
一种改进的协同过滤推荐算法
2017-07-18 11:48:47王茜王艳明
现代计算机 2017年14期
王茜,王艳明
(重庆大学计算机学院,重庆 400044)
一种改进的协同过滤推荐算法
王茜,王艳明
(重庆大学计算机学院,重庆 400044)
在协同过滤推荐系统中,商品被视为特征,用户提供他们对购买的商品的评分。通过对用户评分的学习,推荐系统可以向用户推荐他们可能需要的产品。然而电子商务通常有相当多的产品,如果在推荐前要对每一个商品都进行考虑,推荐系统将是非常低效的。提出一种改进的ItemRank方法,应用自构建聚类算法来减少商品数量相关的维度,然后直接在聚类上运行推荐算法。最后,对推荐聚类进行变换得到推荐商品列表推荐给不同的用户。所提出的方法在计算推荐商品时所需的时间大大减少。实验结果表明,在不影响推荐质量的前提下,推荐系统的效率得到了提高。
协同过滤推荐系统;ItemRank
0 引言
随着网络的快速发展,网络商店中商品的数量、种类变得越来越多,网络购物的人群也越来越多,从如此数量众多、种类繁杂的商品中选择适合自己的商品也变得越来越困难。因此,推荐系统应运而生,以帮助人们在网上找到他们感兴趣的商品,节约他们的检索时间[1]。对于用户来说,推荐系统可以通过他们的购买、浏览记录分析出他们的喜好,从而把他们感兴趣的商品推荐给他们。在过去的几年中,推荐系统得到了快速的发展,在本质上,他们可以分为两类,基于内容和协同过滤,虽然近几年来混合系统[2]趋势不断增长。
基于内容的推荐系统根据产品的类别和其他属性等内容向用户推荐商品。通过一些技术分析这些数据,如贝叶斯模型[3],基于内容的推荐系统向用户推荐那些最有吸引力的商品。一般来说基于内容的推荐系统需要商品和用户的详细信息,它可以向用户推荐新商品,但是它需求的信息是巨大的,而且很难获取所有用户和商品的属性及其他信息。此外收集代表用户或商品的唯一属性也很难。
协同过滤推荐系统[4-8]不需要用户或商品属性的详细信息。相反,它通过用户和商品之间的交互信息向用户推荐商品,通常交互信息表示为用户对购买的商品的评分。通过对用户项目评分矩阵的分析,系统可以向他们推送和他们有相同兴趣用户购买的而且他们还没有购买的商品。总体来说协同过滤系统更易实现和高效。
然而网络商店中通常有相当多的产品,如果在推荐前要对每一个商品都进行考虑,推荐系统将是非常低效的。降维技术已经在面对大规模数据产生快速、高效推荐系统中得到了广泛的应用。K-means的一种变形B-Kmeans[9]算法已经应用在对用户进行不同的划分中。通过分析给定用户所属的分区中用户的邻域,向用户推荐商品。Ba Q[10]等人将用户按照性别、年龄、职业等属性分组,然后用户项目评分矩阵重组后再计算两个用户之间的相似度。