
基于词向量方法的微博用户抑郁预测
2017-06-05 16:39方振宇
电子技术与软件工程 2017年7期


摘 要 常用的抑郁检测方法都是采用的传统的情感分析的方法,比如情感词汇的统计,用户微博情感的极性计算以及聚类分析等。这些方法采用的都是人为的定义特征的方法,需要花费大量的时间定义以及处理特征,同时还需要进行特征的降维和简化等工作。为了自动学习出用户的特征,本文采用了word2vec训练词向量的方法来构建用户的向量表示。由于词向量包含了一定的语义信息,在此基础上构建的用户向量则涵盖了用户的微博文档信息。本文利用构建好的用户向量进行了用户的抑郁分类实验,结果表明本文提出的方法可以应用于抑郁的分类与检测。
【关键词】word2vec 词向量 用户向量 抑郁检测
1 引言
世界卫生组织目前指出,在2020年到来之际抑郁症的发病率将仅次于缺血性心脏病,成为世界上第二大严重的流行疾病。抑郁症心理障碍对人们造成的影响十分巨大,患有抑郁的人群注意力学习能力会相应的下降,工作的效率会大大减小,这极大的影响了这群人的生活。在世界前十种致残或使人丧失劳动能力的主要疾病中有五种是精神疾病,其中抑郁症名列第一给社会带来巨大的危害。
目前抑郁症的检测主要是基于问卷调查的方式,医院或者心理检测机构向参与心理调查的用户发放调研问卷。基于心理测评表的方法能够很好的预测用户是否有心理障碍的迹象,针对心理自评表的得分基本可以判断用户是否有抑郁症等心理障碍。但是这种方法只适用于一对一的调查检测,大规模的采用这种问卷调查方式进行人群普查将消耗大量的人力物力。
作为中国的的社交网络工具,微博是中国最热门的个人及媒体发布信息的平台之一。由于微博是个人用户分享心情,发表看法以及与他人互动的平台,个人用户的微博包含了大量的用户个人信息以及情感动态,获取并对这些微博内容进行分析可以进行个人情感的挖掘,深度挖掘这些内容为分析个人用户的情感提供了可能。
本文通过获取具有心理障碍以及没有心理障碍人的微博数据,对这些数据进行格式的清洗,去除不需要的信息如符号,表情,标点等,获取到文本信息进行词向量的训练,并在此基础上构建用户向量用于分类器的实现。
2 词向量简介
word2vec是google发布的通过训练词汇得到词向量的一款开源工具。word2vec采用的是分布式表示的词向量方法。根据给定的分此后的语料库,word2vec可以使用神经网络模型将词语表示成向量的形式。主要思想是根据每个词具有不同的词频特性,使用Huffman编码方式对词语进行编码。编码的方法是根据不同的词频采用不同的编码。词频越高的词语,其训练时隐藏层数目越少。词频相差不多的的词汇在训练时隐藏层采用相同的激活方式。采用这种方法可以有效的减少模型计算的复杂度。
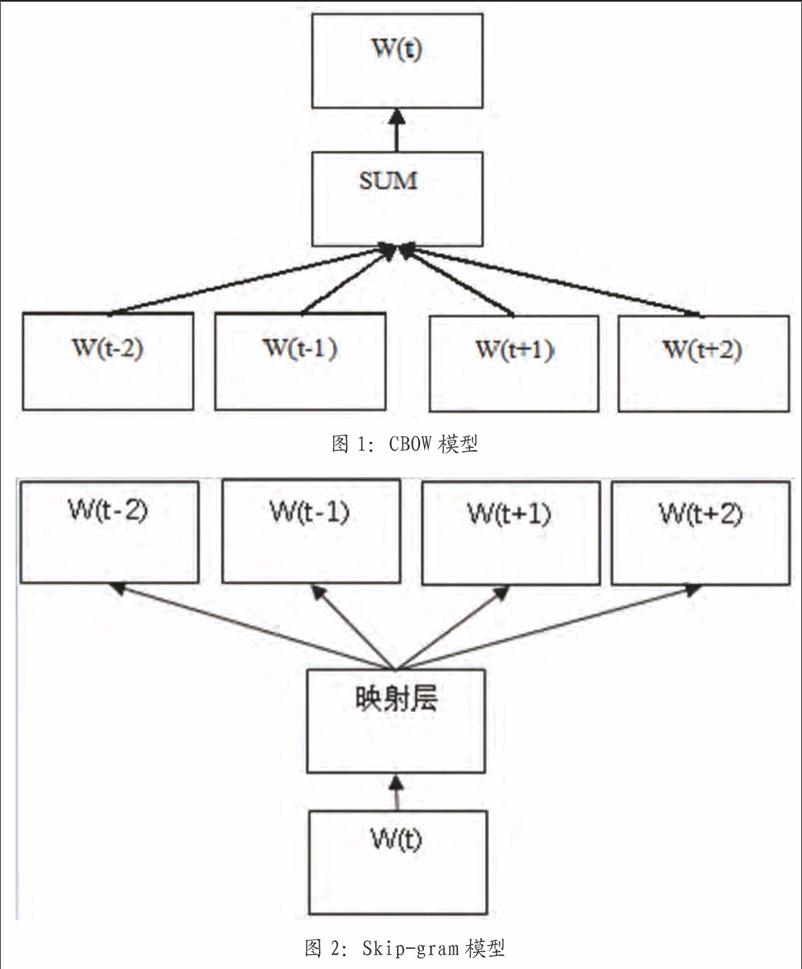
Word2vec包括两种训练模型,分别是CBOW和Skip-gram。
如图1,CBOW模型采用周围的词对中心词进行预测,中间为求和层。这种方法是Mikolov将原始的NNLM的神经网络训练模型经过改造后的到的一种模型。其中,最下一层是句子上下文词汇,中间层是对上下文词汇进行汇总去预测中间词汇。
图2为skip-gram模型,输入为词的独热向量形式,隐藏层对输入进行了抽象处理,输出层节点的数目和目标词周围词对应。最终由softmax计算得到词的预测概率。
