
大数据环境下决策树算法并行化研究
2017-06-22 14:42:01李运娣
河南工程学院学报(自然科学版) 2017年2期
李运娣
(河南工程学院 计算机学院,河南 郑州 451191)
大数据环境下决策树算法并行化研究
李运娣
(河南工程学院 计算机学院,河南 郑州 451191)
决策树算法是数据挖掘中重要的分类算法,但目前多数针对决策树的改进方法都基于传统的串行算法,不能满足大数据环境下对海量数据挖掘的需要.针对大数据集中串行挖掘算法效率低下的问题,采用MapReduce对决策树算法进行了并行化实现,同时引入修正参数来改进ID3算法倾向于多值属性选取的问题.实验结果表明,该算法具有较好的并行性和扩展性,能有效处理大数据集的分类问题.
决策树;MapReduce;大数据;并行化
数据挖掘[1]是知识发现的有效手段,能够让人们获取未知的知识、提升数据的价值.随着网络的普及和大数据时代的到来,数据呈爆炸式增长.与此同时,计算机硬件的提升则相对有限.在大数据环境下,传统的数据挖掘算法的局限越来越明显,很难满足大数据分析的需求.
分类问题是数据挖掘研究的热点问题,目前有很多成熟的分类算法,决策树算法[2]是其中一个经典的算法.基于信息熵的ID3算法是决策树分类模型中最常用的算法,该算法用信息增益作为属性选择的准则,选择信息增益最大属性作为决策树构造的分裂点.ID3算法的不足之处在于基于信息熵的计算方法偏向于特征值数目较多的属性,而此属性往往不是最优的.随着数据量的增加,算法的计算量也快速增加,大大降低了算法的效率,内存驻留问题限制了数据处理的规模.针对这些问题,本课题提出了许多相应的决策树改进方法[3-5],这些方法在一定程度上改善了决策树算法在应用过程中所面临的问题,但无法有效应对海量数据的挖掘问题.
并行机制是海量数据挖掘的一种有效解决方法,也是近年来数据挖掘算法研究的热点.传统的并行方法主要是基于消息传递的如PVM和MPI并行编程模型[6].PVM有较好的负载平衡能力和容错性,而MPI相对简单,在消息传递领域应用广泛.基于消息传递的并行化算法适合处理计算密集型问题,当处理数据密集型问题时,通讯代价快速增加会使系统性能大大降低.传统的方法抽象度较低,需要显式处理一些编程的底层细节问题,这提高了并行程序设计的复杂度.云计算的提出,尤其是MapReduce编程模型[7]的兴起,降低了并行程序设计的难度,又由于数据的分布存储避免了大量数据在网络上的传输,MapReduce更适合大数据环境下海量数据的处理需求[8-9].ID3算法的应用非常广泛,但其并行化研究较少.因此,对MapReduce编程模型进行深入研究,对经典的决策树ID3算法理论进行剖析,利用信息增益计算过程中属性间的相互独立性并基于文件横向分裂的方式进行了ID3算法的MapReduce并行化设计和实现,同时引入了修正参数来改进其倾向于多值属性选取的问题.
1 相关知识
本研究主要对已有的ID3算法运用MapReduce编程模型进行并行化设计和实现,下面对ID3算法和MapReduce并行编程模型进行介绍.
