
利用句法信息改进交互式机器翻译
2017-06-01 11:29张亚鹏蔡东风
中文信息学报 2017年2期
张亚鹏,叶 娜,蔡东风
(沈阳航空航天大学 人机智能研究中心,辽宁 沈阳 110136)
利用句法信息改进交互式机器翻译
张亚鹏,叶 娜,蔡东风
(沈阳航空航天大学 人机智能研究中心,辽宁 沈阳 110136)
在很多领域中,全自动机器翻译的译文质量还无法达到令人满意的程度。要想获得正确无误的译文,往往需要翻译人员对自动翻译系统的输出进行后处理。在交互式机器翻译的框架内,翻译系统和译员协同工作,译员确认系统提供的译文中的最长正确前缀,系统据此对译文后缀进行预测,共同完成翻译任务。该文利用基于短语的翻译模型,建立了交互式机器翻译系统,并结合交互式机器翻译的特点,利用句法层面的子树信息来指导翻译假设的扩展。实验表明,该方法可以有效地减少人机交互次数。
交互式机器翻译;子树信息;译文前缀
1 引言
尽管机器翻译在最近的几十年取得了很大的进展,但是,现有的自动机器翻译系统,只是在有限的领域里,可以输出直接可用的高质量的译文。对于大部分领域,用户所需要的直接可用的译文,都必须由拥有翻译知识的译员,对机器翻译系统输出的译文进行后处理,然后才能交付使用。在这种模式下,译员可以利用翻译系统推送的译文完成翻译任务,但是,机器翻译系统却不能利用译员的翻译知识。于是,一些研究人员提出了交互式机器翻译框架,在此框架内,允许译员人工干预翻译过程。首先机器翻译系统会对给定的待翻译句子推送出可能的译文,然后译员可以对翻译系统推送出的译文做出接受、修改或舍弃等操作,最后机器翻译系统会根据译员当前的操作做出下一步的预测,循环进行此过程,直到译员得到最终想要的译文。图1展示了一个经典的交互式机器翻译过程。
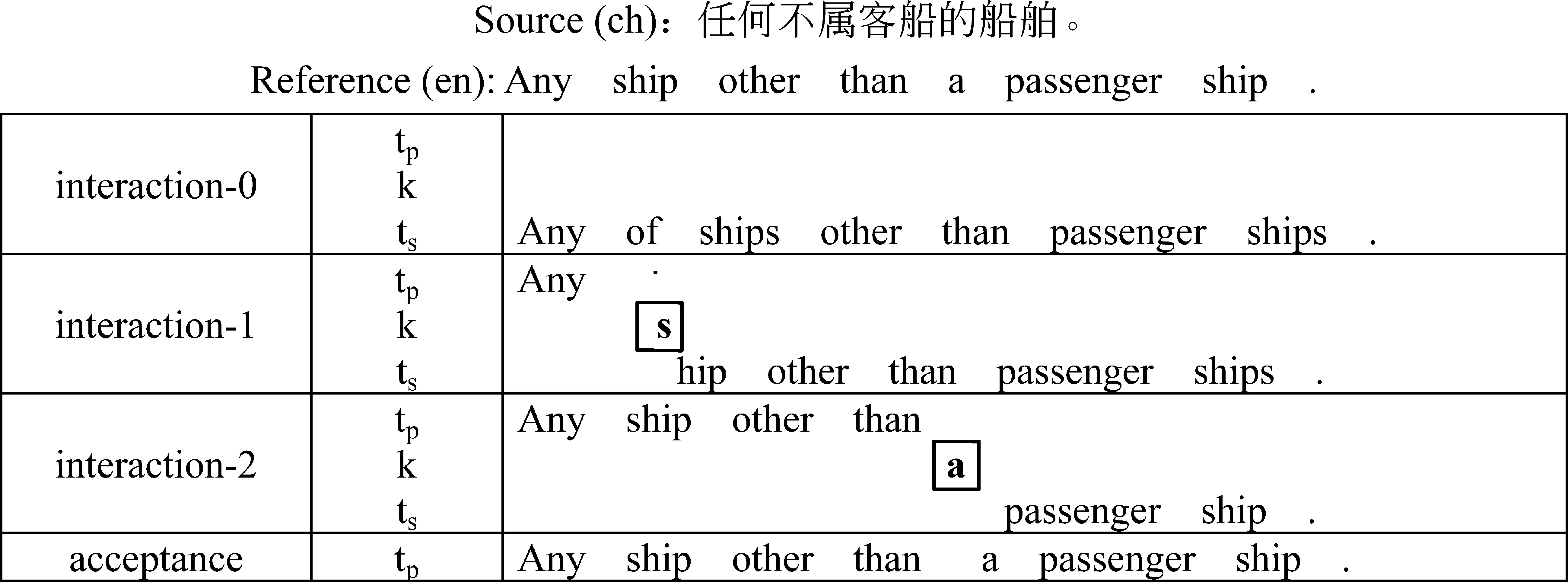
图1 交互式机器翻译实例
在这里我们要将一个汉语句子(source)“任何 不 属 客船 的 船舶 。”翻译为英文译文(reference)“Any ship other than a passenger ship .”。在开始交互之前(interaction-0),系统首先推荐一个可能的译文(或译文后缀,ts)。在第一次交互(interaction-1)中,用户挪动光标来接受译文的前四个字符“Any ”(空格也包含在内),并且用键盘输入字符s(k),然后系统根据用户修改后的译文前缀立即给出新的译文后缀“hip other than passenger ships .”第二次交互(interaction-2)的境况类似。在最后一次交互时用户完全接受了系统当前推荐的译文。