3 词向量的训練
3.1 数据获取
本文通过编写爬虫的方法,获取了443个患有抑郁症的用户数据以及477个没有抑郁的用户的数据。由于是采用词向量的方法进行试验所以本文去除了与文字无关的符号。采用正则匹配的方式过滤掉无用的信息,最后针对文本进行分词处理,得到一个微博文本的分词库。
为了保证词向量训练的效果,要将分词库中的停用词去掉。常见中文停用词包括“的”,“得”,“么”等助词,同时也包括“和”,“与”,“以及”等连接词。同时也包括逗号,句号等标点符号。
训练过程中,word2vec根据不同参数的值来改变训练的方法以及词向量的表示大小以及采样大小等。word2vec的具体参数如图3所示。
其中time表示训练的总共时间,train后面为训练文件即输入的处理后的分词文件。Dir为文件所在地址。output为训练后的词向量文件,一般保存为bin格式。cbow表示是否采用cbow模型训练,默认为skip-gram模型。两种模型有不同的优势,cbow训练速度快,skip-gram对于罕见词汇有更好的表示。Size表示词向量的维度大小,window表示训练词向量时上下文相关词汇的数值,word2vec会根据这个数值来扫描当前词汇的上下词汇,词汇的数值反映了得到词向量的语义包含的上下文词汇数目。hs和negative是训练网络中的采样方法表示,1表示选用,0表示不选用。Sample参数是采样过程中设置的大小,这个要根据语料集的大小来决定采样的数值。min-count参数是最低频率的表示,一个词语的频率小于设定的阈值系统将屏蔽该词汇。本文为了得到用户微博中所有的词向量的表示,将频率设置为1。Binary参数指的是输出的向量文件的编码格式,word2vec采用的是二进制的词向量编码,一般设置为1。
4 基于TF-IDF的用户向量表示
由于微博用户的微博信息由微博文本数据以及个人信息数据组成。本文在构建微博用户的用户向量时考虑到这一点,将文本数据的向量以及个人信息的向量结合在一起作为最终的用户向量表示。
4.1 个人信息向量
个人信息数据包含用户的个人年龄,性别,个人的粉丝数目,关注数目以及总共的点赞数和转发评论数等。这些数据是体现个人在微博上的社交情况,同时也反映了一些用户的性格特征。个人信息数据组成的向量用Vi表示。Vi包含了个人信息的相关特征,本文制订了15个用户信息特征,所以Vi是一组15维的向量。
由于最终获得的词向量的值在0到1之间,所以要把个人信息向量归一化到0到1之间。归一化的公式如下:
4.2 用户文档向量
本文采用加权词向量的方式获得用户的文档向量,由于词向量包含了上下文的语义信息,由词向量获得的用户文档向量则包含了整个用户微博的语义信息。在这个加权过程中会存在一定的词的语义的损失,但是大部分的信息都被保存下来了。所以用户的文档向量可以抽象的表示用户的微博内容信息。本文采用TF-IDF方法对词向量进行加权。
其中ni表示词语i出现的总次数,除以该用户微博中所有词的次数之和得到词i的词频表示。
(3)式表示了词语的文档间频率。N为总的文档数,mi为词语i出现过的文档数。为了防止出现词语出现次数为0导致分母为0的情况出现,本文在分母中加了数值1。
基于上面的式子,用户的文档向量可以表示为:
其中Ei为词i对应的词向量表示,N为词的个数。根据上面得到的用户的文档向量以及个人信息向量,本文得到了用户向量Ui的表示。Ui={Di,Vi}。括号内为连接的操作。
5 实验与分析
本文使用三层神经网络作为分类器进行用户的分类。分类的输入为用户的用户向量。本文共获取了68.4万的微博数据作为词向量的训练文本。Word2vec参数上本文设置了批处理大小为128,上下文词数为3,以及频率过滤数目为1.对于不同维度的词向量以及不同训练方法的训练出来的词向量,本文给出了对应的结果。
本文从微博上获取了920个用户的信息,其中443个为有抑郁的用户,477个为没有抑郁的用户。本文采用精确率,召回率以及F1值作为实验的验证标准。其中,采用十折交叉的方式遍历所有的样本,获取十次的预测结果的均值作为本文最终的实验结果,即平均精确率,平均召回率以及平均F1值。本文最终采用F1值作为实验的综合考量。实验结果如表1所示。
从表1中可以看出,CBOW相比于skip-gram的效果更好,CBOW模型的F1值普遍高于用Skip-gram,这是因为在小规模数据集上,CBOW方法训练的词向量具有更好的表现效果。在词向量50维的时候,CBOW获得了最好的F1值81.501%。实验结果表明,本文提出的使用词向量构建用户文档语义的方法是正确的。CBOW方法的各维度词向量分类精确率均在80%左右,说明该方法构建的用户向量模型是可以用于抑郁预测的,且有较好的实践效果。
6 结论
本文提出了使用加权词向量的方法构建用户向量的方法,并使用用户向量作为用户的抽象表示。实验结果表明,本文提出的方法有着比较好的效果。在此基础上可以进行进一步的扩展研究,比如用深度学习的方法对词向量进行顺序的编码以获得词的次序信息。同时利用词向量的聚类特性,可以对用户进行聚类的分析与研究。总而言之,词向量对于抑郁检测的研究有着很大的帮助。在此基础上可以挖掘出新的方法与模型用于社交网络的抑郁检测研究。
参考文献
[1]王睿,黄树明.抑郁症发病机制研究进展[J].医学研究生学报,2014(12):1332-1336.
[2]付菁文,林凡凯,乔瑾渊,等.抑郁症发生的病理生理研究进展[J].生命科学仪器,2015(01):12-16.
[3]劉芳宜,朱丽明,方秀才,等.三种不同心理测评量表对功能性消化不良患者焦虑、抑郁状态的评估[J].胃肠病学,2012,17(02):106-109.
[4]Lai S,Liu K,He S,et al.How to Generate a Good Word Embedding[J]. IEEE Intelligent Systems,2015, 31(06):5-14.
[5]Salton G,Buckley C.Buckley,C.:Term-Weighting Approaches in Automatic Text Retrieval.Information Processing & Management24(05),513-523[J].Information Processing & Management,1988,24(05):513-523.
作者简介
方振宇(1992-),男,安徽省铜陵市人。
作者单位
合肥工业大学计算机与信息学院 安徽省合肥市 230009