CAI[11]等人用模糊聚类方法运用到用户上对用户进行聚类,利用用户组特征向量代表用户,对用户代表的维度降维。Sarwat[12]等人在一个框架内使用三种类型的基于位置的评级的分类法产生推荐,利用用户划分和旅行点向查询用户推送跟接近的候选人。在PRM2[13]算法中,个人兴趣、人际关系相似性和人际影响被融合成一个统一的个性化推荐模型,并且使用奇异值分解(SVD)来对原始的用户项目评分矩阵进行降维。ICCRS[14]算法是一种迭代评分算法,它对有偏见的评价者有很大的鲁棒性,与之前的迭代方法不同,它不是基于将提交的评分与最终评分的近似进行比较,而是完全将评分评估的可信度与排名本身分离,这使得它比先前的迭代过滤算法对复杂的攻击有更强的鲁棒性。
上述基于维度降低的推荐系统具有一些缺点。一些系统[10,12]需要关于用户或商品的额外属性来将用户或商品进行聚类,而这些属性通常是很难在实际应用中得到的。另一些系统[11,15]需要预先给出聚类的数量,这对用户来说是很难确定的,只能通过重复训练,这是一个很大的负担。此外,使用降维的推荐系统在计算相似性的时候仅仅考虑聚类的中心,忽略聚类的方差可能导致推荐结果的不精确。
在本文中,我们提出了一种改进的ItenRank方法,应用自构建聚类算法来减少商品的维度,创建出商品聚类之间相互关系的相关图。然后执行一系列的随机游动,为每个用户生成商品聚类的推荐列表。最后执行将商品聚类推荐列表转换成单个商品的推荐列表。利用我们提出的方法,不需要搜集用户和商品的额外属性信息,而且不需要用户提供预定的聚类数量。此外,在计算相似性的时候我们不仅考虑聚类中心,还应用聚类方差等因素。由于商品数量维度的减少,我们提出推荐商品的处理时间也大大减少。
1 相关算法
假设一个有N个用户的集合ui,1≤i≤N,一个有M个商品的集合pj,1≤i≤M。用户ui通过对商品pj的评分ri,j(ri,j为一个正整数)来表达自己对商品的喜好程度。通常,评分越高表明用户对商品的喜好程度越高。如果用户ui未提供对商品pj的评分,ri,j=0。这些信息用一个用户项目评分矩阵来表示R:

此矩阵为N×M矩阵,把Ri记为Ri=[ri1ri2…riM],1≤i≤N。矩阵R的每一行代表一个用户,每一列代表一个商品。协同过滤推荐系统的目标是给定用户项目评分矩阵,预测用户对商品的喜好程度,向用户推荐商品。
ItemRank[16-17]是协同过滤推荐的基本方法之一。它应用基于图模型的推荐算法,通过项目(商品)节点来构图,形成项目间的关联关系图并计算得到用户的偏好向量,然后利用随机游走算法预测用户对项目的预测评分,最后向用户推荐生成的Top-K商品。在关联关系图创建步骤中,每个节点都是一个商品,商品节点pi与pj之间的连线wi,j具有的权重是同时购买商品pi和pj的数量。构建完关联关系图后得到矩阵W:
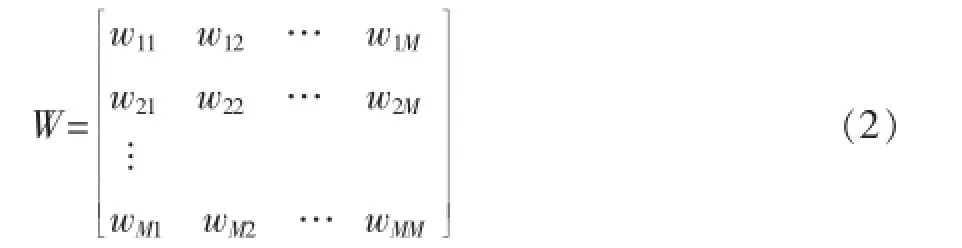
此矩阵为M×M矩阵,然后对矩阵W的每一列进行归一化。在随机游走算法中,假设用户ui,1≤i≤N,设Si(0)=[1/M 1/M…1/M]T,然后执行Si(t+1)= αWSi(t)+(1-α)RiT操作,t=0,1,2,…,直至达到收敛。α∈[0,1]是用户定义的一个常数,通常α取0.85,在执行20次迭代后达到收敛效果。设Si为收敛后的向量,即用户ui的预测偏好列表。然后可以根据Si中元素的大小顺序向用户ui推荐商品。
2 提出的改进算法
电子商务中可能包含数量巨大的商品,这使得ItemRank在生成项目节点图的矩阵W时耗时较长,导致ItemRank不适合处理大规模数据。本文中,我们主要是针对ItemRank算法的改进。首先我们用自构建聚类(SCC)算法[18-19]为用户分配类标签,其次用自构建聚类(SCC)算法对商品进行聚类以降低维度,然后创建项目关联图,随后利用随机游走算法预测用户对项目聚类评分,最后进行聚类转换到商品个体对用户进行推荐商品。结果表明ItemRank的效率可以大大提高。
2.1 自构建聚类(SCC)算法
假设X集合有n个模式X1,X2,…,Xn,其中Xi=xi1,xi2,…,xip,1≤i≤n,SCC算法目的是将这些模式分配到不同的聚类中。假设现在存在K个聚类,分别是G1,G2,…,Gk,每个聚类Gj(1≤j≤k)的平均值为mj=mj1,mj2,…,mjp,标准差为σj=σj1,σj2,…,σjp,Gj的大小为sj,即Gj含有的模式个数。最初我们没有聚类,K=0,我们计算每个模式Xi对聚类Gj的隶属度μGj(Xi),
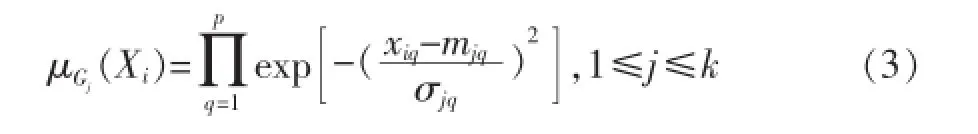
如果隶属度不小于预定义的阈值,μGj(Xi)≥ρ, 0≤ρ≤1,我们就说Xi通过了聚类Gj的相似度检测。较大的ρ导致较小的聚类,较小的ρ导致较大的聚类。此时可能有两种情况。一种情况为Xi没有通过对现存的任何聚类Gj的相似度检测。这种情况下我们创建一个新聚类Gh,h=K+1,mh=xi,σh=σ0,σ0=σ0,σ0,…,σ0是用户定义的一个常数向量。此时聚类的数目增加了1,聚类Gh的大小初始化为1,即K=h,s1=1。第二种情况Xi通过了某些现存的聚类相似度检测,设最大隶属度的聚类为Gt,此时把Xi归入到聚类Gt中,更新聚类Gt的均值和标准差,这种情况下K不改变。该过程一直跌到所有的模式被处理完,最终得到K个聚类。