交互式翻译系统的解码原理与传统全自动机器翻译的解码原理是一样的,因此交互式的机器翻译系统可以采用基于栈的解码策略,利用多栈或者是柱搜索解码算法。不同的地方在于,在交互式翻译系统解码时,会考察当前的翻译假设是否符合译文前缀,若不符合译文前缀则不加入到待扩展假设中。然后一步步扩展,直至生成最终译文。
本文在基于短语的机器翻译模型的基础上,建立交互式机器翻译框架,并针对交互式机器翻译中前缀信息的引入,提出了利用句法层面的子树信息来指导翻译假设扩展的方法。并且结合翻译人员给予的译文前缀,相比于传统的机器翻译系统,交互式机器翻译系统的特殊特征,用三种策略把子树信息加入到交互式机器翻译系统的解码当中。第一种: 只在完全匹配译文前缀之前的翻译假设扩展时,使用子树信息指导翻译假设的扩展;第二种: 只在完全匹配译文前缀之后的翻译假设的扩展时使用子树信息作为指导;第三种: 在整个翻译假设扩展当中都使用子树信息进行指导。实验结果表明,三种策略相比于基线系统,都能减少人机交互次数,但是第三种策略的效果最好。
本文结构安排如下: 在第二部分,介绍与本文相关的研究;第三部分介绍子树的抽取方法,以及如何将子树信息嵌入交互式机器翻译系统的解码中;第四部分介绍实验配置、实验结果及分析;第五部分对本文进行总结,并给出未来的工作设想。
2 相关工作
在这部分中,介绍一些交互式机器翻译方面的其他研究人员的工作。
在早期的交互式机器翻译研究中,研究人员主要的研究点集中在对源语言文本的解释和消歧。Foster在1997年提出了TransType的基本系统[1],该系统第一次将交互式机器翻译的关注点从对源语言文本的解释分析转移到目标语言文本的生成上,减轻了译员的工作负担提高了效率,并且使译员可以控制翻译系统输出的译文。之后的几年当中,又有很多的研究人员对TransType系统进行了改进。Langlais等人在2000年对系统的用户界面和词的预测提出了改进[2]。2002年,由许多欧盟研究机构共同参与的TransType2项目,创新性的把一个完全的基于数据驱动的机器翻译系统嵌入到交互式翻译框架中,并且在每一次的交互过程中,翻译系统都会根据翻译人员给出的译文前缀,预测出一个或者多个最好的后缀补全译文,供翻译人员选择。在TransType2项目中,很多的研究人员对系统进行分析,并且提出很多种方法来解决这些问题。TransType的这两个项目极大的推动了交互式机器翻译技术的发展。2010年,Ortiz和Casacuberta等人,将在线学习的思想加入到了交互式机器翻译技术当中。其主要思想是利用用户的反馈信息来不断的完善系统的底层模型[3]。González-Rubio和Ortiz等人,将机器译文的置信度评价作为其是否需要和翻译人员进行交互的衡量,从而有效地平衡了翻译人员的工作量和系统翻译结果的准确率[4]。