
基于Sphinx的机器人语音识别系统构建与研究
2017-06-05 16:44袁翔
电脑知识与技术 2017年7期
关键词:语音识别
袁翔


摘要:通过对基于隐马尔科夫模型(Hidden Markov model,HMM)的语音识别算法进行研究,将HMM模型算法的基本思想应用到机器人语音识别系统中,以Sphinx为测试平台,对机器人的控制命令语音信号进行训练得到语言模型和声学模型,利用训练得到的语言模型和声学模型构建一个机器人控制命令语音识别系统,实验测试结果表明,该系统平均错词率为7.1%,具有良好的识别效果,在小词汇量汉语语音识别中具有较高的识别率。
关键词:语音识别;Sphinx;隐马尔科夫模型;声学模型;语言模型
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2017)07-0154-02
目前主流的语音识别算法田有隐马尔科夫模型12和深度神经网络 。对于建模单元统计概率模型描述,主要采用混合高斯模型(GMM),HMM-GMM模型在很长一段时间是语音识别声学建模的主流模型。2011年微软在深度神经网络领域取得突破并成功应用于语音识别,深度神经网络因具有更加优异的特征学习和特征表达能力成为研究的前沿。深度学习在语音识别中取得了较好的效果,但其需要的海量数据训练以及大规模并行运算无法在嵌入式平台上实现。
本文在嵌入式平台上搭建一个机器人的控制命令小词汇量汉语语音识别系统,通过收集录制控制命令的训练和测试语音数据,设计训练过程需要用到的脚本,本文完成了控制命令的声学模型和语言模型训练,最终使用训练好的模型文件构建了一个以Sphinx为识别引擎的机器人语音识别系统。
1基于HMM的语音识别算法
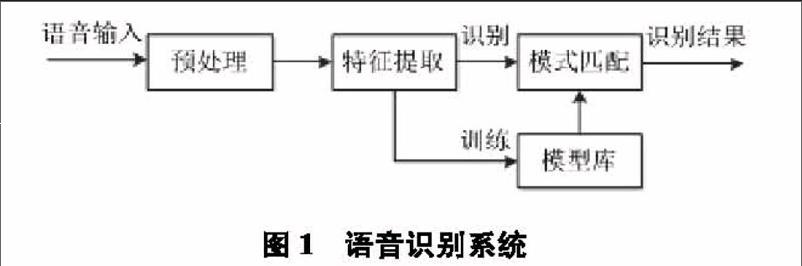
一个典型的语音识别系统结构如图1所示,包括预处理单元、特征提取单元、模式匹配单元、模型库建立单元四个部分。
HMM模型可表示为λ=(A,B,π),A为状态转移矩阵,B为观察值概率矩阵,π为初始状态概率分布,N表示马尔可夫链状态数目,M表示观察值个数。在本文应用中,主要运用HMM模型解决控制命令的识别问题和声学模型训练问题。
1.1语音识别算法识别问题
识别问题:给定观测序列o={o1,o2,…,oT)和模型λ=(A,B,π),确定产生最优O的状态序列。识别问题主要用于识别过程中解码,识别问题的基本算法为Viterbi算法,具体过程由以下公式迭代计算:
(1)
(2)
(3)
(4)
(5)
(6)
(7)
(8)
1.2语音识别算法训练问题
训练问题;给定观测序列O={o1,o2,…,oT)和模型λ=(A,B,π),如何得到一个最优的HMM模型,即通过训练模型中各个参数使得P{O|λ)取最大值。语音识别中用于声学模型的训练基本算法有Baum-Welch算法,实现过程如下:
(9)
(10)
将ξ(i,j)对#从1到T求和可求得状态Si到Sj的转移期望值,将γt(i)对t求和可求得从其他状态访问状态Si的期望值,这两个过程就是Baum-Welch算法基本思想。
2基于sphinx的机器人语音识别系统构建
2.1实验系统与设置
机器人语音识别系统设计如图2所示:
嵌入式主控平台主要负责语音识别,识别麦克风传人的语音控制命令,再通过无线模块与机器人通信,最终实现了语音命令控制机器人的效果。选择的命令包括“前进”、“后退”、“左转”、“右转”、“停止”、“启动”、“开灯”、“关灯”、“开电源”、“关电源”。
2.2数据准备
数据准备主要分为语言模型数据和声学模型数据两大部分,下面分别介绍。
