
开源处理器Rocket的分支预测机制与性能评估
2017-06-27 08:08:46雷思磊
单片机与嵌入式系统应用 2017年6期
雷思磊
(酒泉卫星发射中心,酒泉 735000)
开源处理器Rocket的分支预测机制与性能评估
雷思磊
(酒泉卫星发射中心,酒泉 735000)
Rocket是基于RISC-V指令集架构的开源处理器,具有分支预测功能,其实现了GShare分支预测机制,在分析Rocket处理器分支预测处理过程、分支预测实现原理的基础上,利用模拟器进行了性能测试,并依据测试结果,对Rocket处理器分支预测参数配置给出建议。
Rocket; 分支预测; Chisel
引 言
RISC-V是加州大学伯克利分校(University of California at Berkeley,UCB)设计并发布的一种开源精简指令集架构,其目标是成为指令集架构领域的Linux,应用覆盖IoT(Internet of Things)设备、桌面计算机、高性能计算机等众多领域[1]。RISC-V自2014年正式发布以来,受到了包括谷歌、IBM、Oracle等在内的众多企业,以及包括剑桥大学、苏黎世联邦理工大学、印度理工学院、中国科学院在内的众多知名学府与研究机构的关注和参与,RISC-V的生态环境逐渐完善,众多开源处理器及SoC均采用了RISC-V架构。Rocket就是采用RISC-V指令集的开源处理器,本文研究分析了Rocket处理器中分支预测机制的实现原理,并对其性能进行了测试评估。
1 Rocket处理器简介
Rocket是UCB设计的一款基于RISC-V指令集、5级流水线、单发射顺序执行64位处理器,主要特点有:支持MMU和支持分页虚拟内存,可以移植Linux操作系统;具有兼容IEEE 754-2008标准的FPU;具有分支预测功能,具有BTB(Branch Prediction Buffer)、BHT(Branch History Table)、RAS(Return Address Stack)。
Rocket是采用Chisel(Constructing Hardware in an Scala Embedded Language)编写的,这也是UCB设计的一种开源的硬件编程语言,是Scala语言的领域特定应用,可以充分利用Scala的优势,将面向对象(object orientation)、函数式编程(functional programming)、类型参数化(parameterized types)、类型推断(type inference)等概念引入硬件编程语言,从而提供更加强大的硬件开发能力。Chisel除了开源之外,还有一个优势就是使用Chisel编写的硬件电路,可以通过编译得到对应的Verilog设计,还可以得到对应的C++模拟器。Rocket使用Chisel编写,可以很容易得到对应的软件模拟器[2]。本文对于分支预测机制的性能评估就是使用编译得到的软件模拟器进行实验的。
2 GShare分支预测机制
