程计算,利用其内置的龙格库塔法[15]求解模型微分方程,同时应用遗传算法[16]优化目标函数。待优化的目标函数(func)见式(2)。

首先假设一组活化能与指前因子为遗传算法的初值,然后利用Arrhennius方程计算出2个反应区的反应速率值,解出模型的基本方程,从而求得目标函数值。遗传算法通过不断选择、变异、交叉不断优化活化能与指前因子数值,使目标函数值最小。
本工作估计动力学参数的数据来源于国内某炼油厂MIP装置2014年6月10日至2014年10月30日的生产实测数据,共120组,其中,代表性的30组原料油和催化剂性质的数据见表1,操作条件数据见表2。表中的数据前10组用于模型的计算,后20组以及未列出的90组数据用于模型的验证。计算结果见表3。

表1 MIP工业装置原料油和催化剂的性质Table 1 The properties of feedstock and catalyst of MIP industrial units
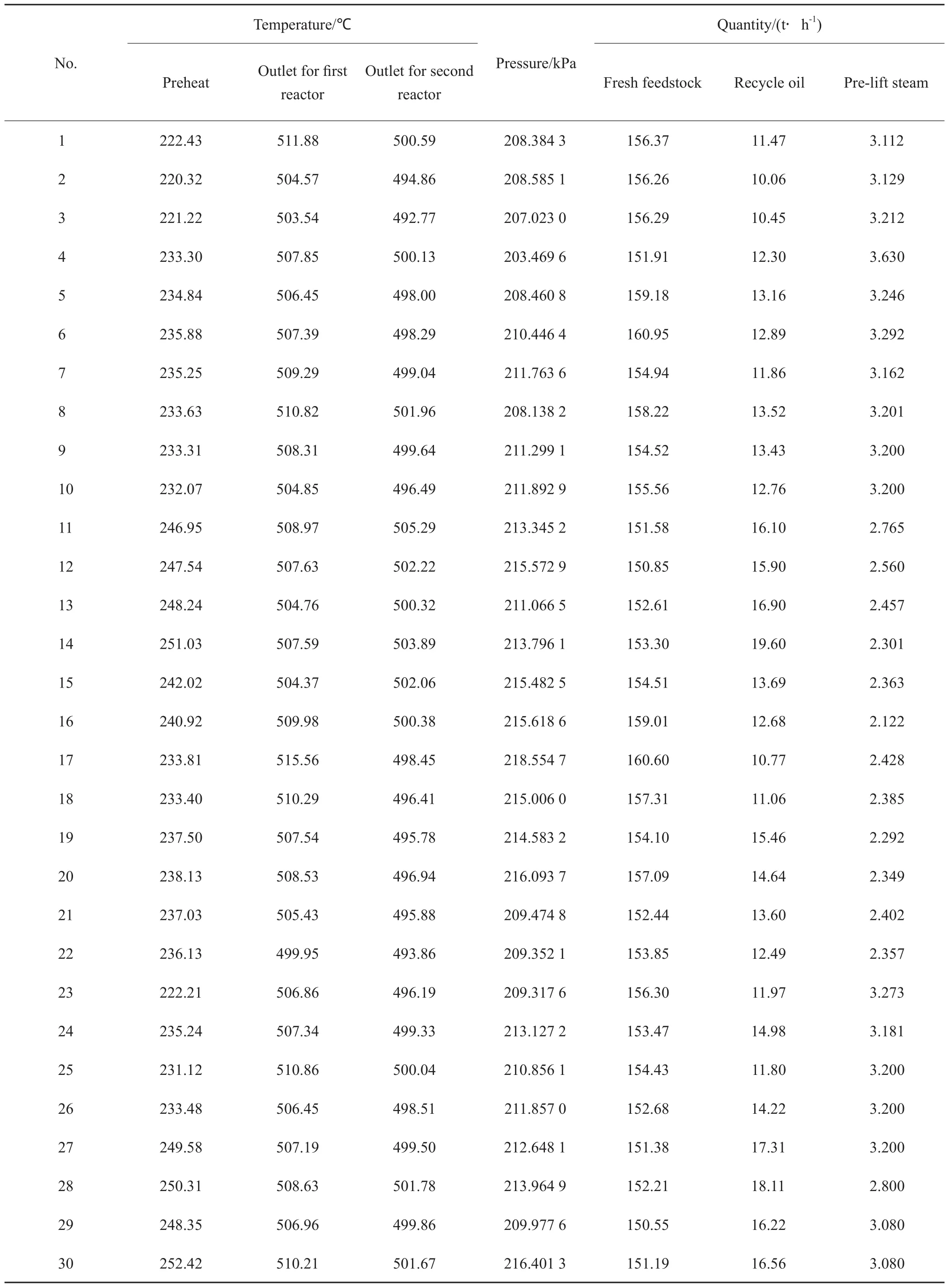
表2 MIP工艺操作条件Table 2 The operating conditions of MIP process

表3 8集总模型动力学参数Table 3 The kinetic parameters of the 8-lumped kinetic model for MIP process
从表3可看出:1)原料油3个集总饱和分、芳香分、胶质和沥青质裂化生成小分子的反应速率常数(kn)明显大于柴油和汽油裂化生成小分子的反应速率常数。同时饱和分、芳香分、胶质和沥青质裂化生成小分子的活化能也明显小于柴油、汽油裂化生成小分子的活化能,因此,大分子烃类化合物比小分子更容易裂化,且裂化反应速率更快,与催化裂化反应规律相符。2)总体来说,饱和分裂化生成小分子的反应速率常数的和(k1+k2+k3+k4+k5)最大,芳香分次之(k6+k7+k8+k9+k10),胶质和沥青质最小(k11+k12+k13+k14+k15),表明饱和分裂化生成小分子的反应速率更快,芳香分次之,胶质和沥青质最慢。