1.1 ID3算法
ID3算法是一个贪心算法,它从根节点开始,采用信息增益作为选择分枝属性的分裂准则,计算各属性的信息增益,然后选择信息增益最大的属性为节点,自顶向下递归构造决策树.ID3决策树构造的相关理论描述如下:
设S是一个含有t个样本的数据集合,Ci(i=1,2, …,n)为S中样本的分类,每个分类Ci中含有的样本数为ti,则S中样本分类所需要的期望信息为
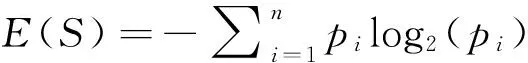
(1)
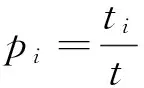
设A为样本集合S的一个属性且有v个不同的取值{a1,a2, …,av},选择属性A对S进行划分,将S分为v个子集{S1,S2, …,Sv},Sj为集合S中属性A的值为aj的样本集合,则基于属性A对集合S进行分类的期望信息为
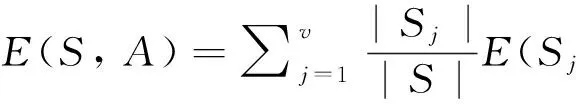
(2)
信息增益为原信息需求与新信息需求之间的差值,则属性A相应于样本集合S的信息增益定义为Gain(S,A)=E(S)-E(S,A),Gain(S,A)越大,说明使用属性A作为测试属性进行分类提供的信息越多,ID3算法就是选择信息增益最大的属性作为当前节点的分裂属性来进行决策树构造的.
1.2 MapReduce并行编程模型
Google公司于2004年最先提出MapReduce技术,它是一种并行编程模型,主要通过大规模服务器集群解决大数据集的并行计算问题.MapReduce一经推出,立即引起了工业界和学术界的广泛关注,它通过接受用户自己编写的Map函数和Reduce函数自动在大规模数据集上并行执行,在系统层面上解决了可扩展性与容错性等问题.MapReduce编程模型采取“分而治之”的思想,先对大数据集进行分割,得到成百上千的小数据块,然后把这些小数据块分配给多个计算节点来共同完成计算任务,计算完成后再把各计算节点得到的结果进行归并,从而得到任务最终的计算结果,具体过程如图1所示.
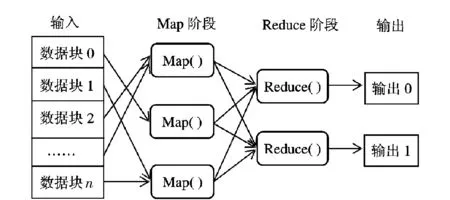
图1 MapReduce的计算过程Fig.1 MapReduce calculation process
MapReduce的并行计算过程主要分为Map和Reduce两个阶段.在Map阶段,Map任务先将输入数据块转换成键/值对,键一般为数据记录文件的行号,值为该行文件对应的内容,然后自定义Map函数对输入键/值对进行处理,产生一系列的中间键/值对缓存在内存中,缓存的中间键/值对定期写入硬盘并记录位置信息,以便下一阶段的处理.在Reduce阶段,对Map阶段产生的中间键/值对进行处理,Reduce函数合并所有具有相同键值的中间键/值对,形成较小的值的集合,Reduce处理后的结果可添加到对应分区的输出文件中.整个文件的最终输出结果可以通过合并所有Reduce处理输出而得到.
MapReduce模型的核心是Map和Reduce函数,使用者只需要关注这两个函数的具体计算任务即可,其他并行模式中的复杂问题如分布式文件系统、工作调度等都是由MapReduce模型后台处理的.由于简洁性、实用性、可扩展性等优点,MapReduce已成为当前最流行的并行数据处理模型,它在大数据集的存储、管理与处理过程中也越来越受到人们的关注.
2 决策树算法的并行化实现
决策树算法中最耗费资源的阶段是最佳分裂属性的选择部分,利用MapReduce对该阶段进行并行化计算会大大提高决策树生成的效率,使之适应大数据处理的需求.在ID3算法中,信息增益的计算是基于属性间相互独立的,可以利用MapReduce并行地计算出信息增益所需的各个属性的相应信息,从而快速选出最佳分裂属性.
