
基于GPU的多尺度Retinex图像增强算法实现
2017-06-28 15:09李辉解维浩刘寿生盖颖颖
山东科学 2017年3期
李辉,解维浩,刘寿生,盖颖颖
(山东省科学院海洋仪器仪表研究所,山东 青岛 266001)
基于GPU的多尺度Retinex图像增强算法实现
李辉,解维浩,刘寿生,盖颖颖
(山东省科学院海洋仪器仪表研究所,山东 青岛 266001)
为提高多尺度Retinex算法的实时性,本文提出了基于GPU的多尺度Retinex图像增强算法,通过对算法进行数据分析和并行性挖掘,将高斯滤波、卷积和对数差分等计算量非常耗时的模块放到GPU中,利用大规模并行线程处理来提高效率。在GeForce GTX 480和CUDA 5.5中进行实验,结果表明该算法能显著提高计算速度,且随着图像分辨率的增加,最大加速比达160倍。
图像增强;多尺度Retinex;GPU;CUDA;并行计算
图像增强是指通过一定的技术有选择地突出图像中感兴趣的特征,抑制或掩盖某些不需要的特征,从而增强图像中的有用信息,改善图像的视觉效果。图像增强的方法主要有两大类:频率域法和空间域法,常见的增强技术主要有直方图均衡化、小波变换以及同态滤波等[1-3]。由于这些方法在应用中的局限性,使得增强效果有限。直方图均衡化会合并灰度值出现概率较小的像素,导致图像细节丢失而使局部模糊;小波变换缺乏平移不变性,会产生Gibbs失真效果,且对于亮度不足或非均匀的图像处理效果一般;同态滤波缺乏自适应性,并且前提是假设光照均匀,对于存在暗区和高光区的夜间图像处理效果差。
多尺度Retinex算法同时保持图像的高保真度和对图像的动态范围进行压缩,增强效果好。该算法采用卷积进行大量运算来实现动态范围压缩和颜色/亮度再现,但由于算法的卷积、对数差分等操作计算数据量大、处理时间长,很难在对实时性要求较高的视频实时处理等场合中应用。因此,必须有效减少该算法的处理时间,以满足更多实时性应用场景的需求。