分支预测是处理器用来提高执行速度的一种机制,其对程序的分支流程进行预测,然后预先读取其中一个分支的指令并解码,从而避免了流水线的空闲等待,也就相应提高了处理器的整体执行速度。但是,一旦分支指令结果出来表明前期分支预测是错误的,那么就必须将已经进入流水线执行的指令和结果全部清除,然后再装入正确的指令重新处理,这样会消耗处理器额外的时钟周期,所以提高分支预测准确率是一项十分重要的工作。分支预测可以分为静态分支预测、动态分支预测。GShare[3]是Scott Mcfarling于1993年提出的一种动态分支预测机制,也是Rocket处理器采用的分支预测机制,包括BTB、BHT两部分。对于一条指令,首先查询BTB,如果命中,表示是分支指令,那么再查询BHT,预测分支是否发生,BHT的内容及预测机制如图1所示。
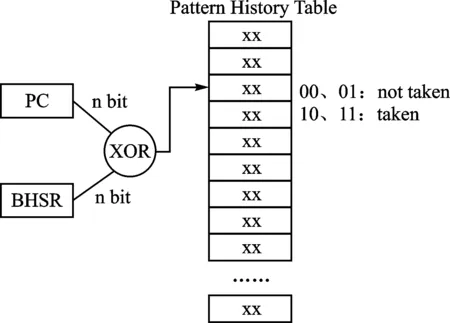
图1 GShare分支预测机制
将分支指令的地址取出n位,与分支历史移位寄存器(BHSR:Branch History Shift Register)的n位进行异或运算,运算结果作为索引,查询模式历史表(PHT:Pattern History Table),PHT中使用的是2位饱和计数器,其状态变化如图2所示。如果查询的结果是00或者01,那么预测分支不发生;如果查询的结果是10或者11,那么预测分支发生。根据分支指令实际运行结果更新BHSR、PHT的相关内容。
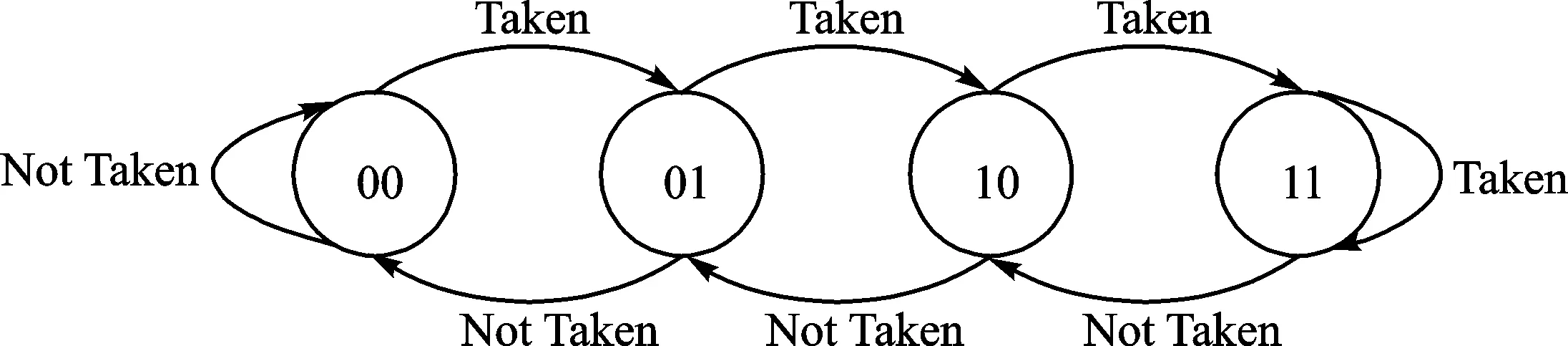
图2 2位饱和计数器
3 Rocket处理器分支预测机制分析
3.1 分支预测机制设计分析
Rocket处理器除了实现BTB、BHT,还实现了RAS,都在BTB Module中实现,BTB Module的接口以及与Rocket Core的连接如图3所示。Rocket处理器主要在流水线的取指、访存两个阶段使用到BTB Module。
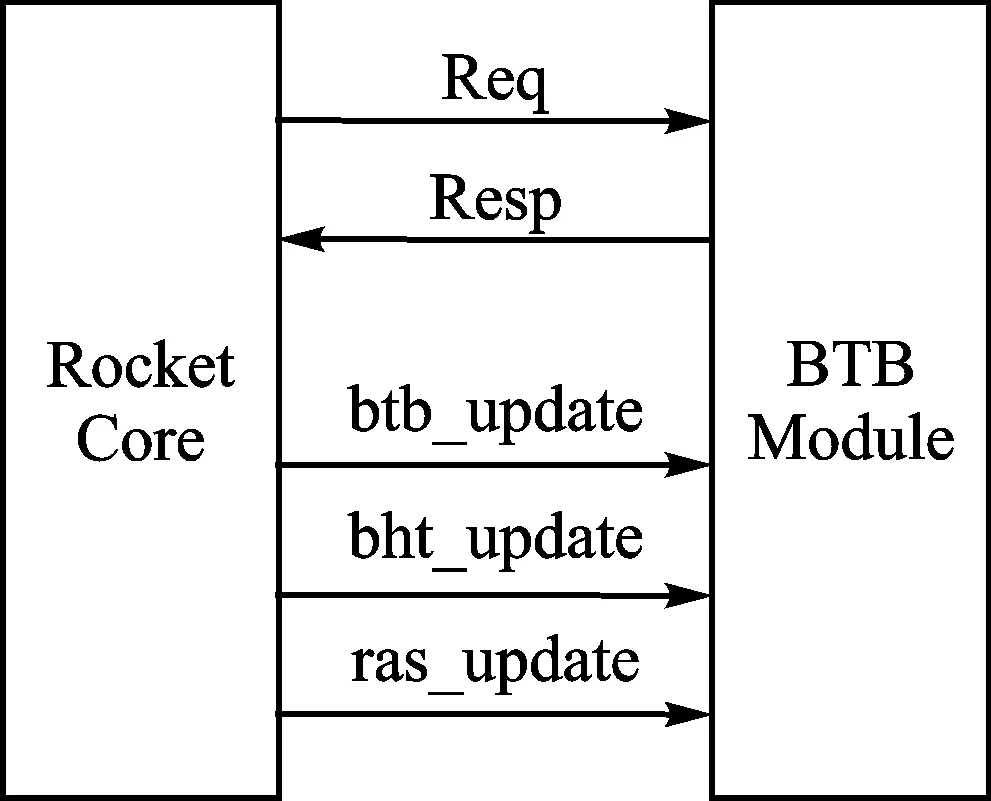
图3 BTB Module与Rocket Core的连接关系
3.1.1 取指阶段
将取指阶段的指令地址通过Req送到BTB Module,后者进行如下判断(如图4所示):
① 查询BTB是否有对应的指令地址,如果有,那么进行下一步骤。
② 如果是返回指令,那么将RAS堆栈顶部的数据返回,作为目标地址,反之,进行下一步骤。
③ 如果是jal、jalr这两条绝对转移指令,那么设置taken为true,表示转移发生,目标地址是BTB查询的结果,反之,进行下一步骤。
④ 按照图1进行查询,依据BHT的查询结果,判断是否发生转移,如果转移,那么设置taken为true,转移目标地址为BTB查询的结果,反之,设置taken为false。无论是否转移,均更新BHT中的BHSR。
⑤ 将上述判断结果通过resp返回给Rocket Core,后者据此决定下一条指令的地址。
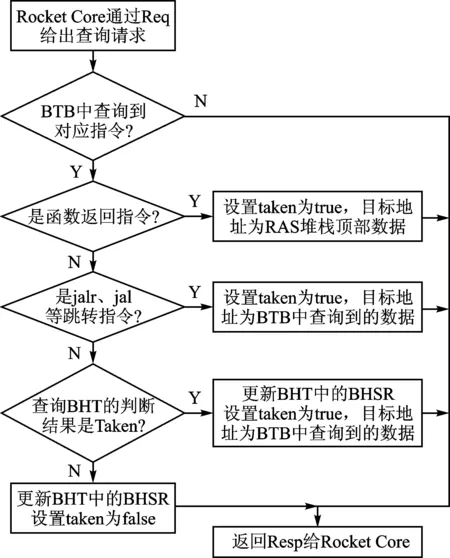
图4 取指阶段BTB Module的处理过程
3.1.2 访存阶段