2.1 Map阶段的设计
假定样本数据文件按行存储,每行一个记录样本,数据具有内部无关性.Map阶段的任务是读取样本数据文件,然后按需要对每个记录进行解析.信息增益的计算需要统计训练数据集属于每类的元组数及每类中每个属性的各属性值的元组数,所以Map函数的输入为以记录形式存储的训练数据集,输出key设计为所属类别或所属类别、属性名、属性值,value的值为1.Map函数伪代码如下:
Map(key,value)
Input:训练数据集S
Output:
Begin
fori=1 tondo
提取所属类别和每个属性的属性值
key=所属类别,value=1,输出
对每个属性值do
key=<所属类别,属性名,属性值>,value=1, 输出
end do
end for
end
2.2 Reduce阶段的设计
Reduce阶段的任务比较单一,主要是对Map阶段输出的
Reduce(key,value)
Input: Map函数生成的
Output:
Begin
对所有相同的key值do
累计计数其value值,结果保存到sum
end do
key′=key,value′=sum
输出
end
2.3 并行执行ID3算法
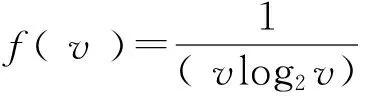
引入修正参数后,修正的信息增益表示为Gain′(S, A)=f(v)Gain(S, A).将Gain′(S, A)作为新的属性选择判断标准,属性的取值个数越多,f(v)越小,减少了ID3算法属性选择时倾向于多值属性的问题.利用MapReduce对决策树算法中最耗费资源的最佳分裂属性的选择部分进行并行化计算,以提高决策树的生成效率,使之适应大数据处理的需求,改进后的ID3算法执行步骤描述如下:
Generate_Decision_Tree
输入:训练数据集S,候选属性集C
输出:一棵决策树
(1)创建一个节点N;
(2)如果S中样本都为同一个类别C,则返回N作为树中一个叶子节点,将其类别标为C;
(3)如果C为空,则返回N作为树的叶节点,将其类别标为S中样本出现次数最多的类别;
(4)对S中的数据样本进行MapReduce操作,根据各个Reduce节点返回的统计输出结果,计算并找出最大修正信息增益属性,以此属性作为分裂属性;
(5)用分裂属性所对应的每一个属性值ai来划分S,假设Si是S中相应属性值为ai的元组的集合;
(6)对当前节点N所长出的满足分裂属性的属性值为ai的树的分支Si;
(7)如果Si为空,则为决策树增加一个新的叶节点,类别为S中的多数类;
(8)否则,增加一个由Generate_DecisionTree( Si, 候选属性集)所返回的新节点.
3 实验
本实验主要验证决策树算法并行化后具有高效性和可扩展性,以适应海量数据处理的需求,实验数据来自UCI数据集.算法基于Hadoop平台,实现了该方法的MapReduce化,实验所用集群由7台PC机组成.其中,1台为Master节点,另外6台为Slave节点.为了方便对比,同时进行了单机决策树ID3算法和MPI环境下的并行ID3算法.
首先,对串行算法、基于MPI并行化方法与本研究中基于MapReduce并行化方法在处理相同数据规模时所需要的时间进行了对比,结果如图2所示.从图2可以看出,当数据规模较小时,集群与单机计算时间相差不大,当数据规模增加时,单机随着数据规模的增加而快速增长,数据规模越大,这种增长趋势越明显,达到一定程度时会由于机器内存不足而使程序无法正常运行,而集群则始终平稳运行.随着数据规模的增加,集群的优势较明显,计算时间增加平稳,各个节点的资源消耗波动较小,系统显示了良好的可扩展性.同时,由于MPI方法的通信开销较大,在相同情况下基于MPI并行化的决策树ID3算法的性能要低于基于MapReduce并行化算法.
为了考查集群规模对数据处理的影响,对本算法在不同节点数量的集群上进行了实验,结果如图3所示.从图3可知,集群规模与数据处理能力密切相关,随着节点数量的增加,处理相同规模的数据所需的运行时间越短,特别是随着数据规模的增加,这种趋势越来越明显.