近年来,图形处理器(graphics processing unit,GPU)被应用于大规模计算,其多线程以及多核心处理器特别适用于数据的并行化计算[4]。CUDA(compute unified device architecture)架构使用SIMT(single-instruction-thread, multi-thread)模型,是一个可以用来实现细粒度的并行性的软件平台,利用CUDA编写的程序灵活而高效。本文提出了一种基于GPU CUDA的多尺度Retinex算法,该算法利用大规模并行线程和GPU的异构存储器层次结构来提高算法的执行效率。
1 Retinex理论与多尺度Retinex图像增强算法
Retinex算法的产生与发展是基于Land[5]提出的颜色恒常知觉的计算理论,其构成是retina(视网膜)和cortex(皮层)。Retinex是消除环境光干扰的一种有效方法,并且已经被用来作为一个预处理步骤应用在许多图像和视频应用中,如视频压缩、高动态范围成像以及人脸识别等。Retinex是一种非线性机制,可以通过模拟人类颜色感知来实现颜色的恒常性,可以适应不同的光线条件并提高感知的图像的视觉质量。Land首次提出了一个人类视觉感知的亮度和颜色模型,Retinex模型[6]是以照度反射成像模型为基础的,相比反射光,照射光的变化更为平滑,因此可以使用低通滤波对输入图像进行模糊运算来估计;反射光的计算则通过输入图像与平滑图像的相除来进行。
Retinex理论[7]的基本思想是通过去除或降低亮度图像的影响,保留物体的反射图像特征。根据Land提出的Retinex模型,将一幅图像定义为L(x,y):
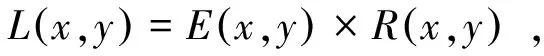
(1)
式中,E(x,y)表示亮度图像,R(x,y)是指物体的反射图像,与照射光无关,它包含了物体的细节特征。
Retinex算法分为单尺度Retinex(single-scale retinex, SSR)、多尺度Retinex(multi-scale retinex, MSR)和带彩色恢复的多尺度Retinex算法(multi-scale retinex with color restoration, MSRCR)。本文采用多尺度Retinex图像增强算法,设原始图像为I(x,y),反射图像为R(x,y),F(x,y)为低通卷积函数,W为权值,该算法可用下式描述:
(2)
其中,*表示卷积运算,环境函数F(x,y)可以表示为:
(3)
即高斯滤波函数,其中K是常量值,该值是通过实验来确定的。