3)饱和分和芳香分生成汽柴油的反应速率常数远大于胶质和沥青质生成汽柴油的反应速率常数,且远大于它们生成裂化气(k3+k4,k8+k9)、焦炭(k5,k10)的速率常数,说明汽柴油主要来自于饱和分和芳香分的裂化。芳香分生成柴油的反应速率常数(k6)略大于生成汽油的反应速率常数(k7),这是由于芳香分中芳环上的侧链容易断裂成小分子的烷烃和烯烃,但是芳香环本身十分稳定,难发生开环反应,直接进入柴油中,因此芳香分是柴油的主要来源之一。4)对于生成干气的反应速率常数,饱和分(k4)<芳香分(k9)<胶质和沥青质(k14),且柴油(k18)和汽油(k21)的反应速率常数远小于前三者。同时对应反应的活化能E4>E9>E14,且远小于E18和E21。因此柴油与汽油很难深度裂化成干气,胶质和沥青质对生成干气的贡献最大。5)从生焦反应速率常数看,饱和分(k5)<芳香分(k10)<胶质和沥青质(k15),且柴油(k19)和汽油(k22)的反应速率常数远小于前三者。同时对应反应的活化能E5>E10>E15,且远小于E19和E22。因此胶质和沥青质对生焦的贡献最大。从催化裂化反应机理来看,胶质和沥青质是原油中最重的组分,含有多个芳环和环烷环杂合而成的稠环结构,在这些环上往往还带有较多的烷基链,此外,分子中还有较多的杂原子,这些烷基链易断裂生成裂化气,而稠环部分则易发生缩合反应而生成焦炭。因此,胶质和沥青质反应是裂化气和焦炭的主要来源。
3 模型的验证
为验证所求得的模型动力学参数的可靠性,图3给出了产物分布的实际值和模型计算值之间的相对误差。从图3可看出,用于模型验证的110组数据的相对误差几乎全部小于10%,且经计算产物分布的平均相对误差均小于5%。说明所求得的模型动力学参数是可靠的。

图3 产品分布的模型计算值与实际值的相对误差Fig.3 Relative error of product distribution between the model-calculated values with the commercial data.