2.2 标记用户类标签
为了有效的降低维数,我们用SCC算法对用户进行聚类,标记用户类标签,而且不需要用户输入聚类个数。为了消除用户评分的尺度不同,我们对用户评分进行归一化:
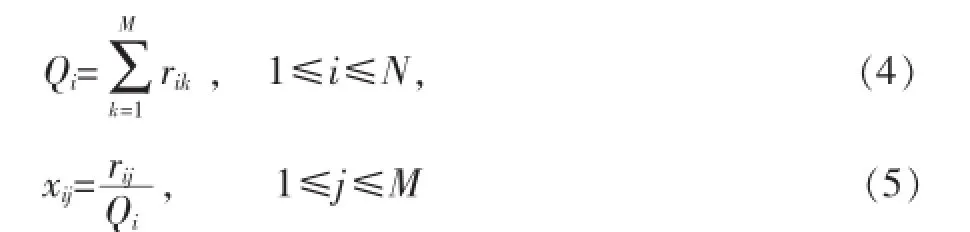
设Xi=xi1,xi2,…,xiM,1≤i≤N,X={Xi│1≤i≤N},我们对X运用SCC算法,假设得到z个聚类,G1,G2,…,Gz,每个聚类当做一个类标签,分别标记为c1,c2,…,cz。对所有属于聚类Gj的用户我们标记类标签为cj。此时我们将原始数据集合R扩展为R+,(R1,y1),(R2,y2),…(RN,yN),yi∈{c1,c2,…,cz},1≤i≤N。
2.3 降维
这个步骤中我们使用Jiang[19]等提出的类似方法降低商品维数。对于每件商品pj,1≤j≤M,我们构造一个特征模式Xj=xj1,xj2,…,xjz,其中:
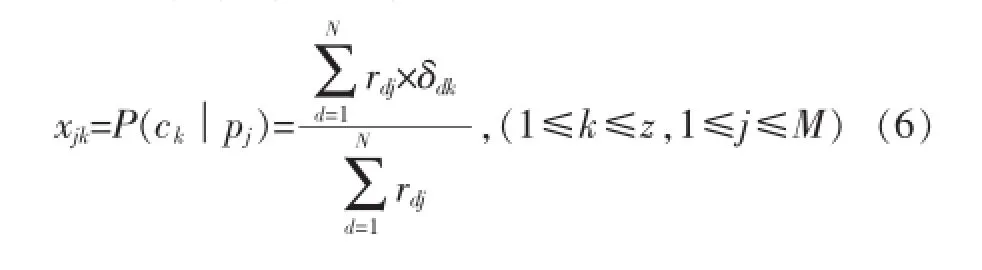

因此我们有M个特征模式X1,X2,…,XM,每个具有z个分量。设Y={Xi│1≤i≤M}。
然后我们在Y上应用SCC算法,假设我们获得q个聚类G1,G2,…,Gq,同一聚类中的商品相似。由于有q个聚类,用户对商品评价的维度由M降维到q,得到矩阵T:

然后我们把高维的N×M矩阵R降维成低维矩阵B:
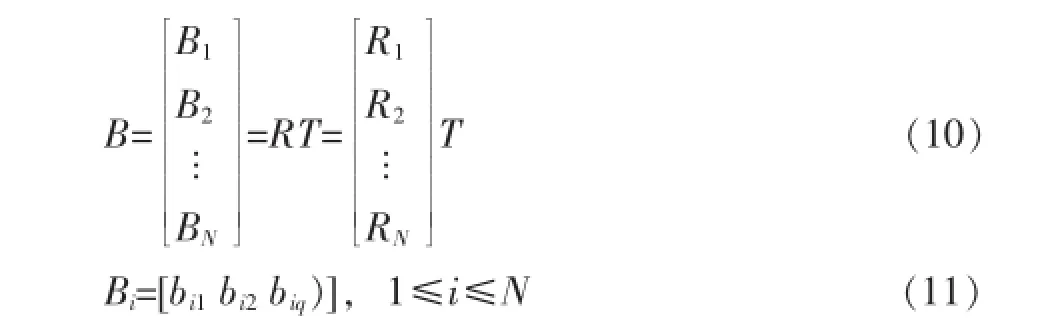
我们将B中的每一列称为一个商品类,因此我们有q个商品类,记为g1,g2,…,gq。由此,原来具有M个商品评分的用户记录降维成具有q个商品组评分。ItemRank算法运行在R矩阵上,我们的算法将运行在降维后的B矩阵上。
2.4 创建关联关系图
此步骤中我们创建一个相关图,显示q个商品类之间的关联关系。由于我们使用的是B,我们以不同的方式派生关联关系图。每个商品类被视为一个节点,我们有q个节点。节点gi和gj之间的权重为wij,1≤i,j≤q,计算方式如下:
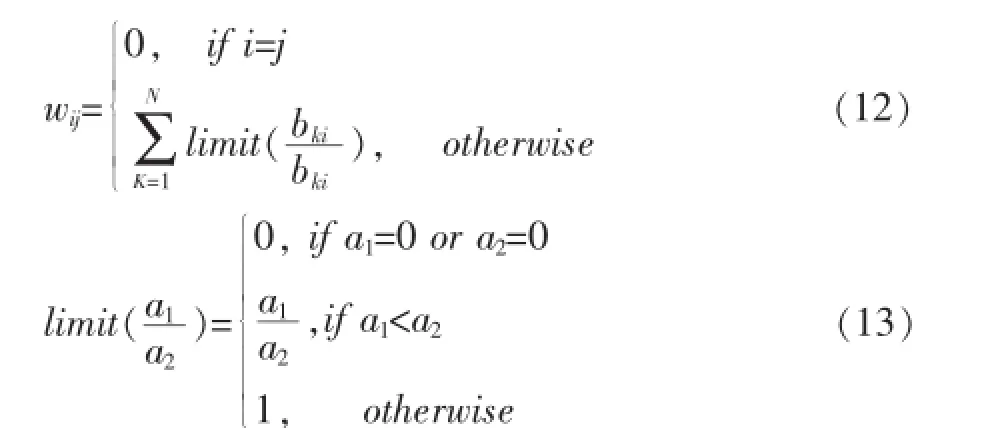
如果wij太大,则某些商品类可能占主导地位,并且妨碍一些商品被划分到其他商品组,因此我们对wij设置上限为1。当关联关系图完成后,我们得到如下矩阵:
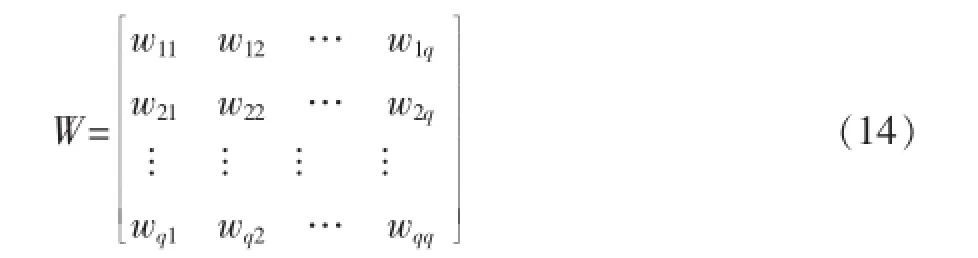
然后我们对W矩阵的列进行归一化。
2.5 随机游走
在随机游走步骤中,执行一系列随机游走。任一用户ui,1≤i≤N,设:

然后执行如下步骤,直至vi收敛。
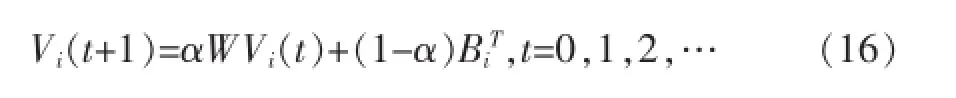