基于多尺度Retinex理论,设置每个尺度的权值为1/3,通过在原图像中去除亮度图像即光源亮度的影响,得到对物体反射光线颜色的本质描述,以增强夜间图像。
2 基于GPU CUDA的MSR并行实现
2.1 CUDA简介
CUDA是由NVIDIA[8]提出的通用并行计算架构,该架构通过利用GPU的处理能力,可大幅提升计算性能。
在GPU CUDA硬件体系结构中,一个GPU内有许多SM(streaming multiprocessor),类似CPU的核,一个SM配备若干个SP(streaming processor)。SP,即CUDA核,是CUDA最基本的处理单元,具体的指令和任务都是在SP上处理的。GPU进行并行计算,也就是多个SP的并行处理。
GPU中的每个SM都支持数以百计的线程并行执行,并且每个GPU都包含了很多的SM,所以GPU支持成百上千的线程并行执行。当一个CUDA核(Kernel)启动后,线程(Thread)会被分配到这些SM中执行。大量的线程可能会被分配到不同的SM,同一个线程块(Block)中的所有线程在同一个SM中并行执行。每个线程拥有自己的程序计数器和状态寄存器,并且用该线程自己的数据执行指令,这就是所谓的SIMT[9]。
2.2 CUDA线程模型
GPU中的线程是以网格(Grid)的方式进行组织的,每个网格包含若干个线程块,而每个线程块由若干个线程组成,线程是CUDA中的基本执行单元,线程块的结构可以是一维、二维或三维。同一线程块中的线程具有相同的指令地址,不仅能够并行执行,而且能够通过共享存储器(Shared Memory)和栅栏(Barrier)实现块内通信。如图1所示为CUDA内存访问模型。
使用CUDA进行编写的代码既适用于主机处理器(CPU),也适用于设备处理器(GPU)[10]。主机处理器负责派生出运行在GPU设备处理器上的多线程任务(CUDA称其为内核程序),当这些任务有足够的并行度时,随着GPU中SM的增加,程序的运算速度就会提升。图2所示为CUDA线程模型。
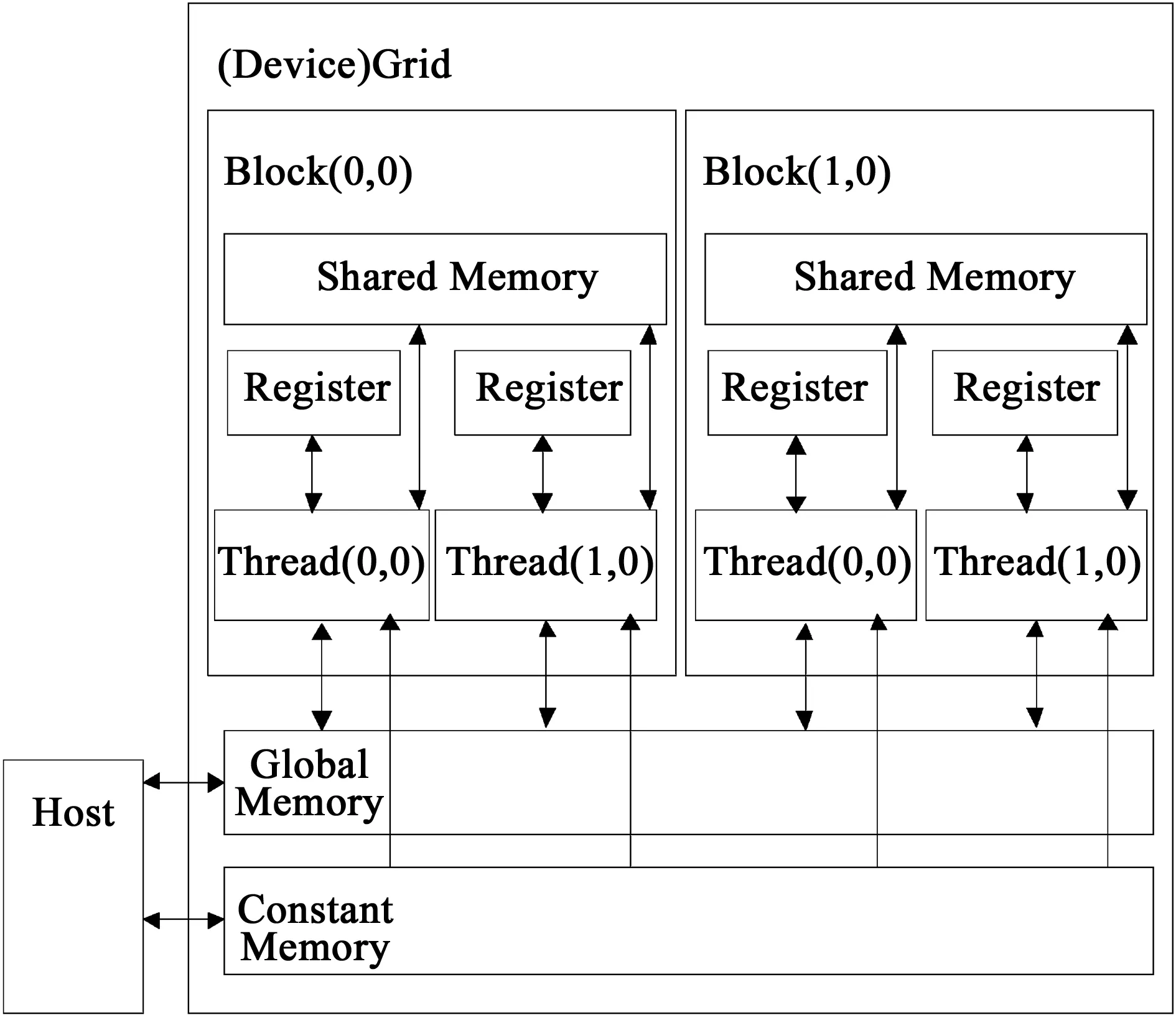
图1 CUDA内存访问模型Fig.1 CUDA memory access model