4 BP神经网络的建立及其对集总动力学模型的修正结果
BP神经网络是一种单向传播的多层前向网络,这种网络不仅含有输入节点、输出节点,且还含有一层或者多层隐含节点。对输入信息,首先向前传播到隐含层的节点上,然后经各单元的映射函数运算后,把隐含节点的输出信息传播到输出节点,最后给出输出结果。
本工作采用含有一个隐含层的神经网络,即3层神经网络,同时选取表1与表2中的原料组成及性质、催化剂性质、操作条件等共14组变量为BP神经网络的输入,用集总模型计算的各产物收率与实际值的相对误差,共5组变量为输出。其中,后100组数据用来训练神经网络,前20组数据用来验证神经网络。虽然BP网络的隐含层神经元数有相应公式可计算,但实际应用过程中仍需选取不同的隐含层神经元个数建立不同的神经网络,对其进行训练,然后检验模型,并根据相对误差最小的原则来选择适宜的神经元的个数,结果见图4。由图4可见,最佳隐含层神经元个数为7,因此本研究建立14-7-5结构的BP神经网络。
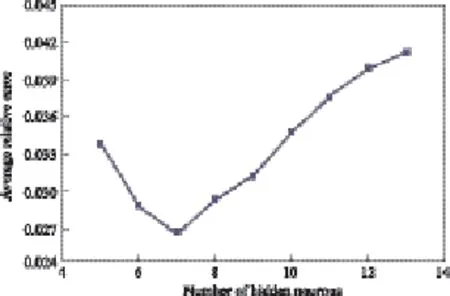
图4 隐层神经元个数对模型误差的影响Fig.4 Effect of the nodes of hidden layer on average relative error for BP.
集总模型用神经网络模型修正后采用20组样本验证的相对误差统计见表4。由表4中数据可以看出,机理模型与神经网络结合后,各产品预测误差均有较明显下降(平均下降约1.32百分点),体现了混合模型的优越性。

表4 20组验证样本相对误差Table 4 Relative errors of 20 groups of samples
5 结论
1)根据催化裂化反应机理和MIP工艺的特点,并结合工业数据,建立了该工艺的8集总反应网络。
2)利用工业数据,通过参数估计确定了模型的47个动力学参数,且模型参数可靠,并能与催化裂化反应规律较好地吻合。
3)通过将集总动力学模型与有7个隐含层神经元个数的BP神经网络相结合,可进一步提高模型对产物分布的预测精度,为重油催化裂化的模拟优化提供了一个新的方向。
符 号 说 明
a 组分向量
f(A) 重芳烃吸附失活函数
f(N) 碱氮吸附失活函数
K 所有反应速率常数组成的矩阵
kA催化剂芳烃吸附失活系数
kN催化剂碱氮吸附失活系数
kn反应速率常数
MW气相混合物的平均摩尔质量,kg/mol
p 反应压力,Pa
R 气体常数,8.314 J/(mol·k)
SWH重时空速,h-1,可用近似计算
T 反应温度,K
tc催化剂停留时间,s
wA原料中芳烃的质量含量,%
wN原料中碱氮的质量含量,%
x 无因次反应器长度
α 催化剂生焦失活系数
φC/O剂油比
φ(tc) 催化剂时变失活函数
[1] 许友好. 我国催化裂化工艺技术进展[J].中国科学:化学,2014,44(1):13-24
[2] 许友好,张久顺,龙军. 生产清洁汽油组分的催化裂化新工艺MIP[J].石油炼制与化工,2001,32(8):1-5.
[3] 杨朝合,山红红,张建芳. 两段提升管催化裂化系列技术[J].炼油技术与工程,2005,35(3):28-33.
[4] 刘昱. 灵活双效催化裂化(FDFCC)工艺的工程设计及工业应用[J].炼油设计,2002,32(8):24-28.
[5] Weekman V W,Jacob S M,Gross B,et al. A lumping and reaction scheme for catalytic cracking[J].Aiche J,1976,22(4):701-713
[6] 熊凯,卢春喜. 催化裂化(裂解)集总反应动力学模型研究进展[J].石油学报:石油加工,2015,31(2):293-306.
