
魂芯分簇VLIW DSP上指令调度的优化*
2017-06-19 18:50王玉林郑启龙
网络安全与数据管理 2017年11期
王玉林,郑启龙
(1. 中国科学技术大学 计算机科学与技术学院,安徽 合肥 230027;2.中国科学技术大学 安徽省高性能计算重点实验室,安徽 合肥 230027)
魂芯分簇VLIW DSP上指令调度的优化*
王玉林1,2,郑启龙1
(1. 中国科学技术大学 计算机科学与技术学院,安徽 合肥 230027;2.中国科学技术大学 安徽省高性能计算重点实验室,安徽 合肥 230027)
魂芯DSP处理器是一款32 bit静态超标量、分簇结构的、支持SIMD的VLIW处理器。魂芯DSP芯片有4个执行簇和3个内存块,但簇间数据传输和寻址会占用总线带宽。魂芯DSP上每个簇中有大量的计算部件,但是现有的编译器框架中指令调度算法是针对非分簇结构的,无法充分利用魂芯DSP的分簇结构特点,产生出高效的指令级并行代码。根据魂芯处理器架构分簇的特点,提出了在魂芯DSP上进行指令分簇和指令调度的启发式算法,并且在开源Open64编译器框架上进行了实现。实验结果表明,该算法在魂芯DSP编译器上的实现可以显著提高一些在DSP上有着计算密集型程序的性能。
分簇体系DSP;指令级并行;指令分簇;指令调度;Open64编译器
0 引言
魂芯DSP是一款32 bit静态超标量处理器,采用4个执行簇16发射、单指令流多数据流(Single Instruction Multiple-data Stream,SIMD)架构[1]。处理器指令总线宽度为512 bit;内部数据总线采用非对称全双工总线,内部数据读总线位宽为512 bit,内部数据总线位宽为256 bit。该处理器是一款32 bit浮点数字信号处理器(Digital Signal Processor,DSP),采用超长指令字(Very Long Instruction Word,VLIW)架构[2],具有强大的并行处理能力,能较好地满足高速实时信号处理的应用要求。
魂芯DSP芯片具有4个执行簇,每个执行簇都有自己的本地寄存器组和计算单元,指令分簇和调度可以高效利用DSP的硬件并行性并且利用单指令组合成超长指令字产生高质量的代码。对于分簇体系结构,指令调度比原有的正交体系结构调度更难,各个簇间的通信是通过簇内部的数据总线,单周期内只能够从一个簇传值64 bit的数据到另一个簇。本文重点介绍魂芯DSP上的指令分簇和调度算法,并在开源编译基础设施Open64编译器框架上进行了实现。实验效果表明,与原有的非分簇指令调度算法相比该指令分簇和调度算法能够生成更高质量的代码。
1 编译器框架
1.1 魂芯DSP体系结构
魂芯DSP是一款分簇结构、字寻址模式、支持SIMD的16发射的VLIW浮点运算信号处理器[3],片内有3块数据处理器,每块8 MB。主要结构如图1所示。魂芯DSP有4个计算簇,分别是X簇、Y簇、Z簇、T簇,每个计算簇有8个算术逻辑单元(ALU)、4个乘法器(MUL)、2个移位器(SHF)、1个超算单元(SPU)和1个寄存器组。计算簇与计算簇之间通过簇间数据总线通信。有3个地址簇即地址生成器,分别是U簇、V簇、W簇。存储器与计算核之间的数据交换所需要的地址计算由地址生成器提供(AGU地址)。AGU是作用访存地址计算的特殊单元,每个AGU上有独立的地址寄存器文件(address register file)、专用的地址运算器(address calculation ALU)以及内存存储单元(load/store unit)。AGU主要用于普通的地址加减计算,以及load和store指令。
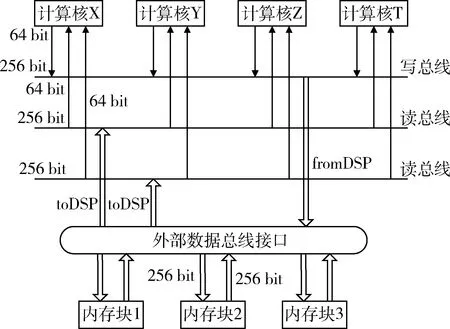
图1 魂芯DSP体系结构
1.2 Open64开源编译器框架
BWDSP编译器采用开源Open64[4]编译器基础设施作为编译器研究框架。Open64是一款GPL协议的工业级开源编译基础设施,以中后端提供的强大的分析优化能力著称。主要架构如图2所示。
采取GCC作为前端,中间语言为抽象语法树ASTtree。高级语言经过前端时,以tree的形式存在,经由gspin(一种从gcc的tree到WHIRL转换的中间表示)的媒介,转换成为WHIRL中间语言。Open64的前端将源程序转化为内部中间表示WHIRL,后端读入WHIRL,经过翻译生成代码生成阶段(Code Generation,CG)的中间表示CGIR,再经过一系列优化,最终CGIR经过代码输出生成汇编程序。

图2 Open64编译器架构