2012年,González-Rubio和Ortiz等人[5],将动态学习的方法引入到交互式机器翻译系统当中,使系统可以增量式的从已经翻译完的句子中学习,从而明显地提高后续句子的翻译准确率,有效减少了翻译人员的工作量。2013年,Jesús González-Rubio和Daniel Ortíz-Martinez等人[6],将基于层次短语的翻译模型应用到了交互式机器翻译当中,并且采用了超图作为机器和用户之间的交互接口。
在之前的研究中,研究人员从对源语言的分析转移到对目标语言的生成,并且把在线学习和动态学习的思想加入到模型中,但都没有使用句法信息对翻译系统进行改进。
3 子树信息抽取及嵌入
这一部分,主要讲述子树信息的抽取及如何将子树信息嵌入到翻译系统的解码中。
3.1 子树信息抽取
句法树采用短语结构树。该句法结构把句子细分成更小的单位,然后通过短语连接起来。
子树是一个句子中相对独立的一部分,它可以是一个名词短语或动词短语。我们使用的子树信息,是一个三元组,如式(1)所示,我们所用到的子树并不包含整棵句法树,因为整棵句法树在本文中无任何意义。
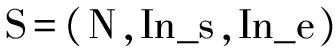
(1)
N表示子树名称,In_s表示子树开始词在句子中的位置,In_e表示子树结束词在句子中的位置。
系统得到待翻译的句子之后,我们首先用句法分析器对句子进行句法分析,生成短语结构句法树,如图2所示。经图3的伪代码处理之后,我们得到句子的子树信息。最终我们得到的子树是(NP,0,1)、(VP,2,6)、(IP ,3 ,6)、(VP ,4 ,6)、(VP ,5,6)。

图2 短语结构树的示例

图3 子树抽取伪代码
3.2 子树信息的嵌入
对句子进行翻译时,应该在完成对一个子树的翻译之后,才能对其他子树进行翻译,我们就把这个原则加入到交互式翻译系统框架中。本文中,我们使用基于短语的交互式翻译系统框架,利用多栈解码算法对短语系统进行解码。在每个代表当前翻译假设覆盖源语言词个数的大栈中,有很多覆盖不同位置但覆盖源语言词个数的小栈。当扩展翻译假设时,我们会选取每个大栈里的每个小栈中最大分值的翻译假设进行扩展。在这里我们使用子树信息选择更合适的翻译假设,由于短语扩展存在调序现象,所以覆盖相同源语言词的翻译假设可能是由不同的短语组成的,选取短语假设扩展时,在覆盖源语言词个数且源语言词位置相同的多个翻译假设中,若存在符合子树限制的翻译假设,则选择此翻译假设进行扩展,若不存在,我们按照传统的翻译假设选择方法,选择翻译假设进行扩展,当出现多个符合子树限制翻译假设时,我们选择分值最高的那个翻译假设进行扩展。