当分支指令进入访存阶段后,Rocket Core可以判断出前期的分支预测是否正确,从而更新BTB Module中相应的内容,更新消息是通过btb_update、bht_update、ras_update送入BTB Module的,分别代表更新BTB、BHT、RAS。假设分支指令是B,跳转指令是J、返回指令是R,那么可以分为如下几种情况:
① B在取指阶段没有在BTB查询命中,并且实际分支结果是not taken。此时不更新BTB,仅仅更新BHT,即图1中的BHSR,以及对应的模式历史表中的表项,按照图2的2位饱和计数器的状态机进行更新。
② B在取指阶段没有在BTB查询命中,并且实际分支结果是taken。此时更新BTB、BHT,其中BHT的更新内容同情况①,对于BTB而言,需要在其中新增一个表项,其中存储指令B的地址与分支目标地址。
③ B在取指阶段在BTB查询命中,实际分支结果与预测结果不一致,此时更新BTB、BHT,其中BHT的更新内容同情况①,对于BTB而言,需要更新其中存储的指令B对应的目标地址。
④ B在取指阶段在BTB查询命中,实际分支结果与预测结果一致,此时不更新BTB,仅仅更新BHT,更新内容同情况①。
⑤ J在取指阶段没有在BTB查询命中。此时将更新BTB,在其中新增一个表项,将指令J的地址及跳转的目标地址写入该表项,同时将当前指令地址加4,结果存入RAS堆栈顶部。
⑥ J在取指阶段在BTB查询命中,并且目标地址预测正确。此时将当前指令地址加4,结果存入RAS堆栈顶部。
⑦ J在取指阶段在BTB查询命中,但是目标地址预测错误。此时将更新BTB,将其中存储的指令J对应的目标地址更新为新的地址,同时,将当前指令地址加4,结果存入RAS堆栈顶部。
⑧ R在取指阶段没有在BTB查询命中。此时将更新BTB,在其中新增一个表项,将指令R的地址及跳转的目标地址写入该表项。
⑨ R在取指阶段在BTB查询命中,并且目标地址预测正确。此时将RAS堆栈顶部的数据出栈。
⑩ R在取指阶段在BTB查询命中,但是目标地址预测错误。此时将更新BTB,将其中存储的指令R对应的目标地址更新为新的地址。
3.2 BTB Module分析
在BTB Module中实现了BTB、BHT、RAS,其中RAS就是一个简单的堆栈,本文不再单独分析,重点分析BTB、BHT。
3.2.1 BHT分析
通过BHT类实现了BHT,其实现的就是图1所示的GShare分支预测算法,其中重点的方法是get,通过get方法返回预测结果,通过以下片段可以理解GShare的基本过程。
def get(addr: UInt, update: Bool): BHTResp = {
val res = Wire(new BHTResp)
val index = addr(nbhtbits+1, log2Up(coreInstBytes)) ^ history //指令地址的低位与BHSR进行异或
res.value := table(index)
//异或的结果作为查询模式历史表的索引
res.history := history
val taken = res.value(0)
//依据查询结果,判断分支是否taken