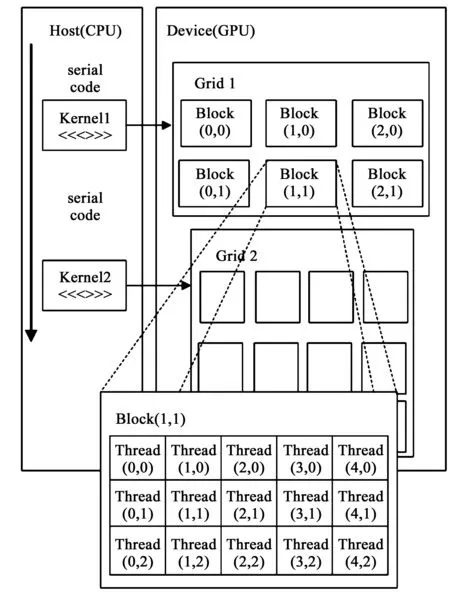
图2 CUDA线程模型Fig.2 CUDA thread model
2.3 CUDA编程模型
由于多尺度Retinex算法在对输入图像进行处理时,图像的R、G、B分量在进行高斯滤波、卷积和对数空间差分等操作时是单独计算的,各数据之间相互独立,符合CUDA的SIMT特性,因此可以进行高性能并行处理。
在进行CUDA编程时,通常将程序分为两个部分:主机(Host)端和设备(Device)端[11-12]。Host端是指在CPU上执行的部分,是串行代码;而Device端则是在GPU上执行的部分,是并行代码。Device端的程序又称为"Kernel",Kernel产生的所有线程成为Grid。在CUDA中,Host和Device有不同的内存空间。
基于CUDA架构编写的程序在主机端和设备端协同进行,其中主机端是指在CPU上执行的部分,是串行代码;而设备端则是在GPU上执行的部分,是并行代码。在实现MSR算法的CUDA编程时,应尽可能增加数据的并行化,减少主机端和设备端的数据相互拷贝,从而充分发挥GPU的运算优势。因此,本文中输入图像数据的读取、主机端与设备端内存空间的分配与回收以及主机端与设备端的数据传输均在主机端处理。其余整个算法的执行流程均在设备端执行,主要有高斯滤波、图像边缘扩展、卷积和对数空间差分4个内核函数。
2.4 MSR并行实现
为了提高并行化执行效率,该算法为每个像素单独分配一个线程进行处理,并采用Shared Memory缓存卷积算子。由于CUDA的Warp大小都是32,为了充分利用每一个Thread的计算能力,每个线程块中的线程数目最好是32的倍数。本文采用一维分配的方式,为每个线程块分配了256个线程,并根据图像的维度确定线程块的数量。其中,高斯滤波确定线程块时依赖于卷积模板窗口的大小,经过实验测试,本文取卷积模板窗口大小为11,因此线程块取值确定如下:
gridSize1= (11*11+256-1)/256 。
在CUDA核中执行的高斯滤波函数为:
generateGaussFactor_kernel<<
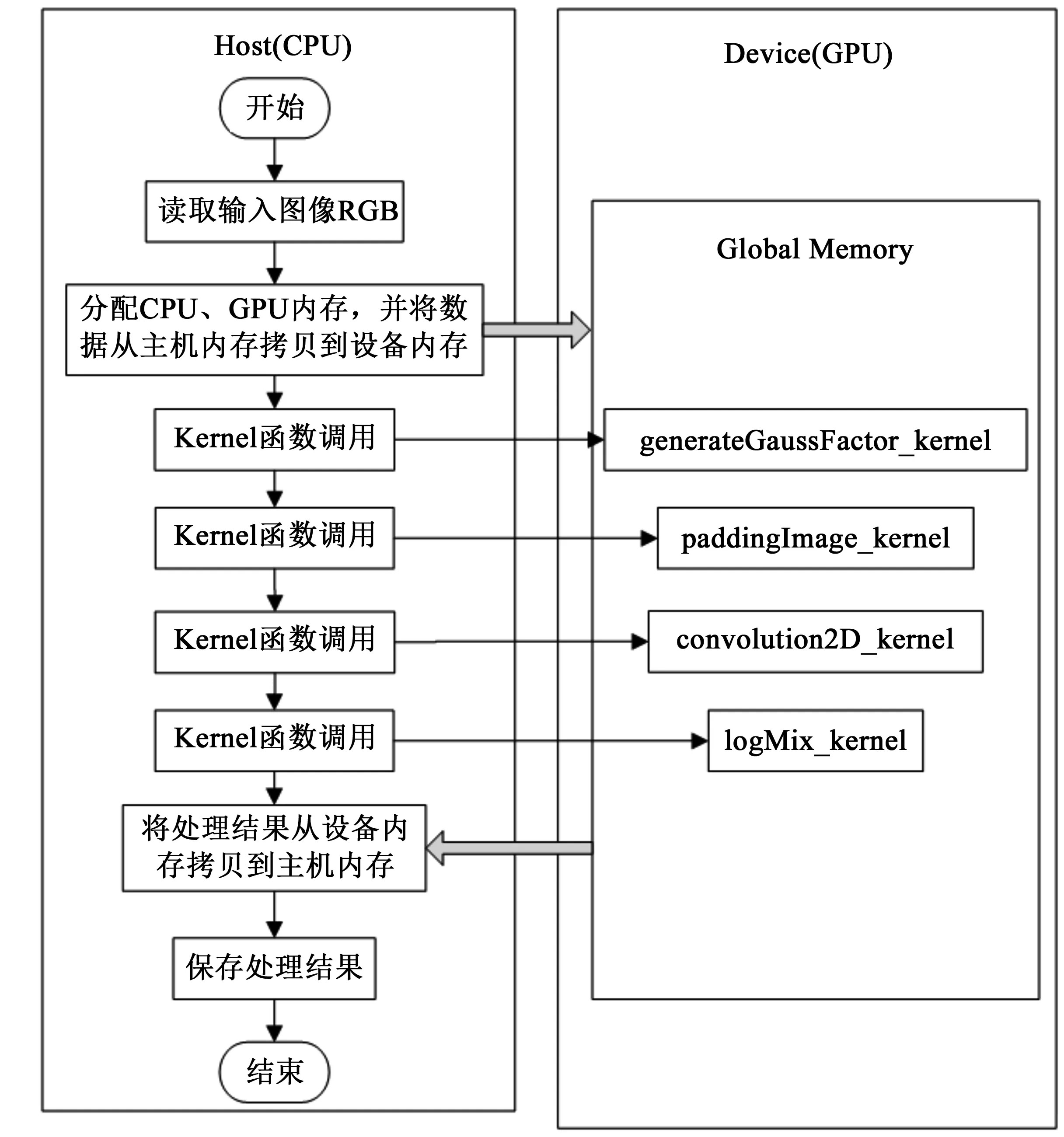