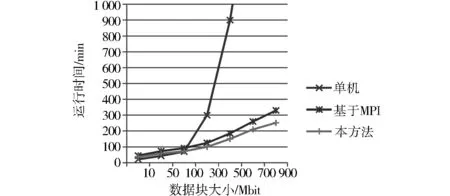
图2 不同数据量下3种方法运行时间比较Fig.2 Comparison of three methods’ runtimefor different data sizes
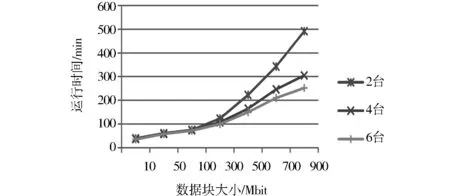
图3 集群对比Fig.3 Cluster comparison
4 结语
决策树算法是数据挖掘中重要的分类算法,ID3是决策树算法中的经典算法,但它存在偏袒属性值数目较多这一缺点,而且传统的并行算法不能满足大数据环境下对海量数据处理的需求.针对上述问题,引入了修正参数来解决ID3算法倾向于多值属性选取的问题,然后借助当前流行的MapReduce编程模型对决策树ID3算法进行了并行化实现.实验表明,改进后的算法与传统的决策树算法相比具有较大的优势,能够有效地支持海量数据的计算,具有良好的可扩展性,能够满足大数据环境下对大规模数据处理的需求.
[1] HAN J,KAMBER M,PEI J.数据挖掘概念与技术[M].3版.北京:机械工业出版社,2012.
[2] QUILAN J R.Induction of decision trees[J].Machine Learning,1986,1(1):81-106.
[3] 黄爱辉,陈湘涛.决策树ID3算法的改进[J].计算机工程与科学,2009,31(6):109-111.
[4] 冯少荣,肖文俊.基于样本选取的决策树改进算法[J].西南交通大学学报,2009,44(5):643-647.
[5] 黄宇达,范太华.决策树ID3算法的分析与优化[J].计算机工程与设计,2012,33(8):3089-3093.
[6] 任波,王乘.MPI集群通信性能分析[J].计算机工程,2004,30(11):71-73.
[8] 宋杰,郭朝鹏,王智,等.大数据分析的分布式MOLAP技术[J].软件学报,2014,25(4):731-752.
[9] 覃雄派,王会举,杜小勇,等.大数据分析——RDBMS与MapReduce的竞争与共生[J].软件学报,2012,23(1):32-45.
Research on parallelization of decision tree algorithm under big data environment
LI Yundi
(CollegeofComputerScience,HenanUniversityofEngineering,Zhengzhou451191,China)
Decision tree is an important classification algorithm in data mining, but most of the improvement methods for decision tree are based on the traditional serial algorithm, which can’t meet the need of massive data mining under big data environment. For the inefficiency of serial mining algorithm in massive data, MapReduce is used to parallelize the decision tree algorithm. At the same time, the modified parameters are introduced to avoid the ID3 algorithm tending to multi-valued attribute selection problem. The experimental results show that the proposed algorithm has good parallelism and scalability, and can effectively deal with massive data classification problem.
decision tree; MapReduce; big data; parallelization
2017-01-12
河南省高等学校重点科研项目(16A520004)
李运娣(1978-),女,河南鹤壁人,讲师,主要研究方向为分布式系统、图像处理与数据挖掘.
TP311
A
1674-330X(2017)02-0057-05
猜你喜欢
北京航空航天大学学报(2021年6期)2021-07-20 07:23:56
大众投资指南(2021年35期)2021-02-16 01:06:26
电子制作(2019年19期)2019-11-23 08:41:36
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年19期)2018-11-14 02:37:02
电子制作(2018年16期)2018-09-26 03:27:06
电力与能源(2017年6期)2017-05-14 06:19:37
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
信息通信技术(2015年6期)2015-12-26 01:16:46
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
