
这些都是货真价实的伪科学|涨姿势
2017-07-07 01:35
壹读 2017年1期


“实验验证,95%的用户使用两周后效果明显”;
“统计显示,服用某保健品的人群比同地区平均寿命高出2岁”;
“超过75%的用户在同类产品中更加偏爱本品牌”;
数字时代,似乎有数据说话的广告总是更能令人信服,尤其是當广告语还出自一个穿着白大褂、戴眼镜的中年帅大叔之口。
可是“电视医生”们口中的数字当真是铁证如山吗?就让壹读君来带你看看这些“科学实验”背后的猫腻,原来那些言之凿凿的数字,也许通通只是一个无关紧要的语气助词。
比三分之二提高两倍的75%的壹读君|何满子
1. 糖丸效应
作为医药界最著名、波及最广泛的理论,糖丸效应告诉我们:当人们以为自己服用了药物、但其实只是服用了糖丸的时候,由于心理作用,糖丸也可能产生和药物类似的治愈效果。
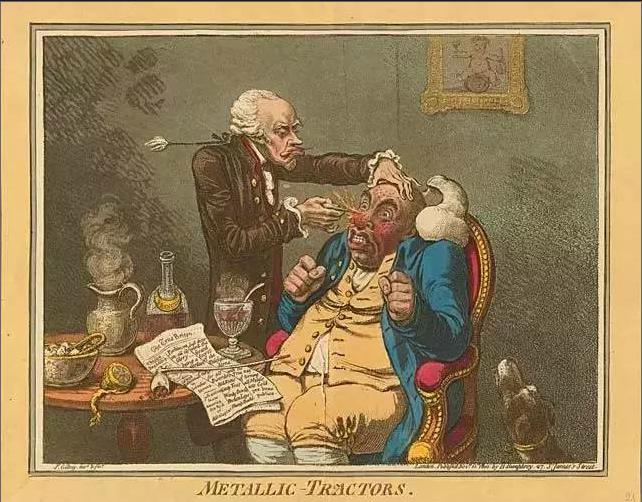
“糖丸”(placebo)一词来自拉丁语,意为“吾将取悦”,并且从16世纪开始就被发现、被研究。到了18世纪,英国生物学家John Haygarth第一个以科学实验证明了糖丸效应的存在:当时一位美国医学家Perkins号称发明了一种神奇的金属针,可以“吸走疼痛根源的有毒电流”,从而治疗风湿痛和肿胀,并且成功案例无数,还申请了专利。
于是John Haygarth从Perkins那里买了一支神奇金属针,用它和随便的一支普通针交替给病人治疗。结果发现,Perkins神奇金属针的治疗效果,和任何一支普普通通的铜针或者银针的治疗效果,并无差别。
Perkins发明的“可以消肿的神奇金属针”
所谓的“神奇金属”以及那些治愈病例,完全是病人的心理作用。
这种因病人的心理作用而产生治疗效果的“糖丸效应”,广泛地出现在医药界的每个角落,譬如在一个实验中,病人被告知自己吃下了刺激药物,随后便不同程度地出现了心率加快、血压升高、反应速度骤增的现象;另一个试验中,病人被告知吃下了安眠药,随后就出现了完全相反的身体变化——在两个实验中,病人吃下的都是糖丸。
也正是因为这个原因,在现在药物的功效测试中,“糖丸对照组”成了必不可缺的部分。只有当服下真正药物的病人组比服下糖丸的病人组产生明显优越的结果时,才能表示药物真的具有某种疗效。
而广告里仅凭用户的自我反应,觉得自己比使用前有精神、腿不疼、皮肤变白,很可能完全是糖丸效应在作祟。
2. 向均数回归(Regression to the mean)
如果用户的自我感觉不够科学,那么选取客观指标的数据,是否就完全值得信赖了?先来听听“向均数回归”(regression to the mean)再说。
“向均数回归”理论由Sir Francis Galton提出,指的是在统计学上,如果第一次测量时某个变量的数值非常极端,那么第二次测量时它一般都会向平均值靠拢。
举个例子:一百个人掷骰子。掷骰子是一个完全随机的状况,第一轮下来,我们从一百人中选出成绩最好的5个人。然后进行第二轮,以同样的规则再掷一轮骰子,那么第一轮成绩最好的那5个人,几乎不可能仍旧是掷得最好的那五个。也就是说,他们第二轮的表现一定不如刚才好,他们的成绩,必然要向平均成绩靠拢。
同样地,第一轮最差的5个人,也不大可能仍旧最差,他们也会向平均成绩靠拢。
多次测验中,第一次结果偏极端的会在接下来的测验中向平均值靠拢,就是“向均数回归”理论的核心。这种统计理论在生活中随处可见:父母身高都很高的小孩,通常会比父母矮;而父母都很矮的小孩,通常则比父母高——他们都在“向均数靠拢”。
同样地,提高考试成绩、降低胆固醇含量这些“奇效”,也可能只是向均数回归的结果:如果我们选取一个班里成绩最差的1/3进行实验,他们在第二次考试时肯定不可能还是最差的1/3,只要他们之中有几个人跳出了这个范围,这个1/3的群体就会产生成绩的进步。
而1994年《临床化学》杂志上发表的论文中也验证了,如果在医院选出胆固醇测试中含量最高的人,不管他们吃不吃药、改不改变生活方式,过半个月,都会出现胆固醇指数降低的现象,这也是一个极端群体在“向均数回归”。
当然,上学考试、胆固醇不是掷骰子,不可能所有人的多次检测都在平均值上下均等地浮动,但是这种统计学规律依然存在。而许多学习辅助工具只挑选成绩最差的学生进行实验、降脂降压药只跟踪血脂血压极端超标的人群,它们所测出的“提高”,很大程度上只是极端人群在自然而然地“向均数回归”。
3、关联关系,不是因果关系
在所有科学实验的伪数据和伪结论中,逻辑关系的判断错误是隐藏最深,却出现频率最高的一个,甚至于许多真正的科学家和社会学家在写论文、著书立说的时候,都会犯这样的错误。
关联关系不能代表因果关系,这句话的意思其实十分好理解:A与B两个变量可能呈现出某种一荣俱荣、一损俱损,或者两者此消彼长的联系,但是仅仅靠这种联系,并不能说明他们之间有因果关系:我们仍旧不知道是A导致了B,还是B导致了A,还是他们谁也没有导致谁,只是受了一些共同因素的影响而呈现出表面的关联。
意思很好懂,但是把表面的关联关系当作因果关系,作为“噱头”的说法,在生活中随处可见:
上过大学的人,比没上过大学的年薪高50%
经常运动的人,幸福指数更高
xxx的用户比同龄人显得更年轻……
薪水拿的多,是因为上了大学,还是上大学的人本身就更聪明、更渴望提升自我?