其中W是根据公式(14)得到的,Bi是根据公式(11)得到的。假设Vi为收敛后的向量,则Vi是为用户ui生成的推荐商品组。
2.6 再转换
在上面步骤中,我们得到q个商品类,为用户ui推荐的商品类包含q个商品。但是,最终我们不是向用户推荐商品类,而是向用户推荐单个商品,因此,我们要将Vi转化成包含单个商品列表的Si。根据公式(9),我们得到xj对商品聚类G1,G2,…,Gq的隶属度分别为tj1= μG1(Xj),tj2=μG1(Xj),…,tjq=μGq(Xj)。首先我们对公式(8)中的矩阵T的列进行归一化:
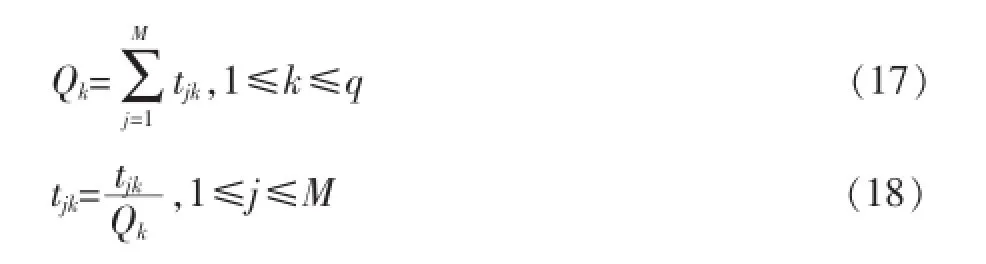
对每一行进行如下计算:
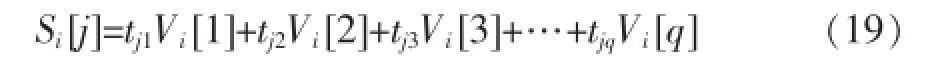
Si[j]是Si的第j个分量,Vi[k]是Vi的第k个分量。tjk是商品pj对商品类gk的贡献值,Vi[k]表示用户ui对商品类gk的喜好程度。因此tjkVi[k]表示用户ui在商品类gk中对商品pj的喜好程度,累加得出用户ui对商品pj的喜好程度。最终,我们得到用户ui的推荐商品列表Si。
3 实验结果与分析
3.1 时间复杂度分析
在标记用户类标签步骤时,我们必须计算每个用户和每个现有聚类之间的相似性,N为用户数,M为商品数,每个用户向量有M个分量,z为类标签个数,所以这步骤复杂度为O(NzM)。在降维步骤中,我们需要计算特征模式和现有聚类之间的相似性,特征模式为M,商品类为q,每个特征模式包含z个分量,所以这步骤复杂度为O(Mqz)。在关联关系图步骤中,两点之间的权重wij都需要计算,所以这步骤复杂度为O(q2)。在随机游走算法中,公式(16)必须要进行迭代,每次的跌倒需要q q2次运算,对所有用户(N个)的复杂度为O(Nq2)。最后,对一个用户来说,公式(19)需要进行M次运算,每次涉及q次乘法和q-1次加法,所以此步复杂度为O(NqM)。所以,总共的时间复杂度为O(NzM)+O(Mqz)+O(q2)+O(Nq2)+O(NqM)。
3.2 实验结果分析
本文用了四个数据集进行实验,分别是Movie-Lens,BookCrossing和Epinions。这三个数据集的特征如表1所示。通过与ItemRank算法,PRM2算法,BiFu算法和ICRRS算法进行比对。ItemRank算法不采用任何降维技术,PRM2算法应用奇异值分解(SVD)方法来降维,BiFu算法应用K-means算法进行聚类降维,ICCRS算法将评分估计的可信度与排名本身分离。因为K-means需要预先输入聚类数目,所以我们先运行本文的方法得到聚类数目,然后把聚类输入应用到BiFu算法中。