2.2.1语言模型数据准备
本文使用CMUClmtk工具进行语言模型训练,CMUClmtk将统计控制命令文本数据产生以单个词建立的N_Gram模型。N-Gram模型的基本思想是,当前词的出现只与该词前面出现的所有词有关,各个词出现概率的乘积就是整个句子出现的概率。从语料中统计每个词同时出现的次数可得到各个词的概率,准备好用于语言模型训练的语言数据之后,CMUClmtk将统计文本文件中每个词出现的次数和词的总数,然后列举文本中出现的每一个词的n元语法,最终转换为Sphinx需要的二进制格式(DMP)语言模型。
2.2.2声学模型数据准备
声学模型数据准备首先需要录制用于训练和测试的原始语音文件,然后准备字典文件,字典文件包括主字典文件和补充字典文件,主字典文件中包含了需要进行训练的控制命令以及与控制命令相对应的音素集,补充字典主要列举了非语音单词,它包括静音,背景噪声等。下一步将字典文件通过命令脚本生成音素文件,音素文件包含所有训练的音素集。
2.3模型训练
首先对训练的语音信号提取特征向量,Sphinxtrain采用提取梅尔频率倒谱系数(MFCC)作为特征向量。下面分别为字典中每个音素建立上下文无关模型(CI-modds),并为音素关联状态建立上下文有关模型(CD-unfied models)以及建立决策树,可以通过决策树聚类的方法来减少参数数量。下一步将为音素训练最终聚类后的CD模型(CD-tied models),删除插值是一个为了减少过度拟合的一个迭代过程,最终得到由均值文件、方差文件、混合权重文件和转移矩阵文件组成的控制命令声学模型。
2.4语音识别
在完成以上声学模型训练过程之后,系统会使用测试语音对训练好的声学模型进行解码。使用Viterbi算法计算概率最大路径的输出概率得到识别结果,系统会统计解码器对测试语音的错词率作为识别结果。
3结果及分析
本实验系统环境为Ubuntul2.04系统,在实验室环境录制了20名同学的语音,其中男10名,女10名,在无噪声环境下采用近距离麦克风录制,数据采样率为16kHz,16位量化编码,每位同学将以正常说话语速将10个命令录制10次,将10位男生和10位女生前5次录音作为训练数据,后5次录音作为测试数据,对训练好的声学模型进行测试,采用错词率(WER)作为标准来统计结果,假设有一个N个单词长度的原始文本和识别出来的文本。I代表被插入的单词个数,D代表被删除的单词个数,S代表被替换的单词个数,那么错词率就定义为:
WER=(I+D+S)/N (11)
系统的识别结果如表1所示:
测试语音的识别结果表明系统对十个单词都达到了较高的识别率,其中单词摞の缭磾的错词率最高为9%,单词搏V箶错词率最低为5%,整体来说十个控制的命令能平均错词率为7.1%。本系统识別结果表明训练所得声学模型良好,在Sphinx上构建语音识别控制平台取得较好的效果。
4结束语
本文以Sphinx为语音识别平台,通过收集录制控制命令的训练和测试语音数据,设计训练过程需要用到的脚本,本文完成了控制命令的声学模型和语言模型训练,最终成功搭建了一个嵌入式控制命令语音识别系统,对机器人语音控制命令进行测试,在本文实验测试中,Sphinx在训练的声学模型和语言模型中表现优良,十个控制命令的平均错词率为7.1%,具有良好的识别效果。
猜你喜欢
科技创新与应用(2017年3期)2017-02-18
中国新通信(2016年21期)2017-01-06
现代电子技术(2015年11期)2015-07-28
现代电子技术(2015年8期)2015-07-09