幸福指数高,是因为经常运动,还是去健身房的人本身就有钱有闲、身体健康?
不难猜出,许多广告中的数字里说的,服用某某保健品,或者实施某种健康/饮食计划的人群寿命比平均水平更长,很可能是因为那些肯花钱去吃保健品、合理膳食和调整生活作息的人,本身就有更好的生活状态:他们经济优裕,营养良好,可能住在更安全、安静的高端社区,不会从事高危的劳动工种,不用受奔波劳累熬夜之苦,有条件旅游、放松,并且比普通人更注重保养、关注自己的健康。endprint
这样的人,本身就比平均水平活得长。
同样地,“从某校走出了近三十位英国首相”,也实在说不清到底是学校的教育成果,还是那些学生们本来就将成为政治精英,而某校只是挑選了他们入学。
壹读君也可以说,本文的读者智商水平比未读过的人高20%。难道是这篇文章骤然提高了读者的智力?当然不是。更可能地,是只有智有余力的人才会点开并且详读这篇推送。本文只是选择了一批高智商的读者,并没有带给读者的智商以任何改变。
与之同理,大多数昂贵的保健品,只是通过市场定位和营销手段选择了高收入人群作为自己的用户,而非真正给这批用户带来了任何提升。它们只是选择了优秀的样本,而并没有把随机样本变得优秀。
4、偏心的实验
前面所说的三种错误推导的共性,是仅仅通过观察得出结论,而没有控制变量、进行对比试验,导致不可控因素太多、结论完全不可信。
不过即使是由实验室对比验证过的“科学数字”,其中也可能掺杂着猫腻:只要稍微调整一下实验环境,几乎就能得到自己想要的任何结果。
70%的用户在同类产品中更喜欢本品牌;
产品盲测中,xx品牌被75%的用户选中;
听起来是不是都无比熟悉?这些数字,其实都很好做到。
比如说,大多数广告没有透露实验人群的选择标准。在百事大楼里采访纯果乐(百事出品)和果粒橙(可口可乐出品)的青睐度,在汉堡店测试炸鸡和寿司的喜爱度,以及在政协食堂调查民意,都可以严重地将结果的天平往一方倾斜。
实验人员还可以巧妙地调控实验环境,譬如在炎热的海滩,将自己品牌的冰镇果汁与其他品牌的常温果汁放在一起,显然自己的将更受欢迎。
乃至于到了实验结果的统计阶段,依然可以挑挑拣拣:还举可口可乐vs百事可乐的例子,在大部分人盲测时分不出区别的情况下,合理的结果应该在50比50左右。倘若有100个人参加实验,那么统计学上的随机谬误最多导致48比52的误差,可是如果一共只调查五个人,那么喜好的倾向最少就是60比40、甚至可能制造出80比20这样的悬殊差距啊!
在自己品牌的支持度随机占上风的时候使调查戛然停止,是一个十分有效的控制结果的手段——反正看广告的人也不会关心它们的取样范围到底有多大。
糖丸效应、向均数回归、逻辑错误和偏向性实验,给出的都看似是货真价实的数字,但也是千真万确的伪科学。所以千万不要掉以轻心!生活从来就是一道随时出现的思考题。
参考资料
1. Booth C (2005). "The rod of Aesculapios: John Haygarth (1740-1827) and Perkins' metallic tractors". Journal of medical biography. 13 (3): 155–161
2. Galton, F (1889). Natural Inheritance. London: Macmillan
3. Marcovina SM, Gaur VP, Albers JA (1994). Biological variability of cholesterol, triglyceride, low- and high-density lipoprotein cholesterol, lipoprotein(a), and apolipoproteins A-I and B. Clinical Chemistry. 40:574–78.
4. Franz H. Messerli, M.D. (2012). “Chocolate Consumption, Cognitive Function, and Nobel Laureates” New England Journal of Medicine. 367:1562-1564endprint
猜你喜欢
海外文摘·文学版(2022年4期)2022-04-14
科技研究(2021年8期)2021-09-10
作文周刊·八年级版(2020年20期)2020-10-27
作文成功之路·教育前言(2019年7期)2019-08-27
作文周刊·高一版(2019年11期)2019-04-29
小溪流(画刊)(2017年5期)2017-06-15
幼儿教育·父母孩子版(2017年4期)2017-06-13
故事大王(2016年4期)2016-05-14
红领巾·成长(2015年12期)2015-09-10
少儿科学周刊·少年版(2015年4期)2015-07-07