表2显示了本文方法(IRSCC)和BiFu中涉及的用户项目聚类数。表3显示了算法之间绝对平均误差(MAE)的比较。对MAE来说,获得的值越小,方法越好。可以看出对于三个数据集来说,ItemRank和IRSCC在MAE方面表现相当好。表4显示了不同方法之间的执行时间(以秒为单位)的对比。我们可以看出IRSCC运行速度要比其他方法好很多。
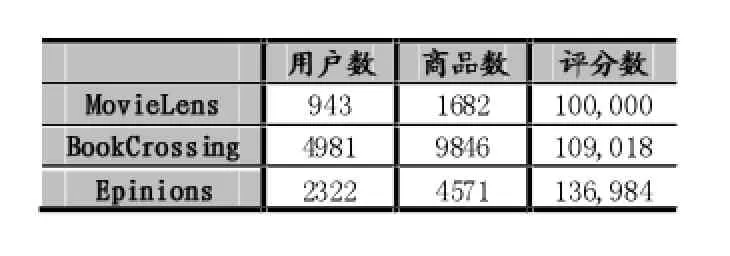
表1 数据特征
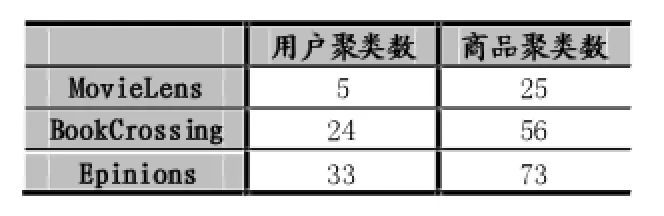
表2 聚类数目
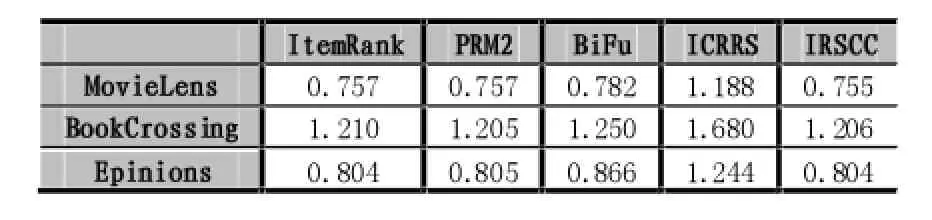
表3 不同方法的MAE比较
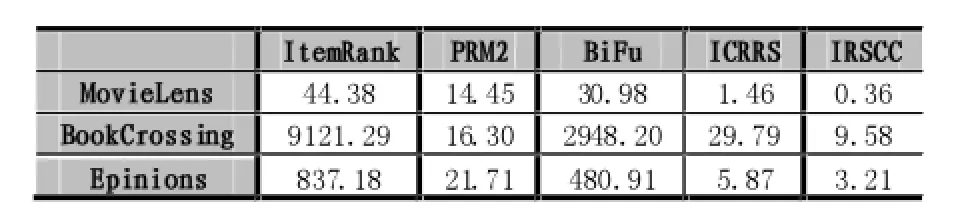
表4 不同方法执行时间比较
因为ItemRank算法设计的维数是商品的数量,例如,对于BookCrossing数据集来说ItemRank要处理一个9846×9846矩阵,所以ItemRank在BookCrossing上运行9121.29s。相反,IRSCC应用自构建聚类以降低维度,把9846个商品聚类到56个聚类中。所以在公式(16)中使用的关联关系矩阵减小到56×56,所以IRSCC运行的很快。BiFu通过K-means进行降维,这是非常耗时的,所以BiFu也比IRSCC算法慢很多。
为本算法选择一个合适的ρ仍然是一个难题,还是经受一些试验和错误。在第3节中指出ρ的选择直接影响算法的效果。当ρ选择的较大时,聚类较小,生成的聚类数目就较多,这将导致算法运行时间增加。
4 结语
在协同过滤系统中,商品被视为特征。然而,涉及电子商务时,通常有相当多的商品,如果每一个商品在推荐前都要考虑的话,推荐效率将是非常低效的。我们提出了一种应用自构建聚类算法来降维,以达到效率的提高。实验结果表明,推荐系统的效率大大提高,而且不损害推荐质量。
[1]Marko Balabanovic,Yoav Shoham.Content-Based Collaborative Recommendation.Communications of the ACM.March 1997.Pages 66-72.
[2]Gatzioura,A.,Sànchez-Marrè,M.A Case-Based Recommendation Approach for Market Basket Data.IEEE Intell.Syst.30(1),2014. Pages20-27.