符合子树限制的定义是: 当前翻译假设包含的上一个被翻译的短语和最后一个被翻译的短语所包含的词在同一个子树内。为了更好的结合基于短语的翻译模型,若当前所选择的子树只有一个连续的短语未被翻译且这个连续的短语在子树的边界上,允许扩展当前子树未包含的源语言词,前提是,当前所扩展的短语完全包含当前子树未翻译的词。例如,假设一个源语言句子有7个词,已翻译词的标志数组为[1100100](标志位为1表示已经被翻译,标志位为0表示未被翻译),当前翻译的短语包含的词在句子中的位置为<4,4>和选择子树(VP,3,5)来限制短语的扩展,那么符合子树限制的短语有<3,3>、<5,5>、<5,6>,不符合子树限制的短语有<2,2>、<2,3>、<6,6>。
在判断翻译假设是否符合子树限制时,只使用翻译假设的上一个被翻译的短语和当前被翻译的短语是一种软策略,考虑到句法分析的性能,我们并不要求翻译假设的每一次扩展都符合子树限制,这样能够更好的利用原有系统短语扩展的优势。
然后结合交互式翻译所特有的特征——译文前缀,本文提出三种策略,第一种: 只把子树信息应用到当前所选择的翻译假设未覆盖译文前缀时;第二种: 只把子树信息应用到当前所选的翻译假设覆盖译文前缀之后;第三种: 把前面两种结合起来,在整个句子的翻译中使用子树信息。三种策略的伪代码如图4~图6所示。

图4 只在所选翻译假设未覆盖翻译前缀时使用子树信息伪代码

图5 只在所选翻译假设已经覆盖翻译前缀时使用子树信息伪代码

图6 在整个翻译过程中使用子树信息伪代码
子树抽取时,抽取子树之间会存在嵌套且仅仅对包含整个句子的子树的特殊子树限制抽取,会造成包含句子词的个数过多的情况出现,这将导致翻译假设对子树限制不敏感。针对子树嵌套的情况,根据子树包含句子中词的个数,我们提出了最大子树策略(max_subtree)和最小子树策略(min_subtree),当出现子树嵌套情况时,根据策略不同,选取不同的子树。为了避免出现包含句子中词个数过多的子树出现,我们通过子树包含词的个数与整个句子词的个数的比值(RatioSubtreeSentece)对所抽取子树进行过滤。另外,在选取符合子树限制的翻译假设进行扩展时,我们还应该考虑将本方法所选择的翻译假设的分值与传统方法所选择的翻译假设的分值进行比较,对一些分值过低但符合子树限制的翻译假设进行舍弃。因为如果分值过低,在下一步的剪枝策略时也会被舍弃。我们把这个因素定义为分值比(score_ratio),在实验环节,会对以上提出的可能影响到系统性能的参数进行单独实验。
4 实验设置及结果分析
在这一部分,对实验语料的信息、评价标准和实验结果进行描述,并对实验结果进行分析。