图3 Retinex算法流程图Fig.3 Flow chart of Retinex algorithm
边缘扩展运算中,扩展后的图像高度和宽度设置如下:
height_padding = ImgHeight + 2*(int)(11/2);
width_padding = ImgWidth+ 2*(int)(11/2);
因此,线程块取值确定如下:
gridSize2=((height_padding*width_padding+256-1)/256) 。
在CUDA核中执行的边缘扩展函数为:
paddingImage_kernel<<
卷积计算及对数差分运算中,线程块取值确定如下:
gridSize3= (ImgHeight*ImgWidth+256-1)/256
在CUDA核中执行的卷积函数和对数差分函数为:
convolution2D_kernel<<
logMix<<
整个算法的流程如图3所示。
3 实验仿真与分析
本次实验采用GeForce GTX 480[13]以及CUDA5.5进行性能测试,其中CPU为2.66 GHz、2.67 GHz的酷睿双核,GeForce GTX 480则有480个SP,1 536 M的显存容量,计算能力为2.02TFLOPs。本次实验中,我们选取夜间图像以及逆光图像进行了增强效果测试,同时选取不同图像分辨率的图像,对256×256到2 048×2 048的M×M的图像进行了计算速度的测试,并与相应的CPU算法的执行速度进行了比较。
本次实验总共采集了400张图像进行了测试,其中200张夜间图像,200张逆光图像,MSR算法的CPU实现与GPU实现的图像增强效果如图4所示。
实验结果显示,该算法改善了图像的视觉效果,增强效果明显。图4中a,d为两张原始图像,其中a图像为夜间图像,由于夜间图像的对比度和信噪比都比较低,导致图像的视觉效果较差;d图像为逆光图像,在高对比度下导致图像偏暗,可视化效果差。b,e为CPU实现的多尺度Retinex算法增强后的图像,c,f为GPU实现的多尺度Retinex算法增强后的图像。增强后整个图像的可见性增强,亮度和对比度得到提升,细节部分更加突出,且具有很好的保真度。其中,该算法基于CPU与GPU的实现在增强效果上表现一致,但在算法的处理速度上得到了明显的提升。