when (update) { history :=Cat(taken, history(nbhtbits-1,1)) }
res
}
3.2.2 BTB分析
Rocket通过一系列数组实现了BTB,为了便于分析,假设BTB的表项是64,此时会有如图5所示的一系列数组。以idx开始的数组表示是与分支指令有关,以tgt开始的数组表示是与分支目标地址有关,其含义如下。
idxs:64项,存储的是分支指令地址的第2~11位,实际应该是低12位,但是指令是4字节的,所以最低2位可以忽略。
idxPages:64项,与idxs一一对应,每一项是3位,是一个索引,指向pages数组,后者存储的是分支指令地址的高27位。
idxPagesOH:64项,与idxPages一一对应,每一项是6位,实际就是idxPages中对应数据的one-hot编码,是为了加快查询pages数组的速度而设计的。
idxValid:64项,与idxs一一对应,每一项是1位,表示对应的idxs是否有效。
tgts:64项,存储的是分支目标地址的第2~11位,实际应该是低12位,但是指令是4字节的,所以最低2位可以忽略。
tgtPages:64项,与tgts一一对应,每一项是3位,是一个索引,指向pages数组,其中存储的是分支目标地址的高27位。
tgtPagesOH:64项,与tgtPages一一对应,每一项是6位,实际就是tgtPages中对应数据的one-hot编码,是为了加快查询pages数组的速度而设计的。
pages:6项,存储的是分支指令地址或者分支目标地址的高27位,RISC-V中定义虚拟地址是39位,在idxs中已有低位的10位,此外最低2bit忽略,所以就是27位。
pagesValid:6项,与pages一一对应,表示对应的pages是否有效。
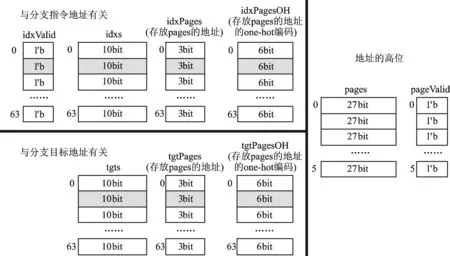
图5 实现BTB的一系列数组
从图5中可以发现,Rocket将地址分为低位、高位两部分,其中高位存储在pages中,并且pages的表项显著小于idxs、tgts,从而减少BTB占用的芯片资源。每次进行BTB查询的时候,首先将分支指令地址的低位与idxs中的表项一一比较,如果有相等项,再通过对应的idxPages表项检索pages数组,进行地址高位的比较,如果也相等,那么表示BTB查询命中,反之,BTB查询没有命中。当BTB查询命中的时候,就可以通过tgts数组得到分支目标地址。
4 Rocket处理器分支预测机制性能评估
4.1 评估环境
Rocket使用Chisel编写,所以可以很容易得到对应的C++模拟器,本文使用得到的C++模拟器,运行RISC-V提供的benchmark,以测试分支预测性能。默认的Rocket编译后并不会输出分支预测有关的信息,需要在rocket.scala添加如下代码:
val counter0 = WideCounter(64, mem_reg_valid && !take_pc_wb && mem_ctrl.branch)