4.1 语料信息
我们的实验采用部分的汉英平行语料Hong Kong Laws Parallel Text(LDC2000T47)进行,该语料是来自香港的一些法律文本。我们使用了其中的20万平行句对来作为训练语料,并从这20万平行句对之外的部分随机选取了不重叠的1 000个和1 558个平行句对分别做开发集和测试集,并且考虑到模拟交互环境对参考译文准确性的要求,开发集和测试集的平行句对都是经过人工校正的。表1示出了所用语料的一些统计特性。
中文部分都采用ICTCLAS进行了分词处理,并且所用语料的英文部分都经过了词形还原和小写化处理。GIZA++[8]工具被用来进行训练语料的词对齐工作,而双向词对齐的融合采用Grow-Diag-Final策略。此外我们利用SRLIM[9]工具在训练语料的英文单语语料上训练了一个3-gram的语言模型。我们使用开源工具moses来训练基于短语的统计翻译模型。该短语模型使用了moses默认的14个特征,并且这些特征之间按照对数线性的方式进行结合,此外, 我们使用了最小错误率训练[10](MERT)来对特征的参数进行优化,并且优化指标采用大小写不敏感的BLEU-4指标。句法树采用berkeley句法分析器生成[11],我们选用1-best句法树来抽取子树信息。
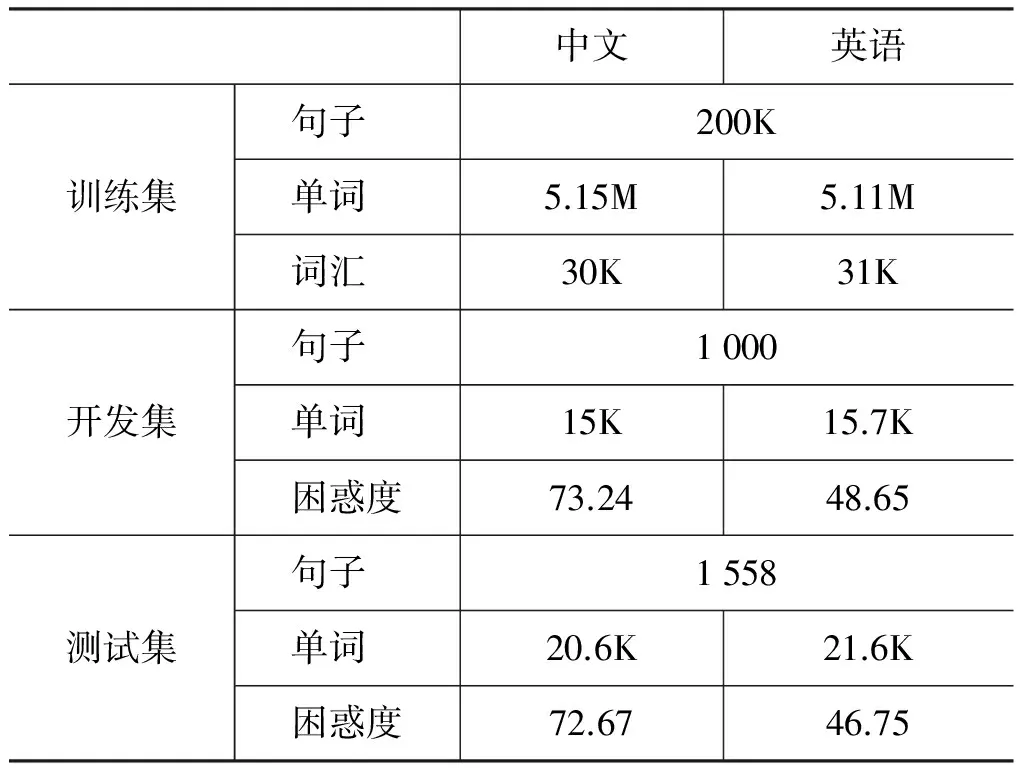
表1 语料统计特性
4.2 评价标准
在本文中,对交互式翻译系统的性能评价我们采用了Key-stroke ratio(KSR)指标,该指标的计算方法为: 用要得到标准译文(参考译文)所需的键盘敲击次数除以标准译文(参考译文)所包含的字符总数[7]。KSR的值越小,则交互式翻译系统的性能也应该越好。
4.3 系统设置
基线系统(Baseline)是我们实现的传统的交互式机器翻译系统,然后我们子树信息通过三种策略加入到基线系统中。三种策略分别表示为(+ISIBCP : 在翻译假设未覆盖译文前缀时使用子树信息, +ISIACP : 在翻译假设已经覆盖译文前缀后使用子树信息, +Both : 在整个翻译过程中使用子树信息)。为了更好的显示系统性能,我们在不同的N-best列表上计算评价标准。
4.4 实验结果及分析
表2的系统中,对于上一节我们所提到的三个影响因素设置是一致的。这里我们在使用子树的选择上使用min_subtree,对于另外的两个可能影响系统性能的因素没有考虑。通过表2的实验结果,我们可以看到,把子树信息嵌入到交互式翻译系统,无论是在覆盖翻译假设前,还是覆盖翻译假设后,都可以在一定程度上减少交互次数,但在“+Both”系统中表现出比其他系统更好的性能。