图4 Retinex算法增强效果图Fig.4 Images of Retinex algorithm enhanced
为对算法的计算速度进行测试,本实验采用了Intel VTune。通过多次测试不同尺寸图像的计算速度,进而取平均值的方式得到算法最终的处理速度,如表1、表2所示。
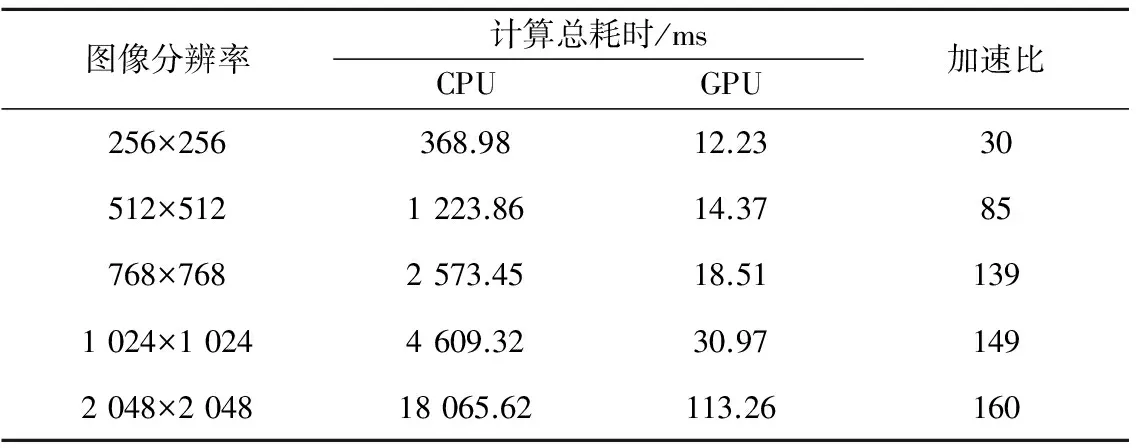
表1 不同图像分辨率总计算时间对比
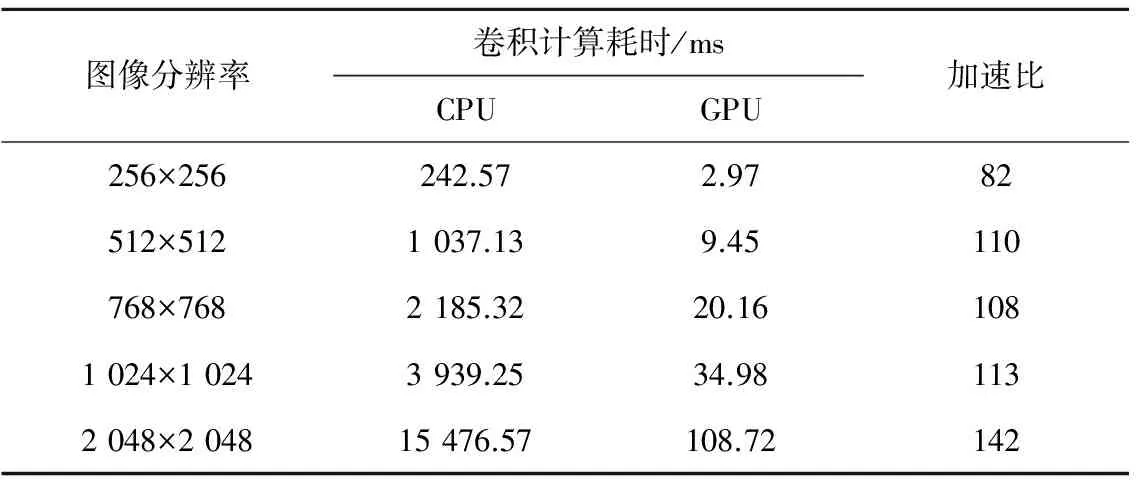
表2 不同图像分辨率卷积计算时间对比
表1表示不同图像分辨率下,CPU和GPU实现的总计算时间的对比;表2表示不同图像分辨率下,CPU和GPU实现的卷积计算时间的对比。通过表1、表2可以看出,该算法的瓶颈部分主要为卷积计算,并且当图像分辨率为2 048×2 048时,CPU总计算时间为18 065.62 ms,而卷积的CPU计算时间高达15 476.57 ms。该算法经过GPU加速后,总计算时间仅为113.26 ms,加速比达160倍;卷积部分的计算时间仅为108.72 ms,加速比达142倍,加速效果非常明显。由此我们可以看出,与CPU方式相比,本文提出的基于GPU的多尺度Retinex算法的计算速度得到了明显的提升,并且随着图像尺寸的增大,该算法在计算速度上的优势更加明显。
4 结 语
多尺度Retinex算法在图像增强处理中具有锐化、色彩恒常、颜色高保真度和高动态范围压缩等特性,特别是在处理夜间、云雾等视觉效果较差的图像时,具有明显的增强效果。但由于其计算方法较为复杂,计算数据量较大,导致算法的实时性效果差。本文通过对输入图像数据进行并行性分析与挖掘,将算法中的时间瓶颈部分,如高斯滤波、卷积和对数差分等放到GPU CUDA内核中进行处理,既保证了增强效果,又使得处理速度得到了明显的提升,从而较好地实现了该算法的实时性。后续将通过改进该算法以进一步对其效果和性能进行优化,同时将该算法的GPU实时处理编程模式引入到更多的图像处理算法(如去雾、视频摘要等)中,并进一步应用到智能视频的实时处理中。
[1]尹士畅,喻松林.基于小波变换和直方图均衡的红外图像增强[J].激光与红外,2013,43(2):225-228.