然而Open64编译器框架支持的众多处理器中没有簇的概念。由于魂芯DSP拥有丰富的向量化资源,同时其应用对性能要求极高,因此有必要对魂芯DSP提供分簇支持,在分簇基础上对指令进行调度。本文针对DSP芯片分簇和计算单元堆叠的特点,设计了一种算法,把指令分簇和指令调度耦合为一个过程来进行处理,通过指令调度的反馈来优化指令分簇,进而迭代优化指令调度。
2 指令调度
指令调度是对编译器后端生成的指令的调度,利用可以并行执行的指令充分发挥目标机的性能。所谓指令调度就是从顺序程序中识别出指令级可并行的成分,并利用这些并行性合理安排指令的执行顺序,以达到最大限度地发挥目标机所提供的处理能力的目的。指令调度决定操作执行的相对顺序、各操作的具体执行时间及使用哪些硬件资源等。
现有的一些比较好的局部和全局的调度算法都是针对非分簇体系结构。例如线性调度、基于关键路径的调度[5],以及跟踪调度[6]和渗透调度[7]。这些算法都不是为了分簇体系结构设计的,在利用这些算法前至少需要一个对指令分簇的阶段。然而这些算法在指令分簇的阶段并不能知道后期指令调度中对资源和通信的约束。
2.1 问题定义
DSP上指令调度要解决的问题可以如下阐述:用B来表示一个基本块,可以通过一个数据流图(DFG)G=(V,E,ω)来代表。假设DFG中V表示具体指令,DFG中的边表示指令间的依赖关系,每一条边e的权重ω(e)是一个整数,代表了两条指令间延迟的值。
假定DFG中的节点都还没有绑定到X、Y、Z、T任何一个簇上。
P:V→{X,Y,Z,T}
分簇可定义为选择DFG中的每一个节点应该绑定到X、Y、Z、T中的哪一个簇上,在选定了节点要绑定到哪一个簇的同时,这个节点需要的计算部件FU也就可以在这个簇上绑定到这个节点了。对于一个给定的分簇P,指令调度可以用如下两个映射表示:
F:V→{ALU,MUL,SHF,SPU}
C:V→INs
一个调度是有效的指令调度定义为:对于任意的一个节点v∈V,指令需要的功能部件FUF(v)是在簇P(v)上的,每一个部件FU在一个周期内只能使用一次,并且指令条C不能违反任何内部的指令间依赖关系。也就是说对于任意的节点v的入边都需要满足下面的约束条件:
e1=(μ1,v),…,ek=(μk,v)
指令调度S=(F,C)的长度L(S)定义为控制流执行的最后一步。最后一步的意思是,对于一条指令v的延迟,设为d(v),那么L(S)是其中的执行周期加上指令本身延迟中的最大值。
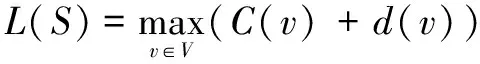
本文的目标是同时计算出一个分簇P和一个有效的并且长度最短的调度(F,C)。
2.2 指令分簇算法
调度算法包括两个相互交互的阶段。在阶段1会产生一个暂时的指令分簇,然后对于给定的分簇信息阶段2可以进行指令调度。调度的代价(指令执行的周期数)作为评价分簇的测量指标,然后基于此反馈,阶段1重新找到一个更好的分簇结果作为阶段2的输入,一直迭代到收敛终止条件。
第一阶段的分簇采用的是模拟退火算法(SA)[8],与其他的遗传算法类似,SA适用于非线性的优化问题,因为它能避免基于评价函数的局部最优化的问题。算法的思想是模拟冷却的过程,从一个初始的结果和初始的阈值开始,每一步迭代中当前的结果被随机地改变,如果更改后的结果更好那就作为当前的最优解,否则就会根据当前的一个随机值决定是否接受这个值作为最优解。在迭代过程中,阈值越来越小,接受不好的值作为最优解的可能性越来越小,算法如下:
algorithm PARTITION
input DFG
outout: P: array[1..N]of {0,1,2,3}
var
int i,j,r,cost,mincost;
Operlist operlist
float T;
begin
T=10; p:=InitalRandomPartitioning();
mincost:=ListSchedule(G,P)
while T>0.01 do
for i=1 to 50 do
r:=Random(1,n)
Pre_clustered:=P[r];
operlist:=getOpnds(r);
P[r]:=getMostOperlistClusterFlag(operlist,m);
cost:=ListSchedule(G,P);
delta:=cost-mincost;
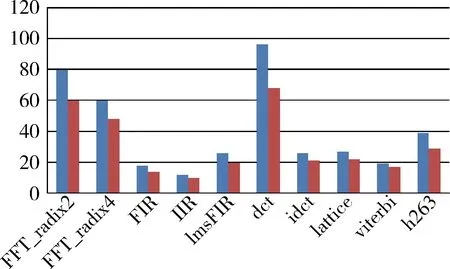