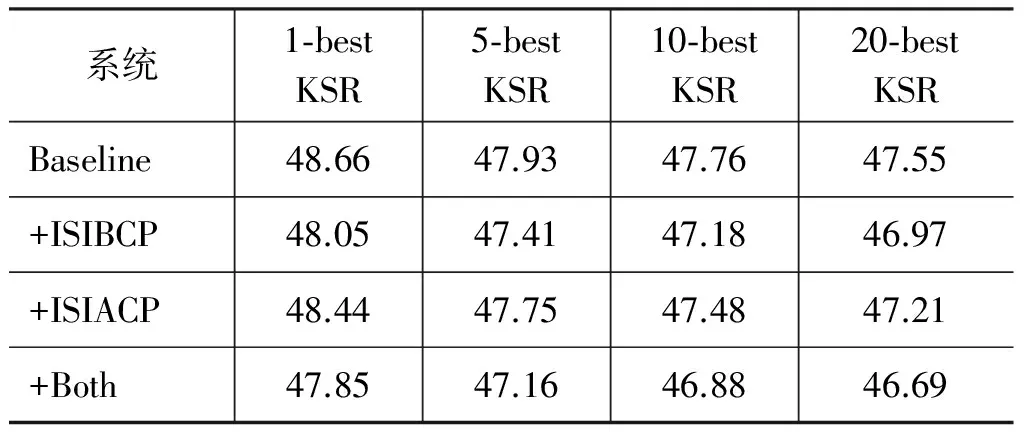
表2 不同系统的实验结果
表3是各个系统的在用1-best结果作为参考的情况下,翻译速度方面的表现,我们发现随着系统性能提高,在可接受的范围内,速度也会有所下降。

表3 不同系统的速度
在其他影响因素固定的情况下,使用不同的策略选择子树。通过表4中的实验结果,我们知道,当子树出现嵌套的情况时,选取不同的子树来评价当前的翻译假设,会对翻译假设的选取有一定的影响,同时对翻译系统的性能产生一定的影响。

表4 max_subtree和min_subtree的实验结果
表5的结果是在其他影响因素固定的情况,根据RatioSubtreeSentence在抽取子树时,对当前句子中所包含的子树进行过滤,在遇到子树嵌套的情况使用min_subtree策略选择子树。并在“+Both”系统上进行实验,结果表明,在一定的情况下对子树进行过滤会提高系统性能。
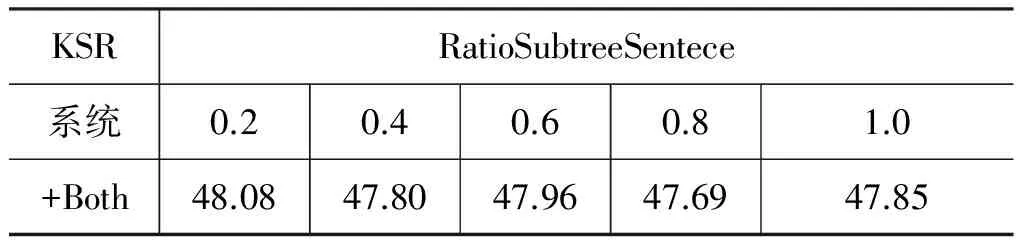
表5 RatioSubtreeSentece的实验结果
表6的结果是我们在“+Both”系统基础上,对所选择符合子树限制的翻译假设的分值与当前的翻译假设的分值比做了限制,我们可以看到随着分值比的限制系统性能越来越差,这也从另一个方面显示了,调序模型的简单,未给出适当的分值。

表6 score_ratio的实验结果
5 总结及未来工作
我们可以看到,随着分值比的限制提高,系统的性能逐步下降。这也从另一个角度证明了,传统方法未能充分利用前缀的约束信息,对翻译假设给出合理的分值。提出三种不同的策略把子树信息加入到交互式翻译系统中。另外,我们还发现了几个影响系统性能的因素,如当子树出现嵌套时,子树的选择;抽取子树时子树包含词的个数与当前句子之间的比值;所选择的符合子树限制到翻译假设与传统的方法所选择的翻译假设之前的分值比。经过实验证明这些都会影响到系统的性能,本文只验证了这些因素单独使用时对系统性能的影响。在未来的工作中,我们会研究三种因素的综合作用对系统性能的影响。而且,在此系统中,对于由于各种原因不能匹配用户前缀的情况,系统会直接跳出解码,不会给出翻译后缀。因此,后面的研究也会涉及到在当前系统不能匹配用户给出翻译前缀时生成翻译后缀的策略。当前我们的基线系统采用的是多栈的解码策略,我们下一步将研究在柱搜索解码策略中子树信息的应用。
[1] Foster G, Isabelle P, Plamondon P. Target-text Mediated Interactive Machine Translation[J]. Machine Translation, 1997, 12(1): 175-194.