[2]占必超,吴一全,纪守新.基于平稳小波变换和Retinex的红外图像增强方法[J].光学学报,2010,30(10):2788-2793.
[3]李庆忠,刘清.基于小波变换的低照度图像自适应增强算法[J].中国激光,2015,42(2):0209001.
[4]WANG Y K, HUANG W B. A CUDA-enabled parallel algorithm for accelerating retinex [J]. Journal of Real-Time Image Processing, 2014, 9 (3): 407-425.
[5]LAND E H. Recent advances in Retinex theory [M]// Central and Peripheral Mechanisms of Colour Vision. UK : Palgrave Macmillan,1985: 5-17.
[6]刘瑞剑,低能见度条件下图像清晰化处理研究[D].太原: 中北大学, 2008.
[7] LEE C H, SHIH J L, LIEN C C, et al. Adaptive multi-scale retinex for image contrast enhancement [M]// Proceedings of the 2013 International Conference on Signal-Image Technology & Internet-Based Systems. Washington, DC, USA: IEEE Computer Society, 2013: 43-50.
[8]NVIDIA .CUDA [EB/OL]. [2016-04-03]. http://www.nvidia.cn/object/cuda-cn.html.
[9]徐元旭, SIMT线程调度模型分析及优化[D].哈尔滨: 哈尔滨工业大学, 2013.
[10]COOK S.CUDA并行程序设计:GPU编程指南[M].北京: 机械工业出版社,2014: 191-200.
[11] JIAN L H,WANG C,LIU Y, et al. Parallel data mining techniques on Graphics Processing Unit with Compute Unified Device Architecture (CUDA) [J]. The Journal of Supercomputing, 2013, 64 (3): 942-967.
[12] YANG Z Y, ZHU Y T, PU Y. Parallel Image Processing Based on CUDA [M]//Proceedings of the 2008 International Conference on Computer Science and Software Engineering. Washington, DC, USA: IEEE Computer Society, 2008: 198-201.
[13]NVIDA. Geforce GTX 480 Computing Processor Board [EB/OL]. [2016-04-03]. http://www.geforce.com/hardware/desktop-gpus/geforce-gtx-480/specifications.
Realization of multi-scale Retinex image enhancement algorithm based on GPU
LI Hui, XIE Wei-hao, LIU Shou-sheng, GAI Ying-ying
(Institute of Oceanographic Instrumentation, Shandong Academy of Science, Qingdao 266001,China)
∶To improve the real-time performance of the multi-scale Retinex algorithm, a GPU based multi-scale Retinex image enhancement algorithm was proposed in this paper. Through the data analysis and parallel mining of the algorithm, time-consuming modules of the calculation, such as Gauss filter, convolution, and logarithm difference, were implemented in GPU, and the efficiency was improved by using massively parallel processing threads. Experiments were conducted in GeForce GTX 480 and CUDA5.5, and the results showed that the proposed algorithm could significantly improve the computing speed, and with the increasing of the image resolution, the maximum speed up ratio could reach 160 times.
∶image enhancement; multi-scale Retinex; GPU; CUDA; parallel computing
10.3976/j.issn.1002-4026.2017.03.018
2016-08-05
山东省科学院青年科学基金(2014QN032)
李辉(1987—),女,硕士,研究方向为图形图像处理、高性能计算。E-mail:lihuihuidou@163.com
TP391.41
A
1002-4026(2017)03-0103-07
猜你喜欢
燃气涡轮试验与研究(2021年6期)2021-08-01
海洋信息技术与应用(2020年4期)2021-01-18
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
网络安全技术与应用(2020年1期)2020-01-07
中国生物医学工程学报(2019年5期)2019-07-16
北京航空航天大学学报(2017年3期)2017-11-23
环球市场(2017年36期)2017-03-09
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
杭州电子科技大学学报(自然科学版)(2010年5期)2010-01-08