if delta<0 or Random(0,1) then mincost:=cost; else P[r]:=Pre_clustered end if end for T=0.6*T end while return P; end algorithm 2.3 指令调度算法 调度算法的主函数是一个线性的调度算法[9],输入是一个DFG图G和一个分簇过的指令流P。算法是一个拓扑排序问题,首先标记所有的节点指令为未调度的指令。每一个被选择的节点通过函数ScheduleNode加到调度序列中,这个函数是指令调度的核心。最后算法返回调度后的指令周期数。主调度算法代码如下: algorithm ListSchedule input: DFG G, Partitioning P; output: schedule length; var m: DFG node; S: schedule; scheduled[N]; begin for i=0 to N do Scheduled[i]:=false; S:={}; while(not all nodes scheduled) do m:=NextReadyNode(G); S:=ScheduleNode(S,m,P); scheduled[m]:=true; end while return Length(S); end algorithm 子过程ScheduleNode用一些启发式算法来避免增加多余的指令数,因为如果指令需要的被调度到不同的簇上,那么就需要通过增加mov_inter指令,通过簇间总线[10]将需要的操作数从另一个簇拷贝到本簇中。算法的输入是当前的序列S,即将要加入S中的节点m,以及当前的分簇信息P[11]。主要的策略是在不违反资源约束和依赖约束的前提下把指令m尽可能插入到最早可以调度的指令数。开始,以m能最早被调度的周期数作为初始值,然而,如果它的前继节点在调度中是第t个周期,并且这个前继节点的延迟是d,那么m节点不能早于第t+d个周期被调度。测试是否满足约束在子过程EarliestControlStep中。指令m在S中可执行的周期数一直在增加,直到找到一个满足约束条件的有效周期数。单个节点的调度算法如下: algorithm ScheduleNode input: current S, node m, partitioning P; output: updated S containing m; var cs:control step number begin cs:=EarliestControlStep(m)-1; repeat cs:=cs+1; fm:=GetNodeUnit(m,cs,p); if fm={} then continue; if (m has a argument on a different cluster) then CheckArgTransfer(); if(at least one transfer impossible) then continue; else TryScheduleTransfers(); if (BusConfict(cs,m)) then continue; until (m has been scheduled) if (m is a load instruction) then ScheduleAddrLoadPath(m); end if return S; end algorithm 对于一个给定的周期数cs,GetNodeUnit寻找一个能执行m指令的功能单元fm,且此功能部件fm在簇P(m)上第cs周期是可用的。对于魂芯DSP上的大部分指令,优先SHF来执行,SHF无空闲的情况下,可以通过ALU或者MUL来执行。当然,因为每个簇中有2个SHF、4个MUL、8个ALU,当有多个FU满足条件时,随机选择一个部件绑定到指令m上。 在提出了基于魂系DSP体系结构的指令分簇和调度算法[12]后,为了测试效果,选取了DSP经典的测试集来测试编译器性能,测试了原有的Open64中指令调度算法[13]和本文提出的调度算法对同一个程序编译后执行的周期数。在 ECS(Effective Coding Studio)统计程序执行的周期数,优化指令调度前后程序的周期数如图3所示。没有考虑寄存器分配的影响,是因为寄存器分配是在指令调度之前,所生成的DFG是一样的,而且魂芯DSP每个簇中有64个通用寄存器,所以寄存器溢出并不是一个关键因素,不同的只是最后的指令调度阶段。至此,基于开源编译器框架Open64完成了针对魂芯DSP上指令分簇和指令调度的优化,加速了程序的执行。 图3 DSP代码的性能对比 图3中的左边柱条是指令优化前的实验结果,右边的柱条是优化后的指令调度算法的结果。实验结果表明,程序性能提高了11%(irr)~41%(dct),对于计算密集型程序且关键路径节点较少的dct程序来说优化效果最好,程序的限制因素是资源部件的约束,而对于程序中关键路径节点较多的程序iir来说,指令调度并不能带来多高的程序性能的提高。 