[2] Langlais P, Foster G, and Lapalme G. TransType: a Computer-aided Translation Typing System[C]//Proceedings of the NAACL/ANLP Workshop on Embedded Machine Translation Systems, 2000: 46-52.
[3] Ortiz-MartinezD, Garcia-Varea I, Casacuberta F. Online Learning for Interactive Statistical Machine Translation[C]//Proceedings of NAACL 2010, 2010: 546-554.
[4] Gonzalez-Rubio J, Ortiz-Martinez D, Casacuberta F. Balancing User Effort and Translation Error in Interactive Machine Translation Via Confidence Measures[C]//Proceedings of the 48th ACL, 2010: 173-177.
[5] Gonzalez-Rubio J,Ortiz-Martinez D, Casacuberta F. Active learning for interactive machine translation[C]//Proceedings of the 13th EACL, 2012: 245-254.
[6] Jesús González-Rubio, Daniel Ortiz-Martínez, José-Miguel Benedí, et al. Interactive Machine Translation using Hierarchical Translation Models[C]//Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, 2013: 244-254.
[7] Och FJ, Zens R, Ney H. Efficient Search for Interactive Statistical Machine Translation[C]//Proceedings of EACL 2003, 2003: 287-293.
[8] Och F J, H Ney. A systematic comparison of various statistical alignment models[J]. Computational Linguistics, 2003, 29(1): 19-51.
[9] AndreasStolcke, Jing Zheng, Wen Wang, and Victor Abrash. SRILM at Sixteen: Update and Outlook[C]//Proceedings of IEEE Automatic Speech Recognition and Understanding Workshop,2011.
[10] Franz Josef Och. Minimum error rate training in statistical machine translation[C]//Proceedings of ACL, 2003: 160-167.
[11] Petrov S, Barrett L, Thibaux R, et al. Learning accurate, compact, and interpretable tree annotation[C]//Proceedings of the 44th Association for Computational Linguistics, 2006: 433-440.
Using Syntactic Information to Improve InteractiveMachine Translation
ZHANG Yapeng,YE Na,CAI Dongfeng
(Human-Computer Intelligence Research Center, Shenyang Aerospace University,Shenyang,Liaoning 110136,China)
In many domains, the performance of fully automatic machine translation is still not satisfactory. In order to obtain error-free translation, human translators need to perform post-editing on the output of automatic translation systems. Under the framework of interactive machine translation, the translation system and the translator work collaboratively. The translator validates the longest correct prefix in the translation provided by the system, and the system predicts the suffix to complete the sentence. On the basis of phrase-based translation model, this paper built an interactive machine translation system. Considering the characteristics of interactive machine translation, syntactic subtree information is used to guide the extension of translation hypotheses. Experiments show that this method can effectively reduce the interaction time between human and the computer.
interactive machine translation; subtree information; translation prefix

张亚鹏(1988—),硕士研究生,通信作者,主要研究领域为交互式机器翻译。E⁃mail:zhangyp_nlp@163.com叶娜(1981—),博士,讲师,主要研究领域为辅助翻译、文本挖掘。E⁃mail:yena_1@126.com蔡东风(1958—),博士,教授,主要研究领域为人工智能、自然语言处理。E⁃mail:caidf@vip.163.com
2015-01-10 定稿日期: 2015-03-10
国家自然科学基金(61402299)
1003-0077(2017)02-0042-07
TP391
A
猜你喜欢
中国石油石化(2022年12期)2022-07-16
通信技术(2021年12期)2022-01-25
医学美学美容(2021年18期)2021-10-21
中国人民公安大学学报(自然科学版)(2020年2期)2020-07-04
中国外汇(2019年19期)2019-11-26
初中生世界·九年级(2019年6期)2019-08-15
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
计算机应用与软件(2018年9期)2018-09-26
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