val counter1 = WideCounter(64, mem_reg_valid && !take_pc_wb && mem_ctrl.branch && mem_wrong_npc)
printf("branch inst number[%x] ", counter0)
printf("misprediction branch inst number[%x] ", counter1)
上述代码定义了两个计数器,第一个计数器counter0,当访存阶段是分支指令的时候加1,第二个计数器counter1,当访存阶段是分支指令,且分支预测错误的时候加1,所以,上述两个计数器可以分别输出分支指令数、分支预测错误指令数。
4.2 分支预测机制性能评估
BTB的表项数量不同,会影响分支预测的准确率,分别取BTB的表项为40、60、120,其分支预测效果如图6所示。当BTB的表项为默认的40的时候,最差情况为0.815,最好情况为0.991;当BTB的表项为60的时候,最差情况为0.813,最好情况为0.991;当BTB的表项为120的时候,最差情况为0.819,最好情况为0.992。并且,从图6中可以发现对于一个特定的测试程序,当BTB表项增加的时候,其分支预测准确率相对有所提高。
在实验过程中发现如果BTB表项数目是2的幂,那么分支预测准确率会急剧下降,如图7所示,分别取BTB表项为32、64、128,与BTB表项为40时的分支预测效果对比。原因是由于BTB Module中如下一段代码引起的。
val nextRepl =
if (!isPow2(entries)) {
Counter(r_btb_update.valid && !updateHit, entries)._1 //BTB表项不是2的幂的时候的替换算法
} else {
val plru = new PseudoLRU(entries)
//BTB表项是2的幂时的替换算法
when (hits.orR) { plru.access(OHToUInt(hits)) }
plru.replace
}
其中计算nextRepl的值,如果当前更新的分支指令在BTB中没有查询到,那么就从BTB中找出一个表项,用来存储这个新的分支指令,nextRepl计算的就是这个新的表项的序号。如果BTB的表项是2的幂,那么替换算法是伪最近最少使用算法(PseudoLRU);反之,替换算法就是简单地累加。算法的不同,导致最终效果的差异,建议使用的时候可以避免设置BTB表项的值为2的幂。
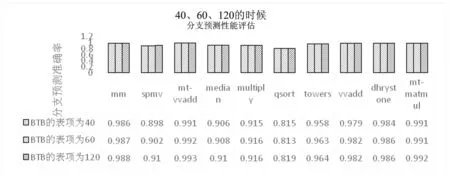
图6 当BTB表项是40、60、120的时候的分支预测效果
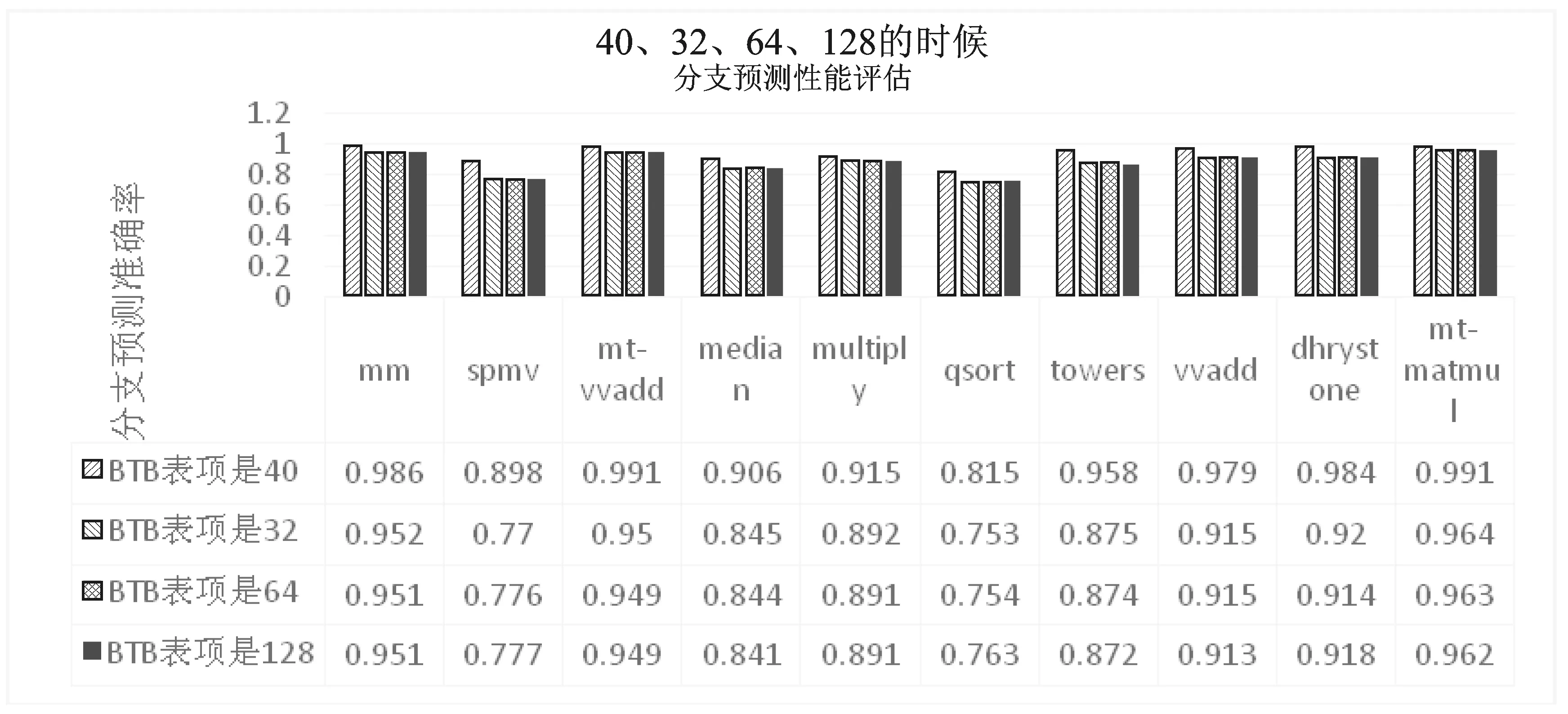
图7 当BTB表项是40、32、64、128的时候的分支预测效果
结 语

[1] VIBU Isa,A Waterman,Y Lee, et al.The RISC-V Instruction Set Manual, Volume I: User-Level ISA, Version 2.1[EB/OL].[2016-12].http://www.atmel.com/Images/doc0856.pdf.