最后,要说明一下本文提出算法的运行时开销。原有的Open64的汇编优化使用的是纯启发式的分簇和调度算法,开销比较小。也就是说,SA算法对于大的优化问题有较大的运行时开销。然而,在本文提出的算法中,只是用SA算法进行分簇,指令调度还是用的启发式算法[14]。这种桥接模式可以在可接受的时间内调度较多DFGs节点的程序,而且在嵌入式系统中,代码质量要远远高于对编译速度的考量,所以这点运行时开销是可接受的。 本文针对魂芯DSP高性能处理芯片,利用其分簇特点和VLIW特点,提出了针对魂芯DSP上指令分簇和指令调度的算法。基于开源的Open64编译器,对算法进行了实现,实验结果表明算法进一步优化了魂芯DSP程序的代码质量,充分利用了魂芯DSP 4个簇和功能部件,缩短了程序指令的指令周期。对于这种分簇结构的处理器,一般是先进行分簇之后再进行指令调度。本文提出的算法基本上与机器是独立的,算法把指令分簇和指令调度结合起来,相比原有两遍单独的优化,取得了更好的优化效果。 未来的工作是,考虑如何把寄存器分配和全局指令调度考虑进来。目前的调度是基于基本块的,但是块与块之间全局的调度也有很大的优化空间。 [1] 张为华, 朱嘉华, 张宏江, 等.基于位宽控制提高架构并行度的优化算法[J].计算机学报, 2009, 32(11):2168-2176. [2] FISHER J A, FARABOSCHI P, YOUNG C. Embedded computing: a VLIW approach to architecture, compilers and tools[M].北京:机械工业出版社, 2006. [3] CETC38.BWDSP100 hardware user manual[Z]. Hefei:China Electronics Technology Group Corporation No.38 Research Institute, 2011. [4] 高伟, 李骁, 赵博.源源翻译流程研究[J].信息工程大学学报, 2013, 14(5):612-618. [5] AIKEN A, NICOLAU A.A development environment for horizontal microcode[J].IEEE Transactions on Software Engineering, 1988, 14(5):584-594. [6] 中国电子科技集团第三十八研究所.软件用户手册[Z]. 2011:181-191. [7] DAVIDSON S, LANDSKOV D, SHRIVER B D, et al.Some experiments in local microcode compaction for horizontal machines[J].IEEE Transactions on Computers, 1981, 100(7):460-477. [8] CHENG G, LAM M. An optimizer for multimedia instruction sets[R]. Proceedings of the 2nd SUIF Compiler Workshop. Stanford University, 1997. [9] FERNANDES M M, LLOSA J, TOPHAM N.Partitioned schedules for clustered vliw architectures[C].Parallel Processing Symposium, 1998. IPPS/SPDP 1998. IEEE, 1998: 386-391. [10] LARSEN S, AMARASINGHE S .Exploiting supeword level parallelism with multimedia instruction sets[J].ACM SIGPLAN Notices, 2000, 35(5):145-156. [12] 黄胜兵,郑启龙,郭连伟. 分簇VLIW DSP上支持单双字模式选择的SIMD编译优化[J]. 计算机应用,2015,35(8):2371-2374. [13] HU E W, KU C, RUSSO A, et al.New DSP benchmark based on Selectable Mode Vocoder (SMV)[C].CDES, 2006: 175-181. [14] 王向前,洪一,王昊,等. 魂芯DSP的编译器设计与优化[J]. 