[3]Rish,I.An Empirical Study of the Naive Bayes Classifier.In:International Joint Conferences on Artificial Intelligence(IJCAI)Workshop on Empirical Methods in AI,pp.41-46.
[4]Cui,H.,Zhu,M.Collaboration Filtering Recommendation Optimization with User Imp licit Feedback.J.Comput.Inf.Syst.10(14),5855-5862,2014.
[5]Guo,G.,Zhang,J.,Thalmann,D.,Yorke-Smith,N.Leveraging Prior Ratings for Recommender Systems in E-Commerce.Electron. Comm.Res.Appl.13,440-455,2014.
[6]Nikolakopoulos,A.N.,Kouneli,M.,Garofalakis,J.A Novel Hierarchical Approach to Ranking-Based Collaborative Filtering.Commun.Comput.Inf.Sci.384,50-59,2013.
[7]Jiang,M.,Cui,P.,Liu,R.,Yang,Q.,Fei,W.,Zhu,S.Yang,Social Contextual Recommendation.In:21st ACM International Conference on Information and Knowledge Management,pp.45-54,2012.
[8]Porcel,C.,Tejeda-Lorente,A.,Martinez,M.,Herrera-Viedma,E.A Hybrid Recommender System for the Selective Dissemination of Research Resources in a Technology Transfer Office.Inf.Sci.184,1-19,2012.
[9]Sarwar,B.M.,Karypis,G.,Konstan,J.,Riedl,J.,Recommender Systems for Large-Scale E-Commerce:Scalable Neighborhood Formation Using Clustering.In:5th International Conference on Computer and Information Technology,2002.