[2] Chisel 2.2 Tutorial[EB/OL].[2016-12].https://chisel.eecs.berkeley.edu/2.2.0/chisel-tutorial. 2016-10.
[3] S McFarling. Combining Branch Predictors, Technical Report TN-36[J].Compaq Western Research Laboratory, 1993, 26(4):176-188.
Performance Evaluation of Branch Prediction Mechanism for Open-source Processor Rocket
Lei Silei
(Jiuquan Satellite Launch Center,Jiuquan 735000,China)
The Rocket is an open-source processor based on RISC-V instruction set architecture,it has branch prediction function,it implements the GShare branch prediction mechanism.In the analysis of the Rocket processor branch prediction process,branch prediction based on the principle of performance,the tests are carried out by the simulator,.According to the test results,the suggestions on the configuration of Rocket processor branch prediction parameters are given.
Rocket;branch prediction;Chisel
TP368.1
A
�迪娜
2016-12-28)
猜你喜欢
科普童话·神秘大侦探(2023年1期)2023-05-30 12:48:10
通信技术(2022年5期)2022-06-11 00:47:44
计算机工程与应用(2020年7期)2020-04-07 10:48:54
学生天地(2019年28期)2019-08-25 08:50:54
测控技术(2018年5期)2018-12-09 09:04:26
电子测试(2018年18期)2018-11-14 02:30:34
数学物理学报(2018年1期)2018-03-26 08:16:36
中南民族大学学报(自然科学版)(2017年3期)2017-10-18 01:04:38
机电信息(2014年27期)2014-02-27 15:53:56
山西大同大学学报(自然科学版)(2014年3期)2014-01-23 01:56:30