[7] 刘熠斌,杨朝合,山红红,等. 提高汽、柴油收率的两段提升管催化裂化动力学模型研究及应用 [J].石油学报:石油加工,2007,23(5):7-14.
[8] 欧阳福生,凌巧,虞正恺. 灵活多效催化裂化工艺反应动力学模型研究[J].高校化学工程学报,2015,29(5):1106-1113.
[9] 吴飞跃,翁惠新,罗世贤. FDFCC工艺中重油提升管催化裂化反应动力学模型[J].石油学报:石油加工,2008,24(5):540-547.
[10] 江洪波,钟贵江,宁汇,等. 重油催化裂化MIP工艺集总动力学模型[J].石油学报:石油加工,2010,26(6):901-908.
[11] Hopf i eld J J. Neural networks and physical systems with emergent collective computational abilities[J].Proc Natl Acad Sci USA,1982,79(8):2554-2558.
[12] Mihet M,Cristea V M,Agachi P S. FCCU simulation based on fi rst principle and artif i cial neural network models[J].Asia-Pac J Chem Eng,2009,4(6):878-884.
[13] Li Quanshan,Li Dayu,Cao Liulin. Modeling and optimum operating conditions for FCCU using artif i cial neural network[J].J Cent South Univ,2015,22(4):1342-1349.
[14] 杨文剑,张洋,张小庆,等. 集总动力学-BP神经网络混合模型用于预测延迟焦化装置液体产品产率[J].石油炼制与化工,2015,46(7):101-106.
[15] 程正兴,李水根. 数值逼近与常微分方程数值解[M].西安:西安交通大学出版社,2000:284-293.
[16] 周明,孙树栋. 遗传算法原理及应用[M].北京:国防工业出版社,1999:123-138.
(编辑 平春霞)
Prediction of the product yield from catalytic cracking process by lumped kinetic model combined with neural network
Ouyang Fusheng,Liu Yongji
(Research Center of Petroleum Processing,East China University of Science and Technology,Shanghai 200237,China)
Based on the reaction mechanism of heavy oil catalytic cracking and the characteristics of maximizing iso-paraff i ns(MIP) process and combined with a large amount of industrial data,the reaction network of an 8-lump kinetic model including saturates,aromatics,asphaltenes+resins,diesel,gasoline liquefied gas,dry gas and coke for the process was developed. And then the 47 kinetic parameters for the model were calculated by the combination of Runge-Kutta method and genetic algorithm. The results showed that good consistence with the reaction mechanism of heavy oil catalytic cracking,the average relative errors between calculated values and actual values of products are all less than 5%. Combining the lumped model with the 14-7-5 type of BP neural network can further improve the prediction accuracy of the product distribution,which provides a new direction for simulation and optimization for heavy oil catalytic cracking.
catalytic cracking;MIP process;lumped model;neural network
1000-8144(2017)01-0009-08
TE 624
A
10.3969/j.issn.1000-8144.2017.01.002
2016-08-10;[修改稿日期]2016-10-11。
欧阳福生(1964—),男,江西省赣州市人,博士,教授,电话 021-64252836,电邮 ouyfsh@ecust.edu.cn。
猜你喜欢
电气技术(2023年7期)2023-08-08 05:26:36
神经损伤与功能重建(2020年11期)2020-12-01 05:01:54
化工进展(2020年4期)2020-05-08 10:23:50
石油石化绿色低碳(2019年6期)2019-01-14 01:16:16
石油石化绿色低碳(2019年6期)2019-01-14 01:16:14
湖南中医药大学学报(2016年1期)2016-12-01 04:08:21
当代化工研究(2016年6期)2016-03-20 16:21:37
磁共振成像(2015年1期)2015-12-23 08:52:21
化工进展(2015年6期)2015-11-13 00:26:37
中国舰船研究(2015年2期)2015-02-10 06:45:50