[10]Ba Q,Li X,Bai Z.Clustering Collaborative Filtering Recommendation System Based on SVD Algorithm[C].Software Engineering and Service Science(ICSESS),2013 4th IEEE International Conference on.IEEE,2013:963-967.
[11]Cai Y,Leung H,Li Q,et al.Typicality-Based Collaborative Filtering Recommendation[J].IEEE Transactions on Know ledge and Data Engineering,2014,26(3):766-779.
[12]Sarwat M,Levandoski J J,Eldawy A,et al.LARS*:An Efficient and Scalable Location-Aware Recommender System[J].IEEE Transactions on Knowledge and Data Engineering,2014,26(6):1384-1399.
[13]Qian X,Feng H,Zhao G,et al.Personalized Recommendation Combining User Interest and Social Circle[J].IEEE Transactions on Knowledge and Data Engineering,2014,26(7):1763-1777.
[14]A llahbakhsh M,Ignjatovic A.An Iterative Method for Calculating Robust Rating Scores[J].IEEE Transactions on Parallel and Distributed Systems,2015,26(2):340-350.
[15]Xue,G.-R.,Lin,C.,Yang,Q.,Xi,W.,Zeng,H.-J.,Yu,Y.,Chen,Z.Scalable Collaborative Filtering Using Cluster-Based Smoothing.In:ACM SIGIR Conference,2005.
[16]范家兵,王鹏,周渭博,等.在推荐系统中利用时间因素的方法[J].计算机应用,2015,35(5):1324-1327.
[17]Pucci,A.,Gori,M.,Maggini,M.A Random-Walk Based Scoring A lgorithm Applied to Recommender Engines,Lecture Notes in Computer Science-Advances in Web Mining and Web Usage Analysis 4811(2007):127-146.
[18]Lee,S.-J.,Ouyang,C.-S.A Neuro-Fuzzy System Modeling with Selfconstructing Rule Generation and Hybrid SVD-Based Learning. IEEE Trans.Fuzzy Syst.11(3),341-353,2003.
[19]Jiang,J.-Y.,Liou,R.-J.,Lee,S.-J.,2011.A Fuzzy Self-Constructing Feature Clustering Algorithm for Text Classification.IEEE Trans.Knowl.Data Eng.23(3),335-349.
Improved Collaborative Filtering Recommendation Algorithm
WANG Qian,WANG Yan-ming
(College of Computer Science,Chongqing University,Chongqing 400044)
In collaborative filtering recommender systems,products are regarded as features and users are requested to provide ratings to the products they have purchased.By learning from the ratings,such a recommender system can recommend interesting products to users.However,there are usually quite a lot of products involved in E-commerce and itwould be very inefficient if every product needs to be considered beforemaking recommendations.Proposes an improved approach based ItemRank which applies a self-constructing clustering algorithm to reduce the dimensionality related to the number of products,Recommendation is then donewith the clusters.Finally,re-transformation is performed and a ranked list of recommended products is offered to each user.With the proposed approach,the processing time formaking recommendations ismuch reduced.Experimental results show that the efficiency of the recommender system can be improved without compromising the recommendation quality.
王茜(1970-),女,重庆人,教授,研究方向为网络安全、电子商务、数据挖掘
2017-03-14
2017-05-10
1007-1423(2017)15-0008-06
10.3969/j.issn.1007-1423.2017.15.002
王艳明(1990-),男,河北邯郸人,硕士,研究方向为数据挖掘
Collaborative Filtering Recommender System;ItemRank
猜你喜欢
车主之友(2022年4期)2022-08-27 00:57:12
海峡姐妹(2019年12期)2020-01-14 03:24:40
电子测试(2017年15期)2017-12-18 07:19:27
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
智能系统学报(2015年4期)2015-12-27 09:38:39
南都周刊(2015年4期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
南都周刊(2015年1期)2015-09-10 07:22:44
电子设计工程(2015年6期)2015-02-27 12:04:53
计算物理(2014年1期)2014-03-11 17:00:18