电子学报,2015,43(8):1656-1661. Instruction scheduling optimization for clustered VLIW BWDSP Wang Yulin1,2, Zheng Qilong1 (1. School of Computer Science and Technology, University of Science and Technology of China, Hefei 230027, China;2. Anhui High Performance Computing Key Laboratory, University of Science and Technology of China, Hefei 230027, China) BWDSP is a 32 bit static scalar digital signal processor which supports clustering and SIMD features. The BWDSP chip has four execution clusters and three memory blocks, but the inter-cluster data transmission and addressing will occupy the bus bandwidth. There are a large number of computing components in each cluster of the core BWDSP, but the instruction scheduling algorithm in the existing compiler framework is for non-clustered structure, and can not make full use of the clustering structure characteristic of the core BWDSP to produce efficient instruction level parallelism(IPL). According to the characteristics of the core processor architecture, a heuristic algorithm for instruction clustering and instruction scheduling on the BWDSP core is proposed to improve the instruction level parallelism. The framework is implemented on traditional Open64 compiler framework. Experimental results show that the implementation of the instructions can meet the requirements of the circumstances and the proposed technique is capable of generating more efficient code. multi-cluster DSP; ILP; instruction partitioning; instruction scheduling; Open64 compiler “核高基”重大专项(2012ZX01034-001-001) TP314 A 10.19358/j.issn.1674- 7720.2017.11.007 王玉林,郑启龙.魂芯分簇VLIW DSP上指令调度的优化[J].微型机与应用,2017,36(11):23-26,30. 2017-01-13) 王玉林(1992-),男,硕士研究生,主要研究方向:并行计算、编译理论与技术。 郑启龙(1969-),男,硕士,副教授,主要研究方向:并行编译。3 实验结果
4 结束语
猜你喜欢
铁道通信信号(2020年7期)2020-02-06
计算机与网络(2019年9期)2019-10-21
科技传播(2015年20期)2015-03-25
信息安全研究(2015年3期)2015-02-28
汽车零部件(2014年1期)2014-09-21
西安航空学院学报(2014年5期)2014-07-13
汽车零部件(2014年2期)2014-03-11
组合机床与自动化加工技术(2014年10期)2014-03-01
现代电子技术(2009年8期)2009-06-25
微型计算机(2009年17期)2009-05-19
